一種軌跡數據停留識別方法及系統與流程
本發明涉及軌跡數據處理技術領域,特別涉及一種軌跡數據停留識別方法及系統。
背景技術:
隨著科學技術的進步,移動手機已經高度融合到人們的日常生活中。而手機的使用總是在和附近的信號基站進行通訊,使得在大規模人群級別中對每個個體的位置進行連續追蹤成為了可能。近年來,大規模手機軌跡數據廣泛應用于人口動態分布[1]、城市區域功能檢測[2]、交通需求評估[3]、區域流行病傳播[4]與控制以及城市人群活動模式[5,6]等領域的研究,以空前樣本量為諸多社會經濟現象提供了新的觀察視角,也為感知空間位置的功能現狀以及理解居民的生活訴求提供了一條全新的途徑[7]。
從手機軌跡數據中提取停留是上述諸多應用的基礎。人們的日常活動,尤其是在靜止的局部空間開展的活動(也有在移動環境下進行的,例如地鐵上讀書)是人們日常生活的基本要素,這些活動在個體的時空軌跡上表現為停留的特征。理解人們活動情況是許多應用和研究的基礎,因此從手機軌跡數據中提取停留成為這一過程的必要步驟。
停留-非停留軌跡模型(Stop and Not Stop of Trajectory,SNSoT)是現有的軌跡數據提取的主流方法。該方法是從基于傳統的GPS(Global Position System,全球定位系統)軌跡數據的停留與移動模型(Stop and Move of Trajectory,SMoT)發展而來[8–10]。學者從人的日常生活出發,根據人們的空間行為特征將其分為兩個大的類別:停留和移動,對應的概念模型稱之為SMoT。表現在軌跡數據上,停留表現為持續的一段時間內,個體的位置沒有發生移動,或者是在局部范圍內進行移動;而移動表現為持續的一段時間中,個體的位置不斷的發生變化。在具體操作上,學者用兩個參數來識別停留分段:時間閾值T0和空間閾值D0[6,11]。即,根據軌跡數據中停留的特點,當個體在局部的空間范圍D0內,活動時間超過了T0,可以將軌跡數據中的這部分判定為停留分段。而識別了停留之后,剩余的部分全部歸結為移動的部分。這種方法的實現思路的本質是SNSoT,也就是識別了停留,然后剩下的部分都是“非停留”部分。手機軌跡數據出現之后,學者直接將在GPS軌跡數據中廣泛使用的SNSoT直接用于手機軌跡數據中的停留識別,而現在已成為手機軌跡數據中停留識別的主要方法。
而與傳統的GPS定位方式不同,手機定位信息一般是利用為其提供服務信號基站的位置來表示。實際上,為了實現用戶手機信號的全覆蓋,附近基站的覆蓋范圍是有重疊的,手機可以接收到多個基站的信號;同時,通信系統為了使得每個信號基站服務的手機數量均衡,對各個基站的功率會進行調整。在這種情況下,即使用戶沒有移動,手機接收的信號基站也可能會發生變化,在數據上表現為一種移動。我們稱這種現象為一種“假移動”,典型的是一種“乒乓現象”[12,13],實際上應當歸屬為停留的類別。手機軌跡數據的“假移動”現象在利用SNSoT方法識別停留時會帶來誤判。
在現有的SNSoT方法中,“假移動”帶來兩個負面影響。首先,當“假移動”發生在一個停留中間時,一個停留活動就被分割成了多個,停留的次數變多。其次,“假移動”的存在會使得數據反映出用戶處于停留狀態的時間減少,因為“假移動”的本質是停留,但是在SNSoT中無法識別為停留。在SNSoT方法中,只識別符合停留條件的部分,剩下的“非停留”部分就不再考慮其中是否有漏識別的情況。
手機軌跡數據的稀疏時間采樣特征為“假移動”的檢測和去除帶來了困難。當前用于研究的手機定位數據平均時間采樣間隔最詳細的是30分鐘[14],而GPS軌跡數據的時間采樣間隔一般在30-90秒。當時間采樣間隔較小時,可以根據手機位置在鄰近基站跳轉的特點,通過異常速度值等識別并過濾“假移動”現象。而在稀疏時間采樣的情況下,時間采樣間隔較大,由于跳轉往往在附近的基站進行,速度指標在正常范圍之內,難以實現“假移動”的識別,導致基于手機軌跡數據的停留識別方法的準確率和召回率較低。而隨著研究的深入,應用越來越朝著精細的定量化分析和多種數據源結合的方向演進,對具有高準確率和召回率的停留識別方法顯得尤為迫切。
上述中,與本申請相關的參考文獻包括:
[1]DEVILLE P,LINARD C,MARTIN S等.Dynamic population mapping using mobile phone data[J].Proceedings of the National Academy of Sciences,2014,111(45):15888–15893.
[2]PEI T,SOBOLEVSKY S,RATTI C等.A new insight into land use classification based on aggregated mobile phone data[J].International Journal of Geographical Information Science,2014,28(9):1988–2007.
[3]WANG P,HUNTER T,BAYEN A M等.Understanding Road Usage Patterns in Urban Areas[J].Scientific Reports,2012,2.
[4]WESOLOWSKI A,EAGLE N,TATEM A J等.Quantifying the Impact of Human Mobility on Malaria[J].Science,2012,338(6104):267–270.
[5]SCHNEIDER C M,BELIK V,T等.Unravelling daily human mobility motifs[J].Journal of The Royal Society Interface,2013,10(84):20130246.
[6]JIANG S,FIORE G A,YANG Y等.A Review of Urban Computing for Mobile Phone Traces:Current Methods,Challenges and Opportunities[C]//Proceedings of the 2Nd ACM SIGKDD International Workshop on Urban Computing.New York,NY,USA:ACM,2013:2:1–2:9.
[7]劉瑜.社會感知視角下的若干人文地理學基本問題再思考[J].地理學報,2016,71(4):566–577.
[8]ALVARES L O,BOGORNY V,KUIJPERS B等.A Model for Enriching Trajectories with Semantic Geographical Information[C]//Proceedings of the 15th Annual ACM International Symposium on Advances in Geographic Information Systems.New York,NY,USA:ACM,2007:22:1–22:8.
[9]SPACCAPIETRA S,PARENT C,DAMIANI M L等.A conceptual view on trajectories[J].Data&Knowledge Engineering,2008,65(1):126–146.
[10]ZHENG Y,ZHANG L,XIE X等.Mining Interesting Locations and Travel Sequences from GPS Trajectories[C]//Proceedings of the 18th International Conference on World Wide Web.New York,NY,USA:ACM,2009:791–800.
[11]CALABRESE F,PEREIRA F C,LORENZO G D等.The Geography of Taste:Analyzing Cell-Phone Mobility and Social Events[G]//P,A,SPASOJEVIC M.Pervasive Computing.Springer Berlin Heidelberg,2010:22–37.
[12]IOVAN C,OLTEANU-RAIMOND A-M,T等.Moving and Calling:Mobile Phone Data Quality Measurements and Spatiotemporal Uncertainty in Human Mobility Studies[G]//VANDENBROUCKE D,BUCHER B,CROMPVOETS J.Geographic Information Science at the Heart of Europe.Springer International Publishing,2013:247–265.
[13]VAJAKAS T,VAJAKAS J,LILLEMETS R.Trajectory reconstruction from mobile positioning data using cell-to-cell travel time information[J].International Journal of Geographical Information Science,2015,29(11):1941–1954.
[14]WIDHALM P,YANG Y,ULM M等.Discovering urban activity patterns in cell phone data[J].Transportation,2015,42(4):597–623.
技術實現要素:
本發明提供了一種軌跡數據停留識別方法及系統,旨在至少在一定程度上解決現有技術中的上述技術問題之一。
為了解決上述問題,本發明提供了如下技術方案:
一種軌跡數據停留識別方法,包括以下步驟:
步驟a:識別軌跡數據中顯著的停留分段、移動分段和不確定分段;
步驟b:根據生活基本規律及軌跡分段鄰接關系設定所述不確定分段的歸屬類型判定規則,根據所述歸屬類型判定規則判定不確定分段屬于停留分段或移動分段;
步驟c:將所述顯著的停留分段與所述不確定分段判定的停留分段進行合并,得到最終停留分段。
本發明實施例采取的技術方案還包括:在所述步驟a中,所述識別軌跡數據中顯著的停留分段、移動分段和不確定分段具體為:將所述軌跡數據的原始軌跡進行原始軌跡分段處理,在所述原始軌跡分段的基礎上,根據每個分段停留歸屬度,采用增長聚類的方法,分別識別出軌跡數據中顯著的停留分段、移動分段和不確定分段。
本發明實施例采取的技術方案還包括:在所述步驟a中,所述識別停留分段的方式為:從原始軌跡分段的第一個分段開始,連續停留歸屬度均小于閾值ω的原始軌跡分段組成新的軌跡分段,所述新的軌跡分段的停留歸屬度大于閾值ω,同時,所述新的軌跡分段的持續時間大于閾值T0;所述識別移動分段的方式為:如果分段的停留歸屬度小于給定停留歸屬度閾值θ,則其屬于移動分段,從原始分段軌跡的第一個分段開始,將連續的停留歸屬度小于閾值θ的軌跡分段合并,形成一個移動分段。
本發明實施例采取的技術方案還包括:在所述步驟b中,所述根據歸屬類型判定規則判定不確定分段屬于停留分段或移動分段具體包括:如果一個不確定分段與臨近的移動分段一起的持續時間較長,則判定該不確定分段為停留分段;針對“移動-不確定-移動”模式,如果兩段移動方向夾角大于90度,判定該不確定分段為停留分段;針對“停留-不確定-停留”模式,如果“不確定”處于夜間休息時段之內,判定該不確定分段為停留分段。
本發明實施例采取的技術方案還包括:所述步驟b還包括:設定停留歸屬度判定閥值U0,將不適用于所述歸屬類型判定規則的不確定分段的停留歸屬度與歸屬度判定閥值U0進行比較,并將停留歸屬度大于歸屬度判定閥值U0的不確定分段判定為停留分段,將停留歸屬度小于歸屬度判定閥值U0的不確定分段判定為移動分段。
本發明實施例采取的另一技術方案為:一種軌跡數據停留識別系統,包括:
類型識別模塊:用于識別軌跡數據中顯著的停留分段、移動分段和不確定分段;
第一類型判定模塊:用于根據生活基本規律及軌跡分段鄰接關系設定所述不確定分段的歸屬類型判定規則,根據所述歸屬類型判定規則判定不確定分段屬于停留分段或移動分段;
數據合并模塊:用于將所述顯著的停留分段與所述不確定分段判定的停留分段進行合并,得到最終停留分段。
本發明實施例采取的技術方案還包括軌跡分段模塊,所述軌跡分段模塊用于將軌跡數據的原始軌跡進行原始軌跡分段處理;所述類型識別模塊識別軌跡數據中顯著的停留分段、移動分段和不確定分段具體為:將所述軌跡數據的原始軌跡進行原始軌跡分段處理,在所述原始軌跡分段的基礎上,根據每個分段停留歸屬度,采用增長聚類的方法,分別識別出軌跡數據中顯著的停留分段、移動分段和不確定分段。
本發明實施例采取的技術方案還包括:所述類型識別模塊包括停留識別單元和移動識別單元;
所述停留識別單元用于識別軌跡數據中顯著的停留分段,具體識別方式為:從原始軌跡分段的第一個分段開始,連續停留歸屬度均小于閾值ω的原始軌跡分段組成新的軌跡分段,所述新的軌跡分段的停留歸屬度大于閾值ω,同時,所述新的軌跡分段的持續時間大于閾值T0;
所述移動識別單元用于識別軌跡數據中顯著的移動分段,具體識別方式為:如果分段的停留歸屬度小于給定停留歸屬度閾值θ,則其屬于移動分段,從原始分段軌跡的第一個分段開始,將連續的停留歸屬度小于閾值θ的軌跡分段合并,形成一個移動分段。
本發明實施例采取的技術方案:所述第一類型判定模塊根據歸屬類型判定規則判定不確定分段屬于停留分段或移動分段具體包括:如果一個不確定分段與臨近的移動分段一起的持續時間較長,則判定該不確定分段為停留分段;針對“移動-不確定-移動”模式,如果兩段移動方向夾角大于90度,判定該不確定分段為停留分段;針對“停留-不確定-停留”模式,如果“不確定”處于夜間休息時段之內,判定該不確定分段為停留分段。
本發明實施例采取的技術方案還包括第二類型判定模塊,所述第二類型判定模塊用于設定歸屬度判定閥值U0,將不適用于所述歸屬類型判定規則的不確定分段的停留歸屬度與歸屬度判定閥值U0進行比較,并將停留歸屬度大于歸屬度判定閥值U0的不確定分段判定為停留分段,將停留歸屬度小于歸屬度判定閥值U0的不確定分段判定為移動分段。
相對于現有技術,本發明實施例產生的有益效果在于:本發明實施例的軌跡數據停留識別方法及系統首先對顯著的停留和移動分段識別;其次,結合人們生活基本規律和軌跡分段鄰接關系,總結出不確定分段歸屬的判定規則,根據前后的鄰接分段特征,進一步判定不確定分段的歸屬類型;并通過定義停留歸屬度的閾值來決定其他不適用判定規則的不確定分段的歸屬類型,最后,將類型相同的鄰接分段進行合并,實現停留分段的提取。本發明通過引入不確定分段,分步驟識別軌跡數據中的停留,從而降低“假移動”對停留識別的影響,提高識別結果在數量和時間上的準確率和召回率。
附圖說明
圖1是本發明實施例的軌跡數據停留識別的框架圖;
圖2是本發明實施例的軌跡數據停留識別方法的流程圖;
圖3是本發明實施例9種不確定分段關系模式示意圖;
圖4是本發明實施例的軌跡數據停留識別系統的結構示意圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅用以解釋本發明,并不用于限定本發明。
通過觀察手機軌跡數據,部分類別的信息是確定的,例如顯著的停留分段和顯著的移動分段;剩余的難以確切的部分判定為不確定分段,“假移動”也就存在于不確定分段中。不確定分段的不同類別與臨近的移動或停留之間的關系,可以幫助進一步判定該部分數據最可能的類型歸屬。本發明實施例的軌跡數據停留識別方法及系統利用手機軌跡數據的這一特征,構建了引入不確定分段,分步驟識別手機軌跡數據中的停留,從而降低“假移動”對停留識別的影響,提高識別結果在數量和時間上的準確率和召回率。
具體地,請一并參閱圖1和圖2,圖1是本發明實施例的軌跡數據停留識別的框架圖,圖2是本發明實施例的軌跡數據停留識別方法的流程圖。本發明實施例的軌跡數據停留識別方法包括以下步驟:
步驟100:將軌跡數據的原始軌跡進行原始軌跡分段處理;
在步驟100中,軌跡數據中的相關概念包括:記錄數據、原始軌跡、軌跡分段、原始軌跡分段、分段停留歸屬度、移動、停留、不確定分段以及個體分段軌跡等;各個概念的定義如下:
(a)記錄數據(r)
表示形成軌跡的原始記錄數據,表示為三元組<對象編號,時間,空間位置>,表示為r,相應的數學表達如公式(1):
r=<ObjId,t,pt> (1)
在公式(1)中,ObjId為對象編號,t為時間,pt為空間位置。
(b)原始軌跡(RT)
將具有相同對象編號的記錄數據按照時間順序從先到后的方式組織形成的序列定義為原始軌跡,用RT表示,數學上的表達如公式(2):
RT=[r1,r2,…,rn] (2)
在公式(2)中,n為記錄個數,對任意的1<=i<j<=n,記錄rj的時間晚于記錄ri。
(c)軌跡分段(TS)
軌跡分段是個體軌跡的一部分,由多個連續的記錄組成,是原始軌跡的記錄子集,表示為TS。為了便于處理,將軌跡分段表示為一個6元組,數學表達如公式(3)
TS=<UserId,start,end,type,probability,RECORDS> (3)
在公式(3)中,start和end分別是分段開始和結束的時間,type是軌跡分段的類型,在本發明中軌跡分段包括四種類型:空(N)、停留(S)、移動(M)、不確定(U)。在初始狀態下均為N,隨著處理的流程的進行,最終改寫為停留(S)和移動(M)兩種。RECORDS為組成軌跡分段的初始記錄集,不少于兩個元素,probability是當前軌跡分段歸屬為停留分段的可能性,初始通過停留歸屬度函數計算,依賴于RECORDS中點集的最遠距離LD的值,研究室記錄集中點和點之間距離的最大值。具體的計算方式如公式(4):
LD(RECORDS)=max(Dis(ri.pt,rj.pt)),ri,rj∈RECORDS (4)
在公式(4)中,Dis為距離函數。
(d)原始軌跡分段(RTS)
在原始軌跡中,將時間臨近的兩條記錄組成的軌跡分段(TS)稱為原始軌跡分段(RTS),表示的軌跡數據的原始形態,也是軌跡的最精細分段方式,該分段的記錄集個數為2。
(e)分段停留歸屬度(SSP)
軌跡分段的記錄位置之間的最遠距離LD能夠反映出個體在此分段的時間中在空間上移動的最大效果,我們通過這個指標來猜測用戶在這個分段是停留的歸屬度。停留歸屬度函數的選擇應當符合如下的常識性規律:
距離越遠,停留的可能性越小;距離越小,停留的可能性越大;
距離較小時,停留的可能性在較高的水平,隨著距離的進一步減小,SSP增加幅度不大;
距離較大時,停留的可能性在較低的水平,隨著距離的進一步增大,SSP減小幅度不大;
S型(Sigmoid)函數符合上述條件,并廣泛用于各領域的參數選擇,我們用其計算SSP的值。
常用函數中選用sigmoid函數進行計算,閾值確定也是該函數的重要應用領域之一。我們對原始函數進行變換,如公式(5)所表示:
對于這個函數,實際應用中利用具體的要求來確定其具體形式。在實際研究中,選定兩個臨界距離值,賦予相應的歸屬度:距離為D1時,該分段停留歸屬度為α;距離為D2時,其停留歸屬度為β。相應的有公式(6):
SSP(D1)=α
SSP(D2)=β (6)
據此解算可獲得a與b的數值,從而得到計算SSP的具體函數形式。在本發明實施例中,推薦使用的參數為如表1所示,其他應用可根據實際情況進行調整:
表1本發明中停留歸屬度推薦參數
(f)停留(S)
是軌跡分段的子類,表示個體沒有發生移動或在局部范圍內活動,并且持續時間大于設定值T0,表示為一個七元組<ObjId,start,end,type,probability,RECORDS,cenPt>,其中type類型為S,cenPt為中心點。
(g)移動(M)
是軌跡分段的子類,表示該段時間內,個體處于移動的狀態,并且活動范圍超過設定值,表示為一個八元組<UserId,start,end,type,probability,RECORDS,direction,curvature>,其中type類型為M,direction為首末點的坐標方位角,curvature為繞路度,用路徑路程長度與首末點距離比值表示。
(h)不確定分段(U)
是軌跡分段的子類,表示該段時間內,個體的移動狀態既不符合停留的特征,也不具有移動的條件,表示為一個七元組<UserId,start,end,type,probability,RECORDS,pattern>,其中type類型為U。
pattern是不確定分段前后鄰接分段類型關系模式,受限于數據的時間跨度,如果用戶第一個(或最后一個)的分段類型是不確定分段,那么它的前面(或后邊)沒有鄰接分段,我們用空值(N)來表示,這樣一來,關系模式共有九種:SUS,SUM,SUN,MUM,MUS,MUN,NUM,NUS,NUN(S表示停留,M表示移動,N表示空值,U表示不確定),具體如圖3所示,是本發明實施例9種不確定分段關系模式示意圖。
(i)個體分段軌跡(ITSs)
個體的日常生活是由連續的活動組成的,每一個活動對應個體移動軌跡的一個分段,因此可以用分段的方式表示個體的軌跡,這是軌跡分段挖掘的最終目的形式。我們用ITSs來表達這一形式,具體如公式(7):
ITSs=[TS1,TS2,…,TSm] (7)
在公式(7)中,m為分段個數,對任意的1<=i<j<=m,j=i+1,有如下兩個特征:前后分段的時間上是連續的(TSi.end=TSj.start)并且相鄰分段的類型是相異的(TSi.type≠TSj.type)。
當相鄰的兩個分段類型如果一致,需要進行合并的操作,新的軌跡分段TSNew有公式(8)的計算方式:
TSNew=Merge(TSn,TSn+1),with
.start=TSn.start
.end=TSn+1.end
.RECORDS=TSn.RECORDS∪TSn+1.RECORDS
.probability=SSP(diameter(RECORDS)) (8)
若有一個分段對象為空,則合并結果等于不為空的那個對象。
(j)個體原始分段軌跡(RITSs)
不同的分段方案,分段結果不同。在原始軌跡(RT)基礎上,最細密的分段是分成原始軌跡分段(RTS),此時m=n-1,如果將此種分段來表示軌跡,我們將其定義為個體原始分段軌跡,記為RITSs(Raw ITSs),往往作為數據處理的輸入端。
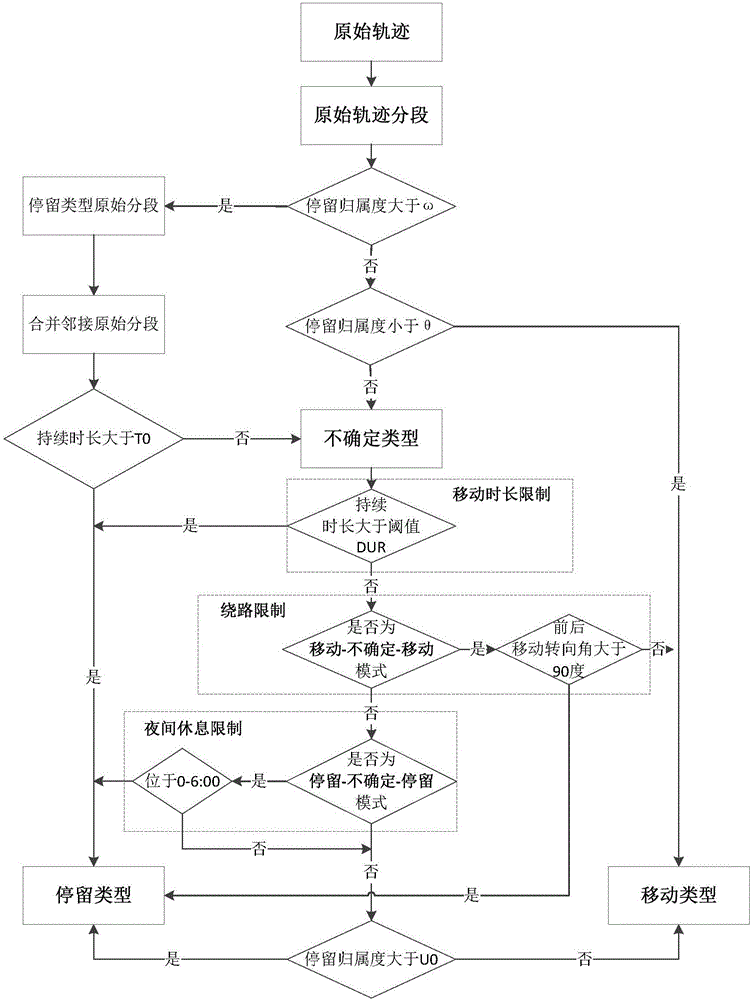
步驟200:在原始軌跡分段的基礎上,根據每個分段停留歸屬度,采用增長聚類的方法,分別識別出軌跡數據中顯著的停留分段、移動分段和不確定分段三種類型;
在步驟200中,在軌跡數據停留識別時,先識別出顯著的停留分段和移動分段,最后提取剩余的部分作為不確定分段。
具體地,識別停留分段的方式為:
停留歸屬度函數是活動范圍的單調遞減函數,停留歸屬度表征了活動范圍的大小。根據停留的定義,停留活動對應的軌跡分段停留歸屬度大于閾值ω,從原始軌跡分段(RTS)的第一個分段開始,符合如下條件的原始軌跡分段(RTS)聚類成一個停留:連續停留歸屬度均小于閾值ω的原始軌跡分段組成新的軌跡分段,而且新的軌跡分段的停留歸屬度也大于閾值ω,同時,軌跡分段的持續時間大于閾值T0。在本發明實施例中,ω取值為0.9,T0取值為10分鐘,具體可根據實際應用進行設定。
識別移動分段的方式為:
與識別停留相似,利用停留歸屬度所反映活動的范圍來判定。根據移動的定義,移動活動對應的個體原始分段軌跡(RITSs)中,如果分段的停留歸屬度小于給定停留歸屬度閾值θ,則其屬于移動分段,從個體原始分段軌跡的第一個分段開始,將連續的停留歸屬度小于閾值θ的軌跡分段合并,形成一個移動。在本發明實施例中,閾值θ取值為0.1,具體可根據實際應用進行設定。
識別不確定分段的方式為:
將個體原始分段軌跡中,提取停留分段和移動分段剩余的部分,根據時間鏈接關系進行合并,即形成不確定分段。在這個過程中,根據記錄點集的位置信息來計算不確定分段的停留歸屬度。
識別出停留分段、移動分段和不確定分段后,它們按照時間順序前后相接,其中移動分段和停留分段具有較高的可信度,可以作為后續判定不確定分段歸屬類型的參考,而每一個不確定分段均有一個停留歸屬度的數值,該數值位于閥值ω和θ之間,根據該數據判定不確定分段的最終歸屬類型。
步驟300:根據移動持續時長、繞路、夜間休息等生活基本規律以及軌跡分段鄰接關系設定不確定分段的歸屬類型判定規則,根據該判定規則判定一部分不確定分段的最終歸屬類型;
在步驟300中,每一個不確定分段都有自己本身的停留歸屬度、開始時間、結束時間和持續時間等信息,同時,根據不同前后分段類型有自己的關系模式,這些信息可以用于輔助判定不確定分段最可能的歸屬。從現實生活角度考慮,本發明實施例用如下規則來判定不確定分段的最終歸屬類型。
(a)移動持續時長限制
現實生活中,除特殊職業人群(如司機、配送員)之外,城市環境中,在局部范圍內持續時間很長(例如2個小時)的移動活動極少,而這些特殊人群有自己典型的活動特征。因此當一個不確定分段與臨近的移動分段一起的持續時間較長的時候,該不確定分段更可能是停留分段。在軌跡數據中,一個移動的持續時間長度受到時間采樣間隔的影響,例如4小時的采樣間隔下,移動行為的最小持續時間也是4小時。對此,選定取2小時與2倍時間采樣間隔中的較大值作為持續時長閾值DUR。例如0.5小時時間采樣間隔的數據,該持續時長閾值為2小時,而1.5小時時間采樣間隔下的數據,該持續時長閾值為3小時。
(b)繞路限制
針對“移動-不確定-移動”(MUM)這種模式,如果兩端的移動方向相反,表明個體先經過移動到特定的位置,而后又以相反的方向回去,這種情況下,相應的不確定分段更可能是停留分段而非移動分段;否則,這段軌跡表示現實世界中的活動過程是一個典型的繞路行為,與人們通常的出行習慣不相符。而如果是方向一致,則表明不確定分段更可能是移動的組成部分,判定為移動分段。在本發明實施例中,針對MUM模式中的不確定分段,如果兩段移動方向夾角大于90度,判定該不確定分段為停留分段;否則,判定該不確定分段為移動分段。
(c)夜間休息限制
人們的休息時間相對較為統一,都是在夜間,同時也呈現出長持續時間的停留,根據這一特點,針對“停留-不確定-停留”(SUS)這種模式,如果U處在早上0:00-6:00的時段之內,判定其中的不確定分段為停留分段。
步驟400:設定停留歸屬度判定閥值U0,將其他不適用于歸屬類型判定規則的不確定分段的停留歸屬度與歸屬度判定閥值U0進行比較,并將停留歸屬度大于歸屬度判定閥值U0的不確定分段判定為停留分段,將停留歸屬度小于歸屬度判定閥值U0的不確定分段判定為移動分段;
在步驟400中,本發明實施例設歸屬度判定閥值U0的值為0.5,具體可根據實際應用進行設定。
步驟500:將步驟200中識別的顯著的停留分段與不確定分段判定的停留分段按照時間特征進行合并,得到軌跡數據中最終的停留分段;
在步驟500中,停留分段的合并公式為:根據公式(8)進行合并。
請參閱圖4,是本發明實施例的軌跡數據停留識別系統的流程圖。本發明實施例的軌跡數據停留識別系統包括軌跡分段模塊、類型識別模塊、第一類型判定模塊、第二類型判定模塊和數據合并模塊。
軌跡分段模塊用于將軌跡數據的原始軌跡進行原始軌跡分段處理;其中,不同的分段方案,分段結果不同。在原始軌跡(RT)基礎上,最細密的分段是分成原始軌跡分段(RTS),此時m=n-1,如果將此種分段來表示軌跡,我們將其定義為個體原始分段軌跡,記為RITSs(Raw ITSs),往往作為數據處理的輸入端。
類型識別模塊用于在原始軌跡分段的基礎上,根據每個分段停留歸屬度,采用增長聚類的方法,分別識別出軌跡數據中顯著的停留分段、移動分段和不確定分段三種類型;其中,在軌跡數據停留識別時,先識別出顯著的停留分段和移動分段,最后提取剩余的部分作為不確定分段。
具體地,類型識別模塊包括停留識別單元、移動識別單元和不確定識別單元;
停留識別單元用于識別軌跡數據中顯著的停留分段,具體識別方式為:停留歸屬度函數是活動范圍的單調遞減函數,停留歸屬度表征了活動范圍的大小。根據停留的定義,停留活動對應的軌跡分段停留歸屬度大于閾值ω,從原始軌跡分段(RTS)的第一個分段開始,符合如下條件的原始軌跡分段(RTS)聚類成一個停留:連續停留歸屬度均小于閾值ω的原始軌跡分段組成新的軌跡分段,而且新的軌跡分段的停留歸屬度也大于閾值ω,同時,軌跡分段的持續時間大于閾值T0。在本發明實施例中,ω取值為0.9,T0取值為10分鐘,具體可根據實際應用進行設定。
移動識別單元用于識別軌跡數據中顯著的移動分段,具體識別方式為:與識別停留相似,利用停留歸屬度所反映活動的范圍來判定。根據移動的定義,移動活動對應的個體原始分段軌跡(RITSs)中,如果分段的停留歸屬度小于給定停留歸屬度閾值θ,則其屬于移動分段,從個體原始分段軌跡的第一個分段開始,將連續的停留歸屬度小于閾值θ的軌跡分段合并,形成一個移動。在本發明實施例中,閾值θ取值為0.1,具體可根據實際應用進行設定。
不確定識別單元用于識別軌跡數據中的不確定分段,具體識別方式為:將個體原始分段軌跡中,提取停留分段和移動分段剩余的部分,根據時間鏈接關系進行合并,即形成不確定分段。在這個過程中,根據記錄點集的位置信息來計算不確定分段的停留歸屬度。
識別出停留分段、移動分段和不確定分段后,它們按照時間順序前后相接,其中移動分段和停留分段具有較高的可信度,可以作為后續判定不確定分段歸屬類型的參考,而每一個不確定分段均有一個停留歸屬度的數值,該數值位于閥值ω和θ之間,根據該數據判定不確定分段的最終歸屬類型。
第一類型判定模塊用于根據移動持續時長、繞路、夜間休息等生活基本規律以及軌跡分段鄰接關系設定不確定分段的歸屬類型判定規則,根據該判定規則判定一部分不確定分段的最終歸屬類型;其中,每一個不確定分段都有自己本身的停留歸屬度、開始時間、結束時間和持續時間等信息,同時,根據不同前后分段類型有自己的關系模式,這些信息可以用于輔助判定不確定分段最可能的歸屬。從現實生活角度考慮,本發明實施例用如下規則來判定不確定分段的最終歸屬類型。
(a)移動持續時長限制
現實生活中,除特殊職業人群(如司機、配送員)之外,城市環境中,在局部范圍內持續時間很長(例如2個小時)的移動活動極少,而這些特殊人群有自己典型的活動特征。因此當一個不確定分段與臨近的移動分段一起的持續時間較長的時候,該不確定分段更可能是停留分段。在軌跡數據中,一個移動的持續時間長度受到時間采樣間隔的影響,例如4小時的采樣間隔下,移動行為的最小持續時間也是4小時。對此,選定取2小時與2倍時間采樣間隔中的較大值作為持續時長閾值DUR。例如0.5小時時間采樣間隔的數據,該持續時長閾值為2小時,而1.5小時時間采樣間隔下的數據,該持續時長閾值為3小時。
(b)繞路限制
針對“移動-不確定-移動”(MUM)這種模式,如果兩端的移動方向相反,表明個體先經過移動到特定的位置,而后又以相反的方向回去,這種情況下,相應的不確定分段更可能是停留分段而非移動分段;否則,這段軌跡表示現實世界中的活動過程是一個典型的繞路行為,與人們通常的出行習慣不相符。而如果是方向一致,則表明不確定分段更可能是移動的組成部分,判定為移動分段。在本發明實施例中,針對MUM模式中的不確定分段,如果兩段移動方向夾角大于90度,判定該不確定分段為停留分段;否則,判定該不確定分段為移動分段。
(c)夜間休息限制
人們的休息時間相對較為統一,都是在夜間,同時也呈現出長持續時間的停留,根據這一特點,針對“停留-不確定-停留”(SUS)這種模式,如果U處在早上0:00-6:00的時段之內,判定其中的不確定分段為停留分段。
第二類型判定模塊用于設定停留歸屬度判定閥值U0,將其他不適用于歸屬類型判定規則的不確定分段的停留歸屬度與歸屬度判定閥值U0進行比較,并將停留歸屬度大于歸屬度判定閥值U0的不確定分段判定為停留分段,將停留歸屬度小于歸屬度判定閥值U0的不確定分段判定為移動分段;其中,本發明實施例設歸屬度判定閥值U0的值為0.5,具體可根據實際應用進行設定。
數據合并模塊用于將類型識別模塊識別的顯著的停留分段與經第一類型判定模塊和第二類型判定模塊判定的停留分段按照時間特征進行合并,得到軌跡數據中最終的停留分段;其中,停留分段的合并公式為:
TSNew=Merge(TSn,TSn+1),with
.start=TSn.start
.end=TSn+1.end
.RECORDS=TSn.RECORDS∪TSn+1.RECORDS
.probability=SSP(diameter(RECORDS)) (8)
本發明實施例利用深圳市某通信公司的手機軌跡數據進行了實驗。實驗選擇了329個具有高頻采樣手機軌跡數據的用戶作為基準數據集。考慮到在高頻采樣下,通過軌跡數據僅僅用來判定停留或移動狀態,還是具有很高的可信度的,因此人工對每個用戶的停留和移動信息進行了判定,標記了相應的開始與結束時間。然后,對該基準數據按照不同的時間采樣間隔進行重采樣,模擬真實的手機定位數據規格。
分別從狀態和對象兩個角度對結果進行評估。從狀態的角度,對識別結果中的每一個停留,在標記結果的停留中遍歷搜尋其空間上臨近的停留,計算重疊時間總和,根據時間總和與標記結果中停留總時間的比例記為召回率,與識別結果中停留總時間的比例記為準確率。從對象的角度,對識別結果中的每一個停留,如果在標識結果中的停留存在滿足以下三個條件的停留,認為該停留判斷正確:(1)空間上臨近;(2)時間上重疊;(3)停留對象在時間上的重疊是“一對一”的關系。符合該三個條件的停留個數與標記結果的停留個數比例記為對象召回率,與識別結果的停留個數比例記為對象的準確率。
利用本發明的方法(SMUoT)和SNSoT的方法進行識別,結果如表2所示。其中,在0.5小時采樣間隔下,本發明的方法在停留的數量角度的準確率提高了28個百分點,召回率提供了21個百分點;而在時間角度的準確率達到97%的準確率,相對于SNSoT降低了2個百分點,但召回率提高了13個百分點。而在2小時的采樣間隔下,改善效果有限,主要原因在于此情況下,軌跡數據過于稀疏,方法的區別較小。但總體而言,結果表明,相較于既有的停留識別方法,本發明提供的技術方案顯著改善了停留識別的效果。
表2 SNSoT與SMUoT結果比較
本發明實施例的軌跡數據停留識別方法及系統首先對顯著的停留和移動分段識別;其次,結合人們生活基本規律和軌跡分段鄰接關系,總結出不確定分段歸屬的判定規則,根據前后的鄰接分段特征,進一步判定不確定分段的歸屬類型;并通過定義停留歸屬度的閾值來決定其他不適用判定規則的不確定分段的歸屬類型,最后,將類型相同的鄰接分段進行合并,實現停留分段的提取。本發明通過引入不確定分段,分步驟識別軌跡數據中的停留,從而降低“假移動”對停留識別的影響,提高識別結果在數量和時間上的準確率和召回率。
對所公開的實施例的上述說明,使本領域專業技術人員能夠實現或使用本發明。對這些實施例的多種修改對本領域的專業技術人員來說將是顯而易見的,本文中所定義的一般原理可以在不脫離本發明的精神或范圍的情況下,在其它實施例中實現。因此,本發明將不會被限制于本文所示的這些實施例,而是要符合與本文所公開的原理和新穎特點相一致的最寬的范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!