一種基于EM算法的LDPC碼譯碼噪聲方差的估計方法與流程
本發明提供一種基于EM算法的LDPC碼譯碼噪聲方差的估計方法,它是一種基于期望最大(即EM)算法的低密度奇偶校驗(即LDPC)碼譯碼噪聲方差的估計方法,屬于通信技術領域。
背景技術:
信道編碼和譯碼是通信系統中保證信息正確傳輸的重要環節。對于編碼領域常用的碼字LDPC碼或渦輪碼(即Turbo)碼,其理論性能優異,但是其優異的性能建立在一些前提條件下,包括理想的同步以及一些準確的參數信息,任何非理想條件都會導致譯碼性能惡化。以LDPC碼為例,置信傳播譯碼算法為其主要譯碼方法。在譯碼的開始,通常需要求解接收信號相應比特后驗概率的對數似然比來初始化迭代譯碼器,而計算后驗概率的對數似然比需要已知接收信號的噪聲方差。然而,噪聲方差的估計精度直接影響了譯碼性能。因此,在信道譯碼時需要合理的估計噪聲方差。
傳統的方差估計需要在利用線性變換去除調制信息后進行。但當噪聲較大時,非線性變化導致信噪比進一步降低,需要通過擴大觀察區間來提升噪聲方差估計準確性,同時也增大了計算量。若已知譯碼環節接收數據,可用極大似然法估計模型的參數。但是,當模型含有隱變量時,就不能簡單地使用這些估計方法。信道編碼后的0、1序列通過二進制相移鍵控(BPSK)調制后變為1、-1的發送序列,發送序列通過高斯白噪聲信道即為接收序列,接收序列的概率分布是一種高斯混合模型。每一個接收信息所對應的發送碼字可能是1或-1,因此,發送序列是高斯混合模型的隱變量。EM算法是一種經典的機器學習方法,用于含有隱變量的概率模型的參數估計,1977年由鄧普斯特(即Dempster)等人提出。因此,可通過EM算法對譯碼環節的噪聲方差進行估計,保證正確譯碼。
技術實現要素:
(一)發明的目的
本發明的目的是提出一種基于EM算法的LDPC碼譯碼噪聲方差的估計方法,它能夠在已知譯碼環節接收序列的情況下,較準確地計算信道噪聲方差,輔助迭代譯碼,減小由方差不準確導致的譯碼性能損失。
(二)技術方案
為實現上述目的,本發明一種基于EM算法的LDPC碼譯碼噪聲方差的估計方法,其步驟如下:
步驟一:獲得信道譯碼環節的接收序列;
步驟二:確定方差估計范圍和初值;
步驟三:基于EM算法估計噪聲方差;
步驟四:將信道噪聲方差估計結果應用于譯碼初始化和迭代環節;
其中,在步驟一中所述的“獲得信道譯碼環節的接收序列”,其作法如下:
在發送端,將信源數據通過LDPC碼信道編碼獲得編碼序列u,并進行BPSK調制獲得發送序列c,在發送序列上加入方差為σ2的高斯白噪聲n,獲得信道譯碼環節的接收序列r。
其中,在步驟二中所述的“確定方差估計范圍和初值”,其作法如下:
根據LDPC碼碼率、接收信息信噪比與方差的對應關系計算方差的合理估計范圍,在該范圍內選取隨機數作為方差估計初值。
其中,在步驟三中所述的“基于EM算法估計噪聲方差”,其作法如下:
首先設置EM算法迭代的初值,該初值為高斯混合模型的主要參數,主要包括噪聲方差、噪聲均值和接收序列來自均值為1或-1的高斯模型概率;其次執行EM算法的E步:根據模型參數計算分模型對接收序列的響應度;執行EM算法的M步:根據響應度重計算模型參數。將E步和M步反復迭代直至模型參數中的方差收斂。
其中,在步驟四中所述的“將信道噪聲方差估計結果應用于譯碼初始化和迭代環節”,其作法如下:
根據接收序列和步驟三中的噪聲方差估計值計算接收序列相應比特后驗概率的對數似然比,從而初始化迭代譯碼器;執行LDPC碼置信傳播譯碼算法的迭代過程,完成信道譯碼。
通過以上步驟,本發明實現了對LDPC碼信道譯碼環節所需的信道噪聲方差的估計,能有效地避免錯誤方差帶來的譯碼性能衰減。相比傳統方差估計方法,本發明方法估計精度高,復雜度較低,對碼字長度和信道噪聲方差變化的魯棒性好,方差估計結果較準確。
(三)優點和功效
基于上述步驟,本發明的一種基于EM算法估計LDPC碼譯碼噪聲方差的方法可以達到以下目的:
一:本發明解決了實際工程中噪聲方差難以估計的問題,可以較準確地估計信道噪聲方差。
二:本發明將噪聲方差估計很好地應用于LDPC碼信道譯碼,防止由于噪聲方差不準確而帶來的譯碼性能衰減。
三:本發明在LDPC碼長度變化和噪聲方差變化時均能正確估計噪聲方差,魯棒性較好。
四:本發明的方差估計結果不僅適用于LDPC碼譯碼,還適用于其他同樣需要噪聲方差的譯碼過程,如Turbo碼的譯碼,應用范圍較廣泛。
總之,本發明能夠解決通信系統中噪聲方差的估計問題,進而輔助信道譯碼過程,是正確譯碼的必要條件。該發明魯棒性較好,在碼字長度不同、噪聲方差大小不同的情況下,均能準確地估計信道噪聲方差,可廣泛應用于LDPC碼和Turbo碼譯碼。
附圖說明
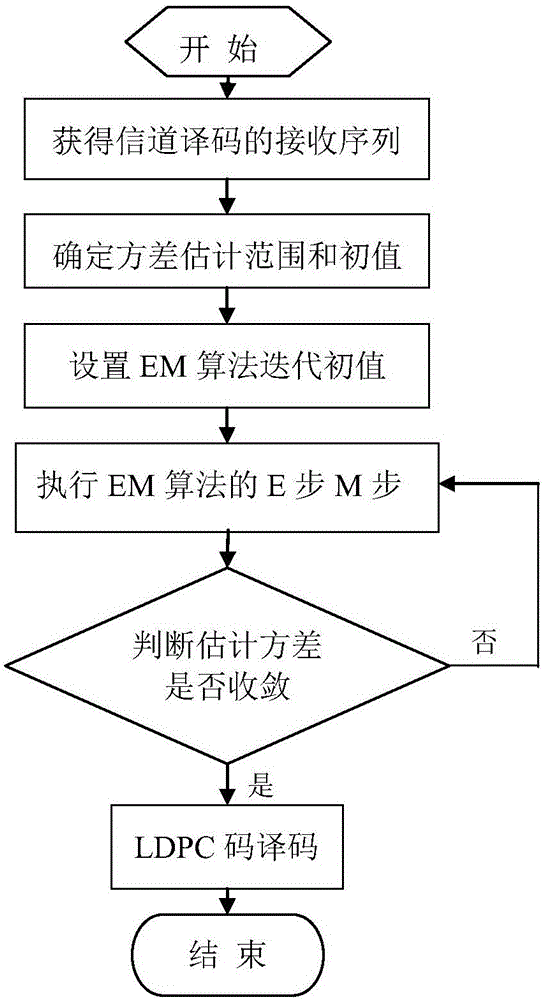
圖1是本發明所述方法的流程圖。
圖2是信道編譯碼及其噪聲方差估計的系統框圖。
圖3是EM算法的流程圖。
圖4是接收序列的概率密度分布函數。
圖5是不同信噪比下的方差估計值。
圖6是初始方差為正確方差的1/2時,長528的LDPC碼采用本發明的譯碼性能。
圖7是初始方差為正確方差的1/2時,長1200的LDPC碼采用本發明的譯碼性能。
圖中序號、符號、代號說明如下:
EM表示期望最大算法;LDPC碼表示低密度奇偶校驗碼;BPSK表示二進制相移鍵控;u表示LDPC碼編碼后的序列;c表示通過BPSK調制的發送序列;n表示均值為0、方差為常數的高斯白噪聲序列;r表示接收序列;Optimum Decision Threshold表示接收序列的硬判決門限;Eb/N0表示接收序列的信噪比,單位為分貝(即dB)。
具體實施方式
下面結合附圖和具體實施例對本發明的一種基于EM算法的LDPC碼譯碼噪聲方差的估計方法進行更進一步的介紹。
如圖1所示,本發明提供一種基于EM算法的估計LDPC碼譯碼噪聲方差的方法,其具體實施步驟如下:
第一步:獲得信道譯碼環節的接收序列;
信道編譯碼及其噪聲方差估計的系統框圖如圖2所示,將信源輸入信息通過LDPC碼信道編碼獲得編碼序列u=(u1,u2,…,uK),并進行BPSK調制獲得發送序列c=(c1,c2,…,cN),發送序列c將編碼序列u中的0和1轉換為1和-1,具體計算方法如下:
ck=1-2·uk
接著,在發送序列上按位疊加均值為0、方差為σ2的高斯白噪聲n=(n1,n2,…,nN),從而獲得信道譯碼環節的接收序列r=(r1,r2,…,rN)。其中,K表示信源輸入的未編碼信息的長度,N表示編碼后碼字長度。
第二步:確定方差估計范圍和初值;
為合理地進行方差估計,需先確定方差估計范圍,再選擇方差估計的初值。噪聲方差與接收序列的信噪比Eb/N0的關系如下:
其中信噪比Eb/N0的單位為分貝(即dB),R表示碼率,且滿足R=K/N。由上式可知,當碼率確定時,接收序列信噪比越大,噪聲方差越小。假設信噪比最小值為0dB,方差估計范圍的上限為:
σmax2=0.5R
因此,方差估計范圍為(0,0.5R]。在該范圍下去任意隨機數可作為方差估計的初始值,即σ02∈(0,0.5R]。
第三步:基于EM算法估計噪聲方差;
基于EM算法估計信道噪聲方差的流程圖如圖3所示。
首先,設置EM算法迭代的初值,該初值為高斯混合模型的主要參數。接收序列是一組隨機序列,其概率分布符合高斯混合模型,概率密度函數如圖4所示,可表示為:
其中,r為接收序列,α1和α2代表單個接收碼元來自均值為1和-1的高斯模型的概率,αk≥0且α1+α2=1;φ(r|θk)是高斯概率密度函數,可表示為:
因此,當前高斯混合模型的參數主要包括噪聲方差噪聲均值μk和模型概率αk。可將參數設置如下:μ1=1,μ2=-1,α1=α2=0.5,
設置完EM算法初值后,開始EM算法的迭代環節。首先,執行E步:根據當前模型參數,計算分模型k對接收序列每個元素rj的響應度,即當前模型參數下第j個接收數據rj來自第k個模型的概率
接著,執行M步:計算新一輪迭代的模型參數:
其中k=1,2。上述的E步和M步的推導過程見《統計學習方法》書中的163-165頁。
每執行完一次M步,計算方差估計值:
循環執行E步和M步,直到方差估計值收斂時停止循環迭代,輸出噪聲方差估計值。
第四步:將信道噪聲方差估計結果應用于譯碼初始化和迭代環節;
根據接收序列和噪聲方差估計值進行LDPC碼譯碼初始化,即計算接收序列相應比特后驗概率的對數似然比:
執行LDPC碼置信傳播譯碼算法的迭代過程,更新校驗節點和變量節點,直至硬判決結果滿足校驗方程或迭代次數達到上限時,結束譯碼,輸出譯碼結果。
為驗證本專利提出算法的有效性、合理性、可行性及科學性,利用本方法對實際的LDPC碼接收序列進行方差估計。圖5是不同信噪比下的方差估計值;圖6是初始方差為正確方差的1/2時長528的LDPC碼采用本發明的譯碼性能;圖7初始方差為正確方差的1/2時長1200的LDPC碼采用本發明的譯碼性能。試驗中各參數設置如下:LDPC碼(528,264)和(1200,600)的碼率為1/2;LDPC碼譯碼采用經典的和積算法,最大迭代次數為50。
由試驗結果可以看出,本文算法可以有效地估計信道噪聲方差,保證LDPC碼譯碼的正確執行;從圖5可以看出,基于EM算法的方差估計可以在已知接收序列的前提下較準確地估計高斯白噪聲方差,隨信噪比的改變,方差估計的準確性較高。從圖6可以看出,相比采用錯誤的初始方差,基于EM算法的方差估計可有效地降低譯碼性能衰減。結合圖6和圖7可以看出,在誤碼率為10-5時,長度為1200的LDPC碼采用本方法相比直接使用初始方差譯碼所提升的編碼增益為0.3dB,其對譯碼性能的提升效果優于長度為528的碼字。因此,碼字越長,方差估計越準確,能更有效地在方差未知時實現最優譯碼性能。
- 還沒有人留言評論。精彩留言會獲得點贊!