一種基于強化學習的網絡擁塞路由選擇方法
本發明屬于強化學習決策和網絡通信領域,尤其涉及一種基于強化學習的網絡擁塞路由選擇方法。
背景技術:
1、在當今多變的社會環境下,強化學習已被廣泛應用于各種場景,成為實現動態決策規劃的高效方式。強化學習的核心是智能體在特定環境中采取行動,以最大化累積獎勵為目標,作為一種基于智能體與環境互動的學習模式,強化學習已經在多個領域展現出巨大潛力,并且在智能系統領域取得了顯著進展。
2、目前針對網絡路由擁塞問題主要采用負載均衡方法進行解決,負載均衡技術將網絡流量分布到多個路由路徑上,以避免某些路徑過載而導致擁塞,其可以通過動態路由協議或專用的負載均衡設備來實現。然而這種傳統負載均衡解決網絡路由擁塞的方式受固定規則限制,以固定的分配策略將網絡流量分布到多個路由路徑,難以滿足復雜多變的實際網絡場景。
技術實現思路
1、本發明針對網絡擁塞路由選擇所存在的技術問題,提出一種設計合理、方法簡單、理論性強且能夠解決傳統負載均衡,解決網絡路由擁塞的方式的固定限制的一種基于強化學習的網絡擁塞路由選擇方法。
2、為了達到上述目的,本發明采用的技術方案為:一種基于強化學習的網絡擁塞路由選擇方法,其特征在于,包括如下步驟:
3、s1:理論建模,對離散動作空間的網絡路由決策分析,圍繞強化學習要素進行建模,所述強化學習要素包括智能體、動作、環境、獎勵以及狀態;
4、s2:數據獲取,隨機選取中間路由節點和到達該階段的線路,依據數據傳輸效率和路由擁塞范式,獲取多樣性數據;
5、s3:搭建模型,綜合s2數據獲取和s1理論建模,借鑒ddpg框架,搭建網絡路由決策強化學習模型,依據深度確定性策略,采用線性神經網絡來逼近策略函數;
6、s4:模型訓練與驗證,用s2獲取的多樣性數據訓練s3獲得的網絡路由決策強化學習模型,并驗證網絡路由決策強化學習模型的有效性。
7、作為優選,所述s1步驟的具體操作方法為:
8、s1-1:網絡路由決策分析理論模型包括智能體a為網絡路由決策模型、動作a為中間路由節點和線路選擇、環境e為路由和線路擁塞狀態、獎勵r為數據傳輸效率以及狀態s,依據路由和線路擁塞狀態引導智能體做出初步動作;
9、s1-2:決策動作空間包含,中間路由節點和中間線路,其中中間路由節點表示為ki,i∈[1,n],其中i表示為中間路由節點編號,n為全部中間路由節點總數,中間線路表示為i∈[1,n],j∈[1,m],其中i→i’表示為中間線路屬于那兩個節點間的線路,j為兩個節點間的線路編號,m為兩個節點間線路總數;
10、s1-3:依據步驟s1-2的命名方式,線路1可以表示為線路2可以表示為線路3可以表示為并且k,r皆為離散數據;
11、s1-4:智能體a根據環境狀態s來決定下一步動作a的策略函數定義為π(a|s),即網絡路由決策動作的選取策略;
12、s1-5:定義v(s)用于衡量狀態s的獎勵價值,定義q(s,a)用于衡量動作a的獎勵價值,從當前狀態s按照策略π選取動作a,最終進入下一狀態,所獲取的總獎勵定義如公式1所示:
13、v(s)=∑π(a|s)q(s,a)?(1)
14、s1-6:引入折扣率β∈[0,1]來降低遠期回報的權重,當β接近0時,智能體更注重短期回報,當β接近1時,智能體更注重長期回報,β定義為公式2:
15、
16、其中,t為決策輪次;
17、s1-7:單決策輪次獎勵依據數據傳輸效率定義為則動作a的獎勵價值q(s,a)與下一狀態s,的獎勵價值v(s,)的關系定義為公式3:
18、q(s,a)=rt+∑βv(s,)?(3)
19、s1-8:依據步驟s1-5和s1-7,可以得出衡量當前動作a的獎勵價值q(s,a)與下一動作a,的獎勵價值q(s,,a,)兩者間的關系,如公式4所示:
20、q(s,a)=rt+∑β∑π(a,|s,)q(s,,a,)?(4)
21、作為優選,所述s2步驟的具體操作方法為:
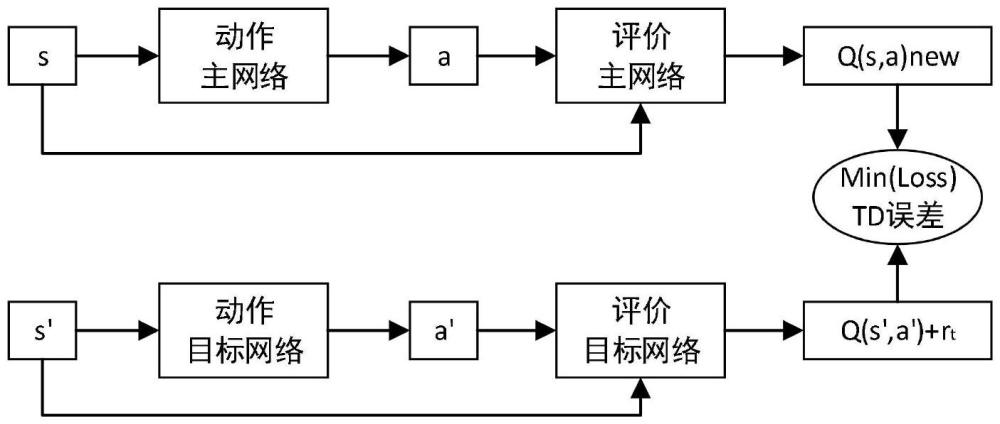
22、s2-1:依據步驟s1-4,對中間路由節點和中間線路進行隨機選取,后經過步驟s1-8公式4給出最終的動作獎勵;
23、s2-2:重復步驟s2-1,最終獲得數據集d,數據集中包含當前中間路由節點和中間線路的選擇情況,即當前狀態s,數據集中還包含獎勵rt、下一個狀態s,,數據集d的定義如公式5所示:
24、d=[s,a,rt,s,]?(5)
25、s2-3:將數據集d放入經驗池用于后續模型訓練。
26、作為優選,所述s3步驟的具體操作方法為:
27、s3-1:搭建網絡路由決策強化學習模型,借鑒ddpg框架,網絡拆分為動作主網絡、動作目標網絡、評價主網絡以及評價目標網絡,其中主網絡是需要訓練的參數更新的網絡,目標網絡是參數凍結的推理網絡;
28、s3-2:網絡第一層結構由自注意力機制的transformerencode構成,后續層均由跨層交叉注意力機制的transformerencode構成,其中第一層自注意力機制中的q、k、v均來自于同一輸入,其余層交叉注意力機制中的q自于上一層的輸入,k、v來自于上一層的輸出,通過注意力機制挖掘各個決策行動間的制約關系,同時引入跨層殘差機制預防梯度消失。
29、作為優選,所述s4步驟的具體操作方法為:
30、s4-1:訓練評價主網絡權重θ,從經驗池中選取樣本[s,a,rt,s,],將樣本中的當前狀態s和當前動作a送入評價主網絡得到當前狀態s預測的q(s,a)new值,將樣本中的下一狀態s,送入動作目標網絡得到下一動作a,,后再送入評價目標網絡得到下一狀態s,的q(s,,a,)值;
31、s4-2:依據步驟s1-8中的公式4,可由q(s,,a,)推導出q(s,a),采用均方誤差作為損失函數如公式6所示,后采用梯度反傳更新評價主網絡權重θ,最后將訓練好的評價主網絡權重θ更新到評價目標網絡更新方式采用軟更新方式,即引入學習率如公式7:
32、loss=(rt+βπ(a,|s,)q(s,,a,)-q(s,a)new)2?(6)
33、
34、其中,rt為數據傳輸效率,β為折扣率,ep為模型當前訓練所處的輪次;
35、s4-3:訓練動作主網絡權重μ,從經驗池中選取樣本[s,a,rt,s,],將樣本中的當前狀態s送入動作主網絡得到預測的當前動作anew,后再送入評價目標網絡得到當前狀態s的q(s,anew)值,需要最大化q(s,anew)值即max(q(s,anew)),通過梯度上升來更新訓練動作主網絡權重μ,最后將訓練好的動作主網絡權重μ更新到動作目標網絡更新方式同樣采用軟更新方式,引入學習率如公式8:
36、
37、其中,ep為模型當前訓練所處的輪次;
38、s4-4:多次重復上述步驟s4-1、s4-2、s4-3,直至損失收斂穩定,后將訓練好的網絡路由決策強化學習模型應用實際網絡場景,驗證模型的有效性。
39、與現有技術相比,本發明的優點和積極效果在于:
40、本發明提供一種基于強化學習的網絡擁塞路由選擇方法,解決了傳統負載均衡解決網絡路由擁塞的方式的固定限制,在滿足達到指定終點路由節點的前提下,隨機選取中間路由節點和到達該階段的線路,后依據數據傳輸效率和路由擁塞范式給出評判,以此來獲取信息充足的狀態數據。同時路由間的線路不唯一,以此來模擬實際網絡通信場景中的復雜狀態,進而獲取多樣化、多表征狀態的數據,提升模型的魯棒性,使得網絡路由決策分析更為貼合實際。
- 還沒有人留言評論。精彩留言會獲得點贊!