基于圖像相關性的自適應快速編碼單元劃分方法及裝置與流程
本發明涉及一種編碼單元劃分方法,尤其涉及一種基于圖像相關性的自適應快速編碼單元劃分方法,同時也涉及相應的自適應快速編碼單元劃分裝置,屬于視頻編碼技術領域。
背景技術:
隨著高分辨率視頻拍攝設備的普及,播放高清視頻的需求也越來越多。因此,對視頻圖像的存儲和傳輸提出了更高的要求。hevc/h.265標準是針對高分辨率視頻推出的高性能視頻編碼標準,其目標在于是提高壓縮率,降低網絡帶寬。hevc/h.265編碼標準與avc/h.264編碼標準相比,不僅具有更多的可選編碼模式,還能提高50%的壓縮效率。
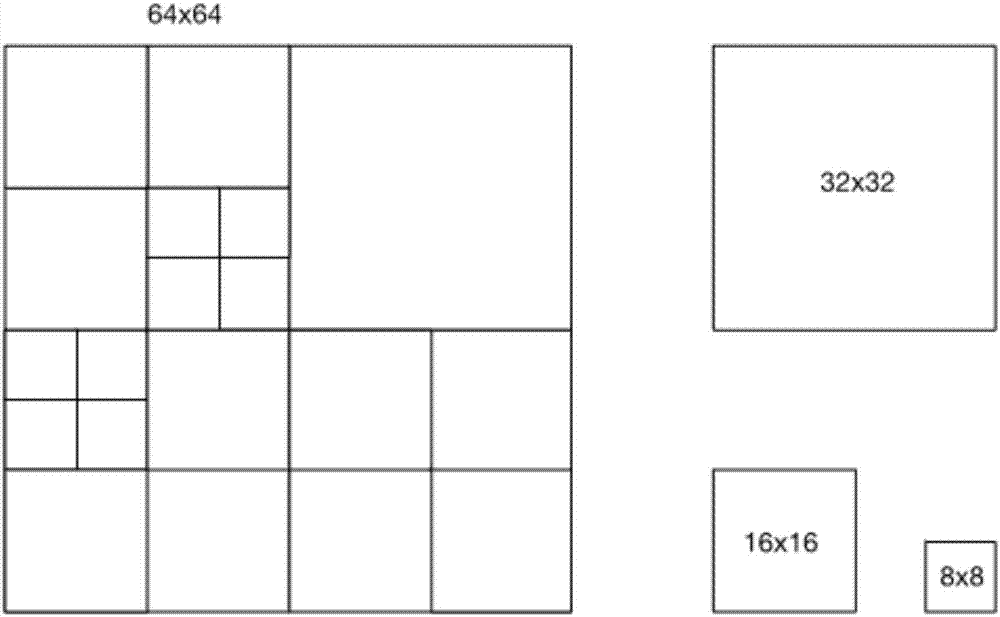
在hevc/h.265編碼標準的編碼器中,通常先將每一幀圖像分割成若干個互不重疊的矩形塊,每一個矩形塊即為最大編碼單元(簡寫為lcu)。編碼器以四叉樹的形式并按照遞歸的方式把每一個lcu分割為不同尺寸的編碼單元(簡寫為cu),然后對cu選擇幀內或幀間模式進行編碼。如圖1和圖2所示,cu可以有64x64、32x32、16x16、8x8四種尺寸級別,通常把64x64作為最高尺寸級別(也稱最大編碼單元),把8x8作為最低尺寸級別(也稱最小編碼單元)。lcu的分割過程主要用兩個變量進行標記:分割深度(cu_depth)和分割標記符(split_flag)。其中,cu的尺寸(即圖中標示出的size)大小和深度(即圖中標示出的depth)相對應,尺寸為64x64的cu的深度為0,尺寸為32x32的cu的深度為1,尺寸為16x16的cu的深度為2,尺寸為8x8的cu的深度為3。而標記符主要用于表示是否對當前的cu進行四等份分割。
現有技術中,對lcu的劃分通常是通過計算率失真代價值來決定的。首先,計算當前lcu的率失真代價值;然后,將當前lcu劃分成四個子cu,對4個子cu按順序進行獨立的遞歸編碼,得到四個子cu的率失真代價值;最后,將當前lcu的率失真代價值與四個子cu的率失真代價值進行比較,選擇最小率失真代價值對應的lcu劃分模式進行最終編碼。
上述lcu的劃分需要對lcu逐層遞歸劃分至8×8的最小編碼單元,然后通過計算各種劃分模式的率失真代價值,選擇最小率失真代價值對應的cu劃分模式進行最終編碼。綜上所述,現有技術中的lcu劃分方法不僅提高了計算復雜度,而且還存在效率低下的缺陷,從而影響視頻編碼效率。
技術實現要素:
本發明所要解決的首要技術問題在于提供一種基于圖像相關性的自適應快速編碼單元劃分方法。
本發明所要解決的另一技術問題在于提供一種基于圖像相關性的自適應快速編碼單元劃分裝置。
為了實現上述發明目的,本發明采用下述的技術方案:
根據本發明實施例的第一方面,提供一種基于圖像相關性的自適應快速編碼單元劃分方法,包括如下步驟:
步驟s1:根據視頻幀類型,獲取相鄰編碼單元的深度信息;
步驟s2:根據相鄰編碼單元的深度信息,建立當前最大編碼單元深度信息向量表;
步驟s3:根據當前最大編碼單元深度信息向量表,計算當前最大編碼單元的深度搜索范圍;
步驟s4:根據當前最大編碼單元的深度搜索范圍,選擇當前最大編碼單元的最優劃分。
其中較優地,步驟s1中,所述視頻幀類型包括幀內編碼幀、幀間編碼幀;
當所述當前最大編碼單元屬于所述幀內編碼幀時,獲取與所述最大編碼單元空間相鄰的所述編碼單元的所述深度信息;
當所述當前最大編碼單元屬于所述幀間編碼幀時,獲取與所述最大編碼單元空間和時間相鄰的所述編碼單元的所述深度信息。
其中較優地,獲取與所述當前最大編碼單元空間相鄰的所述編碼單元的所述深度信息時,按照位于所述當前最大編碼單元的左邊、上邊、右上及左上的位置順序依次獲取空間相鄰的所述編碼單元的所述深度信息。
其中較優地,獲取與所述當前最大編碼單元時間相鄰的所述編碼單元的所述深度信息時,按照位于所述當前最大編碼單元的右下及同位置的位置順序依次獲取時間相鄰的所述編碼單元的所述深度信息。
其中較優地,步驟s2中,建立所述當前最大編碼單元的所述深度信息向量表的步驟如下:
s21:建立長度固定的空的所述深度信息向量表;
s22:向所述深度信息向量表中依次添加預定數量的空間域向量;
s23:向所述深度信息向量表中依次添加預定數量的時間域向量。
其中較優地,向所述深度信息向量表中依次添加預定數量的所述時間域向量時,按照位于所述當前最大編碼單元右下及同位置的編碼單元的深度信息次序,依次選擇一個所述深度信息添加到所述深度信息向量表。
其中較優地,步驟3中,將建立的所述當前最大編碼單元的所述深度信息向量表的深度信息進行升序排序,選取最小和最大的所述深度信息作為所述當前最大編碼單元的所述深度搜索范圍。
其中較優地,步驟3中,計算所建立的所述當前最大編碼單元的所述深度信息向量表的深度信息的平均值并向下取整,以所述深度信息的平均值作為所述深度搜索范圍的深度最小值,以述深度信息的平均值加上一個深度值作為所述深度搜索范圍的深度最大值;其中,當所述深度搜索范圍的深度最大值大于3時,則選取3作為所述深度搜索范圍的深度最大值。
其中較優地,步驟4中,遍歷所述當前最大編碼單元的所述深度搜索范圍內的所有編碼模式,按照遞歸的方式計算出每種所述編碼模式的率失真代價,經過比較,選取率失真代價值最小的編碼模式作為所述當前最大編碼單元的最優劃分。
根據本發明實施例的第二方面,提供一種基于圖像相關性的自適應快速編碼單元劃分裝置,包括信息獲取模塊、建表模塊、計算深度范圍模塊及劃分判斷模塊,所述信息獲取模塊與所述建表模塊連接,所述建表模塊與所述計算深度范圍模塊連接,所述計算深度范圍模塊與所述劃分判斷模塊連接;
所述信息獲取模塊用于獲取與當前最大編碼單元相鄰的編碼單元的深度信息;
所述建表模塊用于根據獲取的與所述當前最大編碼單元相鄰的所述編碼單元的所述深度信息,建立所述當前最大編碼單元深度信息向量表;
所述計算深度范圍模塊用于根據所述當前最大編碼單元深度信息向量表,計算所述當前最大編碼單元的深度搜索范圍;
所述劃分判斷模塊根據所述當前最大編碼單元的深度搜索范圍,選擇所述當前最大編碼單元的最優劃分。
本發明所提供的自適應快速編碼單元劃分方法根據當前最大編碼單元的視頻幀類型,獲取位于當前最大編碼單元相鄰的編碼單元的深度信息,根據相鄰的編碼單元的深度信息建立當前最大編碼單元深度信息向量表,從而確定出當前最大編碼單元的深度搜索范圍。與現有技術相比較,本發明縮小了當前最大編碼單元的深度搜索范圍,減少了計算率失真代價的編碼模式的數量,從而降低視頻編碼的計算復雜度,提高了視頻編碼的效率。
附圖說明
圖1為現有技術中,最大編碼單元的四叉樹結構示意圖;
圖2為現有技術中,最大編碼單元的劃分示意圖;
圖3為本發明所提供的基于圖像相關性的自適應快速編碼單元劃分方法的流程圖;
圖4和圖5為本發明所提供的基于圖像相關性的自適應快速編碼單元劃分方法中,獲取與當前最大編碼單元空間相鄰的編碼單元的深度信息的示意圖;
圖6和圖7為本發明所提供的基于圖像相關性的自適應快速編碼單元劃分方法中,獲取與當前最大編碼單元時間相鄰的編碼單元的深度信息的示意圖;
圖8為本發明所提供的基于圖像相關性的自適應快速編碼單元劃分方法中,獲取與當前最大編碼單元空間和時間相鄰的編碼單元的深度信息的流程圖;
圖9為實現本發明所提供的自適應快速編碼單元劃分裝置的結構示意圖。
具體實施方式
下面結合附圖和具體實施例對本發明的技術內容做進一步的詳細說明。
如圖3所示,本發明所提供的基于圖像相關性的自適應快速編碼單元劃分方法包括如下步驟:
步驟s1:根據視頻幀類型,獲取相鄰cu的深度信息。
在用戶編碼當前lcu的過程中,需要判別當前lcu的視頻幀類型,即判別當前lcu的視頻幀類型是幀內編碼幀(即i幀)還是幀間編碼幀(即p/b幀),下面分別對當前lcu為上述兩種視頻幀類型的情況一一進行說明。
如果當前的lcu的視頻幀類型為幀內編碼幀(即i幀),由于幀內編碼幀是一種自帶全部信息的獨立幀,無需參考其它圖像便可獨立進行編碼,因此幀內編碼幀沒有參考幀,只需獲取與該lcu空間相鄰的cu的深度信息即可。如圖4所示,依次獲取位于當前lcu的左邊(l)cu、上邊(t)cu、右上(rt)cu及左上(lt)cu的深度信息。
由于cu的尺寸大小和深度相對應,尺寸為64x64的cu的深度為0,尺寸為32x32的cu的深度為1,尺寸為16x16的cu的深度為2,尺寸為8x8的cu的深度為3。即與當前lcu空間相鄰的cu的深度范圍為0~3。例如,如圖5所示,依次獲取的位于當前lcu的左邊(l)cu、上邊(t)cu、右上(rt)cu及左上(lt)cu的深度信息值對應為2、1、2、2,與上述左邊(l)cu、上邊(t)cu、右上(rt)cu及左上(lt)cu的深度信息相對應的編碼單元尺寸為16x16、32x32、16x16、16x16。
如果當前的lcu的視頻幀類型為幀間編碼幀(即p/b幀),則需要分別獲取與該lcu空間和時間相鄰的cu的深度信息。同樣,先采用與上述的視頻幀類型為幀內編碼幀時獲取與當前的lcu空間相鄰的cu的深度信息的方法,獲取與當前的lcu空間相鄰的cu的深度信息。并且,也以圖5所示為例,依次獲取的位于當前lcu的左邊(l)cu、上邊(t)cu、右上(rt)cu及左上(lt)cu的深度信息值對應為2、1、2、2,與上述左邊(l)cu、上邊(t)cu、右上(rt)cu及左上(lt)cu的深度信息相對應的編碼單元尺寸為16x16、32x32、16x16、16x16。然后,獲取與當前lcu時間相鄰的cu的深度信息;如圖6所示,依次獲取位于當前lcu右下(rb)cu及同位置(s)cu的深度信息。例如,如圖7所示,依次獲取的位于當前lcu的右下(rb)cu及同位置(s)cu的深度信息值對應為3、2,與上述右下(rb)cu及同位置(s)cu的深度信息相對應的編碼單元尺寸為8x8、16x16。
需要強調的是,在每一幀圖像中,根據當前lcu所處位置的不同,可能會導致與當前lcu空間相鄰的四個位置(即位于當前lcu左邊、上邊、右上及左上位置)中一個或多個位置上的cu不存在,對于不存在的cu可以略過。例如,當lcu位于第一行時,位于該lcu的上邊(t)cu、右上(rt)cu、左上(lt)cu不存在,則可以略過。當lcu位于第一列時,位于該lcu的左邊(l)cu、左上(lt)cu不存在,則可以略過。當lcu位于最后一列時,位于該lcu的右上(rt)cu不存在,則可以略過。同樣,還可能會導致與當前lcu時間相鄰的兩個位置(即位于當前lcu右邊位置及同位置)中一個或多個位置上的cu不存在,對于不存在的cu可以略過。例如,當lcu位于最后一列時,位于該lcu的右下(rb)cu不存在,則可以略過。
步驟s2:根據相鄰cu的深度信息,建立當前lcu深度信息向量表。
在用戶編碼當前lcu的過程中,需要根據獲取的與不同視頻幀類型的當前最大編碼單元相鄰的cu的深度信息,建立當前lcu深度信息向量表。建立當前lcu深度信息向量表的過程為:(1)建立長度固定的空的深度信息向量表。(2)向深度信息向量表中依次添加一定數量的空間域向量(與當前lcu空間相鄰的cu的深度信息)。(3)向深度信息向量表中依次添加一定數量的時間域向量(與當前lcu時間相鄰的cu的深度信息)。同樣,分別以當前lcu為不同視頻幀類型的情況為例,對當前lcu深度信息向量表的建立過程進行說明。
如果當前的lcu的視頻幀類型為幀內編碼幀(即i幀),建立長度為2的空的深度信息向量表,按照以下幾種情況向深度信息向量表中依次添加與當前lcu空間相鄰的編碼單元的深度信息:1、如果沒有空間相鄰cu,沒有獲取到與當前lcu空間相鄰的編碼單元的深度信息,則將深度信息值1和深度信息值2添加到深度信息向量表。2、如果只獲取了一個與當前lcu空間相鄰的編碼單元的深度信息,則將當前深度信息值和深度信息值1依次添加到深度信息向量表.3、如果獲取了兩個以上與當前lcu空間相鄰的編碼單元的深度信息,則只把前兩個深度信息值依次添加到深度信息向量表,余下的深度信息舍棄。例如,建立長度為2的空的深度信息向量表,結果是:();在步驟s1中,依次獲取的位于當前lcu的左邊(l)cu、上邊(t)cu、右上(rt)cu及左上(lt)cu的深度信息值2、1、2、2,由于獲取的深度信息超過了兩個,則只把前兩個深度信息依次添加到深度信息向量表,結果是:(2,1),即將獲取的位于當前lcu的右上(rt)cu及左上(lt)cu的深度信息舍棄。
如果當前的lcu的視頻幀類型為幀間編碼幀(即p/b幀),建立長度為3的空的深度信息向量表,向空的深度信息向量表先依次添加兩個與當前lcu空間相鄰的編碼單元的深度信息,添加深度信息的方法同視頻幀類型為幀內編碼幀(即i幀)時的添加與當前lcu空間相鄰的編碼單元的深度信息的方法,再次不再贅述。添加完與當前lcu空間相鄰的編碼單元的深度信息后,再添加與當前lcu時間相鄰的編碼單元的深度信息,并按照位于當前lcu右下(rb)的cu、同位置(s)的cu的次序,并依次選擇一個深度信息添加到深度信息向量表。如果位于當前lcu右下(rb)的cu不存在,則將位于當前最大編碼單元同位置(s)的cu的深度信息添加到深度信息向量表。例如,建立長度為3的空的深度信息向量表,結果是:();先將采用步驟s1中的方法,依次獲取的位于當前lcu的左邊(l)cu、上邊(t)cu、右上(rt)cu及左上(lt)cu的深度信息值2、1、2、2,由于獲取的深度信息超過了兩個,則只把前兩個深度信息依次添加到深度信息向量表,結果是:(2,1,),即將獲取的位于當前lcu的右上(rt)cu及左上(lt)cu的深度信息舍棄。然后將采用步驟s1中的方法,依次獲取的位于當前lcu的右下(rb)cu及同位置(s)cu的深度信息值3、2,按照依次選擇一個深度信息添加到深度信息向量表的標準,將深度信息值3添加到深度信息向量表,結果是:(2,1,3),即將位于當前lcu的同位置(s)的cu的深度信息舍棄。
步驟s3:根據當前lcu深度信息向量表,計算當前lcu的深度搜索范圍。
根據步驟2中建立的當前lcu的深度向量表,計算當前lcu的深度搜索范圍的第一種實現方法為:對建立的當前lcu深度信息向量表的深度信息進行升序排序,最小和最大的深度信息作為當前lcu的深度搜索范圍。如果當前的lcu的視頻幀類型為幀內編碼幀(即i幀),對建立的深度信息向量表進行升序排序,得到排序后的深度信息向量表(dmin,dmax),其中,dmin表示最小深度信息,dmax表示最大深度信息。根據排序后的深度信息向量表(dmin,dmax),確定出當前的lcu的深度搜索范圍是(smin,smax),其中,smin=dmin,smax=dmax。例如,將步驟2中建立的當前的lcu的深度信息向量表(2,1)進行升序排序,結果是:(1,2),則確定當前lcu的深度搜索范圍為(1,2)。
如果當前的lcu的視頻幀類型為幀間編碼幀(即p/b幀),對建立的深度信息向量表進行升序排序,得到排序后的深度信息向量表(dmin,dmid,dmax),dmid表示位于最大深度信息與最小深度信息之間的深度信息。根據排序后的深度信息向量表(dmin,dmid,dmax),確定出當前的lcu的深度搜索范圍是(smin,smax),其中,smin=dmin,smax=dmax。例如,將步驟2中建立的當前的lcu的深度信息向量表(2,1,3)進行升序排序,結果是:(1,2,3),則確定當前lcu的深度搜索范圍為(1,3)。
根據步驟2中建立的當前lcu的深度向量表,計算當前lcu的深度搜索范圍的第二種實現方法為:計算所建立的當前lcu深度信息向量表的深度信息的平均值davg并向下取整,基于深度信息的平均值,以該深度信息的平均值作為搜索范圍的深度最小值,以平均值加上一個深度值作為搜索范圍的深度最大值。本實施例中,當前lcu的深度搜索范圍是(smin,smax),其中,smin=davg,smax=davg+1。如果davg+1大于3,則smax=3,否則smax=davg+1。例如,當前的lcu的視頻幀類型為幀內編碼幀(即i幀),計算步驟2中建立的當前的lcu的深度信息向量表(2,1)的平均值davg并向下取整,結果是:davg=1,則smin=1,smax=davg+1=2,得出當前lcu的深度搜索范圍為(1,2)。如果當前的lcu的視頻幀類型為幀間編碼幀(即p/b幀),計算步驟2中建立的當前的lcu的深度信息向量表(2,1,3)的平均值davg并向下取整,結果是:davg=2,則smin=2,smax=davg+1=3,得出當前lcu的深度搜索范圍為(2,3)。
需要強調的是,采用上述計算當前lcu的深度搜索范圍的第一種實現方法為本發明的優選方案,根據該實現方法得出的當前lcu的深度搜索范圍,所確定的當前lcu的最優編碼模式(即最優劃分)更精確。根據上述第二種實現方法得出的當前lcu的深度搜索范圍,所確定的當前lcu的最優編碼模式(即最優劃分)雖然可能存在一定誤差,但該誤差被控制在當前lcu的最優編碼模式所允許的誤差范圍內。因此,在精度要求不高的情況下,可以采用第二種實現方法得出當前lcu的深度搜索范圍,并根據該深度搜索范圍確定當前lcu的最優編碼模式(即最優劃分),實現更大程度的縮小當前最大編碼單元的深度搜索范圍,并且進一步減少了步驟s4中計算率失真代價的編碼模式的數量,從而降低視頻編碼的計算復雜度,提高了視頻編碼的效率。
步驟s4:根據當前最大編碼單元的深度搜索范圍,選擇當前lcu的最優劃分。
根據當前lcu的深度搜索范圍,遍歷當前最大編碼單元的深度搜索范圍內的所有可用編碼模式,按照遞歸的方式,計算出每種編碼模式下的編碼比特數和相應的重建圖像失真度。例如,當采用步驟3的方法所確定的當前lcu的深度搜索范圍為(1,2)時,只需遍歷深度為1和2時的所有可用編碼模式,提前終止或跳過遍歷深度為0和3時的所有可用編碼模式,縮小了當前lcu的深度遍歷范圍,從而減少了計算編碼比特數和相應的重建圖像失真度的編碼模式數量。當采用步驟3的方法所確定的當前lcu的深度搜索范圍為(1,3)時,只需遍歷深度為1、2、3時的所有可用編碼模式,提前終止或跳過遍歷深度為0時的所有可用編碼模式,縮小了當前lcu的深度遍歷范圍,也實現減少了計算編碼比特數和相應的重建圖像失真度的編碼模式數量。根據下面公式:
j(s,c,m|qp,λm)=ssd(s,c,m|qp)+λmr(s,c,m|qp)
其中,λm代表拉格朗日乘數,qp代表量化參數,m代表預測模式,s代表編碼塊數據,c代表重建塊數據,r(s,c,m|qp)代表編碼當前預測模式所需的比特數,誤差平方和ssd表示圖像失真度。根據上述公式,計算出每種編碼模式的率失真代價j,經過比較,選取率失真代價值最小的編碼模式作為當前lcu的最優編碼模式(即最優劃分)。
需要強調的是:還可以采用相應的公式,計算出每種編碼模式的失真度sad或者殘差平方和sse,經過比較,選取失真度或者殘差平方和sse最小的編碼模式作為當前lcu的最優編碼模式(即最優劃分)。由于步驟s4采用的是現有的計算方法計算率失真代價值、失真度sad或者殘差平方和sse,因此,不在具體描述計算過程。
如圖9所示,本發明還提供了一種基于圖像相關性的自適應快速編碼單元劃分裝置。該裝置包括信息獲取模塊1、建表模塊2、計算深度范圍模塊3及劃分判斷模塊4,信息獲取模塊1與建表模塊2連接,建表模塊2與計算深度范圍模塊3連接,計算深度范圍模塊3與劃分判斷模塊4連接。其中,信息獲取模塊1用于獲取與當前lcu相鄰的cu的深度信息。如圖8所示,信息獲取模塊1按照位于當前lcu的左邊、上邊(t)、右上(rt)及左上(lt)位置的順序,依次獲取與lcu空間相鄰的cu的深度信息。在獲取空間相鄰的cu的深度信息的過程中,如果與當前lcu空間相鄰的四個位置(即位于當前lcu左邊、上邊、右上及左上位置)中的一個或多個位置上的cu不存在,對于不存在的cu可以略過。如果當前的lcu的視頻幀類型為幀間編碼幀(即p/b幀),信息獲取模塊1不僅要獲取與lcu空間相鄰的cu的深度信息,還需按照位于當前lcu右下(rb)及同位置(s)的位置順序,依次獲取與lcu時間相鄰的cu的深度信息。獲取時間相鄰的cu的深度信息的過程中,如果與當前lcu空間相鄰的兩個位置(即位于當前lcu右下位置及同位置)中的一個或多個位置上的cu不存在,對于不存在的cu可以略過。
建表模塊2塊用于在用戶編碼當前lcu的過程中,需要根據獲取的與不同視頻幀類型的當前最大編碼單元相鄰的cu的深度信息,建立當前lcu深度信息向量表。建表模塊2塊建立當前lcu深度信息向量表的過程同步驟2所述,在此不再贅述。
計算深度范圍模塊3用于根據建立深度信息向量表模塊建立的當前lcu深度信息向量表,計算當前lcu的深度搜索范圍,計算深度范圍模塊3計算當前lcu的深度搜索范圍的方法同步驟3所述,在此不再贅述。
劃分判斷模塊4用于根據計算深度搜索范圍模塊計算的當前lcu的深度搜索范圍,遍歷當前最大編碼單元的深度搜索范圍內的每種可用編碼模式,按照遞歸的方式,計算出每種編碼模式率失真代價,經過比較,選取率失真代價值最小的編碼模式作為當前lcu的最優編碼模式(即最優劃分)。劃分判斷模塊4還可以計算出每種編碼模式的失真度sad或者殘差平方和sse,經過比較,選取失真度或者殘差平方和sse最小的編碼模式作為當前lcu的最優編碼模式(即最優劃分)。
本發明所提供的自適應快速編碼單元劃分方法根據當前最大編碼單元的視頻幀類型,獲取位于當前最大編碼單元相鄰的編碼單元的深度信息,根據相鄰的編碼單元的深度信息建立當前最大編碼單元深度信息向量表,從而確定出當前最大編碼單元的深度搜索范圍。與現有技術相比較,本發明縮小了當前最大編碼單元的深度搜索范圍,減少了計算率失真代價的編碼模式的數量,從而降低視頻編碼的計算復雜度,提高了視頻編碼的效率。
以上對本發明所提供的基于圖像相關性的自適應快速編碼單元劃分方法及裝置進行了詳細的說明。對本領域的一般技術人員而言,在不背離本發明實質精神的前提下對它所做的任何顯而易見的改動,都將屬于本發明專利權的保護范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!