一種基于分布式存儲的Docker鏡像下載方法與流程
本發明涉及互聯網領域中的虛擬化方法,特別是涉及通過分布式存儲加速批量下載Docker鏡像的方法。
背景技術:
Docker是一個開源的應用容器引擎,旨在提供一個可以運行應用程序的解決方案,做為目前最流行的輕量級虛擬化技術,因為資源利用率高及啟動速度快,一度被認為是虛擬機的替代品。例如,可以在Linux系統上迅速創建一個容器container(輕量級虛擬機),部署和運行應用成許,并通過配置文件可以輕松實現應用程序的自動化安裝,Docker可以虛擬出多個容器,容器之間可以互相獨立。但發展到現在,Docker技術并沒有虛擬機發成熟,虛擬機是一項高度發展、非常成熟的技術,可以運行最關鍵的業務工作負載,而Docker依舊在開發過程中,網絡棧、安全性、命名空間隔離以及集群管理等依然有很多領域需要改進,同時如何加快Docker鏡像的下載從而提升私有集群中多臺機器啟動相同容器時的速度也是亟待解決的問題。
Docker鏡像作為容器運行環境的基石,徹底解放了Docker容器創建的生命力,開發者可以用一個標準的鏡像構建一套容器,容器開發完成后可以直接使用這個容器部署代碼,鏡像下載過程中需要Docker架構中多個組件的協作。雖然每臺運行Docker的機器上本身都保存著部分鏡像,但Docker還有集中存儲鏡像的地方,Registry就是為集中管理、管理和分發Docker鏡像而設計的項目,目前推薦使用的是Registry的第二個版本,即用golang語言實現的Distribution項目。Docker公司維護了一個類似于github的官方的鏡像存儲網站DocHub,所有Docker用戶都可以申請帳號并從DocHub下載需要的鏡像或者上傳鏡像供他人使用。同時,用戶也可以通過在私有集群中部署Distribution來管理該集群中的鏡像,本實施例中的方法主要是基于布有Distribution的私有集群中的鏡像存儲和下載提速方式。
目前關于Docker鏡像如何在Distribution中存儲的研究主要關注的是針對Docker鏡像分層的特點,為Distribution開發可以加快鏡像查找和下載速度的新的存儲系統,或者為現有的文件系統開發驅動。
(1)為現有存儲系統提供driver
為Docker Distribution提供的官方的后端存儲系統編寫driver,大體推薦選擇的存儲系統有這幾個:Local Filesystem、S3、Swift、glance、Google gcs。Local Filesystem這個可能在鏡像很少的情況下出于簡單性會選擇使用,主要問題顯而易見,擴展性、可用性方面都受到很大的約束。Swift是一個Consistent Hash的拓撲結構,添加機器需要遷移一部分數據過來,分布式文件系統中文件的潛移導致帶寬占用會比較大,影響線上服務。S3解決方案對很多不想自己開發文件系統,但同時希望鏡像存儲端有不錯的擴展性及可用性方面的能力的企業來說也是一個可行的選擇。
上述方法通過使用分布式存儲系統增加了Distribution存儲Docker鏡像的擴展性和可用性,但由于這些通用的存儲系統并非針對于Docker鏡像分層并且每個層次大小差別很大的特點設計的,所以對于存儲、檢索和下載Docker鏡像的效率并沒有提高。
(2)設計新的Docker鏡像存儲系統
Speedy是京東公司開發的Docker鏡像存儲系統,存儲上將多個小文件合并成一個大文件存儲,減少元數據存儲空間開銷和性能開銷,同時在原生文件系統上通過預分配空間方式,提供接近裸盤的讀寫性能,但兼具原生文件系統的易用性,針對大文件做優化,提供斷點續傳、失敗重試等功能。
在上述方法中,京東雖然通過針對Docker鏡像的特點編寫了特定的存儲系統,并通過使用專用的數據庫來存儲元數據等方式加快了鏡像查找下載速度,使存儲本身已經不是瓶頸。但Distribution所在節點網卡的性能成為了新的瓶頸,該結構并不能擺脫單點瓶頸問題。
綜上,無論是為現有存儲系統寫驅動還是針對Docker鏡像編寫新的存儲系統,在現有Distribution架構下,都不能避免Distribution節點的網絡瓶頸問題。
技術實現要素:
本發明針對現有技術的不足,結合Distribution和分布式文件系統設計新的鏡像分發架構,利用分布式文件系統將鏡像分片存儲,Docker節點(這里的節點指的是物理計算機節點,下文中類似術語皆指物理節點)向Distribution節點發送請求時只傳送元數據,真正的數據去實際的分布式存儲節點中去取,從而真正緩解Distribution節點的網絡瓶頸。
為了解決上述技術問題,本發明提供一種基于分布式存儲的Docker鏡像下載方法,其步驟如下:
步驟S101:將分布式文件系統掛在Registry節點存儲鏡像的目錄,并且集群中所有節點都要創建與Registry節點存儲鏡像目錄相同的目錄并掛載分布式文件系統;
步驟S102:集群中的Docker節點向Registry節點請求下載鏡像;
步驟S103:Registry節點根據Docker節點的請求確定鏡像層數據在分布式文件系統中的存儲位置,并將獲得的鏡像元數據返回給Docker節點;
步驟S104:Docker節點根據從Registry節點接收到的元數據確定鏡像數據的存儲位置,并直接到存儲節點提取鏡像數據。
步驟S101進一步包括:Registry節點在啟動時會指定一個yml文件作為參數,在該文件中設置Registry節點存儲Docker鏡像的目錄、所用的緩存、提供服務的端口以及后端存儲的驅動等內容。在與Docker節點建立連接前,Registry節點先要進行初始化,在初始化的過程中確定要使用的后端存儲,并加載相應的驅動。
步驟S102進一步包括:集群中的運行Docker的節點向運行Registry的節點請求下載需要的鏡像,集群中運行著Docker的機器啟動要使用的容器,如果這些要啟動容器的節點上沒有對應的鏡像,Docker節點根據Registry所在節點的IP地址和提供服務的端口號等參數,向Registry節點請求下載鏡像,這些請求被發送至Registry節點。
步驟S103進一步包括:Registry節點查找是否存在要下載的鏡像,如果不存在則返回無相應鏡像標識;若存在則Registry會從分布式文件系統讀取Docker鏡像的manifest并傳遞給Docker節點,其中manifest包含鏡像所含所有層的哈希值。Registry根據解析manifest得到的鏡像包含的所有層的哈希值及各層之間的依賴關系,獲取鏡像層的存儲目錄位置,根據獲取的所述存儲目錄位置讀取出鏡像層文件存儲的目錄、文件名、大小等元數據,之后將這些元數據傳遞給Docker節點。
進一步的,其中所述所有層的哈希值是使用安全散列算法SHA-256對鏡像層數據進行運算,得出的256位長的消息摘要。
步驟S104進一步包括:Docker節點將從Registry節點接收到的鏡像層的存儲目錄和文件名作為輸入,通過一致性哈希算法計算出哈希值,確定鏡像層在分布式文件系統中的實際存儲位置,并通過通用的posix標準接口讀取鏡像數據,通過哈希校驗鏡像數據完整性并啟動容器。
進一步地,哈希校驗具體是:Docker節點從分布式存儲系統讀取完鏡像層數據后,對讀取的鏡像層數據用SHA-256算法做運算,如果得出的256位的哈希值和manifest中存儲的對應的哈希值相等,則說明讀取的數據是完整,否則說明讀取數據的過程出錯。
采用本發明可以達到以下技術效果:
當集群中運行有Docker的大量機器同時向運行有Distribution的節點請求下載Docker鏡像時,避免了原始架構中Distribution節點容易成為網絡瓶頸的弊端,將數據下載流量均勻分散到分布式存儲系統所處的機器上,從而加速了鏡像分發過程。
附圖說明
圖1為本發明基于分布式存儲的Docker鏡像批量下載方法的流程圖;
圖2為本發明基于分布式存儲系統Glusterfs為例的分布式存儲的Docker鏡像批量下載方法的簡化架構示意圖;
圖3為本發明基于分布式存儲的Docker鏡像批量下載方法的詳細操作流程圖;
圖4為本發明基于分布式存儲的Docker鏡像批量下載技術的數據流圖。
具體實施方式
為了使本申請中的技術方案被更好地理解,下面將結合本申請實施例中的附圖和具體實施方式,對本申請進行清楚、詳細的描述。
首先對本發明涉及的術語及邏輯關系定義如下:
Docker是一個開源的應用容器引擎,它經常被用于和虛擬機相對比;與虛擬機啟動鏡像類似,Docker也需要基于具體的鏡像來啟動,Docker將鏡像啟動后就形成一個容器;與虛擬機鏡像不同,為了減少存儲空間并減少分發鏡像時的數據下載量,Docker鏡像被設計成分層(layer)的,同一個鏡像的layers通過union mount的方式連接成一個完整的鏡像,同時,當兩個不同的Docker鏡像含有相同的layer時,只需要存儲一次,節省了存儲空間;為了便于管理鏡像,Docker設計了manifest結構,該結構定義了Docker鏡像包含了哪些layer和這些layer之間的依賴關系;同時,為了統一的存儲、管理和分發Docker鏡像,Docker公司還牽頭開發了Registry項目,集群中運行Docker的機器可以向Registry上傳鏡像供他人使用,也可以下載鏡像,目前Registry已經出現了使用較廣的第二代版本,即Distribution項目。另外,在本文中節點指的是Docker、Distribution或者分布式存儲系統所在的物理機器;集群指的是運行著Docker,并且包含運行著Distribution的節點的私有計算機集群。本文方案可統一在Registry下實現,而不僅限于Distribution項目。
參見圖1,該圖示出了本申請的基于分布式存儲的Docker鏡像批量下載方法的流程。該實施例包括:
1、步驟S101,將分布式文件系統掛載在Registry節點存儲鏡像的目錄,并且集群中所有節點都要創建與Registry節點存儲鏡像目錄相同的目錄并掛載分布式文件系統。
更具體地,包括:確定Registry節點存儲Docker鏡像的目錄,在該運行Registry的節點上將要使用的后端存儲系統掛載到該存儲Docker鏡像的目錄,同時在集群中的所有節點上創建與Registry節點的鏡像存儲目錄相同的目錄,并將使用的分布式文件系統掛載到目錄上。
很多分布式存儲系統的掛載方式已經做的非常簡單,比如Glusterfs、Ceph可以用linux下載mount命令直接掛載存儲目錄,此處所說的集群是實體計算機集合,節點是一臺計算機。
2、步驟S102,集群中的運行Docker的節點向運行Registry的節點請求下載需要的鏡像,集群中運行著Docker的機器啟動要使用的容器,如果這些要啟動容器的節點上沒有對應的鏡像,那么Docker節點會向Registry節點請求下載鏡像,即會從運行Registry程序的節點下載鏡像。
Docker在通過run命令啟動容器而Docker宿主機并不含有運行該容器對應的鏡像或者Docker通過pull命令直接下載鏡像時,如果在集群中已經運行了Registry,并且Docker運行命令run或者pull命令時添加了Registry所在節點的IP地址和提供服務的端口號等參數,這些請求就會被發送至Registry節點。
3、步驟S103,Registry節點根據Docker節點的請求中所帶有的具體參數確定要下載的Docker鏡像數據在分布式文件系統中的存儲位置等數據,并將獲得的數據返回給Docker節點。由于鏡像由許多層構成,鏡像數據實際就是鏡像層的數據。這里首先說明Registry存儲鏡像層目錄的特點,在Registry中,鏡像層存儲位置的前面幾級目錄是固定的,最后一級目錄是以鏡像層為輸入通過安全散列算法SHA-256計算出的哈希值。
進一步地,其中包括將Docker鏡像的manifest傳遞給Registry,manifest是描述整個鏡像組成的一個數據結構,其中包含鏡像所含所有層的哈希值,這個哈希值是使用安全散列算法SHA-256對鏡像層數據進行運算,得出的256位長的消息摘要。Registry通過解析manifest得到鏡像包含的所有層的哈希值獲取鏡像層的存儲目錄位置。一旦獲取了鏡像層的存儲位置,Registry就可以讀取鏡像層的目錄、文件名、大小等元數據,并將這些數據傳遞給Docker節點。
Registry解析鏡像的manifest獲取出SHA哈希值。Docker在上傳鏡像時會上傳鏡像對應的manifest,里面已經含有了每層SHA哈希值,如果不含有,那么在上傳過程中會運行SHA-256算法,計算出該值并填入manifest,所以在registry只需要從manifest讀取就可以。
因為在Registry中,為了節約存儲空間,一個Docker鏡像包含的鏡像層并不集中存儲到一塊兒,各鏡像層分開存儲,其存儲的前面幾級目錄都是確定的,只有最后一級目錄是該層在manifest中對應的哈希值。這樣,Registry在解析了manifest并得到各層對應的哈希值和依賴關系后,便可以拼接出鏡像層存儲位置的目錄。在原來的架構中,這里會繼續讀取鏡像層內容并傳給Docker節點。
在原始的架構中,Registry在接收到鏡像下載請求時,通過解析manifest得到標識鏡像層的哈希值并拼接出鏡像層的具體存儲目錄后,會繼續去Registry的存儲后端提取鏡像數據返回給Docker節點,當存儲后端并不是Registry所在節點的本地文件系統后,則會首先將鏡像數據從存儲后端所在的機器讀取到Registry節點然后再傳送到請求鏡像的Docker所在節點,即整個鏡像數據都要通過Registry節點,Docker接收到鏡像的所有層的內容后,可以通過解析的依賴關系拼接成整個鏡像。這種松耦合的存儲結構有效避免了鏡像層的重復存儲;而在我們發明的架構中,Registry在解析出鏡像層的存儲位置目錄后,會繼續根據獲取的位置信息讀取出鏡像層文件存儲的目錄、文件名、大小等信息,之后將這些鏡像層數據的目錄名、文件名、大小等元數據傳遞給Docker節點。
4、步驟S104,Docker節點根據從Registry節點接收到的數據得到鏡像數據的存儲位置,并直接到分布式存儲節點提取鏡像數據:Docker在執行run命令運行特定鏡像對應的容器或者執行pull命令直接下載鏡像時,該Docker所在的機器中不再是直接從Registry所在節點提取鏡像數據了,而是根據Registry返回的元數據信息直接去分布式存儲節點提取數據,通過一致性哈希算法計算出哈希值,確定鏡像層的實際存儲位置,并通過通用的posix標準接口讀取鏡像數據,這樣大大緩解了Registry所在節點的網絡壓力。
這里所用的一致性哈希算法與上面manifest中存的計算鏡像層的哈希算法是不同的,計算鏡像層哈希值用的是安全散列算法SHA-256,是為了用一個固定的256位長度的字符串指代鏡像層,該算法產生的哈希值會根據輸入的鏡像層內容不同而改變,且重復的概率幾乎為零;而一致性哈希算法,是一種分布式哈希實現算法,在這里解決的是文件的定位問題。具體的實現方式是,一致性哈希算法將輸入的文件目錄和文件名,經過哈希計算后散列到一個環上,之后將運行有分布式文件系統的機器也通過該算法映射到環上,這樣文件對象和機器位于同一個哈希空間中,就能快速定位對象位于的機器了。
接收到數據后再通過做哈希校驗數據完整性。這里哈希校驗的目的是為了確保Docker根據Registry返回的元數據而從分布式文件系統讀取的數據的完整性,具體校驗方法是,前面我們說過manifest中存儲著鏡像包括的所有層的哈希值,這個值是通過以鏡像層數據為數據通過SHA-256算法計算出的可以唯一標識對應鏡像層的256位長的字符串,這里在Docker節點從分布式存儲系統讀取完鏡像數據后,如果這個數據是完整的,那么再對這個讀取的鏡像層數據用SHA-256算法做運算,得出的256位的哈希值應該是和manifest中存儲的對應的哈希值是相等的。如果不相等,說明讀取數據的過程出了錯。
步驟S101中已經將分布式文件系統掛載在Registry節點存儲鏡像的目錄,并且集群中所有Docker節點都已經創建了與Registry節點存儲鏡像目錄相同的目錄并掛載分布式文件系統,根據分布式文件系統比如Glusterfs、Ceph的原有特性,在Docker節點上訪問掛載的目錄下的文件其實和在Registry節點上訪問掛在目錄下相同文件最后訪問到的其實是同一個數據。另外,Registry節點在存儲鏡像層數據時,是以鏡像層數據存儲的目錄和文件名為輸入,通過一致性哈希算法計算得出這些數據在分布式文件系統中的實際存儲位置的。又因為,Docker節點上在相同目錄同樣掛在了存儲鏡像的文件系統,所以在Docker接收到Registry傳遞來的包含鏡像層存儲目錄、文件名、大小等信息時,可以依然以存儲目錄和文件名為輸入再次通過一致性哈希算法計算得出鏡像在分布式文件系統中的具體存儲位置,從而可以繞過Registry節點直接到分布式文件系統去讀取數據。
Docker的鏡像下載包括集群中的多臺機器,涉及Registry節點、Docker節點和分布式存儲系統所在的節點。
步驟S101中,集群中節點,即物理機,在分布式存儲節點上要預先裝上要用的文件系統,其他節點上裝上該文件系統的客戶端。Registry在啟動時會指定一個yml文件作為參數,在該文件中設置Registry存儲Docker鏡像的目錄、所用的緩存、提供服務的端口以及后端存儲的驅動等內容。這里,不同的后端分布式文件系統需要不同的驅動,現在也有很多機構為Registry針對不同的存儲系統編寫不同的驅動。但是,在本發明中作為Registry后端存儲,并不是簡單地為Registry針對要使用的分布式文件系統寫一個驅動,而是使該文件系統可以無縫的存儲鏡像。
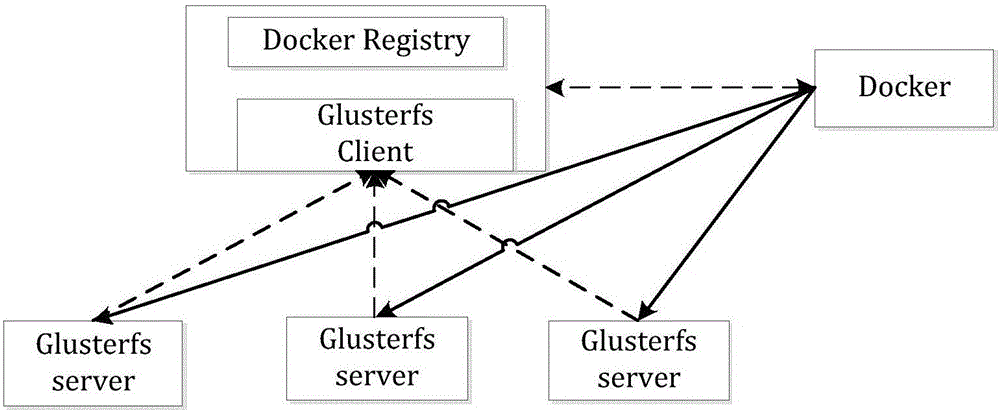
如圖2示例所示,結合Docker鏡像下載過程,以分布式文件系統Glusterfs為例,改變從Registry下載鏡像的架構實現Docke與Registry交換元數據,而從分布式文件系統接收實際鏡像數據。這種實現,對Registry和Docker兩端的源碼都進行了更改。
在具體介紹圖2代表的流程之前,首先對該圖中的模塊做簡要說明,該圖中右側標記有Docker的模塊指的是運行有Docker程序的物理機器,其左側標有Docker Registry和Glusterfs Client的模塊指代的是運行有Registry程序的機器,為了實現發明中描述的功能,在此機器上還安裝了分布式文件系統Glusterfs的客戶端,下面三個標有Glusterfs Server的模塊指代的是安裝有分布式文件系統的機器,途中的連線指的數據傳輸過程。
在改變架構之前所有數據都是通過圖2中的虛線所示的通道傳遞的,Docker會首先向Registry發出下載鏡像的請求,之后Registry會根據Docker請求的鏡像以及在與Docker交互的過程中得到的要下載的鏡像的manifest,Registry根據解析manifest得到的鏡像包含的層的哈希值以及層之間的依賴關系等數據等直接定位鏡像數據的存儲目錄,這個哈希值是以鏡像層數據為輸入,通過SHA-256算法計算出的可以唯一標識對應鏡像層的256位長字符串;然后再以鏡像層的存儲目錄和文件名為輸入,通過一致性哈希算法定位鏡像數據在分布式文件系統中的具體存儲位置并讀取鏡像數據,之后經過Registry節點傳遞到請求下載鏡像的Docker節點,可見整個過程都要經過Registry節點,從而Registry節點成為瓶頸。
本發明改變架構之后,只有鏡像的元數據以及Registry和Docker間的控制流的交互是通過圖2中的虛線指示的通道傳遞的,而真正的鏡像數據的傳輸則是通過圖2中實線所指的通道實現的。本發明中結合已經在Registry節點、Docker節點和分布式存儲結點掛載的目錄更改Docker在下載鏡像時的代碼和Registry在接收到Docker發送來的鏡像下載請求時的處理方式的代碼,Registry中屏蔽了原來接收到Docker發送請求時的處理函數,新增了接收到Docker發送層下載請求時確定該數據存儲目錄以及文件名、文件大小的函數,并通過HTTP發送給Docker;Docker端新增加了接收到從Registry端接收到數據存儲目錄、文件名數據時的處理函數,此時Docker節點會以得到的鏡像層存儲目錄和文件名為輸入,通過一致性哈希算法計算,確定鏡像層在分布式文件系統中的實際存儲位置,直接去提取。
在與Docker建立連接前,Registry先要進行初始化,在初始化的過程中確定要使用的后端存儲,并加載相應的驅動。
步驟S102中,本發明雖然改變了Registry與Docker交換實際鏡像的方式,將原始的交換數據必須經過Registry節點的架構改變為了交換實際鏡像數據時Docker會繞過Registry節點之間從分布式文件系統所部署的機器上提取的方式,但是并沒有破壞Docker原本的使用方式,只要做好了本發明系統所有的準備工作,集群中的機器在啟動大量容器時只需像之前一樣運行run命令就可以,Docker會正常通過本發明中的數據傳輸流程下載鏡像并做好hash校驗后存儲到本地,并基于通過本發明系統下載好的鏡像運行容器。
步驟S103和S104描述了從Registry接收鏡像下載請求到Docker接收到鏡像數據的全過程,流程如圖3所示,具體如下:
Docker節點通過下載鏡像或者運行容器的命令向Registry節點請求要下載的鏡像;
Registry節點和Docker節點間相互認證建立安全連接;
Registry節點接收請求并根據初始化時注冊的Handler提供服務,其中Handler包含的是Registry節點在接收到Docker節點發送來的請求時的處理函數。本發明實現的結合后端分布式存儲系統從而僅通過Registry傳遞元數據,具體鏡像數據繞過Registry節點,其中就改變了Handler中了部分代碼,并新添加了向Docker返回文件存儲目錄數據信息的函數,相應的也在Docker的源碼中添加了向分布式文件系統中讀取鏡像數據的函數。本發明中元數據的傳輸并沒有繞過Registry節點,因為元數據原本就很小,不會占用太多流量,假如繞過Registry在判斷完整性方面反而會有延遲。所以,本發明中,Registry會根據在初始化時注冊的存儲驅動以及在步驟S101中掛載的文件系統,去查找是否存在要下載的鏡像,如果不存在返回無相應鏡像標識,若存在則首先從文件系統中讀取鏡像的manifest到Registry節點,之后返回給Docker節點;
前面已經解釋過每個鏡像對應的manifest結構包含了該鏡像所包含的所有layers(鏡像層)的名稱、大小、依賴關系等數據。Docker接收到從Registry返回的manifest后會讀取manifest中包含的鏡像層并與本地存儲的鏡像層做對比,找出本地不存在的層返回給Registry節點;
接下來,按照原來的架構Registry會繼續從后端存儲系統中讀取實際鏡像數據,然后經過Registry節點中轉最后傳遞給Docker節點;
本發明中,這次Registry接收到請求后,并不會直接去分布式存儲中讀取鏡像層數據,而是根據接收到的層的名稱確定該層對應的存儲目錄以及對應文件大小等元數據,之后Registry節點將這些元數據傳遞給Docker節點;
Docker節點由于在準備階段也創建了與Registry節點指定的存儲鏡像的目錄相同的目錄,并也在目錄上與Registry節點掛載了同樣文件系統并做了相應配置,故Docker節點可以將從Registry節點接收到的鏡像層的存儲目錄和文件名作為數據,根據分布式文件系統使用的通過對鏡像層存儲的目錄以及文件名計算分布式hash值,確定鏡像層的實際存儲位置,具體可以得出鏡像存儲位置的原因已經在前面有過描述,并通過通用的posix標準接口讀取鏡像層的數據,即鏡像層數據。
具體的數據流如圖4所示,這里首先對圖中包括的模塊做簡要解釋,圖中右側標有Docker的模塊指的是運行有Docker程序的物理機器;左側標有Distribution FrontEnd的比較大的模塊指的是運行有第二代版本的Registry,即Distribution的物理機器,其中,Configuration模塊是用來Distribution啟動時注冊所使用的后端存儲驅動、服務端口號等數據的,App中做得是將Configuration中讀取到的配置數據加載到具體的對象并運行對象對外提供服務,Http Server做的是監聽Docker連接和請求、并把處理結果返回給Docker,Router是一個分發器,根據接收到的請求的不同分發到不同的Handler,Handler就是接收到請求后使用的具體處理函數了;下方標有Distribution BackEnd的模塊指代的是安裝有分布式文件系統的物理機器,因為其要存儲位于Distribution中的Docker鏡像,這里將其命名為Distribution BackEnd;其通過linux中的mount命令掛載到Distribution節點,即圖中Mount模塊。其中步驟①指的是Docker發送鏡像下載請求,步驟②是指Registry從后端分布式存儲提取manifest數據并返回給Docker,因為每個Docker鏡像都對應一個manifest,manifest中記錄了鏡像包含的鏡像層(layer),前面說過layer存儲的前面幾級目錄都是固定的,只有最后一級目錄是通過計算layer的hash值得到的,而且manifest中記錄了layer的hash值,所以這里根據拼接起的目錄讀取manifest并不困難,步驟③是指Docker通過接收到的manifest計算得出本地不存在的鏡像layer并就需要下載的層再次發送請求到Registry,步驟④指的就是Registry去后端存儲提取實際鏡像數據的元數據并傳送給Docker,這里所說的元數據主要是指鏡像層的存儲目錄、文件名以及大小等,將這些數據傳遞給Docker,讓Docker可以據此計算出鏡像層的實際存儲位置,與上面所述類似,因為鏡像層的存儲目錄有規律,所以這部讀取元數據并不困難,步驟⑤便是Docker根據從Registry接收到的鏡像元數據信息直接去后端存儲中去讀取實際鏡像數據。
本發明目的是為了通過用分布式文件系統做為Registry存儲后端并繞過Registry直接傳遞鏡像數據到Docker節點,從而減輕Registry節點的網絡壓力。所以,如何讓容器鏡像數據均勻的分布到存儲節點從而讓Docker節點可以同時從盡可能多的節點下載數據成為關注點之一。經過大量嘗試和實驗,本發明指出分布式文件系統中的分片最能實現該目的,通過分片的方式可以將一個比較大的layer分成幾乎大小相等的數據片,從而均勻的分散到分布式文件系統所處的機器上,繼而分散了網絡流量,比如Glusterfs中的stripe卷。在Glusterfs中只需確定存儲系統所使用的機器,在掛載到鏡像存儲目錄時加上stripe參數便指定為了分片的存儲方式,同時在掛載時還可以在參數中指定分片的大小,分片太大或者太小效果都不會太明顯,太大了超過了一些鏡像layer的總大小會使鏡像在文件系統中的分布不均勻,太小了導致元數據操作太頻繁,經測試3M-4M這個區間比較合適,在五臺存儲節點以及由10臺機器構成的Docker集群的基礎上測試鏡像下載速度已經提升了3倍以上,隨著集群規模的增大,這個速度的提升將更加明顯。
Docker節點從分布式存儲中讀取完數據后要做的就是對從各存儲節點讀取來的數據進行合并,之前提到過在運行Docker的機器上也掛在了Glusterfs的客戶端,這一步就是Glusterfs客戶端完成的,合并完成后做hash完整性校驗,在確定了鏡像完整性后就可以在此基礎上啟動容器了。
本發明不僅僅是對鏡像的下載過程做了優化,同時也改變了鏡像的上傳流程。
Docker節點在保存對鏡像的更改后,如果想上傳到Registry并分享給集群中其他節點使用時,像未改動之前一樣,可以直接將要分享的鏡像作為參數通過docker push命令本上傳到Registry,本發明未對鏡像處理的命令做任何改動,這也是該實施例的一個優點。
同下載流程相似,在本發明中,在完整準備工作并做好初始化后,依舊是僅僅通過Registry傳遞鏡像元數據,而需要上傳的實際數據則繞過Registry直接寫入到分布式文件系統,這是本發明的另一個實施例。
Docker鏡像在執行上傳時,首先會向Registry發送請求并發送要上傳的鏡像層元數據,但是并不會直接將鏡像數據上傳,Registry接收到元數據后經處理會返回給Docker端一個目錄,由于所有節點在準備階段已經做好分布式存儲系統的掛載等初始化工作,Docker可以根據接收到的目錄繞過Registry直接通過通用的posix接口向分布式存儲系統寫數據。每上傳一層,Docker都會在鏡像對應的manifest中填寫該layer層的元數據消息。通過循環的方式將鏡像各layer的數據上傳完后,便完成了整個鏡像manifest的組織,然后將該manifest傳遞給Registry。之后,Registry就可以根據此來通過hash方法校驗寫入到存儲系統中的數據的完整性了。上述流程完成后,鏡像便組織到Registry中,集群中其他機器又可以下載使用該上傳的鏡像了。
通過本發明方案的處理,可以分散鏡像下載時流過Registry節點的數據量,避免了Registry成為整個系統的瓶頸,從而提高了分發鏡像的速度。本發明已經對該方法進行了實現和測試,經測試在含有五臺分布式存儲節點、一臺運行Distribution的節點和十臺運行Docker的節點中,鏡像下載速度提升了將近三倍以上,當集群規模增大時,還會有更大的提升。
最后所應說明的是,以上實施例僅用以說明本發明的技術方案而非限制,盡管參照較佳實施例對本發明進行了詳細說明,本領域的普通技術人員應當理解,可以對本發明的技術方案進行修改或者等同替換,而不脫離本發明技術方案的精神和范圍。
- 還沒有人留言評論。精彩留言會獲得點贊!