一種數據平臺系統的擴展方法、系統及電子設備與流程
本發明涉及計算機通信及互聯網、軟件管理后臺技術領域,特別是涉及一種數據平臺系統的擴展方法、系統及電子設備。
背景技術:
近幾年來,隨著計算機和信息技術的迅猛發展和普及應用,行業應用系統的規模迅速擴大,行業應用所產生的數據呈爆炸性增長,動輒數百TB甚至數十至數百PB規模的行業/企業大數據已遠遠超出了現有傳統的計算技術和信息系統的處理能力,因此,尋求有效的大數據處理技術、方法和手段已經成為現實世界的迫切需求。
鑒于大數據處理需求的迫切性和重要性,近年來大數據技術已經在全球學術界、工業界和各國政府得到高度關注和重視,全球掀起了一個可與20世紀90年代的信息高速公路相提并論的研究熱潮。美國和歐洲一些發達國家政府都從國家科技戰略層面提出了一系列的大數據技術研發計劃,以推動政府機構、重大行業、學術界和工業界對大數據技術的探索研究和應用。
大數據的處理需要大量的硬件支撐,沒有硬件支撐就沒有大數據的各種數據分析管理。當數據量呈現幾何量級的增長,如果硬件不能快速的部署變為大數據的節點,就無法滿足日常系統的使用情況。如何快速部署大數據系統,方便地增加大數據服務器的節點數量,是亟待解決的一重要課題。
技術實現要素:
鑒于以上所述現有技術的缺點,本發明的目的在于提供一種數據平臺系統的擴展方法、系統及電子設備,用于快速地將硬件設備部署為大數據處理系統中的計算節點,從而為大數據的分析和管理提供硬件支撐。
為實現上述目的及其他相關目的,本發明提供一種數據平臺系統的擴展方法,應用于所述數據平臺系統,其中,所述數據平臺系統包括:所述管理節點、及與所述管理節點通信連接的至少一個數據節點,所述方法包括:所述管理節點向待添加數據節點發送用于配置系統環境的腳本文件,以供所述待添加數據節點執行所述腳本文件后完成相應的系統環境設置;所述管理節點為所述待添加數據節點安裝相關應用,從而完成所述待添加數據節點向所述數據平臺系統的添加。
于本發明一實施例中,所述數據平臺系統的類型包括:CDH系統。
于本發明一實施例中,所述腳本文件的內容包括:安裝執行所述腳本文件的命令的工具編譯包、編輯所述待添加數據節點的名稱、關閉安全設置、安裝常用軟件包、開啟ntp時間服務并加入自動啟動項、修改swappiness以降低對swap緩存的使用、安裝CDH系統運行環境及語言環境、強制刷新、及重啟所述待添加數據節點中的一種或多種組合。
于本發明一實施例中,所述為待添加數據節點安裝相關應用,包括:添加CDH管理員賬號、開啟CDH客戶端服務、進行所述待添加數據節點的功能安裝、及開啟所述待添加數據節點的計算功能中的一種或多種組合。
于本發明一實施例中,所述至少一個數據節點分別關聯有與其一一對應的至少一個預設負荷值,在所述向待添加的數據節點發送腳本文件之前,所述方法還包括:獲取所述至少一個數據節點的實際負荷值,并分別與對應的預設負荷值比對;若檢測到存在實際負荷值不小于預設負荷值的數據節點,則開始擴展所述數據平臺系統。
為實現上述目的及其他相關目的,本發明提供一種數據平臺系統的擴展系統,應用于所述數據平臺系統,其中,所述數據平臺系統包括:所述管理節點、及與所述管理節點通信連接的至少一個數據節點,所述系統包括:腳本發送模塊,用于所述管理節點向待添加數據節點發送用于配置系統環境的腳本文件,以供所述待添加數據節點執行所述腳本文件后完成相應的系統環境設置;應用安裝模塊,用于所述管理節點為所述待添加數據節點安裝相關應用,從而完成所述待添加數據節點向所述數據平臺系統的添加。
于本發明一實施例中,所述數據平臺系統的類型包括:CDH系統。
于本發明一實施例中,所述腳本文件的內容包括:安裝執行所述腳本文件的命令的工具編譯包、編輯所述待添加數據節點的名稱、關閉安全設置、安裝常用軟件包、開啟ntp時間服務并加入自動啟動項、修改swappiness以降低對swap緩存的使用、安裝CDH系統運行環境及語言環境、強制刷新、及重啟所述待添加數據節點中的一種或多種組合。
于本發明一實施例中,所述為待添加數據節點安裝相關應用,包括:添加CDH管理員賬號、開啟CDH客戶端服務、進行所述待添加數據節點的功能安裝、及開啟所述待添加數據節點的計算功能中的一種或多種組合。
于本發明一實施例中,所述至少一個數據節點分別關聯有與其一一對應的至少一個預設負荷值,所述系統還包括:比對模塊,用于在所述向待添加的數據節點發送腳本文件之前:獲取所述至少一個數據節點的實際負荷值,并分別與對應的預設負荷值比對;若檢測到存在實際負荷值不小于預設負荷值的數據節點,則向所述腳本發送模塊發送開始擴展所述數據平臺系統的指令。
為實現上述目的及其他相關目的,本發明提供一種電子設備,包括如上任一所述的數據平臺系統的擴展系統。
如上所述,本發明的數據平臺系統的擴展方法、系統及電子設備,具有以下有益效果:
1)節省時間:傳統的節點服務器添加需要在圖形界面添加,步驟繁瑣,安裝等待時間長,報錯信息少,如果一旦遇到錯誤,此節點需要重新安裝系統才能被再次添加;本發明采用腳本方式快速擴充節點計算服務器,節約時間和成本,滿足日益龐大的海量數據處理需求;
2)數據可靠:使用命令行添加節點服務器,經驗證,幾乎可以排除所有人為錯誤,添加上去的節點穩定,能夠快速并入CDH系統提供計算;
3)系統故障率低:成熟命令行腳本,添加節點服務器,提前定義好系統的基礎環境,變量,規避了圖形化界面添加未考慮到的方面,使計算節點發生系統故障的幾率大大降低。
附圖說明
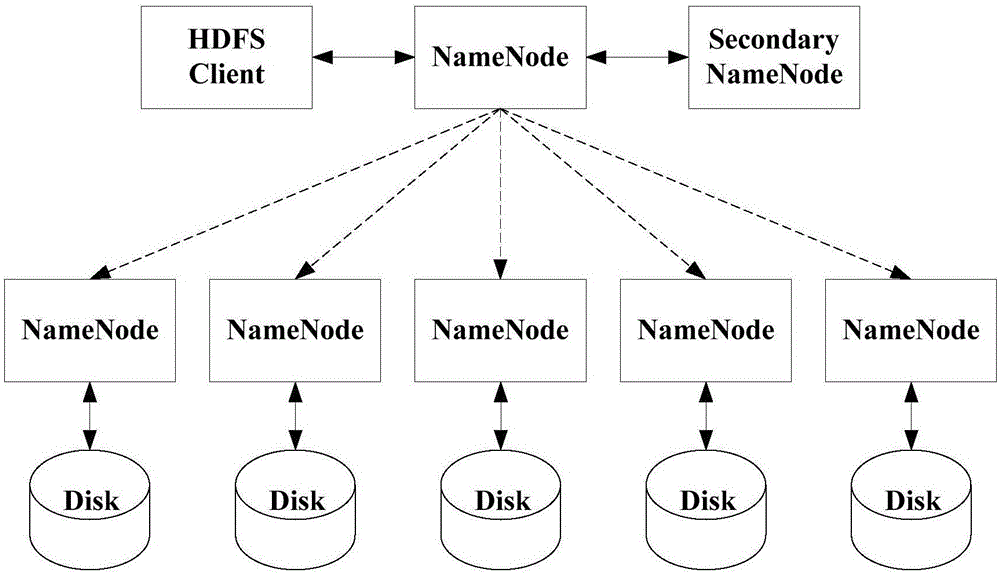
圖1顯示為本發明一實施例的CDH系統結構示意圖。
圖2顯示為本發明一實施例的數據平臺系統的擴展方法流程圖。
圖3顯示為本發明一實施例的腳本內容示意圖。
圖4顯示為本發明一實施例的數據平臺系統的擴展系統模塊圖。
圖5顯示為本發明一實施例的包括擴展系統的電子設備示意圖。
元件標號說明
4 數據平臺系統的擴展系統
400 比對模塊
401 腳本發送模塊
402 應用安裝模塊
5 電子設備
S201~S202 步驟
具體實施方式
以下通過特定的具體實例說明本發明的實施方式,本領域技術人員可由本說明書所揭露的內容輕易地了解本發明的其他優點與功效。本發明還可以通過另外不同的具體實施方式加以實施或應用,本說明書中的各項細節也可以基于不同觀點與應用,在沒有背離本發明的精神下進行各種修飾或改變。需說明的是,在不沖突的情況下,以下實施例及實施例中的特征可以相互組合。
需要說明的是,以下實施例中所提供的圖示僅以示意方式說明本發明的基本構想,遂圖式中僅顯示與本發明中有關的組件而非按照實際實施時的組件數目、形狀及尺寸繪制,其實際實施時各組件的型態、數量及比例可為一種隨意的改變,且其組件布局型態也可能更為復雜。
本發明提供一種數據平臺系統的擴展方法,該數據平臺系統包括管理節點及與其通信連接的數據節點。例如,該數據平臺系統為圖1所示的CDH(Cloudera’s Distribution Including Apache Hadoop)系統,該CDH系統基于Apache協議,基于Apache Hadoop和相關project開發,100%開源,可以做批量處理,交互式SQL查詢和及時查詢,基于角色的權限控制等,是企業中使用最廣的Hadoop分發版本。在該CDH系統中,NameNode為管理節點,用于接收HDFS Client的數據處理需求,并將該數據處理任務分配至各個DataNode數據節點,各個DataNode數據節點并行計算,并把計算結果從寫入的Disk磁盤反饋至HDFS Client。此外,該CDH系統還可以包括與NameNode管理節點通信連接的Secondary NameNode,該Secondary NameNode主要用于定時地對NameNode管理節點中的數據進行備份,以防NameNode管理節點崩潰后會發生數據丟失。以下將詳細介紹該CDH系統中的幾個重要功能模塊:
1)HDFS:CDH應用程序中主要的分布式儲存系統,HDFS集群包含了一個NameNode(管理主節點),這個節點負責管理所有文件系統的元數據及存儲了真實數據的DataNode(數據節點,可以有很多)。HDFS針對海量數據設計,傳統文件系統實現對大批量小文件的優化,HDFS則實現對小批量大型文件的訪問和存儲的優化。
2)Hive:Apache Hive是Hadoop的一個數據倉庫系統,促進了數據的綜述(將結構化的數據文件映射為一張數據庫表)、即席查詢以及存儲在Hadoop兼容系統中的大型數據集分析。Hive提供完整的SQL查詢功能——HiveQL語言,同時,當使用這個語言表達一個邏輯變得低效和繁瑣時,HiveQL還允許傳統的Map/Reduce程序員使用自己定制的Mapper和Reducer進行表達。Hive類似CloudBase,基于hadoop分布式計算平臺上的提供data warehouse的SQL功能的一套軟件,使得存儲在hadoop里面的海量數據的匯總、即席查詢簡單化。
3)Zookeeper:Google中Chubby的一個開源實現,是一個針對大型分布式系統的可靠協調系統,提供的功能包括:配置維護、名字服務、分布式同步、組服務等。ZooKeeper的目標就是封裝好復雜易出錯的關鍵服務,將簡單易用的接口和性能高效、功能穩定的系統提供給用戶。
4)CDH主機項:即圖1中的每個數據計算節點。主機的多少、配置、質量決定著此套CDH系統的優劣,質量越高,處理數據的能力越強。在1主3從的CDH架構中,包括了一個管理節點、3個被管理的數據節點,所有的日志分析、數據處理都會通過主節點分配給這3個數據節點。
以下將以CDH系統為例,詳細闡述本發明的實現過程。優選的,該CDH系統中的管理節點采用linux服務器,由于linux為開源的,不僅能兼容市場上幾乎所有的系統,還不會產生任何系統上的花費,相比于系統費高昂的windows等服務器,大大降低了開銷成本。此外,該CDH系統采用HDFS分布式文件系統進行海量數據存儲,能夠提供高吞吐量的數據訪問,使用1/6的成本就可以是實現原來6倍的性能,以滿足每天進行千萬級的海量用戶的日常運營數據分析和用戶行為挖掘。再有,該CDH系統采用完全互聯網化的關聯系統技術,即系統完全基于C/S技術架構,CDH系統分為Server與Agent兩部分及數據庫,Agent為客戶端負責執行服務端發來的命令,執行方式一般為使用python調用相應的服務shell腳本,有利于實現:管理監控集群主機、統一管理配置、管理維護Hadoop平臺系統等操作。如圖2所示,本發明的擴展方法應用于該CDH系統,主要包括以下步驟:
步驟S201:所述管理節點向待添加數據節點發送用于配置系統環境的腳本文件,以供所述待添加數據節點執行所述腳本文件后完成相應的系統環境設置。如圖3所示,該腳本文件的內容可以包括:安裝執行所述腳本文件的命令的工具編譯包、編輯所述待添加數據節點的名稱、關閉安全設置、安裝常用軟件包、開啟ntp時間服務并加入自動啟動項、修改swappiness以降低對swap緩存的使用、安裝CDH系統運行環境及語言環境、強制刷新、重啟所述待添加數據節點等等,其具體內容可以根據實際功能需要預先編寫、添加。
需要說明的是,所述待添加數據節點的服務器硬件是適合于CDH系統使用的,并且,所述待添加數據節點安裝有Linux服務器操作系統。由于操作系統安裝完成后,系統處于空白狀態,基本上無法使用,一般需要手動安裝基礎軟件環境來支持CDH的快速部署。相比于常規的在安裝環境下一條一條執行命令,本發明采用腳本(如shell腳本)的方式,只需要通過執行此腳本就能自動實現需要的全部功能,從而實現系統基礎環境的快速設置。
步驟S202:所述管理節點為所述待添加數據節點安裝相關應用,從而完成所述待添加數據節點向所述數據平臺系統的添加。也就是說,具體的,服務器基礎環境通過腳本執行安裝完成后,就要開始對CDH節點進行添加的操作,以下將以步驟a)~d)為例,詳細說明在新添加的數據節點服務器上安裝相關應用的詳細內容:
步驟a):useradd--system--home=/opt/cm-5.5.1/run/cloudera-scm-server/--no-create-home--shell=/bin/false--comment"Cloudera SCM User"cloudera-scm#添加cdh管理員賬號;
步驟b):/opt/cm-5.5.1/etc/init.d/cloudera-scm-agent start#打開cdh客戶端服務;
步驟c):./hdfs dfsadmin-refreshNodes#執行命令進行新節點服務器功能安裝;
步驟d):./hadoop-daemon.sh start datanode#新節點安裝完畢開啟節點計算功能。
至此,在hadoop CDH大數據系統中快速添加計算節點服務器的過程結束。
特別的,在一實施例中,在保證CDH系統不宕機、讓數據能夠正常、安全地運行的基礎上,還考慮到資源成本的開銷,本發明的方法還包括:在步驟S201執行之前,對CDH系統中已有的數據節點分別設置預設負荷值,并對其實際負荷值進行監控。這里,負荷的內容可以包括:負載情況、磁盤使用情況、物理內存使用情況等。例如,負荷為磁盤使用情況,則對應的負荷值可以包括:磁盤IO利用率、磁盤等待時間、磁盤平均隊列長度、磁盤服務時間、磁盤等待讀取/等待寫入時間、磁盤讀取/寫入吞吐量等具體數值。當檢測到有數據節點的實際負荷值超過或等于相應的預設負荷值時,開始執行步驟S201,即開始向CDH系統中添加新的數據節點,從而滿足實際數據處理的需要。
請參閱圖4,與上述方法實施例原理相似的是,本發明提供一種數據平臺系統的擴展系統4,作為一套軟件實現,搭載于包括管理節點、及與其通信連接的至少一個數據節點的數據平臺系統,例如:CDH系統,從而實現在該數據平臺系統中添加數據節點的擴展功能。由于前述實施例中的技術特征可以應用于本系統實施例,因而不再重復贅述。
所述系統4包括:腳本發送模塊401、應用安裝模塊402。
腳本發送模塊401的功能在于令所述管理節點向待添加數據節點發送用于配置系統環境的腳本文件,以供所述待添加數據節點執行所述腳本文件后完成相應的系統環境設置,其中,所述腳本文件的內容可以包括:安裝執行所述腳本文件的命令的工具編譯包、編輯所述待添加數據節點的名稱、關閉安全設置、安裝常用軟件包、開啟ntp時間服務并加入自動啟動項、修改swappiness以降低對swap緩存的使用、安裝CDH系統運行環境及語言環境、強制刷新、及重啟所述待添加數據節點中的一種或多種組合。
應用安裝模塊402的功能在于令所述管理節點為所述待添加數據節點安裝相關應用,詳細的,可以包括:添加CDH管理員賬號、開啟CDH客戶端服務、進行所述待添加數據節點的功能安裝、開啟所述待添加數據節點的計算功能中的一種或多種組合,從而完成所述待添加數據節點向所述數據平臺系統的添加。
在一實施例中,所述系統4還包括:比對模塊400,所述至少一個數據節點分別關聯有與其一一對應的至少一個預設負荷值,在所述腳本發送模塊向待添加的數據節點發送腳本文件之前,所述比對模塊獲取所述至少一個數據節點的實際負荷值,并分別與對應的預設負荷值比對;若檢測到存在實際負荷值不小于預設負荷值的數據節點,則向所述腳本發送模塊401發送開始擴展所述數據平臺系統的指令。
請參閱圖5,與上述方法、系統實施例原理相似的是,本發明提供一種包括如上任一所述的數據平臺系統的擴展系統4的電子設備5,例如,包括通信單元(無線通信模塊、有線通信模塊等)、處理單元(CPU芯片等)等部件的服務器,由于前述實施例中的技術特征可以應用于本系統實施例,因而不再重復贅述。
綜上,本發明使用命令行腳本方式在數據平臺系統中快速添加數據節點,能比傳統圖形化添加節點的方式節省三分之二以上的時間,且錯誤率可以降低99%,不論要將多少臺服務器添加為CDH系統的計算節點,只需要統一執行一個腳本就能完成,從而快速支持大數據的并行計算能力,且不耽誤團隊其它人員使用該CDH系統,有效克服了現有技術中的種種缺點而具高度產業利用價值。
上述實施例僅例示性說明本發明的原理及其功效,而非用于限制本發明。任何熟悉此技術的人士皆可在不違背本發明的精神及范疇下,對上述實施例進行修飾或改變。因此,舉凡所屬技術領域中具有通常知識者在未脫離本發明所揭示的精神與技術思想下所完成的一切等效修飾或改變,仍應由本發明的權利要求所涵蓋。
- 還沒有人留言評論。精彩留言會獲得點贊!