視頻資源流行度預測方法與流程
本發明涉及數據挖掘和機器學習技術領域,尤其設計一種視頻資源流行度預測方法。
背景技術:
視頻點播是一種基于用戶收視的動態需求,傳輸并播放相應需求的服務內容的視頻播放技術。在收視內容的選擇和觀看方式上用戶具有對數據流的主動權,是否能及時響應用戶收視行為需求與資源調度的效率密切相關。在資源調度過程中,資源信息的流行度是調度算法的重要參考標準。
下面分別從用戶行為分析和資源流行度預測研究分別來介紹相關的研究工作。
現有的關于用戶行為分析的研究中,對用戶行為的定義主要分為兩類:一類指的是用戶在點播收視過程中的交互式用戶操作,所述的交互式操作與研究的具體問題有密切關系,如賽特斯網絡科技公司的“iptv系統中用戶行為分析裝置及實現”分析應用的系統,主要研究如何結合用戶行為對設備管理模型進行維護和運行,將不同的用戶數據信息統計整理過后反饋到服務提供商,其中的用戶行為主要指的是用戶對直播、點播、回看的使用情況,包括觀看時長和觀看次數等,其中的用戶行為是在其公司自己設備管理系統框架下定義并統計的,對收視行為的定義局限于收視模式(直播、點播)之間的區別,而沒有真正深入到對點播模式中不同的用戶交互行為中;另一類用戶行為指的是用戶請求的內容,以請求的內容代表用戶行為并對用戶請求內容進行處理和挖掘,如王攀等的專利“基于全業務視圖分析的iptv用戶行為分析方法”以業務為中心,根據業務屬性匹配適合偏好的用戶群矩陣,其中的用戶行為主要指的是用戶對iptv增值業務的需求,包括信息瀏覽、游戲、可視電話、影像空間等增值業務,其對用戶行為的研究局限地認為用戶對不同業務的使用代表不同的用戶行為,仍然沒有深入到用戶交互行為的本質,無法準確地反應用戶對收視內容的需求。
針對資源流行度預測,中國聯通的“一種資源服務系統及其資源分配方法”主要將業務系統中的排隊任務按照權重屬性進行聚類分組,按照優先級打分對任務進行資源分配;四達時代通訊網絡技術有限公司的“流媒體代理緩存替換方法及裝置”主要根據主成分分析和多元線性回歸的方法確定流媒體對象的流行度預測值,結合視頻峰值的信噪比確定流媒體對象的綜合價值以進行緩存替換;張天魁等在“一種基于內容流行度預測的信息中心網絡緩存方法”中提出了將每個節點記錄通過相似度分析進行聚類,計算節點上的內容流行度并做周期統計,再根據預測算法對流行度進行預測,與本地數據包進行對比決定是否更新節點緩存;常標等在“一種基于自回歸模型的在線連載內容流行度預測方法”中,著重解決在線連載內容流行度的預測,通過爬取在線連載內容的整體播放量趨勢,解析整體播放量趨勢頁面的html源代碼,利用自回歸模型預測新連載內容的流行度。從上述方案來看,現有研究沒有將流行度的預測與用戶交互行為進行聯合分析,使得流行度的預測研究缺少了用戶行為角度的數據支撐,流行度預測精度無法得到可靠保證。
技術實現要素:
本發明的目的是提供一種視頻資源流行度預測方法,綜合考慮用戶收視交互內容數據和交互行為數據對資源流行度預測的影響,研究兩類數據與流行度之間的關系,提高對資源流行度預測的準確性。
本發明的目的是通過以下技術方案實現的:
一種視頻資源流行度預測方法,包括:
統計一定區域內群體用戶的收視數據,獲得群體用戶的收視類型數據和交互行為數據,并利用收視類型數據來計算所統計數據的資源流行度;
利用耦合用戶行為的文檔主題生成模型lda,遍歷收視類型數據和交互行為數據分別生成對應狄利克雷分布,通過鏈式法則推導每個行為模式的全概率并求取其狄利克雷分布的期望,得到行為模式矩陣;
結合神經網絡模型,將所統計數據的資源流行度與行為模式矩陣作為神經網絡輸入,經過訓練生成預測模型,根據訓練的預測模型來預測未來的視頻資源流行度。
所述統計一定區域內群體用戶的收視數據,獲得群體用戶的收視類型數據和交互行為數據包括:
統計一個地區所有群體用戶的觀看日志,通過劃分時間段和節目類型,得到群體用戶一定天數內不同時間段的收視類型數據和交互行為的數據;
其中,劃分時間段是指對一天的時間進行劃分,若將一天劃分為24個時間段,則每一時間段即為一個小時;
交互行為是指用戶在點播業務中的播放狀態,共有10種:節目收藏、首次啟動播放、再次啟動播放、快進狀態、快退狀態、暫停狀態、定位播放、播放失敗、退出播放與記憶播放。
所述利用收視類型數據來計算所統計數據的資源流行度包括:
將收視類型數據用集合c={ci|i=1,2,···,k}表示,集合c中的元素ci按收視類型編號,ci表示i類收視類型,其被用戶訪問的時間在總收視時長中的占比為pi,則pi是ci在集合c中的流行度,且p={pi|i=1,2,···,k}是集合c的資源流行度集合;其中,k為收視類型的總數量。
所述利用耦合用戶行為的文檔主題生成模型lda,遍歷收視類型數據和交互行為數據分別生成對應狄利克雷分布,通過鏈式法則推導每個行為模式的全概率并求取其狄利克雷分布的期望,得到行為模式矩陣包括:
假設收視類型數據中有k種收視類型vw部節目,交互行為數據中有l種行為類型vl個交互行為;
對某一收視類型的節目中出現某一類型的交互行為,則稱為行為模式;第m個文檔中用戶的行為模式多項式分布
zmn2=(zmnmodk)
利用耦合用戶行為的lda模型,遍歷收視類型數據和交互行為數據分別生成對應狄利克雷分布,其過程如下:
令:
計算狄利克雷分布θ,φ,ψ:
其中,
基于狄利克雷分布θ,φ,ψ,并通過鏈式法則推導每個行為模式的全概率:
其中,
最終基于狄利克雷分布θ,φ,ψ以及每個行為模式的全概率求解狄利克雷分布的期望,推導得到如下公式:
其中,
所述結合神經網絡模型,將所統計數據的資源流行度與行為模式矩陣作為神經網絡輸入,經過訓練生成預測模型,根據訓練的預測模型來預測未來的視頻資源流行度包括:
利用bp神經網絡實現對行為模式矩陣和統計數據的資源流行度的非線性映射,輸入層和輸出層神經元個數與輸入輸出參數有關,輸入的行為模式矩陣節目的收視類型有k種,輸出為未來的視頻資源流行度,則輸入層和輸出層節點個數分別為k和1,隱含層節點數設為s個;
將統計數據的資源流行度,以及行為模式矩陣中不同收視類型的節目的行為向量讀入,再將讀入數據劃分為訓練數據和測試數據;
開始初始化bp神經網絡,訓練方法采用最速下降法,批量方式訓練行為模式數據,然后采用批量訓練的方式將樣本輸入bp神經網絡,計算每個樣本的誤差;最后判斷是否收斂,若不收斂,根據最速下降法調整權值,直至收斂,從而獲得預測模型;
將劃定的測試數據輸入bp神經網絡,利用預測模型來預測未來的視頻資源流行度。
由上述本發明提供的技術方案可以看出,對地區內用戶數據按節目類型進行群體分析,有效弱化了單個影片短期爆發對流行度預測精度的影響;通過耦合用戶行為的lda模型對收視內容和交互行為進行聯合分析,避免了研究單一數據導致的信息缺失,更加準確地發現群體用戶行為模式;采用神經網絡模型,根據融合了行為數據的行為模式矩陣預測視頻資源流行度,提高了預測的非線性處理能力,從而降低預測誤差;此外,將本發明提供的方法應用于云服務器的資源調度中,能有效地提高請求接受率,提升用戶體驗。
附圖說明
為了更清楚地說明本發明實施例的技術方案,下面將對實施例描述中所需要使用的附圖作簡單地介紹,顯而易見地,下面描述中的附圖僅僅是本發明的一些實施例,對于本領域的普通技術人員來講,在不付出創造性勞動的前提下,還可以根據這些附圖獲得其他附圖。
圖1為本發明實施例提供的一種視頻資源流行度預測方法的流程圖;
圖2為本發明實施例提供的行為模式發現的流程圖;
圖3為本發明實施例提供的行為模式矩陣的示意圖;
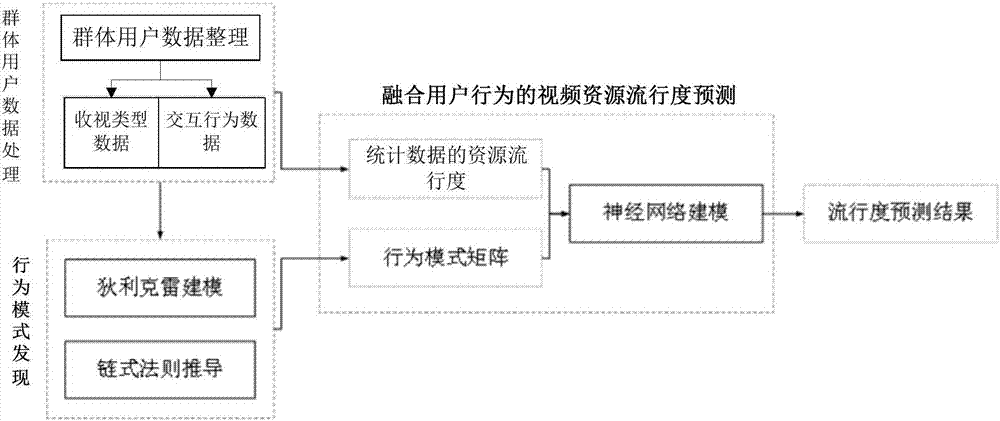
圖4為本發明實施例提供的融合用戶行為的視頻資源流行度預測的流程圖。
具體實施方式
下面結合本發明實施例中的附圖,對本發明實施例中的技術方案進行清楚、完整地描述,顯然,所描述的實施例僅僅是本發明一部分實施例,而不是全部的實施例。基于本發明的實施例,本領域普通技術人員在沒有做出創造性勞動前提下所獲得的所有其他實施例,都屬于本發明的保護范圍。
本發明實施例提供一種視頻資源流行度預測方法,該方法對用戶群體數據從資源類型維度進行處理,生成用戶群體收視數據;對于收視數據分析,不是單獨處理收視內容或者交互行為,而是融合兩類數據推導其聯合概率分布,從而精確描述兩類數據的內在關系;在預測方法上,將聯合概率矩陣輸入到神經網絡模型來預測視頻資源流行度,建立兩者間的準確映射關系。
如圖1所述,為一種視頻資源流行度預測方法的流程圖。首先,統計一定區域內群體用戶的收視數據,獲得群體用戶的收視類型數據和交互行為數據,并利用收視類型數據來計算所統計數據的資源流行度;然后,利用耦合用戶行為的文檔主題生成模型lda,遍歷收視類型數據和交互行為數據分別生成對應狄利克雷分布,通過鏈式法則推導每個行為模式的全概率并求取其狄利克雷分布的期望,得到行為模式矩陣;最后,結合神經網絡模型,將所統計數據的資源流行度與行為模式矩陣作為神經網絡輸入,經過訓練生成預測模型,根據訓練的預測模型來預測未來的視頻資源流行度。該方法綜合考慮用戶收視交互內容數據和交互行為數據對資源流行度預測的影響,研究兩類數據與流行度之間的關系,提高對資源流行度預測的準確性,進而有效改善流媒體云服務器的資源部署效率,提升請求接入和響應的服務質量。
下面針對各個步驟做詳細的說明。
一、群體用戶數據處理。
本發明實施例中,群體用戶數據處理的目的是,通過統計一個地區所有群體用戶的觀看日志,再通過劃分時間段和節目類型,可以得到群體用戶一定天數內不同時間段的收視類型數據和交互行為的數據。同時,對群體數據處理可以有效忽略個別用戶的行為模式變異,行為模式變異指的是某些用戶因為具有特殊的行為模式,如只快進或者只看某類節目。從群體角度處理可以將這些不確定變異對流行度預測的影響弱化到最小。
本發明實施例中,劃分時間段是指對一天的時間進行劃分,若將一天劃分為24個時間段,則每一時間段即為一個小時,那么25天的數據集樣本就可以劃分為600個時間段集合。
收視類型可以劃分為15個類型,分別為新聞、財經、綜藝、體育、電影、動漫、軍事、電視劇、科教、生活、時尚旅游、親子教育、音樂、老人節目和少兒節目。
交互行為是指用戶在點播業務中的播放狀態,共有10種:節目收藏、首次啟動播放、再次啟動播放、快進狀態、快退狀態、暫停狀態、定位播放、播放失敗、退出播放與記憶播放。
此外,本發明實施例還利用收視類型數據來計算所統計數據的資源流行度,作為神經網絡的一個輸入。具體來說:將收視類型數據用集合c={ci|i=1,2,···,k}表示,集合c中的元素ci按收視類型編號,ci表示i類收視類型,其被用戶訪問的時間在總收視時長中的占比為pi,則pi是ci在集合c中的流行度,且p={pi|i=1,2,···,k}是集合c的資源流行度集合;其中,k為收視類型的總數量。
二、行為模式發現。
lda模型作為經典的文本主體生成模型,可以獲取一個數據集中錯綜復雜的主題集合,在廣電數據研究背景下,本發明采用耦合用戶行為的lda模型對群體用戶數據進行研究。如圖2所示,選取用戶過去一個時間段內的收視數據,對每個節目進行類型標定,把節目類型作為文檔生成模型的主題,lda模型可以準確的生成不同節目類型的集合;不同節目類型中用戶的收視行為模式各不相同,因此,把行為模式分布
耦合用戶行為的lda模型作為lda模型的擴展,可以對行為主體進行聯合分析。結合圖3,假設收視類型數據中有k種收視類型vw部節目,則類型-節目的聯合分布φ'是k×vw維矩陣,
本發明實施例中,對于某一收視類型的節目出現某一類型的交互行為,稱之為行為模式;第m個文檔中用戶的行為模式多項式分布
zmn2=(zmnmodk)
利用耦合用戶行為的lda模型,遍歷收視類型數據和交互行為數據分別生成對應狄利克雷分布,其過程如下:
令:
計算狄利克雷分布θ:
上式中的,
同理可以得到狄利克雷分布φ,ψ:
其中,
基于狄利克雷分布θ,φ,ψ,并通過鏈式法則推導每個行為模式的全概率:
其中,
上式的含義是指根據已有的三類分布的先驗參數(即α,β,γ)和節目、行為和行為模式的集合(即
此外,
表1
上表中的第一行第一列θ11到最后一行最后一列θmi所有行為模式的發生概率組合構成
最終基于狄利克雷分布θ,φ,ψ以及每個行為模式的全概率求解狄利克雷分布的期望,推導得到如下公式:
其中,
本發明實施例中,各個參數的含義說明如表2所示。
表2融合用戶行為的clda模型中參數說明表
三、融合用戶行為的視頻資源流行度預測
融合用戶行為的視頻資源流行度預測是指,利用神經網絡模型進行預測,將融合了用戶收視數據和交互行為的行為模式矩陣輸入模型,使每一個行為模式矩陣映射到一個流行度集合,根據模型預測未來視頻資源流行度。
本發明實施例中,利用bp神經網絡實現對行為模式矩陣和統計數據的資源流行度的非線性映射,輸入層和輸出層神經元個數與輸入輸出參數有關,輸入的行為模式矩陣節目的收視類型有k種,輸出為未來的視頻資源流行度,則輸入層和輸出層節點個數分別為k和1,隱含層節點數設為s個。
如圖4所示,將統計數據的資源流行度,以及行為模式矩陣中不同收視類型的節目的行為向量讀入,再將讀入數據劃分為訓練數據和測試數據;開始初始化bp神經網絡,訓練方法采用最速下降法,批量方式訓練行為模式數據,然后采用批量訓練的方式將樣本輸入bp神經網絡,計算每個樣本的誤差,示例性的,可以定義流行度集合的誤差容限為0.1;最后判斷是否收斂,若不收斂,根據最速下降法調整權值,直至收斂,從而獲得預測模型;將劃定的測試數據輸入bp神經網絡,利用預測模型來預測未來的視頻資源流行度。最終,將預測得到的視頻資源流行度和統計得到的視頻流行度分別應用在云服務器上,可以知道,本發明對性能提升有顯著的積極影響。
本發明實施例上述方案,對地區內用戶數據按節目類型進行群體分析,有效弱化了單個影片短期爆發對流行度預測精度的影響;通過耦合用戶行為的lda模型對收視內容和交互行為進行聯合分析,避免了研究單一數據導致的信息缺失,更加準確地發現群體用戶行為模式;采用神經網絡模型,根據融合了行為數據的行為模式矩陣預測視頻資源流行度,提高了預測的非線性處理能力,從而降低預測誤差;此外,將本發明提供的方法應用于云服務器的資源調度中,能有效地提高請求接受率,提升用戶體驗。
通過以上的實施方式的描述,本領域的技術人員可以清楚地了解到上述實施例可以通過軟件實現,也可以借助軟件加必要的通用硬件平臺的方式來實現。基于這樣的理解,上述實施例的技術方案可以以軟件產品的形式體現出來,該軟件產品可以存儲在一個非易失性存儲介質(可以是cd-rom,u盤,移動硬盤等)中,包括若干指令用以使得一臺計算機設備(可以是個人計算機,服務器,或者網絡設備等)執行本發明各個實施例所述的方法。
以上所述,僅為本發明較佳的具體實施方式,但本發明的保護范圍并不局限于此,任何熟悉本技術領域的技術人員在本發明披露的技術范圍內,可輕易想到的變化或替換,都應涵蓋在本發明的保護范圍之內。因此,本發明的保護范圍應該以權利要求書的保護范圍為準。
- 還沒有人留言評論。精彩留言會獲得點贊!