一種基于雙自適應正則化在線極限學習機的網絡入侵檢測方法與流程
本發明屬于機器學習領域,涉及一種基于雙自適應正則化在線極限學習機的網絡入侵檢測方法。
背景技術:
隨著網絡技術和網絡規模的不斷發展,互聯網在軍事、金融、電子商務等領域得到大規模的應用。越來越多的主機和網絡正受到各種網絡入侵攻擊的威脅,信息安全提升到一個非常重要的地位。網絡入侵是指網絡攻擊者通過非法的手段(如破譯口令、電子欺騙等)獲得非法的權限,并通過使用這些非法的權限使網絡攻擊者能對被攻擊的主機進行非授權的操作,例如竊取用戶的網上銀行賬號信息等等。網絡入侵的主要途徑有:破譯口令、IP欺騙和DNS欺騙。網絡入侵檢測技術屬于動態安全技術,是信息安全的一個重要研究方向。它被認為是防火墻之后的第二道安全閘門,主動檢測內部和外部攻擊,保護自己免受網絡入侵。隨著網絡入侵方式的更新換代,網絡入侵技術也面臨一系列新的挑戰。第一點,由于新的網絡入侵方式不斷產生,網絡數據樣本集越來越大(即訓練數據集不斷變大),增大了安全分析的開銷,降低了效率,很難滿足入侵檢測實時性的要求。第二點,網絡攻擊呈現智能化、復雜化的趨勢,檢測惡意入侵更加困難。
為了應對這些挑戰,基于支持向量機(SVM)、人工神經網絡、免疫原理以及聚類分析等人工智能的方法也被用于網絡入侵檢測技術中。這些算法在一定程度上提高了檢測性能,但仍有一些缺點亟待解決,比如:屬于批量學習算法,實時性不強、容易陷入局部最優解、訓練速度慢等等。在實際的網絡環境中,網絡數據連續不斷的產生,需要一種能實時連續學習且快速訓練的方法來進行入侵檢測,很多學者對此展開了大量研究。在線慣序極限學習機(OS-ELM)(參考文獻:N.Liang,G.Huang,et al.(2006).A fast and accurate online sequential learning algorithm for feedforward networks.Neural Networks IEEE Transactions on,17(6),1411-1423.)屬于在線學習算法,繼承了傳統極限學習機(ELM)訓練速度快、檢測精度高、泛化性能優等特點,并且能根據連續到達的數據實時的修正和優化訓練模型,非常適合網絡入侵檢測等實時性強的應用。然而OS-ELM同ELM一樣基于經驗風險最小化,容易發生過擬合以及病態問題。在初始化階段,其初始訓練集大小必須大于或等于隱層單元數,不利于實時的檢測網絡入侵。因此,要將OS-ELM應用于復雜多變的網絡環境,還需要進行更深的研究。
技術實現要素:
本發明是為了解決現有的技術所存在的上述技術問題,提供一種能高效、高速、實時的檢測網絡入侵的基于雙自適應正則化在線極限學習機的網絡入侵檢測方法。
一種基于雙自適應正則化在線極限學習機的網絡入侵檢測方法,包括以下步驟:
步驟1:利用標準NSL-KDD網絡數據訓練在線極限學習機分類器;
步驟2:基于已訓練好的在線極限學習機分類器,計算待檢測的網絡數據的隱含層輸出矩陣H;
步驟3:按照以下公式對待檢測的網絡數據進行入侵檢測判斷,得到入侵檢測判斷結果
其中,β為已訓練好的在線極限學習機分類器中的隱含層和輸出層之間的輸出權重;
在訓練在線極限學習機分類器時,首先對在線極限學習機分類器進行初始化設置:
激勵函數設置為hardlim,隱層單元數L至少為1000,初始數據集大小n0至少為50,從訓練數據集中隨機選取,輸入權重Wi和隱層偏置bi為[-1.1]范圍內的隨機值;
訓練數據集為從標準NSL-KDD網絡數據隨機選取的至少10000個樣本;
在線極限學習機分類器中的隱含層和輸出層之間的初始輸出權重β0按以下公式確定:
若n0<L,則否則,
其中,
C為脊回歸因子,初始值為1e-8,I表示大小為L×L的單位矩陣,大小為,H0表示初始隱層輸出矩陣,T0表示訓練集n0對應的目標集,U0和K0表示中間變量矩陣。
在線極限學習機分類器在不斷的學習過程中,每次用于訓練的數據集是從除去已被隨機選取后的樣本的訓練數據集中隨機選取獲得;
進一步地,在訓練在線極限學習機分類器過程中,脊回歸因子C按照以下設置進行更新;
首先,設置脊回歸因子C的更新間隔時間△P;
其次,按照從第一次訓練在線極限學習機分類器開始,每間隔△P次訓練,更新一次脊回歸因子C。
進一步地,所述脊回歸因子C的更新過程如下:
把當前已經訓練過的所有訓練數據集合并成一個訓練集,并依照當前的在線極限學習機分類器計算出合并后的訓練集對應的輸出矩陣H,采用基于SVD和PRESS的LOO-CV方法計算脊回歸因子C的最優值,并自適應更新參數C,具體包括以下幾個步驟:
對待檢測的網絡數據進行入侵檢測時,由于網絡中的數據為實時增加的,檢測過程,同樣如同訓練過程一樣,當產生新的網絡數據時,將之前已檢測的數據和新產生的數據一起合并后再利用已訓練的在線極限學習機分類器進行檢測;
步驟A:設置脊回歸因子C的候選值[1e-10,1e-8,1e-6,1e-4,1e-2,0,1e,2,1e4,1e6,1e8,1e10];
步驟B:用奇異值分解將輸出矩陣H分解為H=UΣVT;
其中,U、Σ及V均表示通過對H進行奇異值分解得到的中間變量矩陣,ΣT表示Σ的轉置矩陣;
步驟C:依次計算脊回歸因子C每個候選值的對應的預測殘差平方和ELOO;
其中,ti和分別表示合并后的訓練集中第i個樣本的目標值和對應的預測值;hatii表示中間變量矩陣HAT的第i個對角元素值,N表示合并后的訓練集中的樣本數量;
中間變量矩陣HAT是通過對預測集矩陣進行分解獲得:
T表示訓練集的入侵檢測目標集對應的矩陣;
對角矩陣S:
其中,σii為矩陣Σ的第i個對角元素,當i大于L時σii取值為0;
步驟D:選出最小預測殘差平方和ELOO對應的脊回歸因子C的候選值作為脊回歸因子的當前最優值,更新脊回歸因子C。
把合并的訓練集的入侵檢測預測集的矩陣做如下分解:
HAT表示中間變量矩陣,T表示訓練集的入侵檢測目標集對應的矩陣;VT、UT、HT分別表示V、U、H的轉置矩陣;
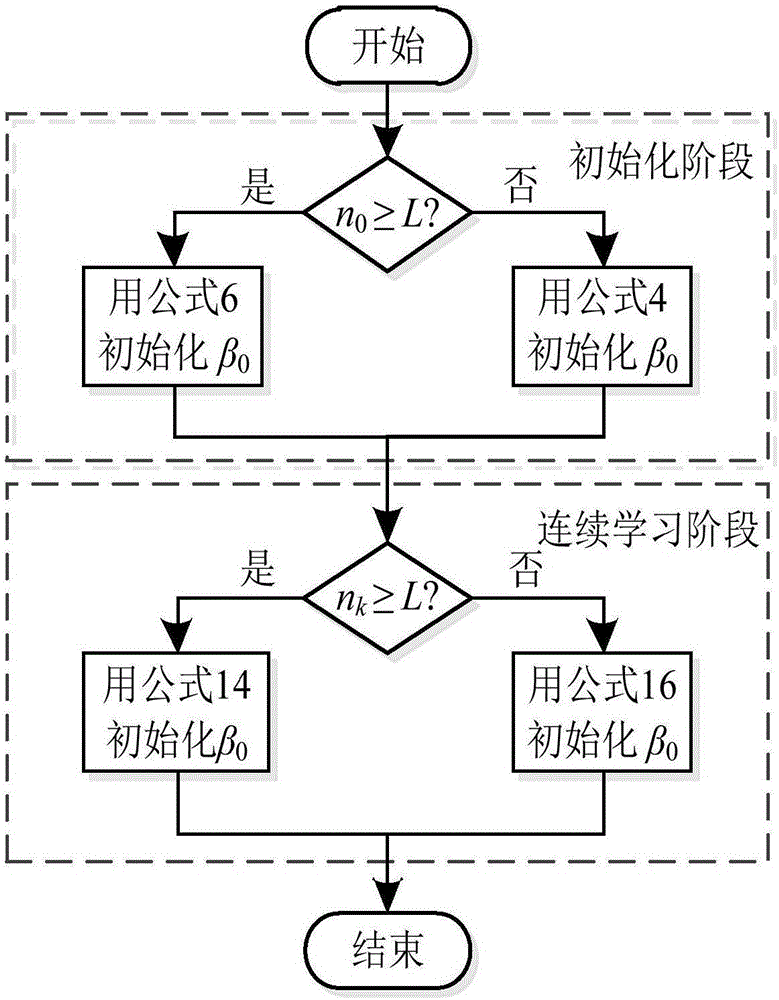
進一步地,在訓練在線極限學習機分類器過程中,隱含層和輸出層之間的初始輸出權重按照以下公式計算:
當nk≥L,用中間變量Kk來更新輸出權重βk,其中Kk為L×L的矩陣:
其中,K′k-1=Kk-1-Ck-1+Ck;
當nk<L,用中間變量Uk來初始化輸出權重βk,其中Uk為nk×nk的矩陣:
其中,U′k-1=(Uk-1-1-Ck-1+Ck)-1;
其中,nk、βk、Kk及Uk分別表示利用第k個合并訓練集對在線極限學習機分類器進行第k次訓練時所需的隱含層和輸出層之間的初始輸出權重以及兩個中間變量矩陣;
nk表示利用第k個合并訓練集的樣本大小,k為大于或等于1的整數;
Ck-1和Ck分別表示利用第k-1個和第k個合并訓練集對在線極限學習機分類器進行訓練時的脊回歸因子。
有益效果
本發明公開了一種基于雙自適應正則化在線極限學習機的網絡入侵檢測方法,該方法用帶標簽的網絡數據集訓練極限學習機網絡,并用該網絡進行網絡入侵檢測。在極限學習機網絡初始化階段,從NSL-KDD網絡數據集中隨機抽取樣本作為初始訓練集,隨機分配網絡輸入權重和隱層偏置,并根據初始訓練集的大小自適應的初始化輸出權重β,在連續學習階段,根據當前已獲取的全部數據集,采用基于奇異值分解(SVD)和預測平方和(PRESS)的留一交叉驗證法(LOO-CV)自適應獲取C的最優值并更新,然后根據新到達的數據集自適應更新β。在輸出權重β的計算過程中,充分權衡經驗風險和結構風險,引入基于吉洪諾夫正則化的脊回歸因子C。訓練好極限學習機網絡后,再利用該網絡分類待檢測的網絡數據,即進行網絡入侵檢測。本發明提出的方法能高效、高速的檢測網絡入侵,顯著的提高網絡入侵檢測算法的泛化性能和實時性能。
附圖說明
圖1為極限學習機網絡結構示意圖;
圖2為輸出權重β的自適應機制流程圖;
圖3為本發明帶和不帶輸出權重β的自適應機制的實驗結果對比圖;
圖4為本發明帶和不帶脊回歸因子C的自適應機制的實驗結果對比圖。
具體實施方式
下面將結合實施例對本發明做進一步的說明。
實施例1:
本實施例分為訓練和檢測兩個部分,訓練即用帶標簽的網絡數據集訓練極限學習機分類器,檢測即用訓練好的分類器來檢測待檢測數據中的網絡入侵數據。
通過在NSL-KDD數據集上模擬訓練和檢測過程來說明本發明的有效性。NSL-KDD數據集是著名的KDD網絡數據集的改進版本,該數據集刪除了KDD數據集中的冗余數據,因此分類器不會偏向更頻繁的數據,并且訓練集和測試集的數據比較合理,使得數據集可以被充分利用。而KDD數據集是用于1999年舉行的KDDCUP競賽的網絡數據集,雖然年代有些久遠,但KDD數據集仍然是網絡入侵檢測領域的事實基準,為基于計算智能的網絡入侵檢測研究奠定基礎。為了評估本發明的性能,用到的評估參數有:檢測精度(ACC)、訓練時間(Train Time)、漏檢率(FPR)、誤檢率(FNR)。檢測精度越高、訓練時間越短、漏檢率和誤檢率越低表示分類器性能越優。
一種基于雙自適應正則化在線極限學習機的網絡入侵檢測方法,包括以下步驟:
步驟1:極限學習機分類器的初始化階段。極限學習機是目前比較新穎的一種神經網絡數學模型,初始化即初始化極限學習機網絡的各個參數,為接下來的連續學習階段做準備。
1.1把原始NSL-KDD數據集中的字符型數據轉換為數字型,然后進行規范化和標準化處理。
1.2從處理過的NSL-KDD數據集中選取16000個樣本作為訓練數據集N,4000個樣本作為測試數據集D,一般訓練數據集應該選擇10000個樣本以上,測試數據集大小不作要求,根據實際網絡待測數據的多少來決定。
NSL-KDD數據集包含五種類別的數據(NORMAL、PROBING、DOS、R2L、U2R),從該數據集中抽取的訓練集N和測試集D中五種類別的數據都是等量的。
1.3選擇激勵函數‘hardlim’、設置隱層單元數L為1000、脊回歸因子C初始值為‘1e-8’、初始數據集大小n0為50。
1.4從訓練集N中隨機的選擇50個樣本作為初始訓練集N0,其中:
N0={(xi,ti)|i=1,…,50} (1)
xi和ti分別代表n×1的輸入向量和m×1的目標向量。
其中n表示的是樣本的特征數,比如連接持續類型、協議類型等等,NSL-KDD數據集中每個樣本用41個特征表示,即n為41。m表示的是分類器把樣本分成的類別,本實施例中樣本分為正常和異常兩類,即m為2,異常即表示該數據表示的網絡連接異常。50個樣本為隨機選取,不考慮各類數據的比例,因為影響整個分類器性能的是整體訓練集,只要整體訓練集中各類數據比例相等即可。
1.4在[-1,1]范圍內隨機分配輸入權重Wi和隱層偏置bi,極限學習機的特色就在于這兩個參數是隨機分配并且不需要迭代調整的,一旦這兩個參數設置好,隱層輸出矩陣就會被唯一確定。
1.5依據如下公式計算初始隱層輸出矩陣H0,其中g(x)為激勵函數‘hardlim’,Xi代表n×1的輸入向量:
1.6根據no和隱層單元數L的大小關系50<1000,用中間向量U0來初始化輸出權重β0,β0是連接隱層和輸出層的輸出權重,U0是50×50的矩陣:
若no設置為1000及以上,則用中間變量K0來初始化β0,其中:
步驟2:極限學習機分類器的連續學習階段。
2.2設置需要更新脊回歸因子C的步驟的集合P={1,100,200,…}(用戶可以自由選擇需要更新脊回歸因子C的步驟,如果精度要求不是太高,用戶可以把更新的步驟間隔設大一些,以此來降低計算復雜度,加快訓練速度,更新步驟間隔一般設置為[100,1000]范圍內。
2.1將訓練數據集N剩下的數據進行分塊處理,每塊數據集大小均為chunk(本實施例中chunk設為50,實際網絡環境中是過一段時間訓練一次極限學習機網絡,相等的時間段內產生的網絡數據集大小不等,因此chunk是不斷變化的),然后用分塊后的訓練數據集依次訓練極限學習機網絡。當用第k個訓練集Nk訓練時,用下式計算其對應的隱層輸出矩陣Hk:
2.2當k∈P時(k代表當前訓練極限學習機網絡使用的訓練數據集序號,k∈P即代表該訓練步驟需要更新脊回歸因子C),把當前已經訓練過的所有訓練數據集合并成一個訓練集,并依照公式2計算出其對應的輸出矩陣H,采用基于SVD和PRESS的LOO-CV方法計算脊回歸因子C的最優值,并自適應更新參數C。
其中,自適應的更新脊回歸因子C的具體過程如下:
1)設置參數C的候選值[1e-10,1e-8,1e-6,1e-4,1e-2,0,1e,2,1e4,1e6,1e8,1e10]。
2)用奇異值分解將輸出矩陣H分解為H=UΣVT,把預測集的計算過程做如下分解:
3)對C的每個候選值,做如下計算:
a.用如下公式計算中間變量W,其中σii是Σ的第i個對角元素,當i>L時σii=0。
b.用如下公式計算HATi和
c.用如下公式計算預測殘差平方和,其中ti代表目標值,代表預測值,hatii代表HAT矩陣的第i個對角元素值:
4)選取k個ELOOi值中的最小值作為參數C的最優值;
2.3類似初始化階段中β0的計算過程,根據nk(nk為第k個訓練集Nk的大小)和L的大小關系自適應的更新輸出權重βk,輸出權重β的自適應初始化和更新過程如圖1所示。
當nk≥L,用中間變量Kk來更新輸出權重βk,其中Kk為L×L的矩陣:
其中,K′k-1=Kk-1-Ck-1+Ck;
當nk<L,用中間變量Uk來初始化輸出權重βk,其中Uk為nk×nk的矩陣:
其中,U′k-1=(Uk-1-1-Ck-1+Ck)-1;
Ck-1和Ck分別表示利用第k-1個和第k個合并訓練集對在線極限學習機分類器進行訓練時的脊回歸因子。
在線極限學習機是用實時網絡環境中不斷生成的網絡數據去更新極限學習機網絡中的輸出權重β,從以上的輸出權重β更新公式可以看出,β的更新僅僅依賴于新生成的訓練集,與之前的訓練數據集無關,這樣使得該方法能夠更加適應實時性很強的網絡環境。當極限學習機網絡分類器訓練好后,只需把待檢測的網絡數據集放入該極限學習機網絡中進行分類,即可判斷是否為網絡入侵數據。
步驟3:網絡入侵檢測階段
步驟1和步驟2訓練好了極限學習機網絡分類器后,就可以用來檢查網絡入侵。用測試數據集D來模擬待檢測的網絡數據集。
3.1對于測試數據集D,用公式2計算其對應的隱層輸出矩陣H;
3.2按以下公式計算其對應的預測集進行分類判決,其中β為訓練好的極限學習機網絡中的輸出權重;
3.3比較目標集T和預測集統計檢測精度、誤檢率和漏檢率。
步驟4:重新對數據集N進行分塊處理,重復步驟1到步驟3,比較數據分塊大小(chunk)在范圍[20,3000]內時,本發明實施例的網絡入侵檢測方法的性能,如表1所示。由表知chunk對精度的影響不大,但chunk越小,訓練時間越長。因此證明在實際的網絡入侵檢測中,不同時間段網絡數據生成不均勻(即chunk大小不一)不會影響本發明的檢測精度,進一步的證明了本發明的實時性良好。
表1不同chunk下本發明方法的性能比較。
步驟5:當chunk在范圍[0,1000]內時,重復步驟1到步驟3,但此次初始化和更新輸出權重β時不采用自適應機制(β自適應機制即在初始化和在線學習過程中自適應的選擇初始化和更新的方式,是我的創新點),僅僅按nk>L情況下的方式進行β的初始化和更新。將此步驟的實驗結果與步驟4的實驗結果進行比較,如圖2所示。本發明的β自適應機制能有效降低計算復雜度,縮短訓練時間,提升檢測性能。
步驟6:重新獲取不同大小的訓練集N,重復步驟1到步驟3,模擬現實的網絡環境中網絡數據集大小不同的情況。當訓練集范圍為[0,1000]時,比較自適應更新脊回歸因子C和不更新C時,本發明網絡入侵檢測方法的性能,如圖3所示。本發明的C自適應更新機制能有效提高檢測精度,提升檢測性能,更加符合實際網絡環境的實時性要求。
步驟7:重新設置隱層單元數L,重復步驟1到步驟3,將本發明方法與基于OS-ELM的網絡入侵檢測方法性能進行詳細比較,如表2所示。本發明相較基于OS-ELM的網絡入侵檢測方法,有更高的檢測精度,更好的泛化性能。另外從表2中也可看出,當訓練數據集只有2萬左右時,隱層單元數應該設置到[500,1000]之間,訓練速度快的同時精度也高。當訓練數據集更大或者要求更高的精度的時候,就要設置更多的隱層數,犧牲訓練時間來換取精度。
表2本發明與基于OS-ELM的網絡入侵檢測方法的性能比較
步驟8:將本發明實施例與以下四個方法進行實驗比較:BP、SVM、ANN、K-means,實驗結果如表3。可以看出,本發明的網絡入侵檢測方法在訓練速度和訓練精度方面均大大優于其他方法。同時,本發明屬于連續學習方法,其雙自適應機制滿足了實際網絡環境的實時性要求,降低了計算復雜度,提高了泛化性能。
表3本發明與其余四個方法的性能比較
以上所述僅為本發明的優選實施例而已,并不用于限制本發明,對于本領域的技術人員來說,本發明可以有各種更改和變化。凡在本發明的精神和原則之內,所作的任何修改、等同替換、改進等,均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!