一種感知網絡流量的YARN調度方法及系統與流程
本發明屬于互聯網大數據技術領域,更具體地,涉及一種感知網絡流量的yarn調度方法及系統。
背景技術:
隨著大數據時代的來臨,每天產生大量非結構化和半結構化數據,傳統的關系型數據庫等解決方案無法存儲和處理如此規模的數據量,于是mapreduce編程模型產生。yarn(yetanotherresourcenegotiator)作為一種資源管理平臺,以其高可靠性,高容錯性,支持多種計算框架而得到廣泛應用。
由于yarn管理資源只包括了cpu和內存,沒有包含節點的網絡流量信息,而mapreduce應用非本地性的map任務需要到其他節點上去取數據,reduce任務需要到每個map任務所在的節點去取它需要處理的數據,這兩種任務都需要占用網絡資源。yarn調度器缺乏對整個集群中網絡資源的感知,極易將reduce任務聚集在某些節點上,導致這些節點上的網絡負載高于其他節點,延長作業的執行時間。
技術實現要素:
針對現有技術的以上缺陷或改進需求,本發明的目的在于提供了一種感知網絡流量的yarn調度方法及系統,由此解決現有技術中yarn調度器缺乏對整個集群中網絡資源的感知,極易將reduce任務聚集在某些節點上,導致這些節點上的網絡負載高于其他節點,延長作業的執行時間的技術問題。
為實現上述目的,按照本發明的一個方面,提供了一種感知網絡流量的yarn調度方法,包括:
s1、應用程序在向yarn資源管理器申請container時設置container的類型;
s2、集群中的每個節點采集節點上的實時網絡流量信息,并在心跳時向資源管理器匯報節點的實時網絡流量信息;
s3、資源管理器記錄每個節點上的實時網絡流量信息,并在收到節點匯報的更新值時,對記錄的相應節點的實時網絡流量信息進行更新,和/或在節點移除時,刪除記錄的移除節點的實時網絡流量信息;
s4、當前節點向資源管理器發送心跳信息時,若當前節點上存在可用資源,則根據記錄的各節點的實時網絡流量信息以及當前節點的實時網絡流量信息,選擇合適的應用程序的container分配資源。
優選地,步驟s2具體包括如下子步驟:
s2.1、對集群中的每個節點,使用nload命令將節點的實時網絡流量信息重定向到文件中;
s2.2、從文件中讀取對應的字段,獲取節點的實時網絡流量信息;
s2.3、將節點的實時網絡流量信息賦給nodestatus的networkflow字段;
s2.4、向資源管理器發送心跳信息匯報節點的實時網絡流量信息。
優選地,步驟s4具體包括如下子步驟:
s4.1、根據記錄的每個節點的實時網絡流量信息和當前節點的實時網絡流量信息確定當前節點需要的任務類型;
s4.2、若當前節點需要的任務類型是normal,則進入步驟s4.3,否則,依次選擇fifo中的應用程序,再按照container的優先級遍歷所選的應用程序中的所有container,判斷是否存在container的類型與當前節點需要的任務類型一致的container,若存在,則將當前節點的資源分配給與當前節點需要的任務類型一致的container,否則進入步驟s4.3;
s4.3、依次選擇fifo中的應用程序,再按照container的優先級遍歷所選的應用程序中的所有container,將當前節點的資源分配給優先級最高的container。
優選地,步驟s4.1具體包括如下子步驟:
s4.1.1、若集群中每個節點的實時網絡流量均小于預設閾值,則認為當前集群沒有網絡任務在執行,直接返回normal;
s4.1.2、計算出集群中所有節點的實時網絡流量總和;
s4.1.3、用所有節點的實時網絡流量總和除以集群中節點的數量得到網絡流量平均值;
s4.1.4、若當前節點的實時網絡流量大于網絡流量平均值,則確定當前節點需要的任務類型為map,否則確定當前節點需要的任務類型為reduce。
按照本發明的另一方面,提供了一種感知網絡流量的yarn調度系統,包括:
容器類型設置模塊,用于在應用程序向yarn資源管理器申請container時設置container的類型;
流量信息收集模塊,用于由集群中的每個節點采集節點上的實時網絡流量信息,并在心跳時向資源管理器匯報節點的實時網絡流量信息;
流量信息更新模塊,用于由資源管理器記錄每個節點上的實時網絡流量信息,并在收到節點匯報的更新值時,對記錄的相應節點的實時網絡流量信息進行更新,和/或在節點移除時,刪除記錄的移除節點的實時網絡流量信息;
資源調度模塊,用于在當前節點向資源管理器發送心跳信息時,若當前節點上存在可用資源,則根據記錄的各節點的實時網絡流量信息以及當前節點的實時網絡流量信息,選擇合適的應用程序的container分配資源。
優選地,所述流量信息收集模塊包括:
重定向模塊,用于對集群中的每個節點,使用nload命令將節點的實時網絡流量信息重定向到文件中;
流量信息獲取模塊,用于從文件中讀取對應的字段,獲取節點的實時網絡流量信息,并將節點的實時網絡流量信息賦給nodestatus的networkflow字段;
發送模塊,用于向資源管理器發送心跳信息匯報節點的實時網絡流量信息。
優選地,所述資源調度模塊包括:
確定模塊,用于根據記錄的每個節點的實時網絡流量信息和當前節點的實時網絡流量信息確定當前節點需要的任務類型;
第一調度模塊,用于在當前節點需要的任務類型不是normal時,依次選擇fifo中的應用程序,再按照container的優先級遍歷所選的應用程序中的所有container,判斷是否存在container的類型與當前節點需要的任務類型一致的container,若存在,則將當前節點的資源分配給與當前節點需要的任務類型一致的container;
第二調度模塊,用于在當前節點需要的任務類型是normal時,或者,在不存在container的類型與當前節點需要的任務類型一致的container時,依次選擇fifo中的應用程序,再按照container的優先級遍歷所選的應用程序中的所有container,將當前節點的資源分配給優先級最高的container。
優選地,所述確定模塊包括:
第一確定子模塊,用于在集群中每個節點的實時網絡流量均小于預設閾值時,認為當前集群沒有網絡任務在執行,直接返回normal;
第一計算模塊,用于計算出集群中所有節點的實時網絡流量總和;
第二計算模塊,用于用所有節點的實時網絡流量總和除以集群中節點的數量得到網絡流量平均值;
第二確定子模塊,用于在當前節點的實時網絡流量大于網絡流量平均值時,確定當前節點需要的任務類型為map,否則確定當前節點需要的任務類型為reduce。
總體而言,本發明方法與現有技術方案相比,能夠取得下列有益效果:
(1)每臺節點上的網絡資源利用的更加均勻,資源管理器能感知每臺節點上面的實時網絡流量值,根據這個值來分配任務,可以有效地避免集群節點網絡使用不均勻的情況。
(2)本發明提出的基于網絡流量的調度方法與yarn自帶的fifo,fair,capacity調度算法相比,在運行不同類型的mapreduce應用時,能使每個節點上面的網絡流量負載比較均勻,達到減少作業完成時間的目的,而任務的更快完成有利于更快地釋放container,提升了集群的資源利用率。
(3)雖然節點采集網絡流量以及根據節點需要的任務類型來遍歷應用程序選擇container會產生一定開銷,但這種開銷基本上可以忽略不計。
附圖說明
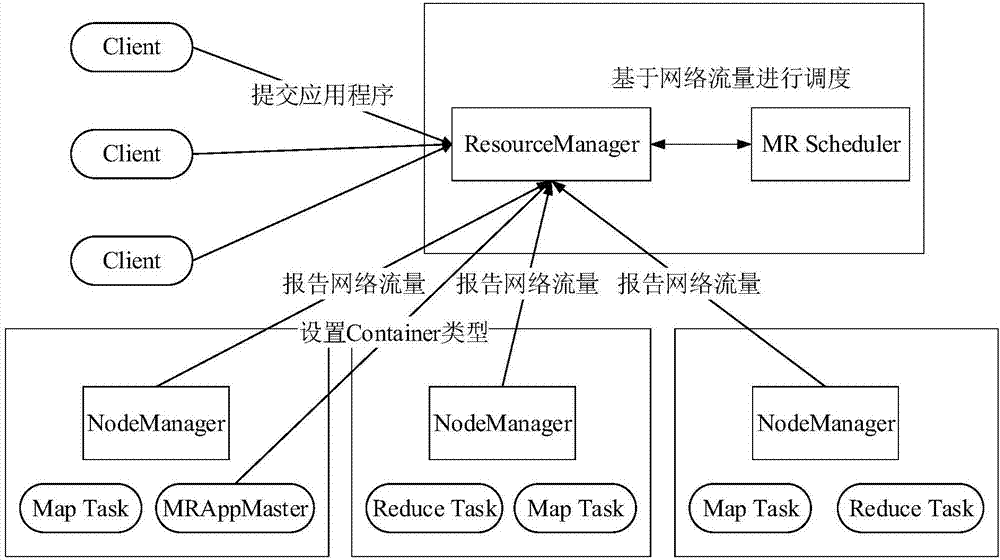
圖1為本發明實施例公開的一種感知網絡流量的yarn調度方法的整體架構圖;
圖2為本發明實施例公開的一種感知網絡流量的yarn調度方法的流程示意圖;
圖3為本發明實施例公開的一種檢測節點網絡流量并向資源管理器報告流量的方法流程示意圖;
圖4為本發明實施例公開的一種資源調度方法的流程示意圖;
圖5為本發明實施例公開的一種任務類型判斷方法的流程示意圖。
具體實施方式
為了使本發明的目的、技術方案及優點更加清楚明白,以下結合附圖及實施例,對本發明進行進一步詳細說明。應當理解,此處所描述的具體實施例僅用以解釋本發明,并不用于限定本發明。此外,下面所描述的本發明各個實施方式中所涉及到的技術特征只要彼此之間未構成沖突就可以相互組合。
以下首先就本發明所涉及的技術術語進行解釋和說明:
mapreduce:由google提出的編程模型,用于大規模數據集的并行運算;
yarn:yetanotherresourcenegotiator,一種通用資源管理系統;
container:cpu和內存的封裝,應用程序申請資源的基本單位;
applicationmaster:管理一個在yarn內運行的應用程序的實例,applicationmaster負責向resourcemanager申請container,并向nodemanager通信啟動container;
mrappmaster:mapreduce應用的applicationmaster,yarn自帶的,編程人員無需再為mapreduce應用編寫applicationmaster;
resourcemanager:控制整個集群并管理應用程序向基礎計算資源的分配,管理整個集群中的container與應用程序;
nodemanager:集群中每個節點上的資源和任務管理器,監控container的生命周期,也會跟蹤節點健康狀況;
調度器:yarn為應用程序分配資源的方式,按照一定的方式選擇應用程序的container為它分配資源;
nload:一款輕量級的linux網絡流量監控工具,可以很方便地獲取節點上的當前網絡流量,平均網絡流量等信息。
以下結合具體實施例和附圖對本發明所提供的感知網絡流量的yarn調度方法做進一步說明。
本發明提供的感知網絡流量的yarn調度方法,其目的在于解決了yarn沒有對網絡進行管理,可能會使mapreduce應用的占用網絡的任務堆積在同一個節點上,導致作業完成時間增長的問題;采用基于網絡流量的調度方案,可以實時感知到每個節點的網絡流量,在為節點分配任務時,根據節點的網絡負載,選擇合適的任務分配到這個節點上運行,使得每個節點上面的網絡負載比較均衡,最終減少mapreduce應用的完成時間,提升集群的資源利用率。
如圖1所示是本發明實施例提供的基于網絡流量的調度器的整體架構,調度方案修改了mrappmaster,nodemanager和resourcemanager。因為yarn上面可以運行多種計算框架,而不僅僅是mapreduce應用,于是無法對mapreduce應用的任務做出專門的調度。因此在mrappmaster端增加了任務類型(map和reduce),以便資源管理器能感知。yarn自身沒有對網絡進行管理,所以需要節點檢測網絡流量之后向資源管理器匯報。mrscheduler會根據集群的網絡流量信息對任務進行調度。
如圖2所示是本發明實施例公開的一種感知網絡流量的yarn調度方法的流程示意圖,在圖2所示的方法中,具體包括如下步驟:
s1、應用程序在向yarn資源管理器申請container時設置container的類型(例如map和reduce);
s2、集群中的每個節點采集節點上的實時網絡流量信息,并在心跳時向資源管理器匯報節點的實時網絡流量信息;
s3、資源管理器記錄每個節點上的實時網絡流量信息,并在收到節點匯報的更新值時,對記錄的相應節點的實時網絡流量信息進行更新,和/或在節點移除時,刪除記錄的移除節點的實時網絡流量信息;
例如,資源管理器維護一個hashmap來記錄每一個節點上的網絡流量信息,在收到nodemanager的心跳時更新該值,在收到節點移出集群的消息時刪除對應的記錄。
s4、當前節點向資源管理器發送心跳信息時,若當前節點上存在可用資源,則根據記錄的各節點的實時網絡流量信息以及當前節點的實時網絡流量信息,選擇合適的應用程序的container分配資源。
如圖3所示為上述步驟s2的具體實施方式流程示意圖,包括以下步驟:
s2.1、對集群中的每個節點,使用nload命令將節點的實時網絡流量信息重定向到文件中;
s2.2、從文件中讀取對應的字段,獲取節點的實時網絡流量信息;
s2.3、將節點的實時網絡流量信息賦給nodestatus的networkflow字段;
s2.4、向資源管理器發送心跳信息匯報節點的實時網絡流量信息。
如圖4所示為上述步驟s4的具體實施方式流程示意圖,包括以下步驟:
s4.1、根據記錄的每個節點的實時網絡流量信息和當前節點的實時網絡流量信息確定當前節點需要的任務類型;
s4.2、若當前節點需要的任務類型是normal,則進入步驟s4.3,否則,依次選擇fifo中的應用程序,再按照container的優先級遍歷所選的應用程序中的所有container,判斷是否存在container的類型與當前節點需要的任務類型一致的container,若存在,則將當前節點的資源分配給與當前節點需要的任務類型一致的container,否則進入步驟s4.3;
s4.3、依次選擇fifo中的應用程序,再按照container的優先級遍歷所選的應用程序中的所有container,將當前節點的資源分配給優先級最高的container。
如圖5所示為上述步驟s4.1的具體實施方式流程示意圖,包括以下步驟:
s4.1.1、若集群中每個節點的實時網絡流量均小于預設閾值,則認為當前集群沒有網絡任務在執行,直接返回normal;其中,預設閾值可以根據實際需要進行確定。
s4.1.2、計算出集群中所有節點的實時網絡流量總和;
s4.1.3、用所有節點的實時網絡流量總和除以集群中節點的數量得到網絡流量平均值;
s4.1.4、若當前節點的實時網絡流量大于網絡流量平均值,則確定當前節點需要的任務類型為map,否則確定當前節點需要的任務類型為reduce。
本領域的技術人員容易理解,以上所述僅為本發明的較佳實施例而已,并不用以限制本發明,凡在本發明的精神和原則之內所作的任何修改、等同替換和改進等,均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!