語音質量評估方法、系統、電子設備及存儲介質與流程
本發明涉及通信,尤其涉及一種語音質量評估方法、系統、電子設備及存儲介質。
背景技術:
1、目前語音質量評估的主要的技術方案:測試電腦控制主叫終端呼叫被叫終端,在呼叫接通時,在主叫終端側播放一段預置好的標準語料,被叫終端實時接聽并將接聽的內容發送給語音評測mos盒。mos盒實時地將接收到的語音與標準語料通過mos算法模型進行對比,計算出該語音的mos分。測試后,通過人工對測試數據的分析,得出部分mos質差的原因。通信網絡是個實時的監控系統,采用主觀評估方法費時費力,受測試條件的限制和測試人員主觀因素的影響,導致測試結果的可靠性低;客觀語音評估方法一般是利用網絡中的一些客觀參量來反映語音質量,如信噪比、誤碼率、接收質量等,這些客觀參量不能準確反映人們的主觀感受,語音質差不能實時獲取根因,需要在測試完成后,人工對質差點進行后分析,因此實效性差。
技術實現思路
1、本發明提供一種語音質量評估方法、系統、電子設備及存儲介質,旨在提高語音質量評估的可靠性和實效性。
2、第一方面,本發明提供一種語音質量評估方法,應用于用戶終端,所述語音質量評估方法包括:
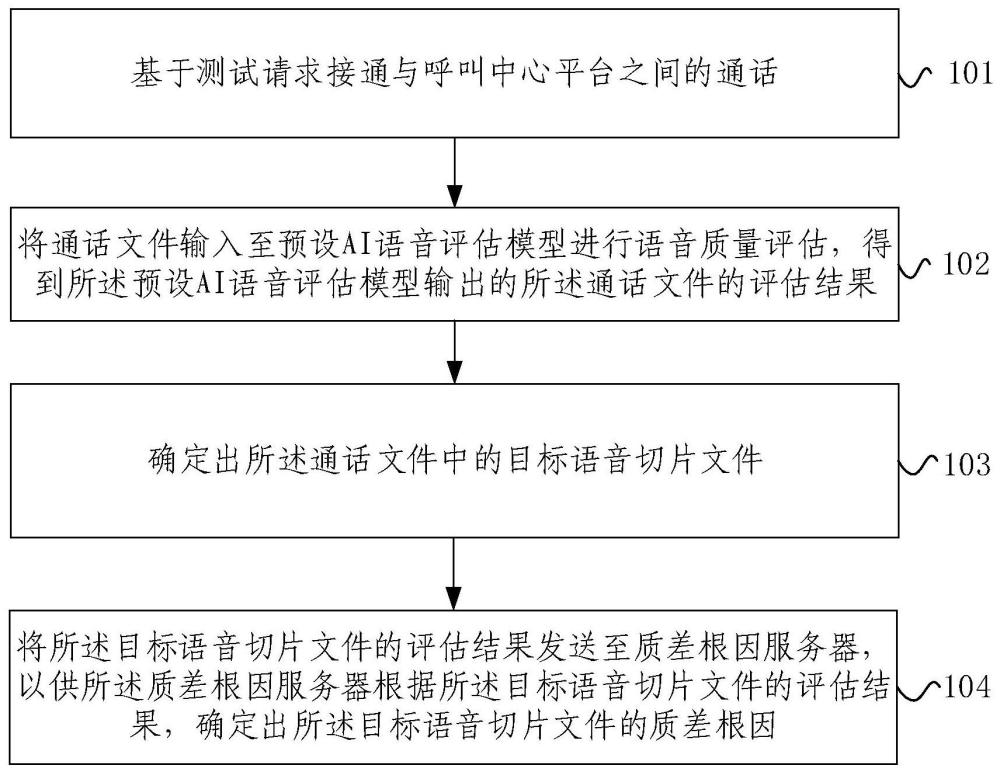
3、基于測試請求接通與呼叫中心平臺之間的通話;
4、將通話文件輸入至預設ai語音評估模型進行語音質量評估,得到所述預設ai語音評估模型輸出的所述通話文件的評估結果;所述通話文件為與所述呼叫中心平臺通話過程中獲取到的通話數據;所述預設ai語音評估模型是通過機器學習結合語音質量算法和人工判斷數據轉換得到的;
5、確定出所述通話文件中的目標語音切片文件;所述目標語音切片文件的評估結果為質差;所述質差表征所述目標語音切片文件的評估結果的mos平均意見得分低于預設分值;
6、將所述目標語音切片文件的評估結果發送至質差根因服務器,以供所述質差根因服務器根據所述目標語音切片文件的評估結果,確定出所述目標語音切片文件的質差根因。
7、在一個實施例中,所述將通話文件輸入至預設ai語音評估模型進行語音質量評估,得到所述預設ai語音評估模型輸出的所述通話文件的評估結果,包括:
8、按照預設時長為單位將所述通話文件拆分為第一數量的語音切片文件,并確定所述第一數量的語音切片文件中最后一個語音切片文件的語音時長;
9、若確定所述語音時長小于所述預設時長,則將所述第一數量的語音切片文件中的最后一個語音切片文件進行剔除,得到第二數量的語音切片文件;
10、將所述第二數量的語音切片文件輸入至所述預設ai語音評估模型進行語音質量評估,得到所述預設ai語音評估模型輸出的所述第二數量的語音切片文件中,每一個語音切片文件的評估結果。
11、第二方面,本發明提供一種語音質量評估方法,應用于質差根因服務器,所述語音質量評估方法包括:
12、接收用戶終端發送的目標語音切片文件的評估結果;
13、根據所述目標語音切片文件的評估結果,對所述目標語音切片文件進行質差根因分析。
14、在一個實施例中,所述根據所述目標語音切片文件的評估結果,對述目標語音切片文件進行質差根因分析,包括:
15、根據所述目標語音切片文件攜帶的文件id,確定出所述目標語音切片文件的信令面數據和用戶面數據;
16、根據所述信令面數據進行信令面根因定界,或/和,根據所述用戶面數據進行用戶面根因定界,確定出質差網元;
17、通過時空關聯所述質差網元的運行日志,輸出質差根因。
18、根據所述用戶面數據進行用戶面根因定界,確定出質差網元具體包括:
19、基于所述用戶面數據偵測到數據流通過目標網元時,對所述數據流進行抓包分析,確定所述數據流發送的第一信息包數目、丟失的第二信息包數目和信息包的抖動情況;所述目標網元為所述用戶面數據所屬網路的任一網元;
20、若基于所述第一信息包數目和所述第二信息包數目,確定丟包數目大于預設數目,或/和,所述抖動情況為時延抖動大于預設時延,則確定所述目標網元為質差網元。
21、所述根據所述目標語音切片文件的評估結果,對所述目標語音切片文件進行質差根因分析之后,還包括:
22、獲取所述用戶終端發送的所述目標語音切片文件的指標數據;
23、將所述目標語音切片文件的指標數據、mos平均意見得分、質差類型、文件id、質差網元和質差根因進行整合,得到語音評估數據,并將所述語音評估數據發送至所述用戶終端。
24、第三方面,本發明提供一種語音質量評估系統,應用于用戶終端,所述語音質量評估系統包括:
25、通信模塊,用于基于測試請求接通與呼叫中心平臺之間的通話;
26、語音質量評估模塊,用于將通話文件輸入至預設ai語音評估模型進行語音質量評估,得到所述預設ai語音評估模型輸出的所述通話文件的評估結果;所述通話文件為與所述呼叫中心平臺通話過程中獲取到的通話數據;所述預設ai語音評估模型是通過機器學習結合語音質量算法和人工判斷數據轉換得到的;
27、確定模塊,用于確定出所述通話文件中的目標語音切片文件;所述目標語音切片文件的評估結果為質差;所述質差表征所述目標語音切片文件的評估結果的mos平均意見得分低于預設分值;
28、發送模塊,用于將所述目標語音切片文件的評估結果發送至質差根因服務器,以供所述質差根因服務器根據所述目標語音切片文件的評估結果,確定出所述目標語音切片文件的質差根因。
29、第四方面,本發明提供一種語音質量評估系統,應用于質差根因服務器,所述語音質量評估系統包括:
30、接收模塊,用于接收用戶終端發送的目標語音切片文件的評估結果;
31、質差根因分析模塊,用于根據所述目標語音切片文件的評估結果,對所述目標語音切片文件進行質差根因分析。
32、第五方面,本發明還提供一種電子設備,包括存儲器、處理器及存儲在存儲器上并可在處理器上運行的計算機程序,所述處理器執行所述程序時實現第一方面或第二方面所述語音質量評估方法。
33、第六方面,本發明還提供一種非暫態計算機可讀存儲介質,非暫態計算機可讀存儲介質包括計算機程序,所述計算機程序被所述處理器執行時實現第一方面或第二方面所述語音質量評估方法。
34、第七方面,本發明還提供一種計算機程序產品,所述計算機程序產品包括計算機程序,所述計算機程序被所述處理器執行時實現第一方面或第二方面所述語音質量評估方法。
35、本發明提供的語音質量評估方法、系統、電子設備及存儲介質,基于測試請求接通與呼叫中心平臺之間的通話;將通話文件輸入至預設ai語音評估模型進行語音質量評估,得到預設ai語音評估模型輸出的通話文件的評估結果;確定出通話文件中的目標語音切片文件;目標語音切片文件的評估結果為質差;將目標語音切片文件的評估結果發送至質差根因服務器,以供質差根因服務器根據目標語音切片文件的評估結果,確定出目標語音切片文件的質差根因。
36、在語音質量評估的過程中,在用戶終端中嵌入輕量級ai語音評估模型,兼顧了主觀評分與客觀評分,既能輸出mos分,又能輸出主觀的質量評價,同時,將通話文件的評估結果發送至質差根因服務器,質差根因服務器只分析質差通話的根因,減輕了運算壓力,提高了語音質量評估的可靠性和實效性。
- 還沒有人留言評論。精彩留言會獲得點贊!