一種自適應調整助聽器接收聲音的方法與流程
本發明涉及智能助聽,特別是一種自適應調整助聽器接收聲音的方法。
背景技術:
1、在當代助聽設備領域,隨著傳感技術與人工智能的飛速發展,助聽器正逐步邁向智能化與個性化的新紀元,傳統的助聽器雖能輔助聽力受損人士改善交流障礙,但其性能受限于靜態的噪聲抑制與固定的聲音放大模式,往往無法適應用戶在不同環境與活動狀態下的多樣化需求,近年來,集成傳感器和深度學習算法的智能助聽器,展現出動態調整增益與反饋抑制的巨大潛力,極大地提升了用戶在復雜環境下的聽力體驗與舒適度。
2、然而,現有技術仍存在顯著局限,一方面,大多數助聽器的噪聲抑制策略較為單一,難以有效區分并適應不同類型環境噪聲的特性,尤其是在交通噪音、社交場合等高變異性噪聲環境下,其性能顯著下降,另一方面,反饋抑制機制常因固定閾值設置,而在用戶活動狀態變化時出現過度或不足的抑制現象,導致聲音失真或反饋嘯叫,嚴重影響了聽力補償的質量與用戶的使用體驗,鑒于此,急需一種能夠實時監測用戶行為與環境噪聲,并據此自適應調整接收聲音策略的創新方法,以填補現有技術空白,實現更精細、更智能的聽力輔助功能。
技術實現思路
1、鑒于上述現有存在的問題,提出了本發明。
2、因此,本發明提供了一種自適應調整助聽器接收聲音的方法解決傳統助聽器在環境適應性、個性化體驗、噪聲抑制和反饋控制不足問題。
3、為解決上述技術問題,本發明提供如下技術方案:
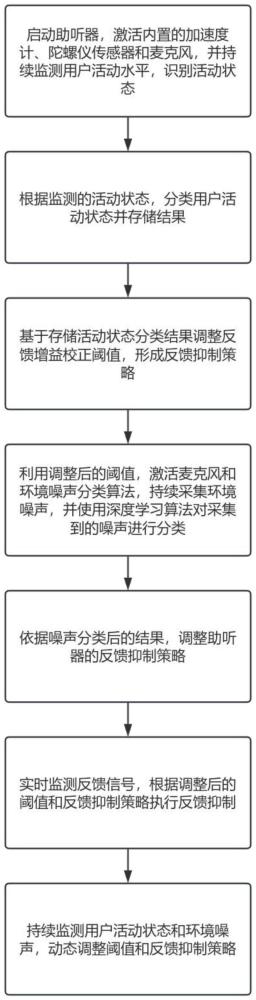
4、第一方面,本發明實施例提供了一種自適應調整助聽器接收聲音的方法,其包括,啟動助聽器,激活內置的加速度計、陀螺儀傳感器和麥克風,并持續監測用戶活動水平,識別活動狀態;根據監測的活動狀態,分類用戶活動狀態并存儲結果;基于存儲活動狀態分類結果調整反饋增益校正閾值,形成反饋抑制策略;利用調整后的閾值,激活麥克風和環境噪聲分類算法,持續采集環境噪聲,并使用深度學習算法對采集到的噪聲進行分類;依據噪聲分類后的結果,調整助聽器的反饋抑制策略;實時監測反饋信號,根據調整后的閾值和反饋抑制策略執行反饋抑制;持續監測用戶活動狀態和環境噪聲,動態調整閾值和反饋抑制策略。
5、作為本發明所述自適應調整助聽器接收聲音的方法的一種優選方案,其中:所述啟動助聽器,激活內置的加速度計、陀螺儀傳感器和麥克風,并持續監測用戶活動水平,識別活動狀態,具體步驟為:
6、啟動助聽器,系統自動激活內置的加速度計傳感器、陀螺儀傳感器以及麥克風;
7、初始化環境噪聲分類算法和用戶活動識別組件,準備采集實時數據;
8、加速度計傳感器和陀螺儀傳感器開始持續監測用戶活動水平,麥克風采集環境噪聲,采集數據包括用戶的運動狀態;
9、將速度計傳感器和陀螺儀傳感器提供的信息通過預處理轉換為可識別的活動狀態;
10、分析加速度計和陀螺儀數據,識別用戶當前活動狀態。
11、作為本發明所述自適應調整助聽器接收聲音的方法的一種優選方案,其中:所述根據監測的活動狀態,分類用戶活動狀態并存儲結果,具體步驟為:
12、通過加速度計和陀螺儀數據,采用活動狀態識別算法分析用戶當前的活動狀態,表達式為:
13、
14、其中,s(t)表示在任意給定時刻t,系統識別到的用戶活動狀態值,表示在時刻t,加速度計在x、y、z三個軸上測量得到的加速度值ai(t)的平方和,i代表加速度計測量值的索引,表示在時刻t,陀螺儀在x、y、z三個軸上測量得到的角速度值ωj(t)的平方和,j代表陀螺儀測量值的索引,表示在時刻t,加速度和角速度值的四次方和;
15、將識別出的活動狀態分類并存儲,定義為st(s(t))存儲函數記錄每個時刻的活動狀態,表達式為:
16、st(s(t))=sa(s(t),t);
17、其中,st(s(t))表示存儲值,sa是存儲活動狀態的函數,sa(s(t),t)表示存儲活動狀態的具體函數。
18、作為本發明所述自適應調整助聽器接收聲音的方法的一種優選方案,其中:所述基于存儲活動狀態分類結果調整反饋增益校正閾值,形成反饋抑制策略,具體步驟為:
19、根據存儲的活動狀態,使用反饋增益校正算法fgca(s(t))來調整反饋增益校正閾值,表達式為:
20、
21、其中,fis(t)表示在時刻t的反饋抑制策略值,代表基于高斯函數,用于根據環境噪聲類型值nt來調整反饋抑制策略值,exp代表指數函數,σ是一個標準差參數,表示基于對數函數,用于根據反饋增益校正閾值threshold(t)來調整反饋抑制策略值,log代表對數函數,threshold(t)表示在時刻t的反饋增益校正閾值,η是一個閾值影響程度的參數,用于控制對數函數的斜率。
22、作為本發明所述自適應調整助聽器接收聲音的方法的一種優選方案,其中:所述利用調整后的閾值,激活麥克風和環境噪聲分類算法,持續采集環境噪聲,并使用深度學習算法對采集到的噪聲進行分類,具體步驟為:
23、根據調整反饋增益校正后的閾值,麥克風持續運行,使用環境噪聲分類算法采集環境噪聲信號;
24、使用帶通濾波器來處理噪聲信號,表達式為:
25、
26、其中,bp(n(t))代表的是經過帶通濾波器處理后的噪聲信號值,n(t)是采集到的噪聲信號,f是信號頻率,fc是中心截止頻率,n是濾波器階數;
27、使用深度學習模型dl對經過帶通濾波器處理后的噪聲信號bp(n(t))進行分類,表達式為:
28、cn(bp(n(t)))=dl(bp(n(t)));
29、其中,cn表示噪聲分類值,bp(n(t))代表的是經過帶通濾波器處理后的噪聲信號值。
30、作為本發明所述自適應調整助聽器接收聲音的方法的一種優選方案,其中:所述依據噪聲分類后的結果,調整助聽器的反饋抑制策略,具體步驟為:
31、基于噪聲類型nt和當前活動狀態s(t),調整反饋抑制策略fis(t),表達式為:
32、fis(t)'=pa(fis(t),nt,s(t));
33、策略調整函數,表達式為:
34、pa(fis(t),nt,s(t))=α·fis(t)+β·φ(nt)+γ·ψ(s(t));
35、其中,fis(t)′是調整后的反饋抑制策略值,pa是策略調整函數,α·fis(t)是基于先前反饋抑制策略fis(t)的權重調整值,α是調整系數,β·φ(nt)是基于噪聲類型nt的調整值,β是噪聲類型影響系數,φ(nt)是噪聲類型轉換函數,γ·ψ(s(t))是基于用戶活動狀態s(t)的調整值,γ是活動狀態影響系數,ψ(s(t))是活動狀態轉換函數。
36、作為本發明所述自適應調整助聽器接收聲音的方法的一種優選方案,其中:所述實時監測反饋信號,根據調整后的閾值和反饋抑制策略執行反饋抑制,具體步驟為:
37、確定調整后的反饋抑制策略后,助聽器內部反饋檢測電路和軟件算法持續監聽輸出音頻信號,尋找反饋信號;
38、一旦檢測到反饋信號,助聽器立即啟動反饋抑制機制,表達式為:
39、o(t)=fia(fs,fis(t)');
40、其中,o(t)表示在時刻t的輸出音頻信號值,fia代表反饋抑制算法,fs表示檢測到的反饋信號值。
41、作為本發明所述自適應調整助聽器接收聲音的方法的一種優選方案,其中:所述持續監測用戶活動狀態和環境噪聲,動態調整閾值和反饋抑制策略,具體步驟為:
42、將助聽器的傳感器和麥克風進行持續運行,監測用戶活動狀態和環境噪聲;
43、根據最新的活動狀態和噪聲類型,重新計算反饋增益校正閾值和反饋抑制策略;
44、助聽器持續監測活動狀態和噪聲類型,根據最新的數據動態調整閾值和抑制策略。
45、第二方面,本發明實施例提供了一種計算機設備,包括存儲器和處理器,所述存儲器存儲有計算機程序,其中:所述計算機程序被處理器執行時實現如本發明第一方面所述的自適應調整助聽器接收聲音的方法的任一步驟。
46、第三方面,本發明實施例提供了一種計算機可讀存儲介質,其上存儲有計算機程序,其中:所述計算機程序被處理器執行時實現如本發明第一方面所述的自適應調整助聽器接收聲音的方法的任一步驟。
47、本發明有益效果為:本發明通過一系列創新性的步驟,不僅顯著增強了助聽器的個性化和智能適應性,還大幅提升了設備在復雜環境下的噪聲處理能力,實現了聲音接收策略的自適應優化,具體而言,通過傳感器數據的高效處理和智能算法的應用,本發明能夠精準識別用戶活動狀態,動態調整反饋增益校正閾值,智能分類環境噪聲,有效抑制反饋嘯叫,從而為聽力受損用戶提供了更加舒適、清晰、穩定的聽力體驗,顯著改善了其在日常生活和社交活動中的溝通質量。
- 還沒有人留言評論。精彩留言會獲得點贊!