數據包傳輸系統及方法與流程
本發明涉及通信技術領域,尤其涉及一種數據包傳輸系統及方法。
背景技術:
隨著移動通信技術的發展,越來越多的移動終端如智能手機具有雙卡雙通的功能,使得用戶在實現語音業務的待機同時,能建立數據業務連接。移動終端通常具有兩個用戶識別卡以及分別與所述兩個用戶識別卡連接的調制解調器,兩個用戶識別卡全開時,一個用戶識別卡(sim1)可以使用4g(the4thgenerationmobilecommunicationtechnology,第四代移動通信技術),例如lte(longtermevolution,長期演進技術)網絡,另一個用戶識別卡(sim2)僅能使用2g(2-generationwirelesstelephonetechnology,第二代手機通信技術規格)或3g(3rdgeneration,第三代移動通信技術)網絡,sim2不能上4g的原因主要是:移動終端只有一套射頻,兩張卡使用該套射頻是分時復用的關系,并不能同時占用,由于兩張卡全開時,只有一張卡可以使用4g網絡,另一張卡只能使用2g或3g網絡,導致移動終端中數據傳輸的效率較低。
因此,為了使移動終端可以支持雙lte,以提高數據傳輸效率,移動終端可與外接設備連接(該外接設備中設置有調制解調器),以實現雙lte通信功能。但是,目前移動終端和外接設備進行數據包傳輸過程中,如果移動終端中的用戶識別卡是電信卡,由于電信卡一般都大于移動終端和外接設備之間數據傳輸的臨時緩沖區buffer的容量值,因此buffer無法緩存一個完整的數據包,若是直接進行數據傳輸,容易導致移動終端死機。
技術實現要素:
本發明的主要目的在于提出一種數據包傳輸系統及方法,旨在解決現有的數據包傳輸方式,容易導致移動終端死機的技術問題。
為實現上述目的,本發明提供的一種數據包傳輸系統,所述數據包傳輸系統包括移動終端,以及通過預設接口與所述移動終端連接的外接設備,所述移動終端包括第一應用處理器、內嵌有虛擬用戶識別卡的第一調制解調器、第一射頻模塊,以及與所述第一調制解調器連接的第一用戶識別卡和第二用戶識別卡,所述外接設備包括第二應用處理器、第二調制解調器和第二射頻模塊;
所述第一應用處理器,用于通過預設接口接收第二應用處理器發送的數據包獲取請求時,從虛擬用戶識別卡中提取所述數據包獲取請求對應的數據包;對提取的數據包進行壓縮;將壓縮后的數據包緩存至所述預設接口的臨時緩沖區buffer中,以供第二應用處理器從所述buffer中提取壓縮后的數據包,以完成數據包的傳輸。
可選地,所述第一應用處理器,還用于判斷能否從所述數據包獲取請求中提取出第二應用處理器添加的壓縮標識;若能提取出壓縮標識,則對提取的數據包進行壓縮。
可選地,所述第一應用處理器,還用于對提取的所述數據包進行解析,以得到所述數據包的包頭;基于所述數據包的包頭確定所述數據包的長度;在所述數據包的長度大于預設閾值時,則對提取的數據包進行壓縮。
可選地,所述第一應用處理器對提取的數據包進行壓縮具體包括:
所述第一應用處理器獲取所述數據包對應的源文本;
確定源文本中出現頻率大于預設頻率的字符段;
在預設字典列表中,查找所述字符段對應的編碼,其中,編碼的長度小于對應的字符段的長度;
通過查找的編碼代替對應的字符段,以實現數據包的壓縮。
可選地,所述第一應用處理器,還用于確定源文本中是否存在內容相同且長度大于預設值的字符段;
若存在,確定后一個字符段與前一個字符端的距離以及所述字符段的長度;
采用距離與長度的標識代替后一個字符段,以實現數據包的壓縮。
此外,為實現上述目的,本發明還提出一種數據包傳輸方法,應用于移動終端以及通過預設接口與移動終端連接的外接設備,所述移動終端包括第一應用處理器、內嵌有虛擬用戶識別卡的第一調制解調器、第一射頻模塊,以及與所述第一調制解調器連接的第一用戶識別卡和第二用戶識別卡,所述外接設備包括第二應用處理器、第二調制解調器和第二射頻模塊,所述方法包括:
第一應用處理器通過預設接口接收第二應用處理器發送的數據包獲取請求時,從虛擬用戶識別卡中提取所述數據包獲取請求對應的數據包;
對提取的數據包進行壓縮;
將壓縮后的數據包緩存至所述預設接口的臨時緩沖區buffer中,以供第二應用處理器從所述buffer中提取壓縮后的數據包,以完成數據包的傳輸。
可選地,所述對提取的數據包進行壓縮的步驟之前,所述數據包傳輸方法還包括:
所述第一應用處理器判斷能否從所述數據包獲取請求中提取出第二應用處理器添加的壓縮標識;
若能提取出壓縮標識,則執行所述對提取的數據包進行壓縮的步驟。
可選地,所述對提取的數據包進行壓縮的步驟之前,所述數據包傳輸方法還包括:
所述第一應用處理器對提取的所述數據包進行解析,以得到所述數據包的包頭;
基于所述數據包的包頭確定所述數據包的長度;
在所述數據包的長度大于預設閾值時,執行所述對提取的數據包進行壓縮的步驟。
可選地,所述對提取的數據包進行壓縮的步驟包括:
所述第一應用處理器獲取所述數據包對應的源文本;
確定源文本中出現頻率大于預設頻率的字符段;
在預設字典列表中,查找所述字符段對應的編碼,其中,編碼的長度小于對應的字符段的長度;
通過查找的編碼代替對應的字符段,以實現數據包的壓縮。
可選地,所述第一應用處理器獲取所述數據包對應的源文本的步驟之后,所述對提取的數據包進行壓縮的步驟還包括:
確定源文本中是否存在內容相同且長度大于預設值的字符段;
若存在,確定后一個字符段與前一個字符端的距離以及所述字符段的長度;
采用距離與長度的標識代替后一個字符段,以實現數據包的壓縮。
本發明提出的技術方案,所述數據包傳輸系統包括移動終端,以及通過預設接口與所述移動終端連接的外接設備,所述移動終端包括第一應用處理器、第一調制解調器第一射頻模塊,以及與所述第一調制解調器連接的第一用戶識別卡和第二用戶識別卡,所述外接設備包括第二應用處理器、第二調制解調器和第二射頻模塊;所述第一應用處理器通過預設接口接收第二應用處理器發送的數據包獲取請求時,先從虛擬用戶識別卡中提取所述數據包獲取請求對應的數據包,然后對提取的數據包進行壓縮,再將壓縮后的數據包緩存至所述預設接口的buffer中,以供第二應用處理器從所述buffer中提取壓縮后的數據包,以完成數據包的傳輸。本方案在傳輸數據包時,先對待傳輸的數據包進行壓縮,再將壓縮后的數據包進行傳輸,使得傳輸的數據包的容量值有所減小,避免了數據傳輸過程中移動終端死機的情況。
附圖說明
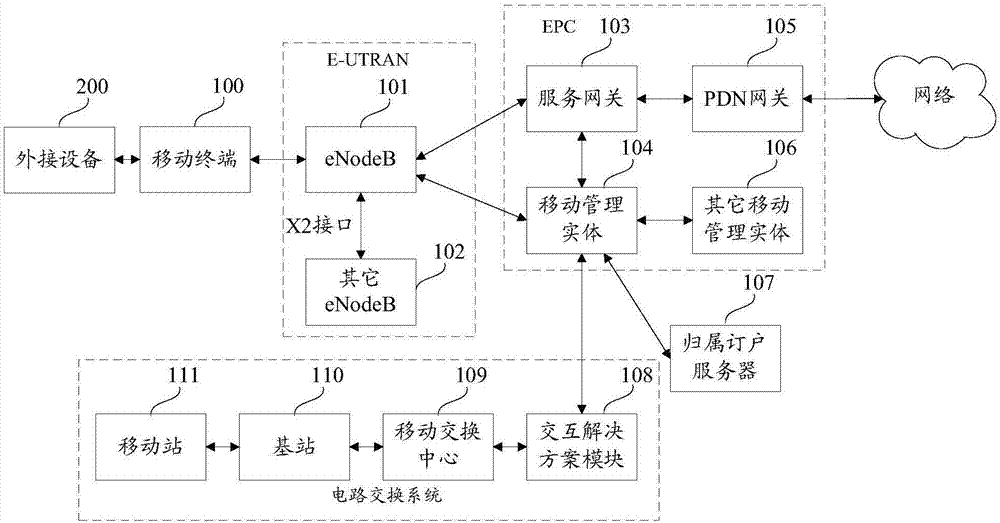
圖1為本發明一實施例的lte網絡架構的示意圖;
圖2為本發明實施例中移動終端和外接設備通訊連接的一種通訊連接的實體示意圖;
圖3為本發明實施例中移動終端和外接設備通訊連接的一種硬件結構示意圖;
圖4為本發明第一應用處理器和第二應用處理器之間的交互示意圖;
圖5為本發明數據包傳輸方法第一實施例的流程示意圖。
本發明目的的實現、功能特點及優點將結合實施例,參照附圖做說明。
具體實施方式
應當理解,此處所描述的具體實施例僅僅用以解釋本發明,并不用于限定本發明。需要說明的是,在不沖突的情況下,本發明中的實施例及實施例中的特征可以相互任意結合。
為了對本發明的技術特征、目的和效果有更加清楚的理解,現對照附圖詳細說明本發明的具體實施方式。
圖1是本發明一實施例的lte(longtermevolution,長期演進)網絡架構的示意圖。本發明一實施例的lte網絡架構包括:一個或多個移動終端(userequipment,ue)100、外接設備200、e-utran(evolvedumtsterrestrialradioaccessnetwork,演進的umts陸地無線接入網)(圖中未標號)、演進分組核心(epc)(圖中未標號)、歸屬訂戶服務器(hss)107、網絡(例如,因特網)(圖中未標號)以及電路交換系統(圖中未標號)。
e-utran包括演進b節點(enodeb)101和其它enodeb102。enodeb101提供朝向移動終端100的用戶面和控制面的協議終接。enodeb101可經由x2接口連接到其他enodeb。enodeb101也可稱為基站、基收發機站、無線電基站、無線電收發機、收發機功能、基本服務集、擴展服務集、或其他某個合適的術語。enodeb101為移動終端100提供去往epc的接入點。
enodeb101通過s1接口連接到epc。epc包括移動管理實體(eem)104、其他移動管理實體106、服務網關103,以及分組數據網絡(pdn)網關105。移動管理實體104是處理移動終端100與epc之間的信令的控制節點。移動管理實體104提供承載和連接管理。所有用戶ip分組通過服務網關103來傳遞,服務網關103自身連接到pdn網關105。pdn網關105提供ueip地址分配以及其他功能。pdn網關105連接到網絡,例如,因特網。
電路交換系統包括交互解決方案模塊(iws)108、移動交換中心(msc)109、基站110和移動站111。在一個方面,電路交換系統可以通過iws和mme(mobilitymanagemententity,移動管理實體)與eps(evolvedpacketsystem,演進的分組系統)進行通信。
移動終端100通過預設接口,如usb(universalserialbus,通用串行總線)數據線300與外接設備200通訊連接。
圖2為本發明移動終端100和外接設備200通訊連接的實體示意圖。
如圖2所示,移動終端100通過usb數據線300與外接設備200通訊連接,其中,所述移動終端包括但不限于手機、pc(personalcomputer,個人電腦)或pad(personaldigitalassistant,個人數字助理),所述外接設備200可選為無線上網卡或數據卡。
圖3為本發明移動終端100和外接設備200通訊連接的結構示意圖。
本發明實施例的移動終端100通過usb數據線300與外接設備200通訊連接,基于移動終端100和外接設備200通訊連接的基礎,移動終端100可支持雙lte。具體地:
移動終端100包括第一處理芯片001,以及與所述第一處理芯片001連接的第一射頻模塊12,其中,第一處理芯片001包括第一應用處理器(applicationprocessor,用ap1表示)10、內嵌有虛擬用戶識別卡11a且與第一用戶識別卡13和第二用戶識別卡14連接的第一調制解調器11(modem1)、rpm(resourcepowermanager,資源電源管理器)15,其中,虛擬用戶識別卡11a包括存儲模塊和虛擬片內操作系統(virtualchipoperatingsystem,vcos),該存儲模塊可為efs(encryptingfilesystem,加密文件系統),存儲模塊用于存儲虛擬用戶識別卡11a的鑒權數據。所述第一用戶識別卡13和第二用戶識別卡14為sim(subscriberidentitymodule,用戶識別模塊)卡。
外接設備200包括第二處理芯片002,以及與所述第二處理芯片002連接的第二射頻模塊22,其中,第二處理芯片002包括第二應用處理器(用ap2表示)20、第二調制解調器(modem2)21。
第一應用處理器10和第二應用處理器20的內部框架包括應用層、框架層等,可處理復雜的邏輯操作以及進行任務分配等。在一個實施例中,應用處理器指android操作系統,以及基于android操作系統的各種apk(androidpackage,安卓安裝包)。在本發明的實施例中,第一應用處理器10和第二應用處理器20通過usb數據線實現通訊連接,為用戶提供交互接口,將用戶輸入的操作指令(例如,用戶通過用戶界面輸入的有關啟動視頻通話的操作指令)傳輸給第一調制解調器11或第二調制解調器21,以實現兩個應用處理器之間數據的定義與傳遞,例如,進行兩個應用處理器的休眠、喚醒、同步的控制、開關機時芯片啟動順序的控制等。
應當理解的是,在本發明實施例中,usb數據線300復用出三條數據通道,分別用于第一應用處理器10和第二應用處理器20之間用戶數據、控制信令數據和sim卡鑒權數據的交互,即第一應用處理器10和第二應用處理器20通過usb數據線300傳輸的數據包括上述三種數據。其中,用戶數據包括上網產生的數據,圖片和聊天信息數據;控制信令數據包括開關機的控制數據,開關飛行模式的控制數據,顯示狀態信號的控制數據;sim卡鑒權數據包括但不限于imsi(internationalmobilesubscriberidentificationnumber,國際移動用戶識別碼)、ki(keyidentifier,鑒權密鑰)等等。
本實施例中,第一應用處理器10和第二應用處理器20通過otg(on-the-go)技術進行數據交互。通過otg技術,移動終端100中的第一調制解調器11可通過虛擬用戶識別卡11a、第一用戶識別卡13或第二用戶識別卡14中的sim卡參數來接入enodeb101,外接設備200中的第二調制解調器21也可通過第二用戶識別卡14、第一用戶識別卡13或虛擬用戶識別卡11a中的sim卡參數來接入enodeb101,所述sim卡參數包括但不限于sim卡鑒權數據。其中,usb接口的buffer存在于第一應用處理器10和第二應用處理器20的兩端,用buffer1和buffer2表示。需要說明的是,buffer1和buffer2對應著同一個物理地址,通過該物理地址,可控制buffer1和buffer2容量值和狀態的同步變化。
由于buffer1和buffer2對應著同一個物理地址,因此第一應用處理器10將提取的數據包緩存至buffer1時,數據包通過該uart發送至buffer2中緩存,第二應用處理器20在buffer2中檢測到該數據包時,即可獲取到該數據包,以實現數據包的傳輸。
第一調制解調器11和第二調制解調器21包含各種網絡交互的網絡制式的協議棧,協議棧包含lte(longtermevolution,長期演進)/wcdma(widebandcodedivisionmultipleaccess,寬帶碼分多址)/gsm(globalsystemformobilecommunication,全球移動通信系統)/td-scdma(timedivision-synchronouscodedivisionmultipleaccess,同步時分碼分多址)/cdma(codedivisionmultipleaccess,碼分多址)/edge(enhanceddatarateforgsmevolution,強型數據速率gsm演進技術)等通訊標準里邊規定的協議代碼。移動終端100通過協議與運營商網絡進行交互,即進行數據流量上網、volte(voiceoverlte)打電話或者cs(circuitswitched,電路交換)域打電話。第一調制解調器11和第二調制解調器21還用于對sim卡的管控等等。
在本發明實施例中,第一射頻模塊12用于將移動終端100傳輸的數據處理后傳給enodeb101(基站網絡),以及用于將enodeb101傳輸的數據處理后傳給移動終端100。第二射頻模塊22用于將外接設備200傳輸的數據處理后傳給enodeb101(基站網絡),以及用于將enodeb101傳輸的數據處理后傳給外接設備200。
第一射頻模塊12和第二射頻模塊22所涉及的無線接入技術可以包括lte、gsm、gprs(generalpacketradioservice,通用分組無線服務)、cdma、edge、wlan(wirelesslocalareanetworks,無線局域網)、cdma-2000、td-scdma、wcdma、wifi(wirelessfidelity,無線保真)等等。
移動終端100中的虛擬用戶識別卡11a、第一用戶識別卡13和第二用戶識別卡14存儲不同的無線通信標準相關聯用戶信息。應當理解,目前的移動終端只有一套射頻,移動終端內部的兩個用戶識別卡使用該套射頻是分時復用的關系,并不能同時占用。例如,在兩張用戶識別卡全開時,一張卡可以處理gsm通話,另一張卡只能處理4g網絡信息,具體哪個用戶識別卡執行何種網絡,不做限定。因此目前的射頻雙卡分時復用這種架構僅做到了lte+gsm(即一張用戶識別卡對應的技術標準為lte,另一張用戶識別卡對應的技術標準為gsm)。
也就是說,現有的移動終端100雖然可以支持雙用戶識別卡,但是移動終端100在注冊網絡的情況下,兩個用戶識別卡支持的是不同技術標準的網絡,一個支持2g或3g,另一個支持4g,會使得移動終端100使用過程中,上網流量速度較慢,因此本發明中,移動終端100通過usb數據線300連接外接設備200,由于外接設備200包括第二射頻模塊22,且第二射頻模塊22支持4g網絡,因此,移動終端100可通過usb線300與外接設備200交互,從而使得移動終端100具備雙lte功能。
在本實施例中,數據包傳輸系統包括移動終端100和外接設備200,移動終端100通過外接設備200具備雙lte功能的實現過程可為:①第二用戶識別卡14通過第二調制解調器21支持lte,具體過程為:第一調制解調器11將第二用戶識別卡14中需要訪問lte網絡的數據發送給第一應用處理器10,第一應用處理器10將所接收的數據通過usb發送給外接設備200的第二應用處理器20,第二應用處理器20將所接收的數據發送給第二調制解調器21,由第二調制解調器21轉發給第二射頻模塊22,第二射頻模塊22將所接收的數據通過lte網絡發送出去;而第一用戶識別卡13通過第一調制解調器11支持lte,以實現移動終端100可支持雙lte。②第一用戶識別卡13通過第二調制解調器21支持lte,具體過程為:第一應用處理器10將第一用戶識別卡13中需要訪問lte網絡的數據通過usb發送給外接設備200的第二應用處理器20,第二應用處理器20將所接收的數據發送給第二調制解調器21,由第二調制解調器21轉發給第二射頻模塊22,第二射頻模塊22將所接收的數據通過lte網絡發送出去;而第二用戶識別卡14通過第一調制解調器11支持lte,以實現移動終端100可支持雙lte。當然,可用虛擬用戶識別卡11a替代上述的第一用戶識別卡13和第二用戶識別卡14,具體不做贅述。
在本實施例中,虛擬用戶識別卡11a、第一用戶識別卡13和第二用戶識別卡14用于提供移動通信業務(cs語音業務、ps數據業務和ps語音業務)所需的相關數據,并在其內部存儲用戶信息、短消息、執行鑒權算法和產生加密密匙等。
用戶識別卡(虛擬用戶識別卡11a、第一用戶識別卡13和第二用戶識別卡14)與移動終端100交互時,移動終端100檢測該用戶識別卡存在與否的信號只在開機瞬時產生,當開機檢測不到用戶識別卡存在時,移動終端100將提示“插入用戶識別卡”。移動終端100開機之后,移動終端100和用戶識別卡之間28秒通信一次,完成一些固定的通信檢查(例如,用戶識別卡是否在位等)。
在本發明的實施例中,虛擬用戶識別卡11a、第一用戶識別卡13和第二用戶識別卡14承載信息,并且根據外界請求返回對應卡參數,以及對網絡進行鑒權運算,第一射頻模塊12和第二射頻模塊22所涉及的無線接入技術為lte。例如,當移動終端100未通過usb與外接設備200連接時,第一用戶識別卡13所對應的技術標準為gsm,用于進行語音通訊,第二用戶識別卡14通過第一調制解調器11支持lte,用于通過4g網絡進行數據訪問。當移動終端100通過usb數據線300與外接設備200連接時,第一用戶識別卡13可通過移動終端100中的第一調制解調器11支持lte,而第二用戶識別卡14通過第二調制解調器21支持lte;或者,第一用戶識別卡13可通過第二調制解調器21支持lte,而第二用戶識別卡14通過第一調制解調器11支持lte,以實現移動終端100連接外接設備200情況下可支持雙lte。
移動終端100中的rpm15用于管控各種資源,包括時鐘資源、總線資源、pmic(powermanagementic,電源管理集成電路,即各個芯片的電壓)、ddr(內存分配),以及管理芯片的休眠喚醒的中斷和應用處理器喚醒的截止時間。移動終端100的各個子系統,在需要資源時,向rpm15申請資源,各個子系統分別包括第一應用處理器10,第一調制解調器11、pronto(wifi/藍牙、nfc(nearfieldcommunication,近場通信)等)、lpass(lowpoweraudiosubsystem,低功耗音頻子系統),rpm15用來決定移動終端100系統的休眠狀態,具體是,rpm15基于各個子系統的投票機制實現,當各個子系統都投休眠票時,rpm15才可以使移動終端100整個系統進行休眠。
在移動終端100的整個系統休眠之后,若是要重新啟動運行,需要喚醒第一應用處理器10以進行數據的傳輸交互。
在移動終端100和外接設備200通過usb數據線300通訊連接的情況下,喚醒方式包括三種:
1、第一應用處理器10接收到控制信令數據時,通過usb數據線300傳送探測包給第二應用處理器20,以喚醒第二應用處理器20。
2、外接設備200的第二調制解調器21接收到用戶數據時,喚醒第二應用處理器20,由第二應用處理器20通過usb數據線300傳送探測包給第一應用處理器10,以喚醒第一應用處理器10。
3、第二調制解調器21周期性查找尋呼請求,以主動激活自己,若接收到尋呼請求,喚醒第二應用處理器20,由第二應用處理器20通過usb數據線300發送探測包給第一應用處理器10,以喚醒第二應用處理器20。
此外,第二調制解調器21還可以定期喚醒自己,以在移動終端100進行位置更新時,跟基站進行握手交互,此時不需要喚醒第一應用處理器10。
需要說明的是,傳輸的數據包為用戶數據、控制信令數據或用戶識別卡數據即sim卡數據時,三種數據都在應用處理器之間傳輸。
本實施例中,sim卡包括移動卡、聯通卡和電信卡,其中,移動卡和聯通卡是指采用3gpp標準協議進行通訊的電話卡,3gpp標準協議規定了電話卡傳輸數據包的容量不能超出一定值,該值設置為512個字節;而電信卡是指采用3gpp2標準協議的電話卡,gpp2標準協議對電信卡傳輸的數據包的容量未做限制,電信卡傳輸的數據包的容量一般會超出512字節。其中,移動卡是由中國移動(運營商)向用戶提供的sim卡,聯通卡是由中國聯通(運營商)向用戶提供的sim卡,電信卡是由中國電信(運營商)向用戶提供的sim卡。
由于現有的buffer的容量一般都不超過512個字節。因此,當移動終端100中的虛擬用戶識別卡11a、第一用戶識別卡13和第二用戶識別卡14都是移動卡或者是聯通卡時,由于移動卡或者是聯通卡收發數據包的數據容量小于512個字節的,因此,第一應用處理器10接收到數據包獲取請求時,從虛擬用戶識別卡11a、第一用戶識別卡13和第二用戶識別卡14獲取到的數據包也是小于512個字節,相應的,存儲到buffer的數據包也是小于512個字節的,因此,數據包可完整的存儲到buffer中,后續,第二應用處理器20也可以取出一個完整的數據包。
但是,由于電信卡一般大于512字節,因此,在第一應用處理器10和第二應用處理器20的數據交互過程中,若是第一應用處理器10中連接的是電信卡,會出現這樣的情況:
以圖3為例,在虛擬用戶識別卡11a、第一用戶識別卡13和第二用戶識別卡14為電信卡的情況下,移動終端100第一應用處理器10通過第一調制解調器11從虛擬用戶識別卡11a、第一用戶識別卡13中或第二用戶識別卡14提取出一個數據包,由于該數據包大于512字節,而buffer一次性只能緩存不超過512字節的數據包,這種情況下,會由于無法轉發大數據包導致移動終端的系統死機。
若是要解決這個問題,按照常規的思路,不會將該數據包一次性進行轉發,而是拆分成多個數據包進行轉發,但是對于第二應用處理器20而言,當從buffer檢測到有數據包時,認為該數據包是完整的數據包,此時第二應用處理器20直接從buffer獲取該數據包,并將該數據包轉發至基站。很明顯,這種情況下,轉發的數據包是不完整的數據包。
基于上述lte網絡的架構圖、以及移動終端100和外接設備200通訊連接的結構示意圖,提出本發明的各個實施例。
參照圖3,本實施例提出一種數據包傳輸系統,所述數據包傳輸系統包括移動終端100,以及通過預設接口與所述移動終端100連接的外接設備200,所述移動終端100包括第一應用處理器10、內嵌有虛擬用戶識別卡11a的第一調制解調器11、第一射頻模塊12,以及與所述第一調制解調器11連接的第一用戶識別卡13和第二用戶識別卡14,所述外接設備200包括第二應用處理器20、第二調制解調器21和第二射頻模塊22;
所述第一應用處理器10,用于通過預設接口接收第二應用處理器20發送的數據包獲取請求時,從虛擬用戶識別卡11a中提取所述數據包獲取請求對應的數據包;對提取的數據包進行壓縮;將壓縮后的數據包緩存至所述預設接口的臨時緩沖區buffer中,以供第二應用處理器20從所述buffer中提取壓縮后的數據包,以完成數據包的傳輸。
在本實施例中,所述第一應用處理器10通過預設接口接收第二應用處理器20發送的數據包獲取請求,后續也是通過所述預設接口將數據包反饋至所述第二應用處理器20。所述預設接口為usb接口。
其中,當第二處理芯片002的第二調制解調器21通過第二射頻模塊22接收到基站發送的數據包獲取請求時,將數據包獲取請求發送至第二處理芯片002的第二應用處理器20中,當第二應用處理器20接收到數據包獲取請求時,先通過usb數據線300將數據包獲取請求傳送至移動終端100的第一應用處理器10中;第一應用處理器10接收到該數據包獲取請求時,將數據包獲取請求傳送至移動終端100的第一調制解調器11中,由第一調制解調器11根據該數據包獲取請求從虛擬用戶識別卡11a中獲取數據包;第一調制解調器11獲取到數據包之后,將數據包傳輸至第一應用處理器10中;第一應用處理器10獲取到數據包之后,為了保證傳輸的數據不會大于usb的buffer,先對獲取的數據包進行壓縮,得到壓縮后的數據包;再通過usb將壓縮后的數據包傳送至第二應用處理器20;第二應用處理器20在接收到數據包后,再將數據包傳送至第二射頻模塊22,由第二射頻模塊22將數據包上傳至基站,以完成數據的傳輸。
本實施例中,第一應用處理器不限于從第一調制解調器內嵌的虛擬用戶識別卡11a中獲取數據包,當然,也可根據實際需要在第一用戶識別卡13或第二用戶識別卡14中獲取數據包,第一應用處理器在虛擬用戶識別卡11a、第一用戶識別卡13或第二用戶識別卡14中獲取數據包的方式一致,下文為了簡述,僅以在虛擬用戶識別卡中獲取數據包為例,其它兩種不再贅述。
具體地,所述第一應用處理器10,還用于通過第一調制解調器11向虛擬用戶識別卡11a中的片內操作系統發送數據包獲取請求,由所述片內操作系統在虛擬用戶識別卡11a中的文件存儲模塊中提取所述數據包獲取請求對應的數據包,并反饋至所述第一調制解調器11;
所述第一應用處理器10,還用于通過第一調制解調器11接收片內操作系統反饋的數據。
在本實施例中,需要說明的是,虛擬用戶識別卡11a中的數據包存儲在文件存儲模塊中,當第一調制解調器11要獲取虛擬用戶識別卡11a中的數據包時,第一調制解調器11不會直接與虛擬用戶識別卡11a中的文件存儲模塊交互,而是先向虛擬用戶識別卡11a中的cos(chipoperatingsystem,片內操作系統)操作系統發送數據包獲取請求即request,然后虛擬用戶識別卡11a的cos操作系統基于該request在文件存儲模塊中獲取數據包,然后將獲取的數據包再傳輸給第一調制解調器11,第一調制解調器11只要接收cos操作系統反饋的數據包即可,后續第一應用處理器10在第一調制解調器11中獲取數據包即可實現數據包的獲取過程。
可以理解,由于第一調制解調器11無法在虛擬用戶識別卡11a中的文件存儲模塊直接提取數據包,因此通過與虛擬用戶識別卡11a的cos操作系統進行交互,以實現數據包的提取,保證后續的數據傳輸過程正常運行。
當第一應用處理器10從虛擬用戶識別卡11a中提取出數據包獲取請求對應的數據包之后,再對提取的數據包進行壓縮,本實施例中,第一應用處理器10對數據包進行壓縮時,可以采用加密壓縮的方式進行數據包的壓縮,也可以直接采用明文進行壓縮。由于傳輸的sim卡網絡鑒權數據量比較小,為了減少加密解密等操作而導致數據傳輸效率低,本發明實施例優選采用明文壓縮的方式對數據包進行壓縮,即本方案中采用的壓縮算法以簡單高效為主,具體采用的壓縮算法和壓縮過程在下文實施例中詳述。
第一應用處理器10對數據包壓縮之后,即可將壓縮后的數據包緩存至所述預設接口usb的buffer中,以供第二應用處理器20從所述buffer中提取壓縮后的數據包,以完成數據包的傳輸。
本實施例中需要說明的是,buffer存在于usb接口的兩端,即usb接口的兩端分別設置有buffer1和buffer2。當第二應用處理器20將數據包獲取請求通過usb接口發送給第一應用處理器10時,第一應用處理器10通過第一調制解調器11從虛擬用戶識別卡11a提取出數據包之后,先將提取的數據包存儲到buffer1中,以通過usb傳輸至buffer2,第二應用處理器20再從buffer2中獲取數據包。
本實施例提出的技術方案,所述第一應用處理器通過預設接口接收第二應用處理器發送的數據包獲取請求時,先從虛擬用戶識別卡中提取所述數據包獲取請求對應的數據包,然后對提取的數據包進行壓縮,再將壓縮后的數據包緩存至所述預設接口的buffer中,以供第二應用處理器從所述buffer中提取壓縮后的數據包,以完成數據包的傳輸。本方案在傳輸數據包時,先對待傳輸的數據包進行壓縮,再將壓縮后的數據包進行傳輸,使得傳輸的數據包的容量值有所減小,避免了數據傳輸過程中移動終端死機的情況。
進一步地,基于第一實施例提出本發明數據包傳輸系統第二實施例。
數據包傳輸系統第二實施例與數據包傳輸系統第一實施例的區別在于,所述第一應用處理器10,還用于判斷能否從所述數據包獲取請求中提取出第二應用處理器20添加的壓縮標識;若能提取出壓縮標識,則對提取的數據包進行壓縮。
在本實施例中,當第二應用處理器20向第一應用處理器10發送數據包獲取請求(request)之前,為了防止傳輸的數據包過大,第二應用處理器20發送request時,先確定是否需要在request中添加壓縮標識,若需要,則先在request中添加一個壓縮標識,如添加字段01,以告知第一應用處理器10對待發送的數據包進行壓縮。
需要說明的是,由于待傳輸的數據是根據通訊協議標準確定的,因此,第二應用處理器20可以得知即將獲取的數據包的數據類型和數據大小,那么,當第二應用處理器20發送request之前,先判斷當前待獲取的數據包的大小,若待獲取的數據包的大小超出了buffer的容量值,則第二應用處理器20在request中添加壓縮標識,以告知第一應用處理器10對待傳輸的數據包進行壓縮,若第二應用處理器20判斷待獲取的數據包的大小未超出buffer的容量值,則直接發送request即可,無需添加壓縮標識。
在本實施例中,第二應用處理器20發送request之前,對待獲取的數據包的大小進行識別,僅在待獲取的數據包超出buffer的容量值時,才在request添加壓縮標識,避免了所有的數據包獲取請求都添加壓縮標識,縮短了數據包傳輸的時間,提高了數據包傳輸的效率。
當第一應用處理器10通過預設接口(usb)接收第二應用處理器20發送的數據包獲取請求時,先對所述數據包獲取請求進行解析,以確定能否從所述數據包獲取請求中提取出第二應用處理器20添加的壓縮標識,若在所述數據包獲取請求中提取出壓縮標識,此時,所述第一應用處理器10即可對提取的數據包進行壓縮,后續再將壓縮后的數據包緩存至所述預設接口的buffer1中,并通過usb傳輸至buffer2中,以供第二應用處理器20從所述buffer2中提取壓縮后的數據包,以完成數據包的傳輸。
在本實施例中,數據包傳輸過程是發生第一應用處理器10和第二應用處理器20喚醒之后,那么當第一應用處理器10和第二應用處理器20喚醒之后,若第二應用處理器20通過第二調制解調器21連接的第二射頻模塊22接收到基站發送的數據包獲取請求,執行以下操作:
判斷:先確定待獲取的數據包的大小,以判斷是否需要添加壓縮標識;
決策:若待獲取的數據包超過usb的buffer的容量,則在發送數據包獲取請求之前,在數據包獲取請求添加壓縮標識;
發送:在數據包獲取請求添加壓縮標識之后,發送數據包獲取請求。
第一應用處理器10通過usb接收到數據包獲取請求時,執行以下操作:
提取:確定能否從數據包獲取請求中提取出壓縮標識,若能,則提取出壓縮標識;
壓縮:基于提取的壓縮標識,對通過第一調制解調器11從虛擬用戶識別卡11a提取的數據包進行壓縮;
反饋:反饋壓縮的數據包。
最終,第二應用處理器20通過usb接收第一應用處理器10反饋的數據包,以完成數據包傳輸過程。上述的操作過程,可參照圖4。
需要說明的是,第二應用處理器20發送的是數據包獲取請求,由于數據包獲取請求一般都小于buffer的容量,因此可不對數據包獲取請求進行壓縮。
在本實施例中,第一應用處理器10在對數據包進行壓縮之前,先判斷能否從所述數據包獲取請求中提取出第二應用處理器20添加的壓縮標識,若能提取出壓縮標識,才對數據包進行壓縮,防止數據包小于buffer的容量時也進行壓縮,以防止系統資源的浪費,并且節省了數據包傳輸的時間,從而提高了數據包傳輸的效率。
進一步地,基于第一實施例提出本發明數據包傳輸系統第三實施例。
數據包傳輸系統第三實施例與數據包傳輸系統第一實施例的區別在于,所述第一應用處理器10,還用于對提取的所述數據包進行解析,以得到所述數據包的包頭;基于所述數據包的包頭確定所述數據包的長度;在所述數據包的長度大于預設閾值時,則對提取的數據包進行壓縮。
在本實施例中,所述第一應用處理器10對數據包進行壓縮之前,先對從第一用戶識別卡13或第二用戶識別卡14中提取的數據包進行解析,以得到所述數據包的包頭,然后從包頭中獲取數據包的長度,以確定該數據包的大小。其中,數據包為tlv格式,tlv格式是ber(basicencodingrules,基本編碼規則)編碼的一種,全稱為type(類型),length(長度),value(值),t字段表示數據包的類型,l字段表示數據包的長度、v字段用于存放數據包的內容。
本實施例中,該數據包的生成過程為:傳輸層獲取到數據包對應的原始數據,并為原始數據添加傳輸層的數據包頭,數據包頭包括傳輸層數據類型和數據長度,得到初始數據包,并將初始數據包傳輸至傳輸復用層。當傳輸復用層接收到初始數據包后,為初始化數據包添加傳輸復用層的數據包頭,數據包頭包括復用層的數據類型和數據長度,得到數據包,并調用物理驅動層的發送接口將該數據包發送給物理層。后續,第一應用處理器10對提取的所述數據包進行解析,就是從物理層(物理傳輸介質)之上的物理驅動層檢測數據包的包頭,以解析得到數據包的大小(長度)。
當第一應用處理器10確定數據包的長度后,再判斷該數據包的長度是否大于預設閾值(即buffer的容量值)。在本實施例中,所述預設閾值可選為512字節,在其它實施例中,也可以將所述預設閾值設置為其它長度,在此不再限定。當數據包的長度大于所述預設閾值時,為了防止數據包傳輸導致終端死機,所述第一應用處理器10對提取的數據包進行壓縮。可以理解,若提取的數據包的長度小于預設閾值,所述第一應用處理器10可直接通過usb接口發送該數據包至第二應用處理器20。
在本實施例中,在對數據包進行壓縮之前,所述第一應用處理器10對提取的所述數據包進行解析,以得到所述數據包的包頭,再確定所述數據包的長度,僅在數據包的長度大于預設閾值時,才對提取的數據包進行壓縮,從而提高了數據包壓縮的準確性。
進一步地,基于第一至第三實施例提出本發明數據包傳輸系統第四實施例。
數據包傳輸系統第四實施例與數據包傳輸系統第一至第三實施例的區別在于,所述第一應用處理器10對提取的數據包進行壓縮具體包括:
所述第一應用處理器10獲取所述數據包對應的源文本;
確定源文本中出現頻率大于預設頻率的字符段;
在預設字典列表中,查找所述字符段對應的編碼,其中,編碼的長度小于對應的字符段的長度;
通過查找的編碼代替對應的字符段,以實現數據包的壓縮。
在本實施例中,所述第一應用處理器10對數據包進行壓縮,具體地,先獲取數據包對應的源文本,然后確定源文本中出現頻率大于預設頻率的字符段,再從預設字典列表中,查找所述字符段對應的編碼,其中,編碼的長度小于對應的字符段的長度,最終通過查找的編碼代替對應的字符段,以實現數據包的壓縮。
該過程涉及的算法為字典算法,字典算法是最為簡單的壓縮算法之一。該字典算法把文本中出現頻率大于預設一定值的單詞或詞匯組合做成一個對應的字典列表,并用特殊代碼來表示這個單詞或詞匯,例如,當前的字典列表中:
00=chinese
01=people
02=china
若當期數據包中的源文本為:iamachinesepeople,iamfromchina。那么,采用該字典算法,壓縮后的編碼為:iama0001,iamfrom02。
可以理解,壓縮編碼后的長度顯著縮小,這樣的編碼專有名詞或者固定組合較多的內容中,壓縮效率十分顯著,將預定的文本內容用字典中預定的編碼映射替代,解壓縮的時候執行反向還原即可。
進一步地,所述第一應用處理器10,還用于依次確定源文本中高四位為零且相鄰的任兩個字符段;
將所述任兩個字符段的高四位進行刪除,并將所述任兩個字符段的低四位進行組合,以實現數據包的壓縮。
即,所述第一應用處理器10獲取到數據包對應的源文本之后,還可依次確定源文本中高四位為零且相鄰的任兩個字符段,再將任兩個字符段的高四位進行刪除,并將任兩個字符段的低四位進行組合,以實現數據包的壓縮。
該過程涉及的算法為固定位長算法(fixedbitlengthpacking),這種算法是把文本用需要的最少的位來進行壓縮編碼。比如:八個十六進制數:1,2,3,4,5,6,7,8。轉換為二進制為:00000001,00000010,00000011,00000100,00000101,00000110,00000111,00001000。每個數只用到了低4位,而高4位沒有用到(全為0),因此對低4位進行壓縮編碼后得到:0001,0010,0011,0100,0101,0110,0111,1000。然后兩兩補充為8位字節得到:00010010,00110100,01010110,01111000。所以原來的八個十六進制數縮短了一半,得到4個十六進制數:12,34,56,78。
可以理解,通過這種組合方式,將需要用到的位數進行了縮小,使得數據包的容量有所減小,同理,解壓時執行反響拆分添加組合即可。
進一步地,所述第一應用處理器10,還用于對源文本中連續出現的字符,采用重復次數加字符進行代替,以實現數據包的壓縮。
即,所述第一應用處理器10獲取到數據包對應的源文本之后,還可對源文本中連續出現的字符,采用重復次數加字符進行代替,以實現數據包的壓縮。
該過程涉及的算法為rle(runlengthencoding,游程編碼,又譯行程長度編碼)算法,這種壓縮編碼是一種變長的編碼,rle根據文本不同的具體情況會有不同的壓縮編碼變體與之相適應,以產生更大的壓縮比率。具體地:
變體1:重復次數+字符
文本字符串:aaabbbccccdddd,編碼后得到:3a3b4c4d;通過該變體算法,即可將數據包終端文本字符串進行壓縮。
變體2:特殊字符+重復次數+字符
文本字符串:aaaaabccccbccc,編碼后得到:bb5abb4cbb3c;其中,該編碼串的最開始說明特殊字符為b,然后再添加一個b,b后面跟著的數字就表示出重復的次數。也就是說,文本串字符采用該變體2算法進行編碼壓縮時,先在編碼后的編碼串的首字母說明特殊字符為b,然后由于后面緊接著出現5個字符a,需要在這5個字符a之前添加一個特殊字符即字符b,因此就是bb5a,在5a之后出現b,且b之后又出現3個c,因此,需要在3個c之前再添加一個特殊字符b,與前面連接起來就是bb5abb4c,后面采用同樣的方式,即可得到最終的編碼串bb5abb4cbb3c。
為了更清楚理解該方案,舉另一個例子:文本字符串仍然為:aaaaabccccbccc,若當前編碼串的最開始說明特殊字符為d,那么,編碼后得到:dd5abd4cbd3c。
變體3:
把文本每個字節分組成塊,每個字符最多重復127次。每個塊以一個特殊字節開頭。那個特殊字節的第7位如果被置位,那么剩下的7位數值就是后面的字符的重復次數。如果第7位沒有被置位,那么剩下7位就是后面沒有被壓縮的字符的數量。
例如:文本字符串:aaaaabcdefff,編碼后得到:85a4bcde83f(85h=10000101b、4h=00000100b、83h=10000011b)。其中,先將文本字符串分組成三個塊,分別是aaaaa、bcde和fff,三個快對應的特殊字符分別是10000101、00000100和10000011,由于10000101中第7位被置位為1,因此剩下的7位數值為后面的字符的重復次數,此時可知剩下的7位數值對應的值為5,即可得到85a;同理,由于00000100中的第7位沒有被置位為1,那么剩下7位是后面沒有被壓縮的字符的數量,可知此時剩下7位對應的值為4,即可得到4bcde;同理可確定83f,此處不在贅述。
需要說明的是,以上所列舉出的三種3種rle變體算法僅僅是較佳的幾種變體算法,本領域技術人員利用本發明的技術思想,根據其具體需求所提出的其它rle變體算法均在本發明的保護范圍內,在此不進行一一窮舉。
進一步地,所述第一應用處理器10,還用于確定源文本中是否存在內容相同且長度大于預設值的字符段;
若存在,確定后一個字符段與前一個字符端的距離以及所述字符段的長度;
采用距離與長度的標識代替后一個字符段,以實現數據包的壓縮。
即,所述第一應用處理器10獲取到數據包對應的源文本之后,還可確定源文本中是否存在內容相同且長度大于預設值的字符段,若存在,確定后一個字符段與前一個字符端的距離以及字符段的長度,采用距離與長度的標識代替后一個字符段,以實現數據包的壓縮。
該過程涉及的算法為lz77(由jacobziv和abrahamlempel于1977年提出,所以命名為lz77)算法。
lz77算法的壓縮原理:如果文件中有兩塊字符串內容相同的話,那么只要知道前一塊字符串內容的位置和大小,我們就可以確定后一塊字符串的內容。所以我們可以用(兩塊字符串之間的距離,相同內容的長度)這樣一對信息,來替換后一塊字符串內容。由于(兩塊字符串之間的距離,相同內容的長度)這一對信息的大小,小于被替換內容的大小,所以文件得到了壓縮。
為更好理解,下面我們來舉一個例子:
有一個文件的內容如下:http://jiurl.yeah.nethttp://jiurl.nease.net,其中有些部分的內容,前面已經出現過了,后面用()括起來的部分就是相同的部分:http://jiurl.yeah.net(http://jiurl.)nease(.net)。
我們使用(兩塊字符串之間的距離,相同內容的長度)這樣一對信息,來替換后一塊字符串內容,得到http://jiurl.yeah.net(22,13)nease(23,4)。
(22,13)中,22表示后一塊http://jiurl.與前一塊http://jiurl.中任意兩個相同字符之間的距離,如后一個h與前一個h的距離;13為相同內容的長度;(23,4)同理,此處不再贅述。
從上述例子中可看出,由于(兩塊字符串之間的距離,相同內容的長度)這一對信息的大小,小于被替換內容的大小,所以文件得到了壓縮。
具體地,lz77算法使用滑動窗口尋找匹配串:
即lz77算法使用"滑動窗口"的方法,來尋找文件中的相同部分,文件中相同部分即匹配串。首先,對匹配串做一個說明,匹配串是指一個任意字節的序列,不僅僅是可以在文本文件中顯示出來的那些字節的序列,還可以是包括標點符號的序列。這里的串強調的是它在文件中的位置,它的長度隨著匹配的情況而變化。具體地:
lz77從文件的開始處開始,一個字節一個字節的向后進行處理。本發明實施例中,滑動窗口的長度是固定的,該滑動窗口的終止位置在當前處理字節之前,并且緊挨著當前處理字節,隨著處理的字節不斷的向后滑動,就象在陽光下,飛機的影子滑過大地一樣。對于文件中的每個字節,用當前處理字節開始的串,和窗口中的每個串進行匹配,以尋找最長的匹配串。
窗口中的每個串指窗口中每個字節開始的串。如果當前處理字節開始的串在窗口中有匹配串,就用(之間的距離,匹配長度)這樣一對信息,來替換當前串,然后從剛才處理完的串之后的下一個字節,繼續處理。如果當前處理字節開始的串在窗口中沒有匹配串,就不做改動的輸出當前處理字節。
處理文件中第一個字節的時候,窗口在當前處理字節之前,也就是還沒有滑到文件上,這時窗口中沒有任何內容,被處理的字節就會不做改動的輸出。隨著處理的不斷向后,窗口越來越多的滑入文件,最后整個窗口滑入文件,然后整個窗口在文件上向后滑動,直到整個文件結束。
需要說明的是,匹配串的長度有所限制,即本實施例中,設置了最小匹配串和最大匹配串,必須限制通過滑動窗口匹配出來的字符串大于該最小匹配串并且小于該最大匹配串,才會進行壓縮,若是匹配出來的字符串小于該最小匹配串,或大于該最大匹配串,則不會進行后續的壓縮操作。
為更好理解本實施例,舉例如下:
假設文本字符串為:aaababaaac,當前有一個6個字符的滑動窗口,表示滑動窗口中一次性最多包含6個字符。
編碼的第一步:滑動窗口是一個空窗口,此時滑動窗口還不需要滑動,將滑動窗口與滑動窗口外的文本字符串第一位字符進行比對,發現不存在匹配的字符,此時將滑動窗口往右移動一位,也就是將滑動窗口從右滑入文本字符串,那么字符串首字母進入該滑動窗口,此時滑動窗口顯示字符a;
編碼的第二步:由于滑動窗口內部只有字符a,滑動窗口外緊接著出現字符a,雖然滑動窗口里面和外面存在匹配的字符a,但是為了保證字符編碼的效率,事先設置最小匹配串,如將最小匹配串設置為2個字符,由于此時只有一個字符a匹配,不符合要求,那么滑動窗口保持不動,將處理的字符往右移動一位,即與滑動窗口進行比對的字符就是aa,此時滑動窗口內只有一個字符a,因此,不存在匹配的字符,那么將該滑動窗口繼續向右滑動,那么文本字符串的第二個字符也進入滑動窗口,此時滑動窗口中出現了兩個一樣的字符a。
編碼的第三步:當滑動窗口內部存在兩個相同的字符a時,將滑動窗口內部的兩個字符a與窗口外的字符進行比對,由于滑動窗口外緊接著的兩個字符是ab,不匹配,因此滑動窗口繼續右滑,當滑動窗口滑動出現aaa時,滑動窗口外緊接著出現的字符是bab,與滑動窗口內的字符不匹配,那么滑動窗口繼續向右滑動,以使得滑動窗口內部出現aaab,此時,由于滑動窗口內部的字符ab與滑動窗口外部緊接著的字符ab匹配,認為找到了相似長度為2的ab,因此滑動窗口外的ab滿足最小匹配串的要求,因此一對〈長度,距離〉就被輸出了,長度(length)是2并且向后距離也是2,所以輸出為<2,2>。
編碼的第四步:當后一個字符串ab用<2,2>輸出之后,該段字符串就相當于刪除了,此時將滑動窗口與剩下的文本字符串進行比對,剩下的文本字符串為aaac,通過該滑動窗口比對時,在將aaac中的前兩個aa與滑動窗口進行比對時,雖然aa與滑動窗口出現相同內容和長度的字符,并且符合最小字符串,但是為了提高壓縮效率,會繼續判斷文本字符串后面是否還有匹配的字符串,若此時檢測到出還有一個字符a,即剛好有文本字符串aaa與滑動窗口內的三個字符a相同,那么確定剩下的文本字符串aaa與滑動窗口內aaa的距離以及相同字符串的長度,此時由于刪除了原本字符串中的后一個ab,因此aaa與滑動窗口內aaa的距離是4,相同的內容長度是3,可輸出<4,3>。
編碼的第五步:輸出<4,3>之后,該文本字符串中還需要處理的字符只有c,由于該滑動窗口中的字符是aaab,不匹配,因此滑動窗口向右滑動一位,將字符c也滑進該滑動窗口,那么滑動窗口內的字符就為aaabc。由于后續沒有內容需要處理,那么將該滑動窗口內的所有字符都輸出,最終得到的編碼串為aaab<2,2><4,3>c。
使用lz77算法進行壓縮和解壓縮
為了在解壓縮時,可以區分“沒有匹配的字節”和“(之間的距離,匹配長度)對”,還需要在每個“沒有匹配的字節”或者“(之間的距離,匹配長度)對”之前,放上一位,來指明是“沒有匹配的字節”,還是“(之間的距離,匹配長度)對”。本發明實施例中,可選用0表示“沒有匹配的字節”,用1表示“(之間的距離,匹配長度)對”。
實際應用中,固定(之間的距離,匹配長度)對中的,“之間的距離”和“匹配長度”所使用的位數。由于要固定“之間的距離”所使用的位數,所以才使用了固定大小的窗口,比如窗口的大小為32kb,那么用15位(2^15=32k)就可以保存0-32k范圍內的任何一個值。此外,還將限定最大的匹配長度,這樣一來,“匹配長度”所使用的位數也就固定了。
實際應用中,還將設定一個最小匹配長度,只有當兩個串的匹配長度大于最小匹配長度時,才認為是一個匹配。為更好理解,舉一個例子來說明這樣做的原因:比如,“距離”使用15位,“長度”使用8位,那么“(之間的距離,匹配長度)對”將使用23位,也就是差1位3個字節。如果匹配長度小于3個字節的話,那么用“(之間的距離,匹配長度)對”進行替換的話,不但沒有壓縮,反而會增大,所以需要一個最小匹配長度。
壓縮:
從文件的開始到文件結束,一個字節一個字節的向后進行處理。用當前處理字節開始的串,和滑動窗口中的每個串進行匹配,尋找最長的匹配串。如果當前處理字節開始的串在窗口中有匹配串,就先輸出一個標志位,表明下面是一個(之間的距離,匹配長度)對,然后輸出(之間的距離,匹配長度)對,然后從剛才處理完的串之后的下一個字節,繼續處理。如果當前處理字節開始的串在窗口中沒有匹配串,就先輸出一個標志位,表明下面是一個沒有改動的字節,然后不做改動的輸出當前處理字節,然后繼續處理當前處理字節的下一個字節。
解壓縮:
從文件開始到文件結束,每次先讀一位標志位,通過這個標志位來判斷下面是一個(之間的距離,匹配長度)對,還是一個沒有改動的字節。如果是一個(之間的距離,匹配長度)對,就讀出固定位數的(之間的距離,匹配長度)對,然后根據對中的信息,將匹配串輸出到當前位置。如果是一個沒有改動的字節,就讀出一個字節,然后輸出這個字節。
綜上所述,可以看出,lz77壓縮時需要做大量的匹配工作,而解壓縮時需要做的工作很少,也就是說解壓縮相對于壓縮將快的多,這對于需要進行一次壓縮,多次解壓縮的情況,是一個效果顯著的優點。
當第一應用處理器10通過上述任一個壓縮算法對數據包進行壓縮之后,再將壓縮后的數據包存儲到buffer中進行轉發。后續,第二應用處理器20即可從buffer中提取出壓縮的數據包,并對提取的壓縮數據包進行解壓,其中,解壓的方式也包括兩種:當第一應用處理器10是加密壓縮時,所述第二應用處理器20采用對應的密文進行解壓,當第一應用處理器10是明文壓縮時,所述第二應用處理器20即可直接進行解壓,以得到解壓后的數據包。由于本實施例中的各個壓縮算法主要是明文算法,因此,解壓的方式也是明文解壓。
可以理解,本方案中,在移動終端100中的電信卡傳輸的數據包較大時,第二應用處理器20在request中添加標識,使第一應用處理器10對數據包進行壓縮,以改變數據包的期望值,后續緩存到buffer的數據包就不會超出buffer的容量值,那么,避免了大數據包傳輸導致死機的問題,同時數據包不會被拆分成多個數據包,避免了數據包轉發不完整的情況。
本發明進一步提供一種數據包傳輸方法。
參照圖5,圖5為本發明數據包傳輸方法第一實施例的流程示意圖。
本實施例提出一種數據包傳輸方法,在本實施例中,提供了數據包傳輸方法的實施例,需要說明的是,雖然在流程圖中示出了邏輯順序,但是在某些情況下,可以以不同于此處的順序執行所示出或描述的步驟。
本發明中,數據包傳輸方法應用于通過預設接口與外接設備200連接的移動終端100,所述移動終端100包括第一應用處理器10、內嵌有虛擬用戶識別卡11a的第一調制解調器11、第一射頻模塊12,以及與所述第一調制解調器11連接的第一用戶識別卡13和第二用戶識別卡14,所述外接設備200包括第二應用處理器20、第二調制解調器21和第二射頻模塊22,所述方法包括:
步驟s10,第一應用處理器通過預設接口接收第二應用處理器發送的數據包獲取請求時,從虛擬用戶識別卡中提取所述數據包獲取請求對應的數據包;
步驟s20,對提取的數據包進行壓縮;
步驟s30,將壓縮后的數據包緩存至所述預設接口的buffer中,以供第二應用處理器從所述buffer中提取壓縮后的數據包,以完成數據包的傳輸。
在本實施例中,所述第一應用處理器10通過預設接口接收第二應用處理器20發送的數據包獲取請求,后續也是通過所述預設接口將數據包反饋至所述第二應用處理器20。所述預設接口為usb接口。
其中,當第二處理芯片002的第二調制解調器21通過第二射頻模塊22接收到基站發送的數據包獲取請求時,將數據包獲取請求發送至第二處理芯片002的第二應用處理器20中,當第二應用處理器20接收到數據包獲取請求時,先通過usb數據線300將數據包獲取請求傳送至移動終端100的第一應用處理器10中;第一應用處理器10接收到該數據包獲取請求時,將數據包獲取請求傳送至移動終端100的第一調制解調器11中,由第一調制解調器11根據該數據包獲取請求從虛擬用戶識別卡11a中獲取數據包;第一調制解調器11獲取到數據包之后,將數據包傳輸至第一應用處理器10中;第一應用處理器10獲取到數據包之后,為了保證傳輸的數據不會大于usb的buffer,先對獲取的數據包進行壓縮,得到壓縮后的數據包;再通過usb將壓縮后的數據包傳送至第二應用處理器20;第二應用處理器20在接收到數據包后,再將數據包傳送至第二射頻模塊22,由第二射頻模塊22將數據包上傳至基站,以完成數據的傳輸。
本實施例中,第一應用處理器不限于從第一調制解調器內嵌的虛擬用戶識別卡中獲取數據包,當然,也可根據實際需要在第一用戶識別卡或第二用戶識別卡中獲取數據包,第一應用處理器在虛擬用戶識別卡、第一用戶識別卡或第二用戶識別卡中獲取數據包的方式一致,下文為了簡述,僅以在虛擬用戶識別卡中獲取數據包為例,其它兩種不再贅述。
具體地,所述步驟s10包括:
步驟a,所述第一應用處理器通過第一調制解調器向虛擬用戶識別卡中的片內操作系統發送數據包獲取請求,由所述片內操作系統在虛擬用戶識別卡中的文件存儲模塊中提取所述數據包獲取請求對應的數據包,并反饋至所述第一調制解調器;
步驟b,所述第一應用處理器通過第一調制解調器接收片內操作系統反饋的數據包。
在本實施例中,需要說明的是,虛擬用戶識別卡11a中的數據包存儲在文件存儲模塊中,當第一調制解調器11要獲取虛擬用戶識別卡11a中的數據包時,第一調制解調器11不會直接與虛擬用戶識別卡11a中的文件存儲模塊交互,而是先向虛擬用戶識別卡11a中的cos(chipoperatingsystem,片內操作系統)操作系統發送數據包獲取請求即request,然后虛擬用戶識別卡11a的cos操作系統基于該request在文件存儲模塊中獲取數據包,然后將獲取的數據包再傳輸給第一調制解調器11,第一調制解調器11只要接收cos操作系統反饋的數據包即可,后續第一應用處理器10在第一調制解調器11中獲取數據包即可實現數據包的獲取過程。
可以理解,由于第一調制解調器11無法在虛擬用戶識別卡11a中的文件存儲模塊直接提取數據包,因此通過與虛擬用戶識別卡11a的cos操作系統進行交互,以實現數據包的提取,保證后續的數據傳輸過程正常運行。
當第一應用處理器10從虛擬用戶識別卡11a中提取出數據包獲取請求對應的數據包之后,再對提取的數據包進行壓縮,本實施例中,第一應用處理器10對數據包進行壓縮時,可以采用加密壓縮的方式進行數據包的壓縮,也可以直接采用明文進行壓縮。由于傳輸的sim卡網絡鑒權數據量比較小,為了減少加密解密等操作而導致數據傳輸效率低,本發明實施例優選采用明文壓縮的方式對數據包進行壓縮,即本方案中采用的壓縮算法以簡單高效為主,具體采用的壓縮算法和壓縮過程在下文實施例中詳述。
第一應用處理器10對數據包壓縮之后,即可將壓縮后的數據包緩存至所述預設接口usb的buffer中,以供第二應用處理器20從所述buffer中提取壓縮后的數據包,以完成數據包的傳輸。
本實施例中需要說明的是,buffer存在于usb接口的兩端,即usb接口的兩端分別設置有buffer1和buffer2。當第二應用處理器20將數據包獲取請求通過usb接口發送給第一應用處理器10時,第一應用處理器10通過第一調制解調器11從虛擬用戶識別卡11a提取出數據包之后,先將提取的數據包存儲到buffer1中,以通過usb傳輸至buffer2中,第二應用處理器20再從buffer2中獲取數據包。
本實施例提出的數據包傳輸方法,所述第一應用處理器通過預設接口接收第二應用處理器發送的數據包獲取請求時,先從虛擬用戶識別卡中提取所述數據包獲取請求對應的數據包,然后對提取的數據包進行壓縮,再將壓縮后的數據包緩存至所述預設接口的buffer中,以供第二應用處理器從所述buffer中提取壓縮后的數據包,以完成數據包的傳輸。本方案在傳輸數據包時,先對待傳輸的數據包進行壓縮,再將壓縮后的數據包進行傳輸,使得傳輸的數據包的容量值有所減小,避免了數據傳輸過程中移動終端死機的情況。
進一步地,基于第一實施例提出本發明數據包傳輸方法第二實施例。
數據包傳輸方法第二實施例與數據包傳輸方法第一實施例的區別在于,所述步驟s20之前,所述數據包傳輸方法還包括:
所述第一應用處理器判斷能否從所述數據包獲取請求中提取出第二應用處理器添加的壓縮標識;
若能提取出壓縮標識,則執行所述對提取的數據包進行壓縮的步驟。
在本實施例中,當第二應用處理器20向第一應用處理器10發送數據包獲取請求(request)之前,為了防止傳輸的數據包過大,第二應用處理器20發送request時,先確定是否需要在request中添加壓縮標識,若需要,則先在request中添加一個壓縮標識,如添加字段01,以告知第一應用處理器10對待發送的數據包進行壓縮。
需要說明的是,由于待傳輸的數據是根據通訊協議標準確定的,因此,第二應用處理器20可以得知即將獲取的數據包的數據類型和數據大小,那么,當第二應用處理器20發送request之前,先判斷當前待獲取的數據包的大小,若待獲取的數據包的大小超出了buffer的容量值,則第二應用處理器20在request中添加壓縮標識,以告知第一應用處理器10對待傳輸的數據包進行壓縮,若第二應用處理器20判斷待獲取的數據包的大小未超出buffer的容量值,則直接發送request即可,無需添加壓縮標識。
在本實施例中,第二應用處理器20發送request之前,對待獲取的數據包的大小進行識別,僅在待獲取的數據包超出buffer的容量值時,才在request添加壓縮標識,避免了所有的數據包獲取請求都添加壓縮標識,縮短了數據包傳輸的時間,提高了數據包傳輸的效率。
當第一應用處理器10通過預設接口(usb)接收第二應用處理器20發送的數據包獲取請求時,先對所述數據包獲取請求進行解析,以確定能否從所述數據包獲取請求中提取出第二應用處理器20添加的壓縮標識,若在所述數據包獲取請求中提取出壓縮標識,此時,所述第一應用處理器10即可對提取的數據包進行壓縮,后續再將壓縮后的數據包緩存至所述預設接口的buffer1中,并通過usb傳輸至buffer2中,以供第二應用處理器20從所述buffer2中提取壓縮后的數據包,以完成數據包的傳輸。
在本實施例中,數據包傳輸過程是發生第一應用處理器10和第二應用處理器20喚醒之后,那么當第一應用處理器10和第二應用處理器20喚醒之后,若第二應用處理器20通過第二調制解調器21連接的第二射頻模塊22接收到基站發送的數據包獲取請求,執行以下操作:
判斷:先確定待獲取的數據包的大小,以判斷是否需要添加壓縮標識;
決策:若待獲取的數據包超過usb的buffer的容量,則在發送數據包獲取請求之前,在數據包獲取請求添加壓縮標識;
發送:在數據包獲取請求添加壓縮標識之后,發送數據包獲取請求。
第一應用處理器10通過usb接收到數據包獲取請求時,執行以下操作:
提取:確定能否從數據包獲取請求中提取出壓縮標識,若能,則提取出壓縮標識;
壓縮:基于提取的壓縮標識,對通過第一調制解調器11從虛擬用戶識別卡11a提取的數據包進行壓縮;
反饋:反饋壓縮的數據包。
最終,第二應用處理器20通過usb接收第一應用處理器10反饋的數據包,以完成數據包傳輸過程。上述的操作過程,可參照圖4。
需要說明的是,第二應用處理器20發送的是數據包獲取請求,由于數據包獲取請求一般都小于buffer的容量,因此可不對數據包獲取請求進行壓縮。
在本實施例中,第一應用處理器10在對數據包進行壓縮之前,先判斷能否從所述數據包獲取請求中提取出第二應用處理器20添加的壓縮標識,若能提取出壓縮標識,才對數據包進行壓縮,防止數據包小于buffer的容量時也進行壓縮,以防止系統資源的浪費,并且節省了數據包傳輸的時間,從而提高了數據包傳輸的效率。
進一步地,基于第一實施例提出本發明數據包傳輸方法第三實施例。
數據包傳輸方法第三實施例與數據包傳輸方法第一實施例的區別在于,所述步驟s20之前,所述數據包傳輸方法還包括:
所述第一應用處理器對提取的所述數據包進行解析,以得到所述數據包的包頭;
基于所述數據包的包頭確定所述數據包的長度;
在所述數據包的長度大于預設閾值時,執行所述對提取的數據包進行壓縮的步驟。
在本實施例中,所述第一應用處理器10對數據包進行壓縮之前,先對從第一用戶識別卡13或第二用戶識別卡14中提取的數據包進行解析,以得到所述數據包的包頭,然后從包頭中獲取數據包的長度,以確定該數據包的大小。其中,數據包為tlv格式,tlv格式是ber(basicencodingrules,基本編碼規則)編碼的一種,全稱為type(類型),length(長度),value(值),t字段表示數據包的類型,l字段表示數據包的長度、v字段用于存放數據包的內容。
本實施例中,該數據包的生成過程為:傳輸層獲取到數據包對應的原始數據,并為原始數據添加傳輸層的數據包頭,數據包頭包括傳輸層數據類型和數據長度,得到初始數據包,并將初始數據包傳輸至傳輸復用層。當傳輸復用層接收到初始數據包后,為初始化數據包添加傳輸復用層的數據包頭,數據包頭包括復用層的數據類型和數據長度,得到數據包,并調用物理驅動層的發送接口將該數據包發送給物理層。后續,第一應用處理器10對提取的所述數據包進行解析,就是從物理層(物理傳輸介質)之上的物理驅動層檢測數據包的包頭,以解析得到數據包的大小(長度)。
當第一應用處理器10確定數據包的長度后,再判斷該數據包的長度是否大于預設閾值(即buffer的容量值)。在本實施例中,所述預設閾值可選為512字節,在其它實施例中,也可以將所述預設閾值設置為其它長度,在此不再限定。當數據包的長度大于所述預設閾值時,為了防止數據包傳輸導致終端死機,所述第一應用處理器10對提取的數據包進行壓縮。可以理解,若提取的數據包的長度小于預設閾值,所述第一應用處理器10可直接通過usb接口發送該數據包至第二應用處理器20。
在本實施例中,在對數據包進行壓縮之前,所述第一應用處理器10對提取的所述數據包進行解析,以得到所述數據包的包頭,再確定所述數據包的長度,僅在數據包的長度大于預設閾值時,才對提取的數據包進行壓縮,從而提高了數據包壓縮的準確性。
進一步地,基于第一至第三實施例提出本發明數據包傳輸方法第四實施例。
數據包傳輸方法第四實施例與數據包傳輸方法第一至第三實施例的區別在于,所述步驟s20包括:
步驟a、所述第一應用處理器獲取所述數據包對應的源文本;
步驟b、確定源文本中出現頻率大于預設頻率的字符段;
步驟c、在預設字典列表中,查找所述字符段對應的編碼,其中,編碼的長度小于對應的字符段的長度;
步驟d、通過查找的編碼代替對應的字符段,以實現數據包的壓縮。
在本實施例中,所述第一應用處理器10對數據包進行壓縮,具體地,先獲取數據包對應的源文本,然后確定源文本中出現頻率大于預設頻率的字符段,再從預設字典列表中,查找所述字符段對應的編碼,其中,編碼的長度小于對應的字符段的長度,最終通過查找的編碼代替對應的字符段,以實現數據包的壓縮。
該過程涉及的算法為字典算法,字典算法是最為簡單的壓縮算法之一。該字典算法把文本中出現頻率大于預設一定值的單詞或詞匯組合做成一個對應的字典列表,并用特殊代碼來表示這個單詞或詞匯,例如,當前的字典列表中:
00=chinese
01=people
02=china
若當期數據包中的源文本為:iamachinesepeople,iamfromchina。那么,采用該字典算法,壓縮后的編碼為:iama0001,iamfrom02。
可以理解,壓縮編碼后的長度顯著縮小,這樣的編碼專有名詞或者固定組合較多的內容中,壓縮效率十分顯著,將預定的文本內容用字典中預定的編碼映射替代,解壓縮的時候執行反向還原即可。
進一步地,所述步驟a之后,所述步驟s20還包括:
步驟e、依次確定源文本中高四位為零且相鄰的任兩個字符段;
步驟f、將所述任兩個字符段的高四位進行刪除,并將所述任兩個字符段的低四位進行組合,以實現數據包的壓縮。
即,所述第一應用處理器10獲取到數據包對應的源文本之后,還可依次確定源文本中高四位為零且相鄰的任兩個字符段,再將任兩個字符段的高四位進行刪除,并將任兩個字符段的低四位進行組合,以實現數據包的壓縮。
該過程涉及的算法為固定位長算法(fixedbitlengthpacking),這種算法是把文本用需要的最少的位來進行壓縮編碼。比如:八個十六進制數:1,2,3,4,5,6,7,8。轉換為二進制為:00000001,00000010,00000011,00000100,00000101,00000110,00000111,00001000。每個數只用到了低4位,而高4位沒有用到(全為0),因此對低4位進行壓縮編碼后得到:0001,0010,0011,0100,0101,0110,0111,1000。然后兩兩補充為8位字節得到:00010010,00110100,01010110,01111000。所以原來的八個十六進制數縮短了一半,得到4個十六進制數:12,34,56,78。
可以理解,通過這種組合方式,將需要用到的位數進行了縮小,使得數據包的容量有所減小,同理,解壓時執行反響拆分添加組合即可。
進一步地,所述步驟a之后,所述步驟s20還包括:
步驟g、對源文本中連續出現的字符,采用重復次數加字符進行代替,以實現數據包的壓縮。
即,所述第一應用處理器10獲取到數據包對應的源文本之后,還可對源文本中連續出現的字符,采用重復次數加字符進行代替,以實現數據包的壓縮。
該過程涉及的算法為rle(runlengthencoding,游程編碼,又譯行程長度編碼)算法,這種壓縮編碼是一種變長的編碼,rle根據文本不同的具體情況會有不同的壓縮編碼變體與之相適應,以產生更大的壓縮比率。具體地:
變體1:重復次數+字符
文本字符串:aaabbbccccdddd,編碼后得到:3a3b4c4d;通過該變體算法,即可將數據包終端文本字符串進行壓縮。
變體2:特殊字符+重復次數+字符
文本字符串:aaaaabccccbccc,編碼后得到:bb5abb4cbb3c;其中,該編碼串的最開始說明特殊字符為b,然后再添加一個b,b后面跟著的數字就表示出重復的次數。也就是說,文本串字符采用該變體2算法進行編碼壓縮時,先在編碼后的編碼串的首字母說明特殊字符為b,然后由于后面緊接著出現5個字符a,需要在這5個字符a之前添加一個特殊字符即字符b,因此就是bb5a,在5a之后出現b,且b之后又出現3個c,因此,需要在3個c之前再添加一個特殊字符b,與前面連接起來就是bb5abb4c,后面采用同樣的方式,即可得到最終的編碼串bb5abb4cbb3c。
為了更清楚理解該方案,舉另一個例子:文本字符串仍然為:aaaaabccccbccc,若當前編碼串的最開始說明特殊字符為d,那么,編碼后得到:dd5abd4cbd3c。
變體3:
把文本每個字節分組成塊,每個字符最多重復127次。每個塊以一個特殊字節開頭。那個特殊字節的第7位如果被置位,那么剩下的7位數值就是后面的字符的重復次數。如果第7位沒有被置位,那么剩下7位就是后面沒有被壓縮的字符的數量。
例如:文本字符串:aaaaabcdefff,編碼后得到:85a4bcde83f(85h=10000101b、4h=00000100b、83h=10000011b)。其中,先將文本字符串分組成三個塊,分別是aaaaa、bcde和fff,三個快對應的特殊字符分別是10000101、00000100和10000011,由于10000101中第7位被置位為1,因此剩下的7位數值為后面的字符的重復次數,此時可知剩下的7位數值對應的值為5,即可得到85a;同理,由于00000100中的第7位沒有被置位為1,那么剩下7位是后面沒有被壓縮的字符的數量,可知此時剩下7位對應的值為4,即可得到4bcde;同理可確定83f,此處不在贅述。
需要說明的是,以上所列舉出的三種3種rle變體算法僅僅是較佳的幾種變體算法,本領域技術人員利用本發明的技術思想,根據其具體需求所提出的其它rle變體算法均在本發明的保護范圍內,在此不進行一一窮舉。
進一步地,所述步驟a之后,所述步驟s20還包括:
步驟h、確定源文本中是否存在內容相同且長度大于預設值的字符段;
步驟i、若存在,確定后一個字符段與前一個字符端的距離以及所述字符段的長度;
步驟j、采用距離與長度的標識代替后一個字符段,以實現數據包的壓縮。
即,所述第一應用處理器10獲取到數據包對應的源文本之后,還可確定源文本中是否存在內容相同且長度大于預設值的字符段,若存在,確定后一個字符段與前一個字符端的距離以及字符段的長度,采用距離與長度的標識代替后一個字符段,以實現數據包的壓縮。
該過程涉及的算法為lz77(由jacobziv和abrahamlempel于1977年提出,所以命名為lz77)算法。
lz77算法的壓縮原理:如果文件中有兩塊字符串內容相同的話,那么只要知道前一塊字符串內容的位置和大小,我們就可以確定后一塊字符串的內容。所以我們可以用(兩塊字符串之間的距離,相同內容的長度)這樣一對信息,來替換后一塊字符串內容。由于(兩塊字符串之間的距離,相同內容的長度)這一對信息的大小,小于被替換內容的大小,所以文件得到了壓縮。
為更好理解,下面我們來舉一個例子:
有一個文件的內容如下:http://jiurl.yeah.nethttp://jiurl.nease.net,其中有些部分的內容,前面已經出現過了,后面用()括起來的部分就是相同的部分:http://jiurl.yeah.net(http://jiurl.)nease(.net)。
我們使用(兩塊字符串之間的距離,相同內容的長度)這樣一對信息,來替換后一塊字符串內容,得到http://jiurl.yeah.net(22,13)nease(23,4)。
(22,13)中,22表示后一塊http://jiurl.與前一塊http://jiurl.中任意兩個相同字符之間的距離,如后一個h與前一個h的距離;13為相同內容的長度;(23,4)同理,此處不再贅述。
從上述例子中可看出,由于(兩塊字符串之間的距離,相同內容的長度)這一對信息的大小,小于被替換內容的大小,所以文件得到了壓縮。
具體地,lz77算法使用滑動窗口尋找匹配串:
即lz77算法使用"滑動窗口"的方法,來尋找文件中的相同部分,文件中相同部分即匹配串。首先,對匹配串做一個說明,匹配串是指一個任意字節的序列,不僅僅是可以在文本文件中顯示出來的那些字節的序列,還可以是包括標點符號的序列。這里的串強調的是它在文件中的位置,它的長度隨著匹配的情況而變化。具體地:
lz77從文件的開始處開始,一個字節一個字節的向后進行處理。本發明實施例中,滑動窗口的長度是固定的,該滑動窗口的終止位置在當前處理字節之前,并且緊挨著當前處理字節,隨著處理的字節不斷的向后滑動,就象在陽光下,飛機的影子滑過大地一樣。對于文件中的每個字節,用當前處理字節開始的串,和窗口中的每個串進行匹配,以尋找最長的匹配串。
窗口中的每個串指窗口中每個字節開始的串。如果當前處理字節開始的串在窗口中有匹配串,就用(之間的距離,匹配長度)這樣一對信息,來替換當前串,然后從剛才處理完的串之后的下一個字節,繼續處理。如果當前處理字節開始的串在窗口中沒有匹配串,就不做改動的輸出當前處理字節。
處理文件中第一個字節的時候,窗口在當前處理字節之前,也就是還沒有滑到文件上,這時窗口中沒有任何內容,被處理的字節就會不做改動的輸出。隨著處理的不斷向后,窗口越來越多的滑入文件,最后整個窗口滑入文件,然后整個窗口在文件上向后滑動,直到整個文件結束。
需要說明的是,匹配串的長度有所限制,即本實施例中,設置了最小匹配串和最大匹配串,必須限制通過滑動窗口匹配出來的字符串大于該最小匹配串并且小于該最大匹配串,才會進行壓縮,若是匹配出來的字符串小于該最小匹配串,或大于該最大匹配串,則不會進行后續的壓縮操作。
為更好理解本實施例,舉例如下:
假設文本字符串為:aaababaaac,當前有一個6個字符的滑動窗口,表示滑動窗口中一次性最多包含6個字符。
編碼的第一步:滑動窗口是一個空窗口,此時滑動窗口還不需要滑動,將滑動窗口與滑動窗口外的文本字符串第一位字符進行比對,發現不存在匹配的字符,此時將滑動窗口往右移動一位,也就是將滑動窗口從右滑入文本字符串,那么字符串首字母進入該滑動窗口,此時滑動窗口顯示字符a;
編碼的第二步:由于滑動窗口內部只有字符a,滑動窗口外緊接著出現字符a,雖然滑動窗口里面和外面存在匹配的字符a,但是為了保證字符編碼的效率,事先設置最小匹配串,如將最小匹配串設置為2個字符,由于此時只有一個字符a匹配,不符合要求,那么滑動窗口保持不動,將處理的字符往右移動一位,即與滑動窗口進行比對的字符就是aa,此時滑動窗口內只有一個字符a,因此,不存在匹配的字符,那么將該滑動窗口繼續向右滑動,那么文本字符串的第二個字符也進入滑動窗口,此時滑動窗口中出現了兩個一樣的字符a。
編碼的第三步:當滑動窗口內部存在兩個相同的字符a時,將滑動窗口內部的兩個字符a與窗口外的字符進行比對,由于滑動窗口外緊接著的兩個字符是ab,不匹配,因此滑動窗口繼續右滑,當滑動窗口滑動出現aaa時,滑動窗口外緊接著出現的字符是bab,與滑動窗口內的字符不匹配,那么滑動窗口繼續向右滑動,以使得滑動窗口內部出現aaab,此時,由于滑動窗口內部的字符ab與滑動窗口外部緊接著的字符ab匹配,認為找到了相似長度為2的ab,因此滑動窗口外的ab滿足最小匹配串的要求,因此一對〈長度,距離〉就被輸出了,長度(length)是2并且向后距離也是2,所以輸出為<2,2>。
編碼的第四步:當后一個字符串ab用<2,2>輸出之后,該段字符串就相當于刪除了,此時將滑動窗口與剩下的文本字符串進行比對,剩下的文本字符串為aaac,通過該滑動窗口比對時,在將aaac中的前兩個aa與滑動窗口進行比對時,雖然aa與滑動窗口出現相同內容和長度的字符,并且符合最小字符串,但是為了提高壓縮效率,會繼續判斷文本字符串后面是否還有匹配的字符串,若此時檢測到出還有一個字符a,即剛好有文本字符串aaa與滑動窗口內的三個字符a相同,那么確定剩下的文本字符串aaa與滑動窗口內aaa的距離以及相同字符串的長度,此時由于刪除了原本字符串中的后一個ab,因此aaa與滑動窗口內aaa的距離是4,相同的內容長度是3,可輸出<4,3>。
編碼的第五步:輸出<4,3>之后,該文本字符串中還需要處理的字符只有c,由于該滑動窗口中的字符是aaab,不匹配,因此滑動窗口向右滑動一位,將字符c也滑進該滑動窗口,那么滑動窗口內的字符就為aaabc。由于后續沒有內容需要處理,那么將該滑動窗口內的所有字符都輸出,最終得到的編碼串為aaab<2,2><4,3>c。
使用lz77算法進行壓縮和解壓縮
為了在解壓縮時,可以區分“沒有匹配的字節”和“(之間的距離,匹配長度)對”,還需要在每個“沒有匹配的字節”或者“(之間的距離,匹配長度)對”之前,放上一位,來指明是“沒有匹配的字節”,還是“(之間的距離,匹配長度)對”。本發明實施例中,可選用0表示“沒有匹配的字節”,用1表示“(之間的距離,匹配長度)對”。
實際應用中,固定(之間的距離,匹配長度)對中的,“之間的距離”和“匹配長度”所使用的位數。由于要固定“之間的距離”所使用的位數,所以才使用了固定大小的窗口,比如窗口的大小為32kb,那么用15位(2^15=32k)就可以保存0-32k范圍內的任何一個值。此外,還將限定最大的匹配長度,這樣一來,“匹配長度”所使用的位數也就固定了。
實際應用中,還將設定一個最小匹配長度,只有當兩個串的匹配長度大于最小匹配長度時,才認為是一個匹配。為更好理解,舉一個例子來說明這樣做的原因:比如,“距離”使用15位,“長度”使用8位,那么“(之間的距離,匹配長度)對”將使用23位,也就是差1位3個字節。如果匹配長度小于3個字節的話,那么用“(之間的距離,匹配長度)對”進行替換的話,不但沒有壓縮,反而會增大,所以需要一個最小匹配長度。
壓縮:
從文件的開始到文件結束,一個字節一個字節的向后進行處理。用當前處理字節開始的串,和滑動窗口中的每個串進行匹配,尋找最長的匹配串。如果當前處理字節開始的串在窗口中有匹配串,就先輸出一個標志位,表明下面是一個(之間的距離,匹配長度)對,然后輸出(之間的距離,匹配長度)對,然后從剛才處理完的串之后的下一個字節,繼續處理。如果當前處理字節開始的串在窗口中沒有匹配串,就先輸出一個標志位,表明下面是一個沒有改動的字節,然后不做改動的輸出當前處理字節,然后繼續處理當前處理字節的下一個字節。
解壓縮:
從文件開始到文件結束,每次先讀一位標志位,通過這個標志位來判斷下面是一個(之間的距離,匹配長度)對,還是一個沒有改動的字節。如果是一個(之間的距離,匹配長度)對,就讀出固定位數的(之間的距離,匹配長度)對,然后根據對中的信息,將匹配串輸出到當前位置。如果是一個沒有改動的字節,就讀出一個字節,然后輸出這個字節。
綜上所述,可以看出,lz77壓縮時需要做大量的匹配工作,而解壓縮時需要做的工作很少,也就是說解壓縮相對于壓縮將快的多,這對于需要進行一次壓縮,多次解壓縮的情況,是一個效果顯著的優點。
當第一應用處理器10通過上述任一個壓縮算法對數據包進行壓縮之后,再將壓縮后的數據包存儲到buffer中進行轉發。后續,第二應用處理器20即可從buffer中提取出壓縮的數據包,并對提取的壓縮數據包進行解壓,其中,解壓的方式也包括兩種:當第一應用處理器10是加密壓縮時,所述第二應用處理器20采用對應的密文進行解壓,當第一應用處理器10是明文壓縮時,所述第二應用處理器20即可直接進行解壓,以得到解壓后的數據包。由于本實施例中的各個壓縮算法主要是明文算法,因此,解壓的方式也是明文解壓。
可以理解,本方案中,在移動終端100中的電信卡傳輸的數據包較大時,第二應用處理器20在request中添加標識,使第一應用處理器10對數據包進行壓縮,以改變數據包的期望值,后續緩存到buffer的數據包就不會超出buffer的容量值,那么,避免了大數據包傳輸導致死機的問題,同時數據包不會被拆分成多個數據包,避免了數據包轉發不完整的情況。
需要說明的是,在本文中,術語“包括”、“包含”或者其任何其它變體意在涵蓋非排他性的包含,從而使得包括一系列要素的過程、方法、物品或者系統不僅包括那些要素,而且還包括沒有明確列出的其它要素,或者是還包括為這種過程、方法、物品或者系統所固有的要素。在沒有更多限制的情況下,由語句“包括一個……”限定的要素,并不排除在包括該要素的過程、方法、物品或者系統中還存在另外的相同要素。
上述本發明實施例序號僅僅為了描述,不代表實施例的優劣。
通過以上的實施方式的描述,本領域的技術人員可以清楚地了解到上述實施例方法可借助軟件加必需的通用硬件平臺的方式來實現,當然也可以通過硬件,但很多情況下前者是更佳的實施方式。基于這樣的理解,本發明的技術方案本質上或者說對現有技術做出貢獻的部分可以以軟件產品的形式體現出來,該計算機軟件產品存儲在一個存儲介質(如rom/ram、磁碟、光盤)中,包括若干指令用以使得一臺終端設備(可以是手機,計算機,服務器,空調器,或者網絡設備等)執行本發明各個實施例所述的方法。
以上僅為本發明的優選實施例,并非因此限制本發明的專利范圍,凡是利用本發明說明書及附圖內容所作的等效結構或等效流程變換,或直接或間接運用在其它相關的技術領域,均同理包括在本發明的專利保護范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!