一種基于多出口神經網絡安全推理的車聯網目標識別方法
本發明屬于網絡安全,具體涉及一種基于多出口神經網絡安全推理的車聯網目標識別方法。
背景技術:
1、目前車輛常常通過使用由電池供電的傳感器設備從環境中收集影像等交通數據,并使用深度神經網絡對交通數據進行處理從而執行推理任務。雖然使用深度神經網絡可以獲得較高的推理精度,但它們存在著訓練和推理速度緩慢等問題。它們較長的推理延遲使其難以在實時應用程序、移動電話等硬件受限的邊緣設備中進行部署。多出口神經網絡因此被廣泛應用來解決這一問題。
2、國內外對多出口神經網絡推理方法的研究十分豐富;有研究人員提出基于雙向變換器模型的獨立動態早期出口算法,在語言模型中插入額外的分類層,即出口匝道,來加速大規模預的語言模型的推斷,在推理任務的執行過程中,使用當前出口匝道的輸出概率分布的熵來量化一個出口對當前任務預測的置信度,當其滿足推理精度的要求時,則返回推理結果。也有提出將傳統單出口神經網絡轉換為具備異構和動態特性的多出口神經網絡的方法。這種方法的缺陷在于,現有的多出口神經網絡有較高的計算需求,阻礙了它們在資源有限的移動設備中的廣泛采用。分布式多出口神經網絡框架解決了該問題,例如,有基于現有的多出口神經網絡設計的一種分布式推理系統被提出,在執行推理任務時,客戶端執行模型的第一部分,并將中間結果傳輸到遠程服務器。服務器繼續執行推理任務并將結果返回給客戶端。該算法中,允許根據客戶端和云服務器的能力來調整將在不同設備上部署的神經網絡的比例。但是,上述方法都是對不同的預測置信度分布使用單一的閾值來做出決策,這使得攻擊者可以對該分布式多出口神經網絡發起側信道攻擊,推測當前推理任務的出口,導致模型預測的泄露。后又有研究者提出使用多個閾值來平衡跨預測類的推理出口選擇,并引入置信偏差來調整不同出口的退出概率。但以上的方法難以很好地解決多出口神經網絡推理過程中的安全性和開銷問題。
3、為保證傳感器設備在使用多出口神經網絡執行推理時仍然能夠保證較高的推理精度和低開銷,本發明使用深度強化學習方法來為每一個推理任務選擇多出口神經網絡的推理出口,綜合考慮執行推理任務時的推理效率、開銷和安全性,實現三者之間的平衡;實現當前車輛以低時延和能耗完成對傳感器設備所收集到的交通數據的目標識別任務。
技術實現思路
1、發明目的:本發明提出一種基于多出口神經網絡安全推理的車聯網目標識別方法,平衡傳感系統在執行推理任務時的推理效率、推理時延、推理能耗和安全性,傳感器設備利用基于長期折扣期望效益的q網絡選擇神經網絡進行推理任務的出口,提升任務推理的效率與安全性,進而防御針對多出口神經網絡的側信道攻擊。
2、技術方案:本發明所述的一種基于多出口神經網絡安全推理的車聯網目標識別方法,具體包括以下步驟:
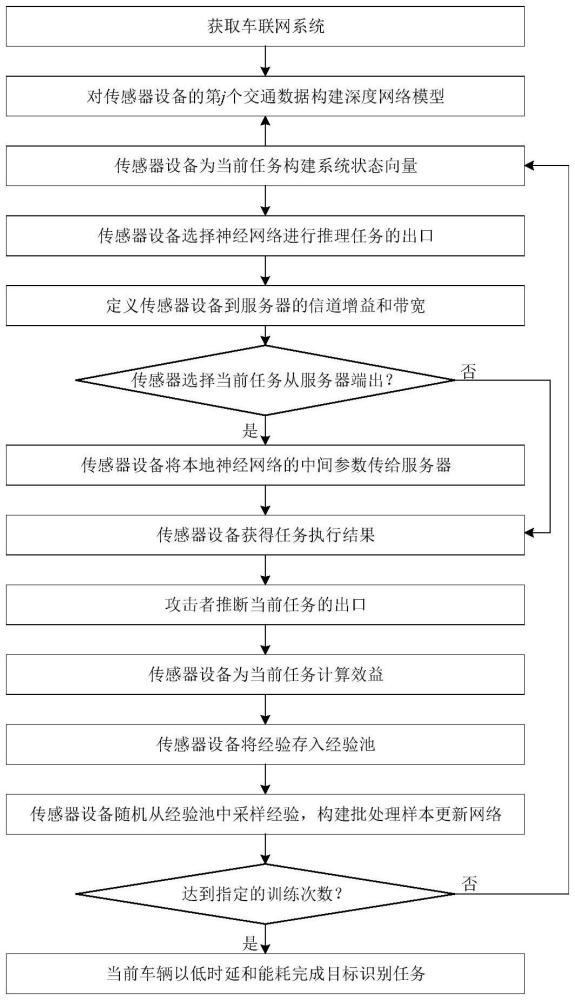
3、(1)獲取車聯網系統;所述車聯網系統包括一個服務器以及一個配備了傳感器設備的車輛;
4、(2)對傳感器設備的第j個推理任務構建深度網絡模型,即q網絡,并且初始化學習率α、折扣因子δ以及所述q網絡的權重參數
5、(3)傳感器設備為當前任務j構建系統狀態向量
6、(4)定義神經網絡進行推理任務的出口,傳感器設備選擇神經網絡進行推理任務的出口;
7、(5)定義傳感器設備到服務器的信道增益為h(k),帶寬為b(k),服務器到傳感器設備的信道增益為帶寬為
8、(6)如果在步驟(4)中傳感器設備選擇在服務器執行當前任務j,傳感器設備需要將本地神經網絡的中間參數以固定功率p發送給服務器;服務器執行完任務后,將任務執行結果以固定功率發送給傳感器設備;如果在步驟(4)中傳感器設備選擇在本地執行當前任務j,則傳感器設備直接獲得任務執行結果
9、(7)攻擊者隨機推斷當前任務j從第個神經網絡出口輸出任務執行結果;
10、(8)計算車輛所配備的傳感器設備執行當前任務j所需要的效益
11、(9)傳感器設備將包含狀態向量、神經網絡進行推理任務的出口選擇策略、效益的經驗存入經驗池;
12、(10)傳感器設備隨機從經驗池中采樣出z條經驗,構建批處理樣本數據;
13、(11)更新所述深度網絡的權重參數
14、(12)重復步驟(3)至步驟(11),每重復一次k加1到直到其與k相等,使得當前車輛以低時延和能耗完成對傳感器設備所收集到的交通數據的目標識別任務。
15、進一步地,步驟(1)所述所述車輛利用自身的傳感器設備從周圍環境中收集m個交通數據,并對每一個數據進行處理,通過一個含有j個出口的resnet18多出口神經網絡執行目標識別任務,該網絡分別部署在服務器和該車輛的傳感器設備上。
16、進一步地,步驟(3)所述構建狀態向量的具體過程為:
17、在時刻k,傳感器設備觀測原始任務的類別根據上一時刻的推理能耗和時延歷史的推理效果以及被攻擊者推斷成功的概率傳感器設備為當前任務j構建其狀態向量如下:
18、
19、進一步地,所述步驟(4)實現過程如下:
20、將傳感器設備將狀態向量輸入q網絡中,q網絡輸出當前狀態下所有神經網絡出口的長期折扣期望效益并通過該值使用ε-貪心法選擇動作;記傳感器設備選擇的動作為xj(k),以1-ε的概率選擇qj值最大的那個動作,以ε的概率隨機選擇其他動作,其中ε∈(0,1);ε決定了傳感器設備的探索性,其值越大,則傳感器設備選擇動作時的隨機性越大;
21、神經網絡進行推理任務的出口定義為其中代表傳感器設備只在本地執行當前任務j,表示傳感器設備在服務器執行當前任務j;對應于神經網絡進行推理任務的j個出口。
22、進一步地,所述步驟(8)實現過程如下:
23、傳感器設備利用任務執行結果與當前任務j的實際類別進行對比,獲取當前的推理效果為指示函數,括號內的變量為真時,指示函數的值為1,否則為0;并計算車輛所配備的傳感器設備執行當前任務所需要的時延以及能耗傳感器設備根據攻擊者推斷的任務出口以及神經網絡進行推理任務j的實際出口估計被攻擊者推斷成功的概率然后計算當前時刻的效益如下:
24、
25、其中,m1,m2,m3是權重系數,分別衡量執行當前任務的推理精度、時延以及被攻擊者推斷成功的概率在效益中的重要性。
26、進一步地,所述步驟(9)實現過程如下:
27、傳感器設備將狀態向量神經網絡進行推理任務的出口選擇策略效益構建為經驗序列并存入經驗池d中,此時經驗池d中共有k條經驗序列。
28、進一步地,所述步驟(10)實現過程如下:
29、傳感器設備從經驗池d中隨機采樣出z條包括歷史的神經網絡進行推理任務的出口選擇策略以及傳感器設備所需要花費的相應的開銷等信息的經驗,構建批處理樣本:
30、
31、其中,表示從經驗池d中取出的第g(η)條經驗,并且服從均勻分布u(1,k),即g(η)~u(1,k)。
32、進一步地,所述步驟(11)實現過程如下:
33、感器設備采用adam優化算法更新q網絡的權重參數如下:
34、
35、其中,θ為權重參數,δ為權重參數更新的折扣因子。
36、有益效果:與現有技術相比,本發明的有益效果:
37、本發明通過觀察原始任務的類別、上一時刻的推理能耗和時延、歷史的推理效果以及被攻擊者推斷成功的概率,從而構建系統狀態,結合基于長期折扣期望效益值的q網絡優化神經網絡進行推理任務的出口選擇策略,提升任務推理的效率與安全性,進而防御針對多出口神經網絡的側信道攻擊;使得當前車輛以低時延和能耗完成對傳感器設備所收集到的交通數據的目標識別任務。
- 還沒有人留言評論。精彩留言會獲得點贊!