4R4W全共享報文的數據緩存處理方法及數據處理系統與流程
本發明涉及網絡通信技術領域,尤其涉及一種4R4W全共享報文的數據緩存處理方法及數據處理系統。
背景技術:
在設計以太網交換芯片時,通常需要使用大容量的多端口存儲器,例如2讀1寫(同時支持2個讀端口和1個寫端口)存儲器、1讀2寫存儲器、2讀2寫存儲器或者更多端口的存儲器。
通常情況下,供應商一般只提供1個讀或者寫存儲器、1讀1寫存儲器和2個讀或者寫存儲器,如此,設計者僅能基于上述基本存儲器單元構建多個端口的存儲器。
報文緩存是一類特殊的多端口存儲器,其寫入是可控的,亦即,順序寫入,但是讀出卻是隨機的。用戶的其中一種需求中,單向交換容量為2.4Tbps的以太網交換芯片,為了做到線速寫入和讀出,每個最小報文(64字節)花費的時間只有280ps,需要核心頻率高達3.571GHz,該種需求目前在現有的半導體工藝上無法實現。為了實現上述目標,通常的做法是,把整個芯片分割成多個獨立的報文轉發和處理單元并行進行處理,報文轉發和處理單元的英文名稱為Slice,例如分割成4個Slice并行處理,每個Slice需要處理的數據帶寬就降低,對核心頻率的要求也會降低到原核心頻率的1/4。相應的,實現該方案過程中,對于報文緩存需要同時提供8個端口供4個Slice訪問,其中4個是讀端口,4個是寫端口。
一般的,在SRAM的端口類型為1個讀或者寫,2個讀或者寫,以及1寫或者2讀的基礎上,通過定制設計,例如:修改存儲單元的辦法,以及算法設計來增加SRAM的端口數量。
定制設計的周期一般比較長,需要做spice仿真,還要提供存儲器編譯器,以生成不同大小和類型的SRAM,對于供應商來說,一般需要6~9個月的時間,才能提供一個新型的SRAM的類型,而且這樣的定制設計是與具體的工藝(例如GlobalFoundries 14nm, 28nm還是TSMC的28nm,16nm)強相關的,工藝一旦改變,定制設計的SRAM庫需要重新設計。
算法設計是基于廠家提供的現成的SRAM類型,通過算法來實現多端口存儲器,最大的好處是避免定制設計,縮短時間,同時設計與廠家庫無關,可以很容易的在不同的廠家庫之間移植。
如圖1所示,一種通過算法設計的方式,設計一個支持4個slice訪問的4R4W的存儲架構,該實施方式中,采用1R1W的SRAM2D設計大容量的2R2W的SRAM,邏輯上總共需要4塊65536深度2304寬度大小的SRAM2D,由于單個物理SRAM2D的容量無法滿足上述需求,需要把1塊65536深度2304寬度的邏輯SRAM切割成多塊物理SRAM,例如:可以切割成32塊16384深度288寬度的物理塊,這樣總共需要32x4=128塊物理塊;以上述2R2W SRAM為基本單元,搭建18M字節大小的4R4W SRAM。
結合圖2所示,邏輯上總共需要4塊65536深度2304寬度大小的2R2W的SRAM,即:需要SRAM2D(16384深度288寬度)的物理塊的個數為512塊;根據現有數據可知:14nm工藝條件下,一塊16384深度288寬度大小SRAM2D物理塊的大小是0.4165平方厘米,功耗是0.108Watts(核心電壓=0.9V,結溫=125攝氏度,工藝條件是最快);上述采用廠家庫提供的基本單元SRAM復制多份拷貝,構建更多端口SRAM的方法,雖然設計原理上顯而易見,但是面積開銷非常大,以上述方案為例,單單18M字節4R4W SRAM的面積就占用了213.248平方厘米,總的功耗為55.296Watts,這里還沒有考慮到插入Decap和DFT以及布局布線的開銷,通過此種算法設計方式設計出的4R4W SRAM,其占用面積以及總功耗均十分龐大;
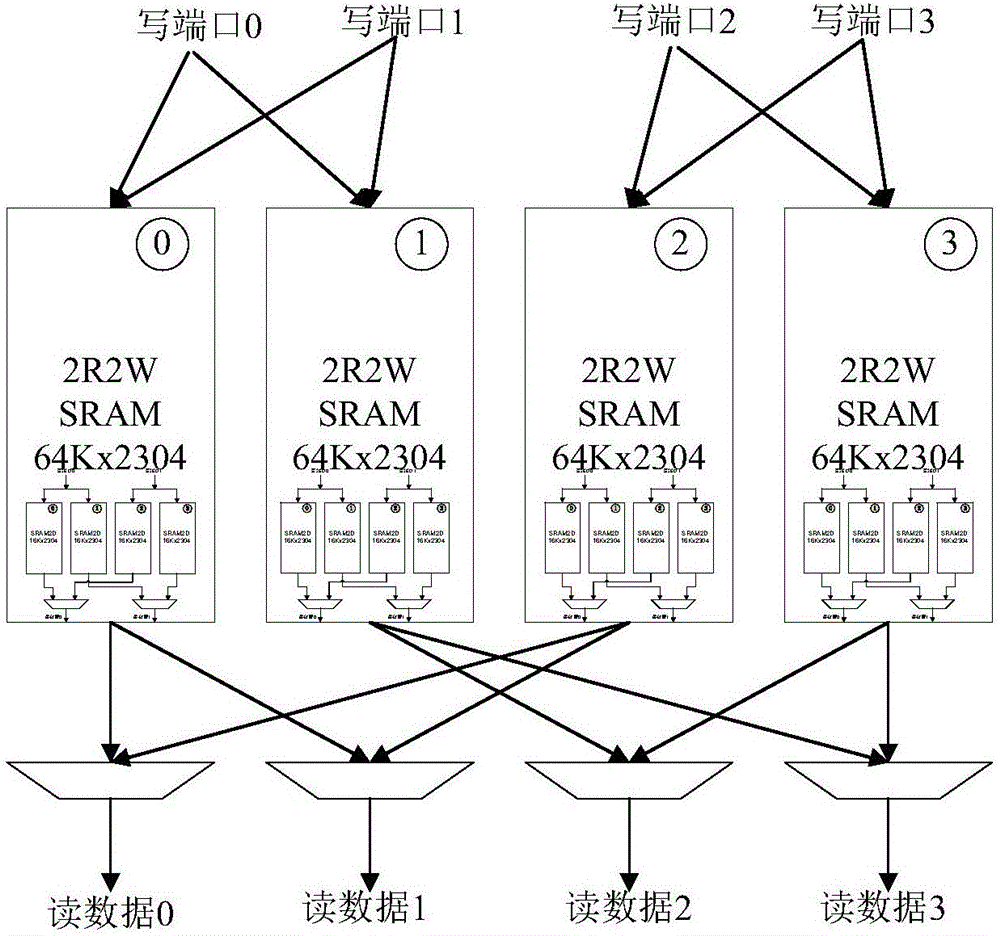
如圖3所示,現有技術中另外一種算法設計方式,以2R2W的SRAM為基本單元,通過空間上的分割實現4R4W SRAM的報文緩存,每個XY是一個2R2W的SRAM邏輯塊,大小是4.5M字節,總共有4塊這樣的SRAM邏輯塊,構成4R4W SRAM,大小是18M字節(4.5Mx4=18M);
其中,S0、S1、S2、S3代表4個slice,每個slice舉例來說包含有6個100GE端口,從slice0或者slice1輸入去往slice0或者slice1的報文存入X0Y0, 從slice0或者slice1輸入去往slice2或者slice3的報文存入X1Y0,從slice2或者slice3輸入去往slice0或者slice1的報文存入X0Y1, 從slice2或者slice3輸入去往slice2或者slice3的報文存入X1Y1;對于組播報文,從Slice0或者Slice1來的組播報文同時存入X0Y0和X1Y0中;進一步的,讀取報文的時候,slice0或者slice1將從X0Y0或者X0Y1中讀取報文,slice2或者slice3將從X1Y0或者X1Y1中讀取報文。
結合圖4所示,現有技術中算法設計的每一個X1Y1的架構圖,一個XY邏輯上需要4塊16384深度2304寬度的SRAM,每一個邏輯上16384深度和2304寬度的SRAM可以切割成8塊16384深度和288寬度的物理SRAM2D;14nm集成電路工藝下,這樣一個18M字節的報文緩存總共需要4x4x8=128塊16384深度和288寬度的物理SRAM2D,總的面積為51.312平方厘米,總的功耗是13.824Watts(核心電壓=0.9V,結溫=125攝氏度,工藝條件是最快)
上述第二種算法設計的面積和功耗開銷只有第一種算法設計的1/4,然而,該算法設計無法實現4個2R2W的SRAM 邏輯塊在所有的4個slice之間共享,每個Slice輸入端口能夠占用的最大報文緩存只有9M字節,這樣的報文緩存不是真正意義上的共享緩存。
技術實現要素:
為解決上述技術問題,本發明的目的在于提供一種4R4W全共享報文的數據緩存處理方法及處理系統。
為實現上述發明目的之一,本發明一實施方式提供的4R4W全共享報文的數據緩存處理方法,所述方法還包括:將2個2R1W存儲器并行拼裝為一個Bank存儲單元;
直接基于4個所述Bank存儲單元形成4R4W存儲器的硬件框架;
一個時鐘周期下,當數據通過4個寫端口寫入到4R4W存儲器時,
若數據的大小小于等于所述2R1W存儲器的位寬,則將數據分別寫入不同Bank中,同時,對寫入的數據進行復制,分別寫入至每個Bank的2個2R1W存儲器中;
若數據的大小大于所述2R1W存儲器的位寬,則等待第二個時鐘周期,當第二個時鐘周期到來時,將數據分別寫入不同Bank中,同時,將每個寫入數據的高低位分別寫入至每個Bank存儲單元的2個2R1W存儲器中。
作為本發明一實施方式的進一步改進,所述方法還包括:
一個時鐘周期下,當數據從4R4W存儲器讀出時,
若數據的大小小于等于所述2R1W存儲器的位寬,則選擇4R4W的存儲器中匹配的讀端口直接讀出數據;
若數據的大小大于所述2R1W存儲器的位寬,則等待第二個時鐘周期,當第二個時鐘周期到來時,選擇4R4W存儲器中匹配的讀端口直接讀出數據。
作為本發明一實施方式的進一步改進,所述方法還包括:
當數據寫入所述4R4W存儲器時,根據每個Bank的剩余空閑資源選擇數據的寫入位置。
作為本發明一實施方式的進一步改進,所述方法具體包括:
為每個Bank對應建立一空閑緩存資源池,所述空閑緩存資源池用于存儲當前對應Bank的剩余的空閑指針,當數據發出寫入所述4R4W存儲器請求時,比較各個空閑緩存資源池的深度,
若存在一個具有最大深度的空閑緩存資源池,則直接將數據寫入到該最大深度的空閑緩存資源池對應的Bank中;
若存在2個以上具有相同的最大深度的空閑緩存資源池,則將該數據隨機寫入到其中一個具有最大深度的空閑緩存資源池對應的Bank中。
作為本發明一實施方式的進一步改進,所述方法還包括:
根據2R1W存儲器的深度和寬度選擇2m+1塊具有相同深度及寬度的SRAM2P存儲器構建2R1W存儲器的硬件框架,m為正整數;
每個SRAM2P存儲器均具有M個指針地址,其中,多個所述SRAM2P存儲器中的一個為輔助存儲器,其余均為主存儲器;
當數據寫入2R1W存儲器和/或從所述2R1W存儲器讀出時,根據數據的當前指針位置,關聯主存儲器以及輔助存儲器中的數據,對其做異或運算,完成數據的寫入和讀出。
為了實現上述發明目的之一,本發明一實施方式提供一種4R4W全共享報文的數據緩存處理系統,所述系統包括:數據構建模塊,數據處理模塊;
所述數據構建模塊具體用于:將2個2R1W存儲器并行拼裝為一個Bank存儲單元;
直接基于4個所述Bank存儲單元形成4R4W存儲器的硬件框架;
所述數據處理模塊具體用于:當確定一個時鐘周期下,數據通過4個寫端口寫入到4R4W存儲器時,
若數據的大小小于等于所述2R1W存儲器的位寬,則將數據分別寫入不同Bank中,同時,對寫入的數據進行復制,分別寫入至每個Bank的2個2R1W存儲器中;
若數據的大小大于所述2R1W存儲器的位寬,則等待第二個時鐘周期,當第二個時鐘周期到來時,將數據分別寫入不同Bank中,同時,將每個寫入數據的高低位分別寫入至每個Bank存儲單元的2個2R1W存儲器中。
作為本發明一實施方式的進一步改進,所述數據處理模塊還用于:
當確定一個時鐘周期下,數據從4R4W存儲器讀出時,
若數據的大小小于等于所述2R1W存儲器的位寬,則選擇4R4W的存儲器中匹配的讀端口直接讀出數據;
若數據的大小大于所述2R1W存儲器的位寬,則等待第二個時鐘周期,當第二個時鐘周期到來時,選擇4R4W存儲器中匹配的讀端口直接讀出數據。
作為本發明一實施方式的進一步改進,所述數據處理模塊還用于:
當確認數據寫入所述4R4W存儲器時,根據每個Bank的剩余空閑資源選擇數據的寫入位置。
作為本發明一實施方式的進一步改進,所述數據處理模塊還用于:
為每個Bank對應建立一空閑緩存資源池,所述空閑緩存資源池用于存儲當前對應Bank的剩余的空閑指針,當數據發出寫入所述4R4W存儲器請求時,比較各個空閑緩存資源池的深度,
若存在一個具有最大深度的空閑緩存資源池,則直接將數據寫入到該最大深度的空閑緩存資源池對應的Bank中;
若存在2個以上具有相同的最大深度的空閑緩存資源池,則將該數據隨機寫入到其中一個具有最大深度的空閑緩存資源池對應的Bank中。
作為本發明一實施方式的進一步改進,所述數據構建模塊還用于:根據2R1W存儲器的深度和寬度選擇2m+1塊具有相同深度及寬度的SRAM2P存儲器構建2R1W存儲器的硬件框架,m為正整數;
每個SRAM2P存儲器均具有M個指針地址,其中,多個所述SRAM2P存儲器中的一個為輔助存儲器,其余均為主存儲器;
當數據寫入2R1W存儲器和/或從所述2R1W存儲器讀出時,所述數據處理模塊還用于:根據數據的當前指針位置,關聯主存儲器以及輔助存儲器中的數據,對其做異或運算,完成數據的寫入和讀出。
與現有技術相比,本發明的4R4W全共享報文的數據緩存處理方法及處理系統,基于現有的SRAM類型,通過算法的方式搭建更多端口的SRAM,僅僅用最小的代價便可以最大限度的支持多端口SRAM;其實現過程中,避免采用復雜的控制邏輯和額外的多端口SRAM或者寄存器陣列資源,利用報文緩存的特殊性,通過空間分割和時間分割,僅需要簡單的異或運算就可實現4R4W的報文緩存,同時,本發明的4R4W存儲器,其所有的存儲資源對于4個Slice或者說對于任意一個輸入/輸出端口而言都是可見的,所有的存儲資源對于任意端口之間是完全共享的,本發明具有更低的功耗,更快的處理速度,以及節省更多的資源或面積,實現簡單,節約人力及物質成本。
附圖說明
圖1是現有技術中,基于1R1W存儲器采用算法設計實現的2R2W存儲器的報文緩存邏輯單元示意圖;
圖2是現有技術中,基于2R2W存儲器算法定制設計實現的4R4W存儲器的報文緩存邏輯單元示意圖;
圖3是現有技術中,基于2R2W存儲器采用另一種算法設計實現的4R4W存儲器的報文緩存架構示意圖;
圖4是圖3中其中一個XY的報文緩存邏輯單元示意圖;
圖5是本發明一實施方式中4R4W全共享報文的數據緩存處理方法的流程示意圖;
圖6是本發明第一實施方式中,通過定制設計形成的2R1W存儲器的數字電路結構示意圖;
圖7是本發明第二實施方式的,通過定制設計形成的2R1W存儲器讀寫分時操作示意圖;
圖8是本發明第三實施方式中,采用算法設計形成的2R1W存儲器的報文緩存邏輯單元示意圖;
圖9a是本發明第四實施方式中,采用算法設計形成的2R1W存儲器的報文緩存邏輯單元示意圖;
圖9b是對應圖9a存儲器塊編號映射表的結構示意圖;
圖10是本發明第五實施方式中,提供的2R1W存儲器的數據處理方法的流程示意圖;
圖11是本發明第五實施方式中,提供的2R1W存儲器的報文緩存邏輯單元示意圖;
圖12是本發明是一具體實施方式中,4個Bank的報文緩存架構示意圖;
圖13是本發明是一具體實施方式中,4R4W存儲器的報文緩存架構示意圖;
圖14是本發明一實施方式中提供的4R4W全共享報文的數據緩存處理系統的模塊示意圖。
具體實施方式
以下將結合附圖所示的各實施方式對本發明進行詳細描述。但這些實施方式并不限制本發明,本領域的普通技術人員根據這些實施方式所做出的結構、方法、或功能上的變換均包含在本發明的保護范圍內。
如圖5所示,本發明一實施方式提供的4R4W全共享報文的數據緩存處理方法,所述方法包括:
將2個2R1W存儲器并行拼裝為一個Bank存儲單元;
直接基于4個所述Bank存儲單元形成4R4W存儲器的硬件框架;
一個時鐘周期下,當數據通過4個寫端口寫入到4R4W存儲器時,
若數據的大小小于等于所述2R1W存儲器的位寬,則將數據分別寫入不同Bank中,同時,對寫入的數據進行復制,分別寫入至每個Bank的2個2R1W存儲器中;
若數據的大小大于所述2R1W存儲器的位寬,則等待第二個時鐘周期,當第二個時鐘周期到來時,將數據分別寫入不同Bank中,同時,將每個寫入數據的高低位分別寫入至每個Bank存儲單元的2個2R1W存儲器中。
一個時鐘周期下,當數據從4R4W存儲器讀出時,
若數據的大小小于等于所述2R1W存儲器的位寬,則選擇4R4W的存儲器中匹配的讀端口直接讀出數據;
若數據的大小大于所述2R1W存儲器的位寬,則等待第二個時鐘周期,當第二個時鐘周期到來時,選擇4R4W存儲器中匹配的讀端口直接讀出數據。
所述4R4W存儲器,即同時支持4讀4寫的存儲器。
本發明優選實施方式中,建立所述2R1W存儲器有五種方法。
如圖6所示,第一種實施方式中,在6T SRAM的基礎,把一根字線分割成左右兩個,這樣可以做成2個讀端口同時操作或者1個寫端口,這樣從左邊MOS管讀出的數據和右邊MOS管讀出的數據可以同時進行,需要注意的是,右邊MOS管讀出的數據需要反相之后才可以用,同時為了不影響數據讀取的速度,讀出的感應放大器需要用偽差分放大器。這樣,6T SRAM面積不變,唯一的代價是增加一倍的字線,從而保證總體的存儲密度基本不變。
如圖7所示,第二種實施方式中,通過定制設計形成的2R1W存儲器讀寫操作流程示意圖;
通過定制設計可以增加SRAM的端口,把一個字線切割成2個字線,將讀端口增加到2個;還可以通過分時操作的技術,即讀操作在時鐘的上升沿進行,而寫操作在時鐘的下降沿完成,這樣也可以把一個基本的1讀或者1寫的SRAM擴展成1讀和1寫的SRAM類型,即1個讀和1個寫操作可以同時進行,存儲密度基本不變。
如圖8所示,第三種實施方式中本發明一實施方式中采用算法設計形成的2R1W存儲器讀寫操作流程示意圖;
本實施方式中,以SRAM2P為基礎構建2R1W的SRAM為例,所述SRAM2P是一種能夠支持1讀和1讀/寫的SRAM類型,即可以對SRAM2P同時進行2個讀操作,或者1個讀和1個寫操作。
本實施方式中,通過復制一份SRAM以SRAM2P為基礎構建2R1W的SRAM;該示例中,右邊的SRAM2P_1是左邊SRAM2P_0的拷貝,具體操作的時候,把兩塊SRAM2P作為1讀和1寫存儲器來使用;其中,寫入數據時,同時往左右兩個SRAM2P寫入數據,讀出數據時,A固定從SRAM2P_0讀取,數據B固定從SRAM2P_1讀取,這樣就可以實現1個寫操作和2個讀操作并發進行。
如圖9a、9b所示,第四種實施方式中,為另一實施方式中采用算法設計形成的2R1W存儲器讀寫操作流程示意圖;
該實施方式中,把邏輯上一整塊的16384深度的SRAM分割成邏輯上4塊4096深度的SRAM2P,編號依次為為0、1、2、3,再額外增加一塊4096深度的SRAM,編號為4,作為解決讀寫沖突用,對于讀數據A和讀數據B,永遠保證這2個讀操作可以并發進行,當2個讀操作的地址是處于不同的SRAM2P中時,因為任何一個SRAM2P都可以配置成1R1W類型,所以讀寫不會有沖突;當2個讀操作的地址處于同一塊SRAM2P中時,例如:均處于SRAM2P_0中,由于同一個SRAM2P最多只能提供2個端口同時操作,此時,其端口被2個讀操作占用,如果恰好有一個寫操作要寫入SRAM2P_0,那么這時就把這個數據寫入存儲器第4塊SRAM2P_4中。
該種實施方式中,需要有一個存儲器塊映射表記錄哪一個存儲器塊存放有效數據,如圖9b所示,存儲器塊映射表的深度和一個存儲器塊的深度相同,即都是4096個深度,每一個條目中在初始化后依次存放每個存儲器塊的編號,從0到4,圖9a示例中,由于SRAM2P_0在寫入數據的時候發生讀寫沖突,數據實際上是寫入到SRAM2P_4中,此時,讀操作同時會讀取存儲器映射表中對應的內容,原始內容為{0, 1, 2, 3, 4},修改之后變成{4, 1, 2, 3, 0},第一個塊編號和第4個塊編號對調,表示數據實際寫入到SRAM2P_4中,同時SRAM2P_0變成了備份條目。
當讀取數據的時候,需要首先讀對應地址的存儲器塊編號映射表,查看有效數據存放在哪一個存儲器塊中,例如當要讀取地址5123的數據,那么首先讀取存儲塊編號映射表地址1027(5123-4096=1027)存放的內容,根據第二列的數字編號去讀取對應存儲塊的地址1027的內容。
對于寫數據操作,需要存儲器塊編號映射表提供1讀和1寫端口,對于2個讀數據操作,需要存儲器塊編號映射表提供2個讀端口,這樣總共需要存儲器塊編號映射表提供3個讀端口和1個寫端口,而且這4個訪問操作必須是同時進行。
如圖10所示,第五種實施方式,即本發明的優選實施方式中,2R1W存儲器的構建方法包括:
根據所述2R1W存儲器的深度和寬度選擇2m+1塊具有相同深度及寬度的SRAM2P存儲器構建2R1W存儲器的硬件框架,m為正整數;
多個所述SRAM2P存儲器按照排列順序依次為SRAM2P(0)、SRAM2P(1)……、SRAM2P(2m),每個SRAM2P存儲器均具有M個指針地址,其中,多個所述SRAM2P存儲器中的一個為輔助存儲器,其余均為主存儲器;
該發明的優選實施方式中,每塊SRAM2P存儲器的深度與寬度的乘積=(2R1W存儲器的深度與寬度乘積)/2m。
以下為了描述方便,對m取值為2、2R1W存儲器為16384深度、128寬度的SRAM存儲器進行詳細描述。
則在該具體示例中,多個所述SRAM2P存儲器按照排列順序依次為SRAM2P(0)、SRAM2P(1)、SRAM2P(2)、SRAM2P(3)、SRAM2P(4),其中,SRAM2P(0)、SRAM2P(1)、SRAM2P(2)、SRAM2P(3)為主存儲器,SRAM2P(4)為輔助存儲器,每個SRAM2P存儲器的深度和寬度分別為4096和128,相應的,每個SRAM2P存儲器均具有4096個指針地址;如果對每個SRAM2P存儲器的指針地址均獨立標識,則每個SRAM2P存儲器的指針地址均為0~4095,若將全部的主存儲器的地址依次排列,則全部的指針地址范圍為: 0 ~ 16383。該示例中,SRAM2P(4)用于解決端口沖突,且在該實施方式中,無需增加存儲器塊編號映射表即可以滿足需求。
進一步的,在上述硬件框架基礎上,所述方法還包括:
當數據寫入2R1W存儲器和/或從所述2R1W存儲器讀出時,根據數據的當前指針位置,關聯主存儲器以及輔助存儲器中的數據,對其做異或運算,完成數據的寫入和讀出。
本發明優選實施方式中,其數據寫入過程如下:
獲取當前數據的寫入地址為W(x,y),x表示寫入數據所處于的SRAM2P存儲器的排列位置,0≤x<2m,y表示寫入數據所處于的SRAM2P存儲器中的具體的指針地址,0≤y≤M;
獲取與寫入地址具有相同指針地址的其余主存儲器中的數據,將其同時與當前寫入數據做異或運算,并將異或運算結果寫入到輔助存儲器的相同指針地址中。
結合圖11所示,本發明一具體示例中,本發明一具體示例中,將數據128比特全“1”寫入到SRAM2P(0)中的指針地址“5”,即當前數據的寫入地址為W(0,5),在寫入數據過程中,除了直接將數據128比特全“1”寫入到指定位置SRAM2P(0)中的指針地址“5”外,同時,需要讀取其余主存儲器在相同指針地址的數據,假設從SRAM2P(1)中的指針地址“5”讀出的數據為128比特全“1”,從SRAM2P(2)中的指針地址“5”讀出的數據為128比特全“0”,從SRAM2P(3)中的指針地址“5”讀出的數據為128比特全“1”,則將數據128比特全“1”、128比特全“0”、 128比特全“1”、 128比特全“1”做異或運算,并將其異或運算的結果“1”同時寫入到SRAM2P(4)中的指針地址“5”。如此,以保證2R1W存儲器的2個讀端口和1個寫端口同時操作。
進一步的,本發明優選實施方式中,其數據讀出過程如下:
若當前兩個讀出數據的讀出地址處于相同的SRAM2P存儲器中,則
分別獲取兩個讀出數據的讀出地址為R1(x1,y1),R2(x2,y2),x1、y1均表示讀出數據所處于的SRAM2P存儲器的排列位置,0≤x1<2m,0≤x2<2m,y1、y2均表示讀出數據所處于的SRAM2P存儲器中的具體的指針地址,0≤y1≤M,0≤y2≤M;
任選其中一個讀出地址R1(x1,y1)中存儲的讀出數據,從當前的指定讀出地址中直接讀出當前存儲的數據;
獲取與另一個讀出地址具有相同指針地址的其余主存儲器、以及輔助存儲器中存儲的數據,并對其做異或運算,將異或運算結果作為另一個讀出地址的存儲數據進行輸出。
接續圖11所示,本發明一具體示例中,讀出的數據為2個,其指針地址分別為SRAM2P(0)中的指針地址“2”,以及SRAM2P(0)中的指針地址“5”,即當前數據的讀出地址為R(0,2)和R(0,5);
在從2R1W存儲器讀出數據過程中,由于每一個SRAM2P只能保證1個讀端口和1個寫端口同時操作,讀端口直接從SRAM2P(0)中的指針地址“2”中讀取數據,但是另一讀端口的請求無法滿足。相應的,本發明采用異或運算的方式解決兩個讀端口同時讀出數據的問題。
對于R(0,5)中的數據,分別讀取其他三個主存儲器以及輔助存儲器的指針地址“5”的數據并對其做異或運算,接續上例,從SRAM2P(1)中的指針地址“5”讀出的數據為“1”,從SRAM2P(2)中的指針地址“5”讀出的數據為“0”, 從SRAM2P(3)中的指針地址“5”讀出的數據為128比特全“1”,從SRAM2P(4)中的指針地址“5”讀出的數據為128比特全“1”,將數據128比特全“1”、128比特全“1”、 128比特全“0”、 128比特全“1”做異或運算,得到128比特“1”,并將其異或運算的結果128比特全“1”作為SRAM2P(0)中的指針地址“5”的存儲數據進行輸出,通過上述過程得到的數據,其結果與SRAM2P(0)中的指針地址“5”中存儲的數據完全一致,如此,根據數據的當前指針位置,關聯主存儲器以及輔助存儲器中的數據,對其做異或運算,完成數據的寫入和讀出。
本發明一實施方式中,若當前兩個讀出數據的讀出地址處于不同的SRAM2P存儲器中,則直接獲取不同SRAM2P存儲器中對應指針地址的數據分別獨立進行輸出。
接續圖11所示,本發明一具體示例中,讀出的數據為2個,其指針地址分別為SRAM2P(0)中的指針地址“5”,以及SRAM2P(1)中的指針地址“10”,即當前數據的讀出地址為R(0,5)和R(1,10);
在從2R1W存儲器讀出數據過程中,由于每一個SRAM2P均能保證1個讀端口和1個寫端口同時操作,故,讀出數據過程中,直接從SRAM2P(0)中的指針地址“5”讀取數據,以及直接從SRAM2P(1)中的指針地址“10”讀出數據,如此,以保證2R1W存儲器的2個讀端口和1個寫端口同時操作,在此不做詳細贅述。
需要說明的是,如果邏輯上把每一個SRAM2P進一步切分,比如切分成4m個具有相同深度的SRAM2P,那么只需要增加額外1/4m的存儲器面積就可以構建上述2R1W類型的SRAM;相應的,物理上SRAM的塊數也增加了近2倍,在實際的布局布線中會占用不少的面積開銷;當然,本發明并不以上述具體實施方式為限,其它采用異或運算以擴展存儲器端口的方案也包括在本發明的保護范圍內,在此不做詳細贅述。
結合圖12所示,對于本發明的4R4W存儲器以2個16384深度和1152寬度的2R1W類型的SRAM并行拼裝成一個Bank為例做具體介紹,一個Bank的容量大小是4.5M字節,總共有4個bank組成一個18M字節的4R4W存儲器。
該示例中,數據寫入4R4W存儲器過程中,需要同時支持4個slice的同時寫入,假設,每個slice的數據總線位寬是1152bits,同時每個slice支持6個100GE端口線速轉發;在數據通道上最差的情況,對于小于等于144字節長度的報文數據,需要核心時鐘頻率跑到892.9MHz,對于大于144字節長度的報文,需要核心時鐘頻率跑到909.1MHz。
一個時鐘周期下,若寫入數據的位寬小于等于144字節,同時,需要滿足4個Slice同時寫入,才能滿足帶寬需求;如此,采用空間分割性,通過4個Slice的寫入數據分別寫入到4個Bank中,同時,將寫于一個Bank中的數據進行復制,并分別寫入到一個Bank的左右2個2R1W存儲器中,如此,以滿足數據的讀出請求,以下將會詳細描述。
一個時鐘周期下,若寫入數據的位寬大于144字節,同時,需要滿足4個Slice同時寫入,才能滿足帶寬需求;即:通過每個Slice的數據均需要占用整個Bank;如此,對于每個Slice而言,只需要在2個時鐘周期下,采用乒乓操作即可以滿足需求,例如:一個時鐘周期下,將其中的兩個數據分別寫入到2個Bank中,第二個周期到來時,將另外兩個數據分別寫入到2個Bank中;其中,每個Bank中的兩個2R1W存儲器,分別對應存儲任一個大于144字節的數據的高位和底位,在此不做詳細贅述。如此,寫入數據不會發生沖突。
其讀取過程與寫入過程相類似;一個時鐘周期下,若讀出數據的位寬小于等于144字節,最壞情況下,讀出數據存儲于同一個Bank中,由于本發明的每個Bank均由2個2R1W存儲器拼接形成,而每個2R1W存儲器均可以同時支持兩個讀出請求,同時,數據寫入時,對數據進行拷貝分別存儲至同一個Bank的左右2R1W存儲器中,故,在該種情況下,也可以滿足數據的讀出請求。
一個時鐘周期下,若讀出數據的位寬大于144字節,最壞情況下,讀出數據存儲于同一個Bank中,與寫入過程相類似,僅需要在兩個時鐘周期下,采用乒乓操作,即一個時鐘周期下,從一個Bank的2個2R1W存儲器讀出兩個數據,在第二個時鐘周期下,從該相同Bank的2個2R1W存儲器中讀出剩余的兩個數據,如此,同樣可以滿足讀出請求,在此不做詳細贅述。
本發明一優選實施方式中,所述方法還包括:當數據寫入所述4R4W存儲器時,根據每個Bank的剩余空閑資源選擇數據的寫入位置。具體的,為每個Bank對應建立一空閑緩存資源池,所述空閑緩存資源池用于存儲當前對應Bank的剩余的空閑指針,當數據發出寫入所述4R4W存儲器請求時,比較各個空閑緩存資源池的深度,
若存在一個具有最大深度的空閑緩存資源池,則直接將數據寫入到該最大深度的空閑緩存資源池對應的Bank中;
若存在2個以上具有相同的最大深度的空閑緩存資源池,則將該數據隨機寫入到其中一個具有最大深度的空閑緩存資源池對應的Bank中。
當然,在本發明的其他實施方式中,也可以設定一定的規則,當具有2個以上具有相同的最大深度的空閑緩存資源池時,按照各個Bank的排列順序,按序寫入到對應的Bank中,在此不做詳細贅述。
結合圖13所示,本發明一具體示例中, X0Y0的具體結構與圖12所示相同,
其中,S0、S1、S2、S3代表4個slice,每個slice舉例來說包含有6個100GE端口,從slice0、slice1、slice2以及slice3輸入分別去往slice0、slice1、slice2以及slice3的報文均存入X0Y0,進一步的,讀取報文的時候,slice0、slice1、slice2以及slice3均直接從X0Y0中直接讀取相應的數據。如此,不同目的slice的端口之間實現緩存共享。而報文寫入及讀出的具體過程可參照圖12的具體說明。
本發明的4R4W存儲器,在14nm集成電路工藝下,其邏輯上總共個需要40個4096深度1152寬度的SRAM2P,總共占用面積22.115平方厘米,總的功耗為13.503Watts(核心電壓=0.9V,結溫=125攝氏度,工藝條件是最快),同時,不需要復雜的控制邏輯,只需要簡單的異或運算就可實現多個讀端口的操作;另外,也不需要額外的存儲器塊映射表和控制邏輯。更進一步的,所有的存儲資源對于4個Slice或者說對于任意一個輸入/輸出端口而言都是可見的,所有的存儲資源對于任意端口之間是完全共享的。
結合圖14所示,本發明一實施方式提供的4R4W全共享報文的數據緩存處理系統,
所述系統包括:數據構建模塊100,數據處理模塊200;
所述數據構建模塊100具體用于:將2個2R1W存儲器并行拼裝為一個Bank存儲單元;
直接基于4個所述Bank存儲單元形成4R4W存儲器的硬件框架;
所述數據處理模塊200具體用于:當確定一個時鐘周期下,數據通過4個寫端口寫入到4R4W存儲器時,
若數據的大小小于等于所述2R1W存儲器的位寬,則將數據分別寫入不同Bank中,同時,對寫入的數據進行復制,分別寫入至每個Bank的2個2R1W存儲器中;
若數據的大小大于所述2R1W存儲器的位寬,則等待第二個時鐘周期,當第二個時鐘周期到來時,將數據分別寫入不同Bank中,同時,將每個寫入數據的高低位分別寫入至每個Bank存儲單元的2個2R1W存儲器中。
所述數據處理模塊200還用于:當確定一個時鐘周期下,當數據從4R4W存儲器讀出時,
若數據的大小小于等于所述2R1W存儲器的位寬,則選擇4R4W的存儲器中匹配的讀端口直接讀出數據;
若數據的大小大于所述2R1W存儲器的位寬,則等待第二個時鐘周期,當第二個時鐘周期到來時,選擇4R4W存儲器中匹配的讀端口直接讀出數據。
本發明優選實施方式中,數據構建模塊100采用5種方式建立所述2R1W存儲器。
如圖6所示,第一種實施方式中,在6T SRAM的基礎,數據構建模塊100把一根字線分割成左右兩個,這樣可以做成2個讀端口同時操作或者1個寫端口,這樣從左邊MOS管讀出的數據和右邊MOS管讀出的數據可以同時進行,需要注意的是,右邊MOS管讀出的數據需要反相之后才可以用,同時為了不影響數據讀取的速度,讀出的感應放大器需要用偽差分放大器。這樣,6T SRAM面積不變,唯一的代價是增加一倍的字線,從而保證總體的存儲密度基本不變。
如圖7所示,第二種實施方式中,數據構建模塊100通過定制設計可以增加SRAM的端口,把一個字線切割成2個字線,將讀端口增加到2個;還可以通過分時操作的技術,即讀操作在時鐘的上升沿進行,而寫操作在時鐘的下降沿完成,這樣也可以把一個基本的1讀或者1寫的SRAM擴展成1讀和1寫的SRAM類型,即1個讀和1個寫操作可以同時進行,存儲密度基本不變。
如圖8所示,第三種實施方式中,以SRAM2P為基礎構建2R1W的SRAM為例,所述SRAM2P是一種能夠支持1讀和1讀/寫的SRAM類型,即可以對SRAM2P同時進行2個讀操作,或者1個讀和1個寫操作。
本實施方式中,數據構建模塊100通過復制一份SRAM以SRAM2P為基礎構建2R1W的SRAM;該示例中,右邊的SRAM2P_1是左邊SRAM2P_0的拷貝,具體操作的時候,把兩塊SRAM2P作為1讀和1寫存儲器來使用;其中,寫入數據時,同時往左右兩個SRAM2P寫入數據,讀出數據時,A固定從SRAM2P_0讀取,數據B固定從SRAM2P_1讀取,這樣就可以實現1個寫操作和2個讀操作并發進行。
如圖9a、9b所示,第四種實施方式中,數據構建模塊100把邏輯上一整塊的16384深度的SRAM分割成邏輯上4塊4096深度的SRAM2P,編號依次為為0、1、2、3,再額外增加一塊4096深度的SRAM,編號為4,作為解決讀寫沖突用,對于讀數據A和讀數據B,永遠保證這2個讀操作可以并發進行,當2個讀操作的地址是處于不同的SRAM2P中時,因為任何一個SRAM2P都可以配置成1R1W類型,所以讀寫不會有沖突;當2個讀操作的地址處于同一塊SRAM2P中時,例如:均處于SRAM2P_0中,由于同一個SRAM2P最多只能提供2個端口同時操作,此時,其端口被2個讀操作占用,如果恰好有一個寫操作要寫入SRAM2P_0,那么這時就把這個數據寫入存儲器第4塊SRAM2P_4中。
該種實施方式中,需要有一個存儲器塊映射表記錄哪一個存儲器塊存放有效數據,如圖9b所示,存儲器塊映射表的深度和一個存儲器塊的深度相同,即都是4096個深度,每一個條目中在初始化后依次存放每個存儲器塊的編號,從0到4,圖9a示例中,由于SRAM2P_0在寫入數據的時候發生讀寫沖突,數據實際上是寫入到SRAM2P_4中,此時,讀操作同時會讀取存儲器映射表中對應的內容,原始內容為{0, 1, 2, 3, 4},修改之后變成{4, 1, 2, 3, 0},第一個塊編號和第4個塊編號對調,表示數據實際寫入到SRAM2P_4中,同時SRAM2P_0變成了備份條目。
當讀取數據的時候,需要首先讀對應地址的存儲器塊編號映射表,查看有效數據存放在哪一個存儲器塊中,例如當要讀取地址5123的數據,那么首先讀取存儲塊編號映射表地址1027(5123-4096=1027)存放的內容,根據第二列的數字編號去讀取對應存儲塊的地址1027的內容。
對于寫數據操作,需要存儲器塊編號映射表提供1讀和1寫端口,對于2個讀數據操作,需要存儲器塊編號映射表提供2個讀端口,這樣總共需要存儲器塊編號映射表提供3個讀端口和1個寫端口,而且這4個訪問操作必須是同時進行。
如圖10所示,第五種實施方式,即本發明的優選實施方式中,數據構建模塊100根據所述2R1W存儲器的深度和寬度選擇2m+1塊具有相同深度及寬度的SRAM2P存儲器構建2R1W存儲器的硬件框架,m為正整數;
多個所述SRAM2P存儲器按照排列順序依次為SRAM2P(0)、SRAM2P(1)……、SRAM2P(2m),每個SRAM2P存儲器均具有M個指針地址,其中,多個所述SRAM2P存儲器中的一個為輔助存儲器,其余均為主存儲器;
每塊SRAM2P存儲器的深度與寬度的乘積=(2R1W存儲器的深度與寬度乘積)/2m。
以下為了描述方便,對m取值為2、2R1W存儲器為16384深度、128寬度的SRAM存儲器進行詳細描述。
則在該具體示例中,多個所述SRAM2P存儲器按照排列順序依次為SRAM2P(0)、SRAM2P(1)、SRAM2P(2)、SRAM2P(3)、SRAM2P(4),其中,SRAM2P(0)、SRAM2P(1)、SRAM2P(2)、SRAM2P(3)為主存儲器,SRAM2P(4)為輔助存儲器,每個SRAM2P存儲器的深度和寬度分別為4096和128,相應的,每個SRAM2P存儲器均具有4096個指針地址;如果對每個SRAM2P存儲器的指針地址均獨立標識,則每個SRAM2P存儲器的指針地址均為0~4095,若將全部的主存儲器的地址依次排列,則全部的指針地址范圍為: 0 ~ 16383。該示例中,SRAM2P(4)用于解決端口沖突,且在該實施方式中,無需增加存儲器塊編號映射表即可以滿足需求。
進一步的,在上述硬件框架基礎上,當數據寫入2R1W存儲器和/或從所述2R1W存儲器讀出時,數據處理模塊200具體用于:根據數據的當前指針位置,關聯主存儲器以及輔助存儲器中的數據,對其做異或運算,完成數據的寫入和讀出。
本發明優選實施方式中,其數據寫入過程如下:
獲取當前數據的寫入地址為W(x,y),x表示寫入數據所處于的SRAM2P存儲器的排列位置,0≤x<2m,y表示寫入數據所處于的SRAM2P存儲器中的具體的指針地址,0≤y≤M;
獲取與寫入地址具有相同指針地址的其余主存儲器中的數據,將其同時與當前寫入數據做異或運算,并將異或運算結果寫入到輔助存儲器的相同指針地址中。
進一步的,本發明優選實施方式中,數據處理模塊200讀出數據過程如下:
若當前兩個讀出數據的讀出地址處于相同的SRAM2P存儲器中,則
數據處理模塊200具體用于:分別獲取兩個讀出數據的讀出地址為R1(x1,y1),R2(x2,y2),x1、y1均表示讀出數據所處于的SRAM2P存儲器的排列位置,0≤x1<2m,0≤x2<2m,y1、y2均表示讀出數據所處于的SRAM2P存儲器中的具體的指針地址,0≤y1≤M,0≤y2≤M;
數據處理模塊200具體用于:任選其中一個讀出地址R1(x1,y1)中存儲的讀出數據,從當前的指定讀出地址中直接讀出當前存儲的數據;
數據處理模塊200具體用于:獲取與另一個讀出地址具有相同指針地址的其余主存儲器、以及輔助存儲器中存儲的數據,并對其做異或運算,將異或運算結果作為另一個讀出地址的存儲數據進行輸出。
本發明一實施方式中,若當前兩個讀出數據的讀出地址處于不同的SRAM2P存儲器中,數據處理模塊200則直接獲取不同SRAM2P存儲器中對應指針地址的數據分別獨立進行輸出。
需要說明的是,如果邏輯上把每一個SRAM2P進一步切分,比如切分成4m個具有相同深度的SRAM2P,那么只需要增加額外1/4m的存儲器面積就可以構建上述2R1W類型的SRAM;相應的,物理上SRAM的塊數也增加了近2倍,在實際的布局布線中會占用不少的面積開銷;當然,本發明并不以上述具體實施方式為限,其它采用異或運算以擴展存儲器端口的方案也包括在本發明的保護范圍內,在此不做詳細贅述。
本發明一優選實施方式中,所述數據處理模塊200還用于:當數據寫入所述4R4W存儲器時,根據每個Bank的剩余空閑資源選擇數據的寫入位置。具體的,所述數據處理模塊200還用于:為每個Bank對應建立一空閑緩存資源池,所述空閑緩存資源池用于存儲當前對應Bank的剩余的空閑指針,當數據發出寫入所述4R4W存儲器請求時,比較各個空閑緩存資源池的深度,
若存在一個具有最大深度的空閑緩存資源池,則直接將數據寫入到該最大深度的空閑緩存資源池對應的Bank中;
若存在2個以上具有相同的最大深度的空閑緩存資源池,則將該數據隨機寫入到其中一個具有最大深度的空閑緩存資源池對應的Bank中。
當然,在本發明的其他實施方式中,也可以設定一定的規則,當具有2個以上具有相同的最大深度的空閑緩存資源池時,按照各個Bank的排列順序,按序寫入到對應的Bank中,在此不做詳細贅述。
結合圖13所示,該具體示例中,X0Y0以及X1Y1的具體結構均與圖12所示相同,數據寫入及讀出過程中,需根據其對應的轉發端口進行存儲,例如:S0、S1的數據僅能寫入到X0Y0中,而S2、S3的數據僅能寫入到X1Y1中,其寫入過程不在具體贅述。
本發明的4R4W存儲器,在14nm集成電路工藝下,其邏輯上總共個需要40個4096深度1152寬度的SRAM2P,總共占用面積22.115平方厘米,總的功耗為13.503Watts(核心電壓=0.9V,結溫=125攝氏度,工藝條件是最快),同時,不需要復雜的控制邏輯,只需要簡單的異或運算就可實現多個讀端口的操作;另外,也不需要額外的存儲器塊映射表和控制邏輯。更進一步的,所有的存儲資源對于4個Slice或者說對于任意一個輸入/輸出端口而言都是可見的,所有的存儲資源對于任意端口之間是完全共享的。
綜上所述,本發明的4R4W全共享報文的數據緩存處理方法及處理系統,基于現有的SRAM類型,通過算法的方式搭建更多端口的SRAM,僅僅用最小的代價便可以最大限度的支持多端口SRAM;其實現過程中,避免采用復雜的控制邏輯和額外的多端口SRAM或者寄存器陣列資源,利用報文緩存的特殊性,通過空間分割和時間分割,僅需要簡單的異或運算就可實現4R4W的報文緩存,同時,本發明的4R4W存儲器,其所有的存儲資源對于4個Slice或者說對于任意一個輸入/輸出端口而言都是可見的,所有的存儲資源對于任意端口之間是完全共享的,本發明具有更低的功耗,更快的處理速度,以及節省更多的資源或面積,實現簡單,節約人力及物質成本。
為了描述的方便,描述以上裝置時以功能分為各種模塊分別描述。當然,在實施本發明時可以把各模塊的功能在同一個或多個軟件和/或硬件中實現。
以上所描述的裝置實施方式僅僅是示意性的,其中所述作為分離部件說明的模塊可以是或者也可以不是物理上分開的,作為模塊顯示的部件可以是或者也可以不是物理模塊,即可以位于一個地方,或者也可以分布到多個網絡模塊上。可以根據實際的需要選擇其中的部分或者全部模塊來實現本實施方式方案的目的。本領域普通技術人員在不付出創造性勞動的情況下,即可以理解并實施。
應當理解,雖然本說明書按照實施方式加以描述,但并非每個實施方式僅包含一個獨立的技術方案,說明書的這種敘述方式僅僅是為清楚起見,本領域技術人員應當將說明書作為一個整體,各實施方式中的技術方案也可以經適當組合,形成本領域技術人員可以理解的其他實施方式。
上文所列出的一系列的詳細說明僅僅是針對本發明的可行性實施方式的具體說明,它們并非用以限制本發明的保護范圍,凡未脫離本發明技藝精神所作的等效實施方式或變更均應包含在本發明的保護范圍之內。
- 還沒有人留言評論。精彩留言會獲得點贊!