一種利用多來源數據具有隱私保護功能的圖象分類方法與流程
本發明涉及圖象特征抽取、應用技術,圖象分類技術,特別涉及一種基于從圖象抽取多組特征之間關系的圖象識別方法以及保護圖象具體特征提取方法的隱私保護技術。
背景技術:
目前,隨著多媒體技術的發展和智能設備的普及,圖象信息的獲取日益便捷,同時,對于圖象的分類需求也日益提高,如使用只能手機拍照之后,需要對照片進行分類;機器人對物體進行識別時,也會用到圖像識別技術;在網絡搜索圖象時也有相關技術的需求。
目前圖象分類的流程主要是先針對圖象提取特征,之后使用某些分類器進行分類。對于圖象進行標記十分昂貴,需要花費大量的人力資源,而從互聯網上獲取圖象十分便捷,但是獲取到的都是沒有標記的圖象。對于一幅圖象,可以有多種不同類型的特征屬性集合:如可以使用不同圖象特征提取方法對圖象進行特征抽取,每一種方法抽取到的特征構成一個屬性集;網絡上一幅圖象往往配有文字、視頻等其它多媒體資源,從這些附帶的資源中也可以提取出特征;智能手機配備多個傳感器,使用手機拍一張照片,其它傳感器可以提供時間、溫度、光照強度等信息,這些信息也可以輔助圖象的分類。傳統的方法一方面需要獲取有標記的圖象進行分類器的訓練,一方面依賴于特定的特征,無法較好地利用未標記圖象和多組不同的圖象特征屬性集。
圖象分類往往也是多個公司、研究組織的共同需求。不同的公司或者研究組織會針對其獲取的數據使用他們自己的方法提取特征,之后根據他們提取的特征進行分類器的訓練。將多個公司(組織)的特征進行結合,無疑可以得到更好的特征,但是各組特征涉及多個公司(組織)的隱私信息,如提取特征的具體技術,這些往往不適合和他人共享,因此需要一種具有隱私保護的利用不同特征進行圖象分類的方法。
技術實現要素:
:
發明目的:目前關于圖象分類的算法往往依賴于有標記的圖象,或者只針對 圖象的某一類屬性集,同時已有的方法幾乎沒有考慮過在“競爭-合作”的場景下對每一個數據來源的特征進行隱私保護,針對上述問題,本發明提出一種利用多來源數據具有隱私保護功能的圖象分類方法,將圖像的多個特征集合看作多個視圖,通過利用視圖之間的相關性提升圖象分類的性能。
技術方案:一種利用多來源數據具有隱私保護功能的圖象分類方法,首先針對圖象收集(提取)不同類型的特征屬性,將每一組特征看作一個視圖,每一個視圖上訓練一個分類器,對圖象的結果進行預測,要求在有標記數據上預測的結果和真實的結果相同;在之后的訓練過程中,要求不同視圖的預測結果盡可能相近,使得預測性能強的視圖能夠輔助其它的視圖,從而提升每一個視圖以及綜合的分類結果;最后利用在迭代訓練過程中得到的分類器在每一個視圖上進行圖象分類。本發明方法可分為圖象分類模型訓練步驟和圖象分類模型分類步驟,具體如下:
所述圖象分類模型的訓練步驟具體為:
步驟100,從不同的k個數據源獲取圖象特征屬性集,將每一個屬性集看作一個視圖;
步驟101,在每一個視圖上利用本視圖的特征屬性訓練分類器,得到每一個視圖上對所有樣本的預測結果,訓練過程中要求在有標記樣本上每一個分類器的預測結果和真實標記相同;
步驟102,將每個視圖對所有圖象的預測結果收集,拼接成一個矩陣(apm),優化該矩陣的秩,使每一個視圖的預測結果盡可能一致;
步驟103,判斷每一個視圖預測拼接構成的矩陣秩是否滿足要求,如果否,則轉入步驟101,繼續分類器的訓練;如果是,則通過該矩陣重構分類器,即每一個視圖最終的預測結果根據該視圖上的特征構造出針對該視圖的分類器wk確定。
所述圖象分類模型的分類步驟具體為:
步驟200,從不同的k個數據源獲取圖象特征屬性集,將每一個屬性集看作一個視圖;
步驟201,利用訓練過程中在每一個視圖上得到的分類器wk對每一個視圖上 的圖象進行分類;
步驟202,判斷是否需要綜合每一個視圖進行圖象分類,如果否,則獲得每一個視圖上的分類結果;如果是,則收集每一個視圖的分類結果,將其進行融合,得到綜合的分類結果。
所述步驟100從不同的k個數據源獲取圖象特征屬性集的方法包括使用不同的特征提取方法對圖象進行特征提取、使用網絡上的附帶信息作為其它數據源和從真實存在的多數據源(如多傳感器)提取特征等。
所述步驟101在每一個視圖上利用本視圖的特征屬性訓練分類器具體方法為:在每一個視圖上構建線性分類器wk,分類器的維度同時取決于圖象類別的數目c和該視圖特征屬性集的維度dk,使用最小二乘方法在有標記樣本上使得分類器的預測結果和真實的結果盡可能相似,具體公式如下:
其中,bk為每個視圖上的分類偏置,γ為參數,fk是分類器的輸出。
所述步驟102使每一個視圖的預測結果盡可能一致的具體方法為:在每一個視圖上對訓練集中所有圖象進行類別的預測,得到預測結果fk,其維度同時取決于訓練集中圖象的數目和類別數目,將所有視圖的預測結果拼接,得到一個擴展的矩陣表示apm,使各個視圖的預測結果一致即優化apm的秩,使其盡可能低秩。優化目標及使得apm的秩為c-1,和理想情況下的秩相同。
所述優化apm的秩方法為優化apm的截斷核范數的方法,包括加速近端梯度方法和交替方向乘子法,具體優化方法如下:
其中,lk為最小二乘損失函數,fk是第k個視圖上分類器的輸出,||f||r是擴展矩陣apm的截斷核范數,集合d為可用分類器集合,在本申請中d為帶偏置的線性分類器集合。
所述步驟201利用訓練過程中在每一個視圖上得到的分類器wk對每一個視圖上的圖象進行分類的具體方法為:將該視圖上某一幅圖象的特征和wk做內積運算,得到一個長為c的向量,其中每一個元素表示分類到每一個類的置信度,圖象分類過程即把當前圖象分類為置信度最高的一類。
所述步驟202將各類別的預測結果融合,具體是指使用某些集成方法(如多個預測結果投票)得到最終的預測。
有益效果:與現有技術相比,本發明所提供的利用多數具有的圖象分類方法,實施過程中能夠充分利用有標記數據和未標記數據上不同數據源的多種特征屬性,適合數據源很多的情況,同時在整個訓練過程中能夠確保每一個數據源的特征屬性不被其它數據源所獲取。
附圖說明
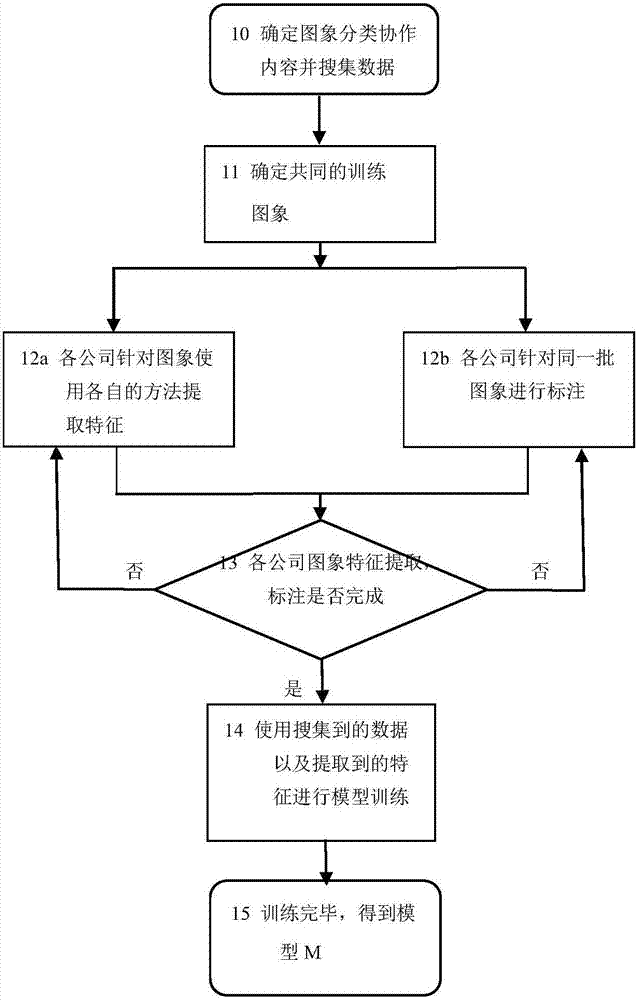
圖1是本發明的圖象分類模型訓練階段的工作流程圖;
圖2是本發明的圖象分類模型分類階段的工作流程圖;
圖3是本發明的訓練圖象分類模型m的工作流程圖。
具體實施方式
下面結合具體實施例,進一步闡明本發明,應理解這些實施例僅用于說明本發明而不用于限制本發明的范圍,在閱讀了本發明之后,本領域技術人員對本發明的各種等價形式的修改均落于本申請所附權利要求所限定的范圍。
圖象分類模型訓練階段的工作流程如圖1所示。圖象分類模型在訓練階段需要收集一定數量的帶標記和大量不帶標記的圖象用于訓練,具體來說,以公司之間“競爭-合作”為例,首先不同的公司確定對于同一個任務(對于某一類型的圖象分類任務)進行協作,從網絡上收集大量數據(步驟10);然后不同公司確定針對相同一部分的圖象進行模型的訓練(可以某一方搜集圖象然后共享,或者由各公司都從同一數據源獲取圖象,步驟11);各個公司使用其自己的方法進行對搜集到的圖象進行特征提取(步驟12a),并對同一批圖象進行類別的標注(步驟12b)。判斷各公司搜集數據、對數據的特征提取是否完成(步驟13),如果否,等待所有公司數據準備完成;如果是,則各公司使用搜集到的數據以及提取到的特征進行模型訓練(步驟14),最終得到模型m(步驟15),包含每一個類別的 分類器wk,用于每一個公司的圖象分類。
圖象分類模型分類工作階段的工作流程如圖2所示。首先各個公司獲取訓練過程中得到的針對每一個公司(每個視圖)的圖象分類器wk(步驟16),然后判定各公司之間是否存在進一步協作(步驟17),即是否需要綜合多個公司的預測結果提供最終的圖象分類結果,如果是,則將圖象分發給各個公司或各公司收集同一批圖象(步驟18b),各公司使用自己的對應的特征提取技術對該圖象提取特征(步驟19b),之后使用各公司的分類器進行判定,得到預測結果(步驟20b),最后將這些預測結果進行集成,得到最終的綜合的預測結果(步驟21)。如果各公司獨立分類,則各個公司分別收集新的數據,這里不要求不同公司搜集的圖象相同,也不要求不同公司要同步操作(步驟18a);對于每一個公司,每當搜集到一個(一批)圖象,使用訓練過程中同樣的方法對該(批)圖象進行特征提取,得到圖象的特征(步驟19a);最后,公司使用自己的分類器對圖像特征進行類別判定,分類結果為置信度最高的一個類別(步驟20a)。注:在圖象分類過程中,各個公司對于數據獨立處理,但要保證使用訓練過程中相同的方式對圖象提取特征。
訓練圖象分類模型m的工作流程如圖3所示。首先各公司使用各自的特征提取方法對圖象進行特征提取,獲取到的數據記為x1,x2,…,xk(步驟141);然后每個公司在有標記的圖象上分別訓練一個線性分類器w1,w2,…,wk(步驟142);各公司使用訓練好的分類器對所有樣本的標記進行預測,得到的預測結果分別為f1,f2,…,fk(步驟143);將各個公司的預測結果集中到一個中間結點,拼接成一個矩陣(步驟144),在中間結點對該矩陣進行優化,得到更好的預測結果矩陣apm,通過優化該矩陣的秩實現(步驟145);將更新之后的預測結果分別傳給各個公司(步驟146);判斷各公司的預測結果是否足夠好(步驟147),如果否,則返回步驟,繼續訓練;如果是,則停止,各公司通過預測結果fk更新分類器wk,各公司得到各自的分類器(步驟148)。注:在訓練過程中,中心結點只獲取各個公司針對圖象的預測結果,不需要獲取各個公司提取到的圖象特 征,保護了各公司圖象提取技術的隱私性。在實現中,通過優化apm的秩來對預測結果更新,使用優化apm的截斷核范數的方法實現,具體有加速近端梯度方法和交替方向乘子法等。
- 還沒有人留言評論。精彩留言會獲得點贊!