用于視頻譯碼中的高級殘余預測的濾波器的制作方法
技術領域
本發明涉及視頻編碼和視頻解碼。
背景技術:
數字視頻能力可以并入到多種多樣的裝置中,包含數字電視、數字直播系統、無線廣播系統、個人數字助理(PDA)、膝上型或桌上型計算機、平板計算機、電子圖書閱讀器、數碼相機、數字記錄裝置、數字媒體播放器、視頻游戲裝置、視頻游戲控制臺、蜂窩式或衛星無線電電話(所謂的“智能電話”)、視頻電話會議裝置、視頻串流裝置及其類似者。數字視頻裝置實施視頻壓縮技術,例如由MPEG-2、MPEG-4、ITU-T H.263、ITU-T H.264/MPEG-4第10部分高級視頻譯碼(AVC)、ITU-T H.265所定義的標準、目前正在開發的高效率視頻譯碼(HEVC)標準及這些標準的擴展中所描述的視頻壓縮技術。視頻裝置可以通過實施此類視頻壓縮技術來更有效率地發射、接收、編碼、解碼和/或存儲數字視頻信息。
視頻壓縮技術執行空間(圖片內)預測及/或時間(圖片間)預測來減少或去除視頻序列中固有的冗余。對于基于塊的視頻譯碼,可將視頻切片(即,視頻幀或視頻幀的一部分)分割成視頻塊。使用關于同一圖片中的相鄰塊中的參考樣本的空間預測對圖片的經幀內譯碼(I)切片中的視頻塊進行編碼。圖片的經幀間編碼(P或B)切片中的視頻塊可使用相對于同一圖片中的相鄰塊中的參考樣本的空間預測或相對于其它參考圖片中的參考樣本的時間預測。圖片可被稱為幀,且參考圖片可被稱為參考幀。
空間或時間預測產生待譯碼塊的預測性塊。殘余數據表示待譯碼原始塊與預測性塊的間的像素差。經幀間譯碼塊是根據指向形成預測性塊的參考樣本塊的運動向量及指示經譯碼塊與預測性塊之間的差的殘余數據編碼的。根據幀內譯碼模式和殘余數據來編碼經幀內譯碼塊。為了進一步壓縮,可將殘余數據從像素域變換至變換域,從而產生殘余系數,可接著量化所述殘余系數。可掃描最初布置為二維陣列的經量化的系數,以便產生系數的一維向量,且可應用熵譯碼以實現更多壓縮。
可例如從多個視角編碼視圖來產生多視圖譯碼位流。已經開發利用多視圖譯碼方面的一些三維(3D)視頻標準。舉例來說,不同視圖可發射左眼和右眼視圖以支持3D視頻。或者,一些3D視頻譯碼過程可應用所謂的多視圖加深度譯碼。在多視圖加深度譯碼中,3D視頻位流可不僅含有紋理視圖分量而且含有深度視圖分量。舉例來說,每一視圖可包括一個紋理視圖分量和一個深度視圖分量。
技術實現要素:
一般來說,本發明描述基于高級編解碼器的多視圖和3維(3D)視頻譯碼的技術,包含以3D-HEVC編解碼器對兩個或更多個視圖的譯碼。更具體來說,本發明描述與非基礎視圖中的高級殘余預測(ARP)相關的實例技術。
在一個實例方面中,本發明描述一種對視頻數據進行解碼的方法,所述方法包括:基于所述視頻數據的當前圖片中的當前塊的運動向量確定第一參考圖片中的第一參考塊的位置;將可分離的雙線性內插濾波器應用于所述第一參考圖片的樣本以確定所述第一參考塊的樣本;確定第二參考圖片中的第二參考塊的位置;將所述可分離的雙線性內插濾波器應用于所述第二參考圖片的樣本以確定所述第二參考塊的樣本;將所述可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本,其中所述第一、第二和第三參考圖片中的每一者是不同圖片;確定預測性塊,其中所述預測性塊的每一相應樣本等于所述第一參考塊的相應樣本加相應殘余預測符樣本,所述相應殘余預測符樣本等于加權因數乘以所述第二參考塊的相應樣本與所述第三參考塊的相應樣本之間的差,其中所述第一參考塊的所述相應樣本、所述第二參考塊的所述相應樣本以及所述第三參考塊的所述相應樣本在所述第一、第二和第三參考塊內對應于所述預測性塊的所述相應樣本的位置的位置處;從位流獲得表示殘余塊的數據;以及至少部分地基于所述殘余塊和所述預測性塊而重構所述當前圖片的譯碼塊。
在另一實例方面中,本發明描述一種對視頻數據進行編碼的方法,所述方法包括:基于所述視頻數據的當前圖片中的當前塊的運動向量確定第一參考圖片中的第一參考塊的位置;將可分離的雙線性內插濾波器應用于所述第一參考圖片的樣本以確定所述第一參考塊的樣本;確定第二參考圖片中的第二參考塊的位置;將所述可分離的雙線性內插濾波器應用于所述第二參考圖片的樣本以確定所述第二參考塊的樣本;將所述可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本,其中所述第一、第二和第三參考圖片中的每一者是不同圖片;確定預測性塊,其中所述預測性塊的每一相應樣本等于所述第一參考塊的相應樣本減相應殘余預測符樣本,所述相應殘余預測符樣本等于加權因數乘以所述第二參考塊的相應樣本與所述第三參考塊的相應樣本之間的差,其中所述第一參考塊的所述相應樣本、所述第二參考塊的所述相應樣本以及所述第三參考塊的所述相應樣本在所述第一、第二和第三參考塊內對應于所述預測性塊的所述相應樣本的位置的位置處;至少部分地基于所述預測性塊確定殘余塊;以及在位流中包含表示所述殘余塊的數據。
在另一實例方面中,本發明描述一種視頻譯碼裝置,其包括:存儲器,其經配置以存儲視頻數據;以及一或多個處理器,其經配置以:基于所述視頻數據的當前圖片中的當前塊的運動向量確定第一參考圖片中的第一參考塊的位置;將可分離的雙線性內插濾波器應用于所述第一參考圖片的樣本以確定所述第一參考塊的樣本;確定第二參考圖片中的第二參考塊的位置;將所述可分離的雙線性內插濾波器應用于所述第二參考圖片的樣本以確定所述第二參考塊的樣本;將所述可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本,其中所述第一、第二和第三參考圖片中的每一者是不同圖片;以及確定預測性塊,其中所述預測性塊的每一相應樣本等于所述第一參考塊的相應樣本減相應殘余預測符樣本,所述相應殘余預測符樣本等于加權因數乘以所述第二參考塊的相應樣本與所述第三參考塊的相應樣本之間的差,其中所述第一參考塊的所述相應樣本、所述第二參考塊的所述相應樣本以及所述第三參考塊的所述相應樣本在所述第一、第二和第三參考塊內對應于所述預測性塊的所述相應樣本的位置的位置處。
在另一實例方面中,本發明描述一種視頻譯碼裝置,其包括:用于基于所述視頻數據的當前圖片中的當前塊的運動向量確定第一參考圖片中的第一參考塊的位置的裝置;用于將可分離的雙線性內插濾波器應用于所述第一參考圖片的樣本以確定所述第一參考塊的樣本的裝置;確定第二參考圖片中的第二參考塊的位置;用于將所述可分離的雙線性內插濾波器應用于所述第二參考圖片的樣本以確定所述第二參考塊的樣本的裝置;用于將所述可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本的裝置,其中所述第一、第二和第三參考圖片中的每一者是不同圖片;以及用于確定預測性塊的裝置,其中所述預測性塊的每一相應樣本等于所述第一參考塊的相應樣本減相應殘余預測符樣本,所述相應殘余預測符樣本等于加權因數乘以所述第二參考塊的相應樣本與所述第三參考塊的相應樣本之間的差,其中所述第一參考塊的所述相應樣本、所述第二參考塊的所述相應樣本以及所述第三參考塊的所述相應樣本在所述第一、第二和第三參考塊內對應于所述預測性塊的所述相應樣本的位置的位置處。
在另一實例方面中,本發明描述一種其上存儲有指令的計算機可讀存儲媒體,所述指令在被執行時致使用于對視頻數據進行譯碼的裝置:基于所述視頻數據的當前圖片中的當前塊的運動向量確定第一參考圖片中的第一參考塊的位置;將可分離的雙線性內插濾波器應用于所述第一參考圖片的樣本以確定所述第一參考塊的樣本;確定第二參考圖片中的第二參考塊的位置;將所述可分離的雙線性內插濾波器應用于所述第二參考圖片的樣本以確定所述第二參考塊的樣本;將所述可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本,其中所述第一、第二和第三參考圖片中的每一者是不同圖片;以及確定預測性塊,其中所述預測性塊的每一相應樣本等于所述第一參考塊的相應樣本加相應殘余預測符樣本,所述相應殘余預測符樣本等于加權因數乘以所述第二參考塊的相應樣本與所述第三參考塊的相應樣本之間的差,其中所述第一參考塊的所述相應樣本、所述第二參考塊的所述相應樣本以及所述第三參考塊的所述相應樣本在所述第一、第二和第三參考塊內對應于所述預測性塊的所述相應樣本的位置的位置處。
在附圖和下文描述中陳述本發明的一或多個實例的細節。其它特征、目標和優點將從所述描述、圖式以及權利要求書而顯而易見。
附圖說明
圖1是說明可利用本發明中描述的技術的實例視頻譯碼系統的框圖。
圖2是說明用于多視圖譯碼的實例預測結構的概念圖。
圖3是說明相對于一個譯碼單元(CU)的實例空間運動向量相鄰者的概念圖。
圖4說明用于多視圖視頻譯碼中的時間殘余的高級殘余預測(ARP)的實例預測結構。
圖5是說明當前塊和參考塊之間的實例關系的概念圖。
圖6是說明用于視圖間殘余的ARP的概念圖。
圖7是說明用于照明補償參數的導出的實例相鄰樣本的概念圖。
圖8是說明可實施本發明的技術的實例視頻編碼器的框圖。
圖9是說明可實施本發明的技術的實例視頻解碼器的框圖。
圖10是說明雙線性內插中的分數樣本位置相依變量以及周圍的整數位置樣本的概念圖。
圖11是說明用于八分之一樣本內插的實例整數樣本和分數樣本位置的概念圖。
圖12是說明根據本發明的技術的視頻編碼器的實例操作的流程圖。
圖13是說明根據本發明的技術的視頻解碼器的實例操作的流程圖。
具體實施方式
高級殘余預測(ARP)是在多視圖/3D視頻譯碼中使用的視頻數據壓縮技術。使用ARP的視頻編碼器產生當前塊的殘余預測符。在一些實例中,當前塊是預測單元(PU)的預測塊。此外,在一些實例中,視頻編碼器將加權因數應用于殘余預測符。另外,視頻編碼器使用幀間預測以產生當前塊的初始預測性塊。視頻編碼器接著可產生當前塊的最終預測性塊(即,最終預測符)。
概念上,最終預測性塊中的每一相應樣本等于當前塊的殘余預測符中的相應對應樣本以及當前塊的初始預測性塊中的相應對應樣本的總和。此外,視頻編碼器產生當前塊的殘余塊。概念上,當前塊的殘余塊中的每一相應樣本指示當前塊的最終預測性塊中的相應對應樣本與當前塊自身中的相應對應樣本之間的差。
樣本是像素的顏色分量(例如,明度、色度等)的值。在本發明中,第一塊中的樣本可稱為對應于第二塊中的樣本,前提是所述兩個樣本在第一和第二塊內相對于第一和第二塊的左上方樣本具有相同的位置。視頻編碼器在包括經編碼視頻數據的位流中包含表示當前塊的殘余塊的數據。
類似地,當使用ARP對當前塊進行解碼時,視頻解碼器產生當前塊的殘余預測符,在需要的情況下反轉加權因數的應用。另外,視頻解碼器使用幀間預測以確定當前塊的初始預測性塊。視頻譯碼器隨后確定當前塊的最終預測性塊(即,最終預測符)。概念上,最終預測性塊的每一樣本等于殘余預測符的對應樣本以及初始預測性塊的對應樣本的總和。
視頻解碼器基于位流中的數據確定當前塊的殘余塊。視頻解碼器基于當前塊的殘余塊和當前塊的最終預測性塊而重構當前塊。概念上,經重構當前塊的每一相應樣本等于當前塊的殘余塊的相應對應樣本以及當前塊的最終預測性塊的相應對應樣本的總和。
如上文所指出,視頻譯碼器(即,視頻編碼器或視頻解碼器)產生當前圖片的當前塊的殘余預測符。為了產生殘余預測符,視頻譯碼器基于當前塊的運動向量確定第一參考圖片中的第一參考塊的位置。在一些情況下,所述運動向量是時間運動向量。在其它情況下,所述運動向量是視差運動向量。
參考圖片是可用于視頻譯碼器在對當前圖片進行譯碼中使用的經先前譯碼圖片。參考塊是在參考圖片中或從參考圖片中的樣本內插的樣本的塊。除確定第一參考塊的位置之外,視頻譯碼器還確定第二參考圖片中的第二參考塊的位置和第三參考圖片中的第三參考塊的位置。
在一些實例中,第一參考塊、第二參考塊和第三參考塊具有與當前塊相同的大小。此外,在一些實例中,殘余預測符可為具有與當前塊相同大小的塊。視頻譯碼器可基于第二和第三參考塊產生殘余預測符。舉例來說,殘余預測符的每一相應殘余樣本可等于加權因數乘以第二參考塊中的相應對應樣本與第三參考塊中的相應對應樣本之間的差。
在一些實例中,當前塊是經雙向幀間預測。因此,在此些實例中,當前塊具有兩個相異運動向量:指示第一參考圖片列表(L0)中的參考圖片的運動向量以及指示第二參考圖片列表(L1)中的參考圖片的運動向量。當視頻譯碼器使用ARP對經雙向幀間預測當前塊進行譯碼時,視頻譯碼器使用當前塊的L0運動向量以基于L0中的時間參考圖片(即,L0參考圖片)的樣本而確定第一L0參考塊。另外,視頻譯碼器可確定L0殘余預測符。
以在單向情況中視頻譯碼器將使用運動向量確定殘余預測符相同的方式,視頻譯碼器可使用當前塊的L0運動向量確定L0殘余預測符。視頻譯碼器接著可確定初始L0預測性塊。初始L0預測性塊中的每一相應樣本可指示第一L0參考塊的相應樣本以及加權因數乘以L0殘余預測符中的對應樣本的總和。視頻譯碼器可以L1運動向量重復此過程以確定初始L1預測性塊。
接著,視頻譯碼器可確定當前塊的最終預測性塊。概念上,最終預測性塊的每一相應樣本是初始L0和L1預測性塊中的相應對應樣本的加權平均。在所述加權平均中,指派給初始L0和L1預測性塊的樣本的權重可基于L0參考圖片、L1參考圖片和當前圖片的POC值。因此,無論當前塊是經單向還是雙向幀間預測(即,單向預測或雙向預測),視頻譯碼器都可產生當前塊的最終預測性塊。本發明可簡單地將最終預測性塊稱為預測性塊和殘余預測符。
在一些情況下,當前塊的運動向量具有子整數精度。換句話說,運動向量可指示參考圖片的兩個實際樣本(即,在整數位置的樣本)之間的位置。在參考圖片的整數位置的樣本在本文中可被稱作“整數樣本”。當運動向量指示參考圖片的兩個實際樣本之間的位置時,視頻編碼器基于參考圖片的整數樣本而內插參考塊的樣本。因此,視頻譯碼器可內插參考塊中的樣本作為在ARP中產生殘余預測符的部分。
在以上描述中,將各種塊的樣本描述為“概念上”具有等于其它塊中的對應樣本的總和或差的值。實際上,視頻譯碼器可削減樣本以確保樣本保持在適用范圍中。舉例來說,視頻譯碼器可支持具有8位的位深度的樣本。因此,在此實例中,樣本可具有從-128到127的范圍。另外,在此實例中,兩個樣本的相加可導致大于127的值,且一個樣本從另一樣本減去可導致小于最小值(例如,-128)的值。因此,視頻譯碼器可削減大于127的值為127且可削減小于-128的值為128。此外,內插過程可導致樣本在適用范圍之外。因此,在一些情況下,視頻譯碼器可削減經內插樣本。
3D-HEVC是用于對多視圖/三維(3D)視頻數據進行編碼的新興標準。3D-HEVC的一些視頻譯碼器實施方案至少針對單向預測情況削減所有中間數據,因為視頻譯碼器實施方案再使用HEVC內插功能。此些中間數據可包含當前塊的預測性塊和當前塊的參考塊的樣本。因為視頻譯碼器削減中間數據,所以視頻譯碼器針對單向預測ARP每樣本執行三次削減操作,因為視頻譯碼器以內插過程產生三個預測塊(即,當前塊的預測性塊和參考塊)。
此外,3D-HEVC的一些視頻譯碼器實施方案當使用ARP確定第一參考塊和第二參考塊的樣本時使用不可分離的濾波器。當視頻譯碼器應用不可分離的濾波器以確定在子整數位置的樣本的值時,視頻譯碼器使用削減操作以確定在全整數位置的周圍樣本的x和y坐標。
每一削減操作可涉及兩個比較操作:一個用于比較值與上限且另一個用于比較值與下限。因此,執行削減操作增加了計算復雜性,其可減慢譯碼過程且可導致較大的電力消耗。
本發明的特定技術可減少ARP中涉及的削減操作的數目。舉例來說,根據本發明的技術,當確定第一參考塊時,視頻譯碼器可將可分離的雙線性內插濾波器應用于第一參考圖片的樣本以確定第一參考塊的樣本。類似地,當確定第二參考塊時,視頻譯碼器可將可分離的雙線性內插濾波器應用于第二參考圖片的樣本以確定第二參考塊的樣本。類似地,當確定第三參考塊時,視頻譯碼器可將可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本。由于應用此可分離的雙線性內插濾波器,因此可避免不可分離的濾波器涉及的削減操作,這可減少復雜性。另外,可再使用HEVC設計中的經加權預測過程。
在一些實例中,用于每一階段(例如,子整數位置)的可分離的雙線性內插濾波器中使用的系數的總和可共計為64,其與布洛斯等人的“高效視頻譯碼(HEVC)缺陷報告3(High Efficiency Video Coding(HEVC)Defect Report 3)”(ITU-T SG16 WP3和ISO/IEC JTC1/SC29/WG11的視頻譯碼聯合合作小組(JCT-VC)第16次會議,美國圣何塞,2014年1月,文檔編號JCTVC-P1003_v1(下文為“HEVC版本1”或“HEVC草案規范”))中使用的其它雙線性內插濾波器相同。換句話說,對于多個階段中的每一相應階段,用于相應階段的可分離的雙線性內插濾波器的系數的總和等于64,所述多個階段對應于位流所符合的視頻譯碼標準(例如,3D-HEVC)允許的子整數位置。在一些實例中,對于所述多個階段中的每一相應相位,用于相應階段的可分離的雙線性內插濾波器的相應系數的總和等于(x*8,(8-x)*8),其中x等于在0到8的范圍內的值。總計為64的系數可具有通過協調在ARP中使用的內插濾波器與在HEVC版本1中在別處使用的雙線性內插濾波器而減少復雜性的增加益處。
因此,視頻譯碼器可基于視頻數據的當前圖片中的當前塊的運動向量確定第一參考圖片中的第一參考塊的位置。視頻譯碼器可將可分離的雙線性內插濾波器應用于第一參考圖片的樣本以確定第一參考塊的樣本。另外,視頻譯碼器可確定第二參考圖片中的第二參考塊的位置。此外,視頻譯碼器可將可分離的雙線性內插濾波器應用于第二參考圖片的樣本以確定第二參考塊的樣本。視頻譯碼器可將可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本。第一、第二和第三參考圖片中的每一者是不同圖片。視頻譯碼器可確定預測性塊。預測性塊的每一相應樣本等于第一參考塊的相應樣本加相應殘余預測符樣本。相應殘余預測符樣本等于非零加權因數乘以第二參考塊的相應樣本與第三參考塊的相應樣本之間的差。第一參考塊的相應樣本、第二參考塊的相應樣本以及第三參考塊的相應樣本在第一、第二和第三參考塊內對應于預測性塊的相應樣本的位置的位置處。
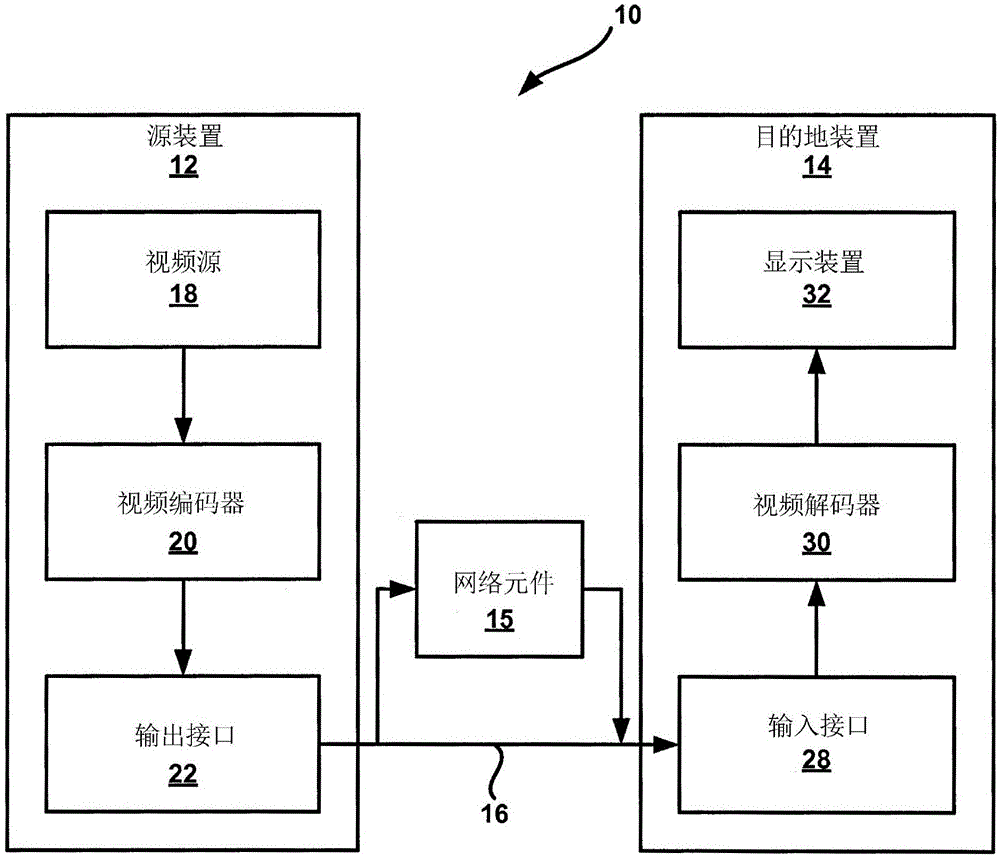
圖1是說明可利用本發明的技術的實例視頻譯碼系統10的框圖。如本文所使用,術語“視頻譯碼器”一般是指視頻編碼器及視頻解碼器兩者。在本發明中,術語“視頻譯碼”或“譯碼”可一般地指代視頻編碼或視頻解碼。
如圖1中所示,視頻譯碼系統10包含源裝置12、目的地裝置14和網絡元件15。源裝置12產生經編碼的視頻數據。因此,源裝置12可被稱為視頻編碼裝置或視頻編碼設備。目的地裝置14可以對由源裝置12所產生的經編碼的視頻數據進行解碼。因此,目的地裝置14可以被稱為視頻解碼裝置或視頻解碼設備。源裝置12以及目的地裝置14可以是視頻編解碼裝置或視頻編解碼設備的實例。
源裝置12和目的地裝置14可包括廣泛范圍的裝置,包含桌上型計算機、移動計算裝置、筆記本(例如,膝上型計算機)計算機、平板計算機、機頂盒、例如所謂的“智能”電話(即,智能電話、手機、蜂窩式電話)的電話手持機、電視機、相機、顯示裝置、數字媒體播放器、視頻游戲控制臺、車內計算機或類似物。
網絡元件15可接收經編碼視頻數據且輸出經處理的經編碼視頻數據。網絡元件15可為媒體感知網絡元件(MANE)、內容遞送網絡(CDN)裝置或另一類型的裝置(例如,計算裝置)。網絡元件15、源裝置12、目的地裝置14以及處理視頻數據的其它類型的裝置可視為視頻處理裝置。
目的地裝置14可經由信道16從源裝置12接收經編碼視頻數據。信道16可包括能夠將經編碼視頻數據從源裝置12移動至目的地裝置14的一或多個媒體或裝置。在一個實例中,信道16包括使得源裝置12能夠實時將經編碼視頻數據直接發射到目的地裝置14的一或多個通信媒體。在此實例中,源裝置12可以根據例如無線通信協議等通信標準調制經編碼的視頻數據,并且可以將經調制的視頻數據發射到目的地裝置14。一或多個通信媒體可以包含無線通信媒體和/或有線通信媒體,例如射頻(RF)頻譜或一或多個物理傳輸線。一或多個通信媒體可形成基于數據包的網絡的一部分,基于數據包的網絡例如局域網、廣域網或全球網絡(例如,因特網)。信道16可包含路由器、交換機、基站或促進從源裝置12到目的地裝置14的通信的其它設備。
在另一實例中,信道16可包含存儲由源裝置12產生的經編碼視頻數據的存儲媒體。在此實例中,目的地裝置14可(例如)經由磁盤存取或卡存取來存取存儲媒體。存儲媒體可以包含多種本地存取的數據存儲媒體,例如藍光光盤、DVD、CD-ROM、快閃存儲器或用于存儲經編碼的視頻數據的其它合適數字存儲媒體。
在另一實例中,信道16可以包含存儲由源裝置12產生的經編碼的視頻數據的文件服務器或另一中間存儲裝置。在此實例中,目的地裝置14可以經由流式傳輸或下載而存取存儲于文件服務器或其它中間存儲裝置處的經編碼的視頻數據。文件服務器可為能夠存儲經編碼視頻數據并且將經編碼視頻數據傳輸到目的地裝置14的一種類型的服務器。實例文件服務器包含網絡服務器(例如,用于網站)、文件傳輸協議(FTP)服務器、網絡附接存儲(NAS)裝置和本地磁盤驅動器。
目的地裝置14可以通過標準數據連接(例如因特網連接)來存取經編碼的視頻數據。數據連接的實例類型可包含無線信道(例如,Wi-Fi連接)、有線連接(例如,數字訂戶線(DSL)、電纜調制解調器等),或適合于存取存儲在文件服務器上的經編碼視頻數據的兩者的組合。經編碼視頻數據從文件服務器的發射可為流式發射、下載發射或兩者的組合。
本發明的技術不限于無線應用或設置。所述技術可應用于視頻譯碼以支持多種多媒體應用,例如空中電視廣播、有線電視發射、衛星電視發射、流式視頻發射(例如,經由因特網)、對視頻數據進行編碼以存儲于數據存儲媒體上、對存儲在數據存儲媒體上的視頻數據進行解碼,或其它應用。在一些實例中,視頻譯碼系統10可經配置以支持單向或雙向視頻傳輸以支持例如視頻流式傳輸、視頻回放、視頻廣播及/或視頻電話等應用。
圖1僅為實例,且本發明的技術可適用于未必包含編碼及解碼裝置之間的任何數據通信的視頻譯碼設定(例如視頻編碼或視頻解碼)。在其它實例中,從本地存儲器檢索、在網絡上流式傳輸或以類似方式處理數據(例如,視頻數據)。視頻編碼裝置可將數據(例如,視頻數據)編碼且存儲到存儲器,和/或視頻解碼裝置可從存儲器檢索且解碼數據(例如,視頻數據)。在許多實例中,通過并不彼此通信而是簡單地編碼數據到存儲器和/或從存儲器檢索數據且解碼數據(例如,視頻數據)的裝置執行編碼和解碼。
在圖1的實例中,源裝置12包含視頻源18、視頻編碼器20以及輸出接口22。在一些實例中,輸出接口22可包含調制器/解調器(調制解調器)和/或發射器。視頻源18可包含視頻俘獲裝置(例如,攝像機)、含有先前俘獲的視頻數據的視頻存檔、用于從視頻內容提供者接收視頻數據的視頻饋入接口及/或用于產生視頻數據的計算機圖形系統,或視頻數據的此等源的組合。因此,在一些實例中,源裝置12包括經配置以俘獲視頻數據的相機。
視頻編碼器20可對來自視頻源18的視頻數據進行編碼。在一些實例中,源裝置12經由輸出接口22將經編碼的視頻數據直接發射到目的地裝置14。在其它實例中,經編碼的視頻數據也可存儲到存儲媒體或文件服務器上以供稍后由目的地裝置14存取以用于解碼和/或回放。
在圖1的實例中,目的地裝置14包含輸入接口28、視頻解碼器30和顯示裝置32。在一些實例中,輸入接口28包含接收器和/或調制解調器。輸入接口28可經由信道16接收經編碼視頻數據。視頻解碼器30可對經編碼視頻數據進行解碼。顯示裝置32經配置以顯示經解碼視頻數據。顯示裝置32可與目的地裝置14集成或在目的地裝置14外部。顯示裝置32可以包括多種顯示裝置,例如液晶顯示器(LCD)、等離子顯示器、有機發光二極管(OLED)顯示器或另一類型的顯示裝置。
視頻編碼器20和視頻解碼器30各自可實施為例如以下各者的多種合適電路中的任一者:一或多個微處理器、數字信號處理器(DSP)、專用集成電路(ASIC)、現場可編程門陣列(FPGA)、離散邏輯、硬件或其任何組合。如果部分地以軟件來實施所述技術,那么裝置可將軟件的指令存儲在合適的非暫時性計算機可讀存儲媒體中,且可使用一或多個處理器以硬件執行指令從而執行本發明的技術。可以將前述內容中的任一者(包含硬件、軟件、硬件與軟件的組合等)視為一或多個處理器。視頻編碼器20和視頻解碼器30中的每一者可以包含在一或多個編碼器或解碼器中,所述編碼器或解碼器中的任一者可以集成為相應裝置中的組合編碼器/解碼器(編解碼器)的一部分。
本發明大體上可指視頻編碼器20將某些信息“用信號表示”給另一裝置(例如,視頻解碼器30)。術語“用信號表示”可大體上指傳達用以解碼經壓縮視頻數據的語法元素及/或其它數據。此傳送可實時或幾乎實時發生。替代地,此通信可經過一段時間后發生,例如可在編碼時以經編碼位流將語法元素存儲到計算機可讀存儲媒體時發生,解碼裝置接著可在所述語法元素存儲到此媒體之后的任何時間檢索所述語法元素。
在一些實例中,視頻編碼器20及視頻解碼器30根據視頻壓縮標準而操作,例如ISO/IEC MPEG-4Visual及ITU-T H.264(也稱為ISO/IEC MPEG-4AVC),包含其可縮放視頻譯碼(SVC)擴展、多視圖視頻譯碼(MVC)擴展及基于MVC的3DV擴展。在一些情況下,符合H.264/AVC的基于MVC的3DV擴展的任何位流始終含有順應H.264/AVC的MVC擴展的子位流。MVC的最新聯合草案描述于2010年3月的“用于通用視聽服務的高級視頻譯碼(Advanced video coding for generic audiovisual services)”(ITU-T建議H.264)中。此外,正在致力于產生H.264/AVC的三維視頻(3DV)譯碼擴展,即基于AVC的3DV。在其它實例中,視頻編碼器20和視頻解碼器30可根據ITU-T H.261、ISO/IEC MPEG-1視覺、ITU-T H.262或ISO/IEC MPEG-2視覺、ITU-T H.263以及ISO/IEC MPEG-4視覺來操作。
在其它實例中,視頻編碼器20及視頻解碼器30根據由ITU-T視頻譯碼專家組(VCEG)及ISO/IEC動畫專家組(MPEG)的視頻譯碼聯合合作小組(JCT-VC)開發的高效率視頻譯碼(HEVC)標準操作。HEVC草案規范可得自:http://phenix.it-sudparis.eu/jct/doc_end_user/documents/16_San%20Jose/wg11/JCTVC-P1003-v1.zip。
在HEVC及其它視頻譯碼規范中,視頻序列通常包含一系列圖片。圖片也可被稱作“幀”。圖片可包含三個樣本陣列,表示為SL、SCb和SCr。SL是明度樣本的二維陣列(即,塊)。SCb是Cb色度樣本的二維陣列。SCr是Cr色度樣本的二維陣列。色度樣本在本文中還可以被稱為“色度”樣本。在其它情況下,圖片可為單色的且可僅包含明度樣本陣列。在其它實例中,圖片可包括用于不同類型的顏色分量的樣本陣列,例如RGB、YCgCo等等。
為了產生圖片的經編碼表示,視頻編碼器20產生譯碼樹單元(CTU)的集合。CTU中的每一者可包括明度樣本的譯碼樹塊(CTB)、色度樣本的兩個對應的譯碼樹塊,以及用以對譯碼樹塊的樣本進行譯碼的語法結構。在單色圖片或具有三個單獨顏色平面的圖片中,CTU可包括單個譯碼樹塊和用于對所述譯碼樹塊的樣本進行譯碼的語法結構。譯碼樹塊可為樣本的NxN塊。CTU也可以被稱為“樹塊”或“最大譯碼單元(LCU)”。HEVC的CTU可以廣泛地類似于例如H.264/AVC等其它標準的宏塊。然而,CTU未必限于特定大小,并且可以包含一或多個譯碼單元(CU)。切片可包含按光柵掃描次序連續排序的整數數目的CTU。
本發明可使用術語“視頻單元”或“視頻塊”或“塊”來指代一或多個樣本塊及用于對所述一或多個樣本塊中的樣本進行譯碼的語法結構。實例類型的視頻單元可包含CTU、CU、PU、變換單元(TU)、宏塊、宏塊分區等。在一些情形中,PU的論述可與宏塊或宏塊分區的論述互換。
為了產生經編碼CTU,視頻編碼器20可對CTU的譯碼樹塊遞歸地執行四叉樹分割,以將譯碼樹塊劃分為譯碼塊,因此命名為“譯碼樹單元”。譯碼塊是樣本的NxN塊。CU可包括具有明度樣本陣列、Cb樣本陣列和Cr樣本陣列的圖片的明度樣本的譯碼塊以及色度樣本的兩個對應的譯碼塊,以及用以對譯碼塊的樣本進行譯碼的語法結構。在單色圖片或具有三個單獨顏色平面的圖片中,CU可包括單個譯碼塊和用以對譯碼塊的樣本進行譯碼的語法結構。
視頻編碼器20可將CU的譯碼塊分割為一或多個預測塊。預測塊是對其應用相同預測的樣本的矩形(即,正方形或非正方形)塊。CU的預測單元(PU)可包括明度樣本的預測塊、色度樣本的兩個對應預測塊和用以預測預測塊的語法結構。在單色圖片或具有三個單獨顏色平面的圖片中,PU可包括單個預測塊和用以預測預測塊的語法結構。視頻編碼器20可針對CU的每一PU的預測塊(例如,明度、Cb和Cr預測塊)產生預測性塊(例如,明度、Cb和Cr預測性塊)。
視頻編碼器20可使用幀內預測或幀間預測來產生PU的預測塊。如果視頻編碼器20使用幀內預測以產生PU的預測性塊,那么視頻編碼器20可基于包含PU的圖片的經解碼樣本產生PU的預測性塊。如果視頻編碼器20使用幀間預測以產生PU的預測性塊,那么視頻編碼器20可基于除包含PU的圖片外的一或多個圖片的經解碼樣本而產生PU的預測性塊。
在視頻編碼器20產生CU的一或多個PU的預測性塊(例如,明度、Cb和Cr預測性塊)之后,視頻編碼器20可產生CU的一或多個殘余塊。舉例來說,視頻編碼器20可產生CU的明度殘余塊。CU的明度殘余塊中的每個樣本指示CU的預測性明度塊中的一者中的明度樣本與CU的原始明度譯碼塊中對應的樣本之間的差異。另外,視頻編碼器20可以產生CU的Cb殘余塊。CU的Cb殘余塊中的每一樣本可以指示CU的預測性Cb塊中的一者中的Cb樣本與CU的原始Cb譯碼塊中對應的樣本之間的差異。視頻編碼器20還可產生CU的Cr殘余塊。CU的Cr殘余塊中的每一樣本可以指示CU的預測性Cr塊中的一者中的Cr樣本與CU的原始Cr譯碼塊中的對應樣本之間的差異。
此外,視頻編碼器20可使用四叉樹分割將CU的殘余塊(例如,明度、Cb及Cr殘余塊)分解為一或多個變換塊(例如,明度、Cb及Cr變換塊)。變換塊是對其應用相同變換的樣本的矩形(例如,正方形或非正方形)塊。CU的變換單元(TU)可包括明度樣本的變換塊、色度樣本的兩個對應變換塊及用以對變換塊樣本進行變換的語法結構。因此,CU的每一TU可具有明度變換塊、Cb變換塊以及Cr變換塊。TU的明度變換塊可為CU的明度殘余塊的子塊。Cb變換塊可為CU的Cb殘余塊的子塊。Cr變換塊可以是CU的Cr殘余塊的子塊。在單色圖片或具有三個單獨顏色平面的圖片中,TU可包括單個變換塊和用以對變換塊的樣本進行變換的語法結構。
視頻編碼器20可以將一或多個變換應用到TU的變換塊以產生TU的系數塊。舉例來說,視頻編碼器20可將一或多個變換應用到TU的明度變換塊以產生TU的明度系數塊。系數塊可為變換系數的二維陣列。變換系數可為標量。視頻編碼器20可將一或多個變換應用至TU的Cb變換塊以產生TU的Cb系數塊。視頻編碼器20可將一或多個變換應用至TU的Cr變換塊以產生TU的Cr系數塊。
在產生系數塊(例如,明度系數塊、Cb系數塊或Cr系數塊)之后,視頻編碼器20可以量化系數塊。量化總體上是指對變換系數進行量化以可能減少用以表示變換系數的數據的量從而提供進一步壓縮的過程。在視頻編碼器20量化系數塊之后,視頻編碼器20可以對指示經量化變換系數的語法元素進行熵編碼。舉例來說,視頻編碼器20可對指示經量化變換系數的語法元素執行上下文自適應二進制算術譯碼(CABAC)。
視頻編碼器20可輸出包含形成經譯碼圖片及相關聯數據的表示的位序列的位流。因此,位流包括視頻數據的經編碼表示。位流可包括一連串網絡抽象層(NAL)單元。NAL單元是含有NAL單元中的數據類型的指示及含有所述數據的呈按需要穿插有模擬阻止位的原始字節序列有效負載(RBSP)的形式的字節的語法結構。NAL單元中的每一者包含NAL單元標頭且囊封RBSP。NAL單元標頭可包含指示NAL單元類型碼的語法元素。由NAL單元的NAL單元標頭指定的所述NAL單元類型代碼指示NAL單元的類型。RBSP可為含有囊封在NAL單元內的整數數目個字節的語法結構。在一些情況下,RBSP包含零個位。
不同類型的NAL單元可囊封不同類型的RBSP。例如,不同類型的NAL單元可包封用于視頻參數集(VPS)、序列參數集(SPS)、圖片參數集(PPS)、經譯碼切片、補充增強信息(SEI)等的不同RBSP。囊封用于視頻譯碼數據的RBSP(與用于參數集和SEI消息的RBSP相反)的NAL單元可被稱為視頻譯碼層(VCL)NAL單元。在HEVC(即,非多層HEVC)中,存取單元可為按解碼次序連續且含有確切一個經譯碼圖片的NAL單元的集合。除經譯碼圖片的經譯碼切片NAL單元之外,存取單元還可含有不含經譯碼圖片的切片的其它NAL單元。在一些實例中,對存取單元的解碼始終產生經解碼圖片。補充增強信息(SEI)含有并非對來自VCL NAL單元的經譯碼圖片的樣本進行解碼所必需的信息。SEI RBSP含有一或多個SEI消息。
視頻解碼器30可以接收由視頻編碼器20產生的位流。另外,視頻解碼器30可以剖析位流以獲得來自位流的語法元素。視頻解碼器30可至少部分地基于從位流獲得的語法元素重構視頻數據的圖片。用以重建視頻數據的過程通常可與由視頻編碼器20執行的過程互逆。舉例來說,視頻解碼器30可使用PU的運動向量來確定當前CU的PU的預測性塊。另外,視頻解碼器30可逆量化當前CU的TU的系數塊。視頻解碼器30可對系數塊執行逆變換以重構當前CU的TU的變換塊。通過將用于當前CU的PU的預測性塊的樣本增加到當前CU的TU的變換塊的對應的樣本上,視頻解碼器30可以重構當前CU的譯碼塊。通過重構用于圖片的每一CU的譯碼塊,視頻解碼器30可重構圖片。
當前,VCEG和MPEG的3D視頻譯碼聯合合作小組(JCT-3C)正在開發基于HEVC的3DV標準,其標準化努力的部分包含基于HEVC的多視圖視頻編解碼器(MV-HEVC)的標準化和用于基于HEVC的3D視頻譯碼(3D-HEVC)的另一部分。對于3D-HEVC,可包含且支持用于紋理和深度視圖兩者的新譯碼工具,包含處于CU/PU層級的那些譯碼工具。參考軟件描述如下可用:張等人的“3D-HEVC和MV-HEVC的測試模型6(Test Model 6of 3D-HEVC and MV-HEVC)”(JCT3V-F1005,ITU-T SG 16WP 3和ISO/IEC JTC 1/SC 29/WG 11的3D視頻譯碼擴展開發聯合合作小組第6次會議:瑞士日內瓦,2013年11月,下文為“JCT3V-F1005”)。JCT3V-F1005可從以下鏈接下載:http://phenix.it-sudparis.eu/jct2/doc_end_user/current_document.php?id=1636。泰克等人的“3D-HEVC草案文本2(3D-HEVC Draft Text 2)”(ITU-T SG 16WP 3和ISO/IEC JTC 1/SC 29/WG 11的3D視頻譯碼擴展開發聯合合作小組第6次會議:瑞士日內瓦,2013年11月,文獻JCT3V-F1001(下文為“3D-HEVC草案文本2”))是3D-HEVC的工作草案。3D-HEVC草案文本2可從以下鏈接下載:http://phenix.it-sudparis.eu/jct2/doc_end_user/documents/6_Geneva/wg11/JCT3V-F1001-v4.zip。
泰克等人的“3D-HEVC草案文本4(3D-HEVC Draft Text 4)”(ITU-T SG 16WP 3和ISO/IEC JTC 1/SC 29/WG 11的3D視頻譯碼擴展開發聯合合作小組第8次會議:西班牙巴倫西亞,2014年3月29日至4月4日,文獻JCT3V-H1001_v2(下文為“3D-HEVC草案文本4”或“當前3D-HEVC”))是3D-HEVC的另一工作草案。
本發明的技術潛在地適用于多視圖譯碼和/或3DV標準和規范,包含MV-HEVC和3D-HEVC。在例如MV-HEVC、3D-HEVC草案文本2和3D-HEVC草案文本4中界定的多視圖譯碼中,可存在同一場景的從不同視點的多個視圖。在多視圖譯碼和可縮放視頻譯碼的上下文中,術語“存取單元”可用以指代對應于同一時間實例的圖片的集合。在一些情況下,在多視圖譯碼和可縮放視頻譯碼的上下文中,存取單元可為根據指定分類規則彼此相關聯、按解碼次序連續且含有與同一輸出時間相關聯的所有經譯碼圖片的VCL NAL單元及其相關聯非VCL NAL單元的NAL單元的集合。因此,視頻數據可經概念化為隨時間出現的一系列存取單元。
在例如3D-HEVC草案文本4中界定的3DV譯碼中,“視圖分量”可為單個存取單元中的視圖的經譯碼表示。視圖分量可含有紋理視圖分量和深度視圖分量。深度視圖分量可為單個存取單元中的視圖的深度的經譯碼表示。紋理視圖分量可為單個存取單元中的視圖的紋理的經譯碼表示。在本發明中,“視圖”可指與相同視圖識別符相關聯的一連串視圖分量。
視圖的一圖片集合內的紋理視圖分量及深度視圖分量可被視為對應于彼此。舉例來說,視圖的圖片組內的紋理視圖分量認為是對應于視圖的所述圖片組內的深度視圖分量,且反之亦然(即,深度視圖分量對應于所述組中的其紋理視圖分量,且反之亦然)。如本發明中所使用,對應于深度視圖分量的紋理視圖分量可被視為紋理視圖分量且深度視圖分量為單一存取單元的同一視圖的部分。
紋理視圖分量包含所顯示的實際圖像內容。舉例來說,所述紋理視圖分量可包含明度(Y)及色度(Cb及Cr)分量。深度視圖分量可指示其對應紋理視圖分量中的像素的相對深度。作為一個實例,深度視圖分量為僅包含明度值的灰階圖像。換句話說,深度視圖分量可不傳達任何圖像內容,而是提供紋理視圖分量中的像素的相對深度的量度。
在多視圖譯碼和SVC譯碼中,位流可具有多個層。在多視圖譯碼中,所述層中的每一者可對應于不同視圖。如果視頻解碼器(例如,視頻解碼器30)可解碼層中的圖片而無需參考任何其它層中的圖片,那么層可被稱為“基礎層”。如果層的解碼取決于在一或多個其它層中的圖片的解碼,那么所述層可被稱為“非基礎層”或“相依性層”。當對非基礎層中的一者中的圖片進行譯碼時,視頻譯碼器(例如,視頻編碼器20或視頻解碼器30)可在圖片與視頻譯碼器當前正譯碼的圖片處于不同視圖中但在同一時間實例(即,存取單元)內的情況下將所述圖片添加到參考圖片列表中。如同其它幀間預測參考圖片,視頻譯碼器可在參考圖片列表的任何位置處插入視圖間預測參考圖片。
在SVC中,除基礎層外的層可被稱為“增強層”且可提供增強從位流解碼的視頻數據的視覺質量的信息。SVC可增強空間分辨率、信噪比(即,質量)或時間速率。在可縮放視頻譯碼(例如,SHVC)中,“層表示”可為單個存取單元中的空間層的經譯碼表示。為便于說明,本發明可將視圖分量和/或層表示稱為“視圖分量/層表示”或簡稱為“圖片”。
為了實施所述層,NAL單元的標頭可包含nuh_reserved_zero_6bits語法元素,其也可被稱作“nuh_layer_id”語法元素。具有指定不同值的nuh_reserved_zero_6bit語法元素的NAL單元屬于位流的不同層。因此,在多視圖譯碼(例如,MV-HEVC)、3DV(例如,3D-HEVC)或SVC(例如,SHVC)中,NAL單元的nuh_reserved_zero_6bits語法元素指定所述NAL單元的層識別符(即,層ID)。在一些實例中,如果一NAL單元與多視圖譯碼(例如,MV-HEVC)、3DV譯碼(例如,3D-HEVC)或SVC(例如,SHVC)中的基礎層有關,那么所述NAL單元的nuh_reserved_zero_6bits語法元素等于0。可在不參考位流的任何其它層中的數據的情況下解碼位流的基礎層中的數據。如果NAL單元并不涉及多視圖譯碼、3DV或SVC中的基礎層,那么語法元素的nuh_reserved_zero_6bits語法元素可具有非零值。如上文所指出,在多視圖譯碼和3DV譯碼中,位流的不同層可對應于不同視圖。
此外,在一層內的一些視圖分量/層表示可在不參考同一層內的其它視圖分量/層表示的情況下加以解碼。因此,囊封一層的某些視圖分量/層表示的數據的NAL單元可從位流移除,而不影響所述層中的其它視圖分量/層表示的可解碼性。移除囊封此些視圖分量/層表示的數據的NAL單元可減小位流的幀速率。可在不參考在一層內的其它視圖分量/層表示的情況下解碼的在所述層內的視圖分量/層表示的子集可在本文中被稱作“子層”或“時間子層”。
NAL單元可包含指定NAL單元的時間識別符(即,TemporalIds)的temporal_id語法元素。NAL單元的時間識別符識別NAL單元屬于的子層。因此,位流的每一子層可具有不同時間識別符。一般來說,如果第一NAL單元的時間識別符小于第二NAL單元的時間識別符,那么可在不參考由第二NAL單元囊封的數據的情況下解碼由第一NAL單元囊封的數據。
圖2是說明用于多視圖譯碼的實例預測結構的概念圖。圖2的多視圖預測結構包含時間及視圖間預測。在圖2的實例中,每一正方形對應于一視圖分量。在圖2的實例中,將存取單元標記為T0...T11及將視圖標記為S0...S7。標記為“I”的正方形為經幀內預測視圖分量。標記為“P”的正方形為單向幀間預測視圖分量。標記為“B”及“b”的正方形為經雙向幀間預測視圖分量。標記為“b”的正方形可將標記為“B”的正方形用作參考圖片。從第一正方形指向第二正方形的箭頭指示第一正方形可在幀間預測時用作第二正方形的參考圖片。如由圖2中的垂直箭頭所指示,可將同一存取單元的不同視圖中的視圖分量作為參考圖片。因此,圖2展示用于多視圖視頻譯碼的典型的多視圖譯碼預測(包含每一視圖內的圖片間預測及視圖間預測兩者)結構,其中由箭頭指示預測,被指向對象使用指出對象用于預測參考。將存取單元的一個視圖分量用作相同存取單元的另一視圖分量的參考圖片可被稱為視圖間預測。
在多視圖譯碼中,在從同一存取單元的不同視圖(即,具有相同時間例項)俘獲的圖片當中執行視圖間預測以移除視圖之間的相關度。以視圖間預測譯碼的圖片可添加到其它非基礎視圖的視圖間預測的參考圖片列表中。視圖間預測參考圖片可以與幀間預測參考圖片相同的方式放入參考圖片列表的任何位置中。
在多視圖視頻譯碼的的情況下,存在兩個類型的運動向量。一種類型是指向時間參考圖片的正常運動向量(即,時間運動向量)且對應時間幀間預測是運動補償預測(MCP)。另一種類型是指向不同視圖中的圖片(即,視圖間參考圖片)的視差運動向量(DMV)且對應幀間預測為視差補償預測(DCP)。視頻譯碼器可使用時間運動向量和視差運動向量兩者用于幀間預測。一般來說,視差向量不是視差運動向量,除非用于幀間預測。
在HEVC版本1中,存在兩個幀間預測模式,對于PU分別被命名為合并(跳過視為合并的特殊情況)和高級運動向量預測(AMVP)模式。在AMVP或合并模式中,為多個運動向量預測符維持運動向量(MV)候選者列表。當前PU的運動向量(以及合并模式中的參考索引)是通過從MV候選者列表獲取一個候選者而產生。
MV候選者列表含有用于合并模式的多達5個候選者和用于AMVP模式的僅兩個候選者。合并候選者可含有運動信息集合,例如對應于兩個參考圖片列表(列表0和列表1)的運動向量和參考索引。如果通過合并索引來識別合并候選者,那么參考圖片用于當前塊的預測以及確定相關聯的運動向量。然而,在AMVP模式下,對于自列表0或列表1起的每一潛在預測方向,將參考索引連同對MV候選者列表的MVP索引一起明確地用信號表示,這是因為AMVP候選者僅含有運動向量。在AMVP模式中,進一步用信號表示所選運動向量與對應于MVP索引的運動向量預測符之間的運動向量差。如可從上文看出,合并候選者對應于整個運動信息集合,而AMVP候選者僅含有用于特定預測方向的一個運動向量和參考索引。
在3D-HEVC草案文本4中,最終合并候選者列表包含來自HEVC基礎合并列表(即,根據HEVC版本1產生的合并列表)的條目以及通過所謂的視圖間預測導出的額外候選者。更具體來說,如下描述主要過程。
第一,將空間和時間合并候選者插入到基礎合并候選者列表中,與HEVC版本1中類似。第二,當必要時將也被稱作組合式雙向預測合并候選者的虛擬候選者以及零候選者插入到基礎合并候選者列表中,以使得候選者的總數等于MaxNumMergeCand,其等于例如在視圖間預測或運動參數繼承(MPI)經啟用的情況下如切片標頭中用信號表示的單視圖HEVC候選者的數目加一。在此之后,形成HEVC基礎候選者列表。第三,通過將額外3D-HEVC候選者以及HEVC基礎候選者列表中的候選者插入到一個列表中而產生3D-HEVC合并列表。第四,額外3D-HEVC候選者包含:經視圖間預測的運動候選者,表示為IvMC;視圖間視差向量候選者,表示為IvDC;視圖合成預測候選者,表示為VSP;移位候選者,表示為IvShift,等于表示為IvMCShift的經移位經視圖間預測的運動候選者或由IvDCShift表示的經移位視差合并候選者。
視頻譯碼器可將視差向量(DV)用作兩個視圖之間的視差的估計量。視頻譯碼器可使用基于相鄰塊的視差向量(NBDV)過程以導出視差向量。NBDV過程用于3D-HEVC草案文本4中的視差向量導出方法,其使用紋理優先譯碼順序用于所有視圖。在3D-HEVC草案文本4中,通過從參考視圖的深度圖檢索深度數據可進一步精煉從NBDV導出的視差向量。
當視頻譯碼器執行NBDV過程以導出視差向量時,視頻譯碼器使用視差向量(DV)作為兩個視圖之間的位移的估計量。因為相鄰塊在視頻譯碼中幾乎共享相同的運動/視差信息,所以當前塊可使用相鄰塊中的運動向量信息作為良好預測符。依照此想法,NBDV過程使用相鄰視差信息用于估計不同視圖中的視差向量。
首先界定若干空間和時間相鄰塊。這些相鄰塊可被稱為“視差運動向量候選者”。視頻譯碼器隨后以通過當前塊與候選塊之間的相關的優先級所確定的預定義次序檢查空間和時間相鄰塊中的每一者。一旦視頻譯碼器在視差運動向量候選者中找到視差運動向量(即,所述運動向量指向視圖間參考圖片),視頻譯碼器便將視差運動向量轉換為視差向量。視頻譯碼器返回視差向量和相關聯視圖次序索引作為NBDV過程的輸出。視圖的視圖次序索引可指示所述視圖相對于其它視圖的相機位置。如上方提及,視頻譯碼器可在NBDV過程中使用相鄰塊的兩個集合。相鄰塊的一個集合是空間相鄰塊并且相鄰塊的另一集合是時間相鄰塊。
L·張等人的“3D-CE5.h:視差向量產生結果(3D-CE5.h:Disparity vector generation results)”(ITU-T SG 16WP 3和ISO/IEC JTC 1/SC 29/WG 11的3D視頻譯碼擴展開發聯合合作小組第1次會議:瑞典斯德哥爾摩,2012年7月16-20日,文獻JCT3V-A0097(下文為“JCT3V-A0097”))中所提議的NBDV過程首先采用到3D-HEVC中。NBDV導出過程已經進一步調適。舉例來說,在桑(Sung)等人的“3D-CE5.h:基于HEVC的3D視頻譯碼的視差向量導出的簡化(3D-CE5.h:Simplification of disparity vector derivation for HEVC-based 3D video coding)”(ITU-T SG 16WP 3和ISO/IEC JTC1/SC 29/WG 11的3D視頻譯碼擴展開發聯合合作小組第1次會議:瑞典斯德哥爾摩,2012年7月16-20日,文獻JCT3V-A0126(下文為“JCT3V-A0126”))中的簡化NBDV包含隱式視差向量(IDV)。此外,在康等人的“3D-CE5.h相關:用于視差向量導出的改進(3D-CE5.h related:Improvements for disparity vector derivation)”(ITU-T SG 16WP 3和ISO/IEC JTC 1/SC 29/WG 11的3D視頻譯碼擴展開發聯合合作小組第2次會議:中國上海,2012年10月13-19日,文獻JCT3V-B0047(下文為“JCT3V-B0047”))中,通過移除存儲在經解碼圖片緩沖器中的IDV而進一步簡化NBDV導出過程,同時提供關于RAP圖片選擇的改進的譯碼增益。康等人的“CE2:在3D-HEVC中的基于CU的視差向量導出(CE2:CU-based Disparity Vector Derivation in 3D-HEVC)”(ITU-T SG 16WP 3和ISO/IEC JTC 1/SC 29/WG 11的3D視頻譯碼擴展開發聯合合作小組第4次會議:韓國仁川,2013年4月20-26日,文獻JCT3V-D0181)提出了基于CU的NBDV,其中DV是針對CU導出且應用于其中的所有PU。
在一些NBDV過程中,視頻譯碼器使用五個空間相鄰塊用于視差向量導出。所述五個空間相鄰塊是覆蓋當前PU的CU的左下方、左邊、右上方、上方和左上方塊,如圖3中所示由A0、A1、B0、B1或B2表示。圖3是說明相對于一個CU 40的實例空間運動向量相鄰者的概念圖。圖3中所示的空間相鄰者與HEVC版本1中的合并和AMVP模式中使用的那些空間相鄰者相同。因此,在一些實例中,當執行NBDV過程時不需要額外存儲器存取來檢索空間相鄰的運動信息。
對于在NBDV過程中檢查時間相鄰塊,視頻譯碼器首先執行候選圖片列表的構造過程。視頻譯碼器可處理來自當前視圖的多達兩個參考圖片作為候選圖片。首先將位于同一地點的參考圖片插入到候選圖片列表,接著按參考索引的升序插入額外候選圖片。含有當前塊的切片的切片標頭中的一或多個語法元素可指示位于同一地點的參考圖片。當兩個參考圖片列表中具有相同參考索引的參考圖片可用時,位于同一地點的圖片的同一參考圖片列表中的參考圖片在另一參考圖片前面。對于候選圖片列表中的每一候選圖片,確定三個候選區以用于導出時間相鄰塊。
當塊是以視圖間運動預測譯碼時,需要導出視差向量用于選擇不同視圖中的對應塊。隱式視差向量(IDV)被稱作在視圖間運動預測中導出的視差向量。IDV還可被稱作“所導出的視差向量”。即使塊是以運動預測譯碼的,為了對隨后的塊進行譯碼的目的也不會丟棄所導出的視差向量。
術語“3D-HTM”指代用于3D-HEVC的測試模型。在3D-HTM 7.0的設計和3D-HTM的隨后版本中,執行NBDV過程的視頻譯碼器按次序檢查時間相鄰塊中的視差運動向量、空間相鄰塊中的視差運動向量以及隨后的IDV。一旦視頻譯碼器找到視差運動向量或IDV,則視頻譯碼器終止NBDV過程。此外,在3D-HTM 7.0的當前設計和3D-HTM的稍后版本中,在NBDV過程中檢查的空間相鄰塊的數目進一步減少到2。
在一些實例中,當視頻譯碼器從NBDV過程導出視差向量時,視頻譯碼器通過從參考視圖的深度圖檢索深度數據而進一步精煉視差向量。在一些此類實例中,精煉過程包含兩個步驟:
1.在例如基礎視圖等經先前譯碼參考深度視圖中通過所導出的視差向量定位對應深度塊。對應深度塊的大小與當前PU的大小相同。
2.從對應深度塊的四個拐角像素選擇一個深度值且將所述選定深度值轉換為經精煉視差向量的水平分量。視差向量的垂直分量不變。
在一些情況下,視頻譯碼器使用經精煉視差向量用于視圖間運動預測,同時視頻譯碼器使用未精煉的視差向量用于視圖間殘余預測。另外,如果經精煉視差向量是以后向視圖合成預測模式譯碼的,那么視頻譯碼器將經精煉視差向量存儲為一個PU的運動向量。在一些設計中,無論從NBDV過程導出的視圖次序索引的值如何,視頻譯碼器都始終存取基礎視圖的深度視圖分量。
高級殘余預測(ARP)是用于利用視圖之間的殘余相關的譯碼工具。在ARP中,視頻譯碼器通過在參考視圖中用于運動補償的當前視圖處對準運動信息而產生殘余預測符。另外,引入加權因數以補償視圖之間的質量差。當ARP針對一個塊經啟用時,視頻編碼器20用信號表示當前殘余與殘余預測符之間的差。在一些實施方案中,ARP可僅適用于具有等于Part_2Nx2N的分割模式的經幀間譯碼CU(即,每一CU具有僅一個PU)。ARP可應用于明度(Y)分量和色度(Cb及Cr)分量。在以下描述中,對一個塊(或像素)的操作(例如求和、減法)的應用意味著對所述塊(或像素)中的每個像素的每一分量(Y、Cb及Cr)的操作的應用。當需要區分用于明度和色度分量的過程時,用于明度分量的過程被稱作明度ARP(子PU ARP),且用于色度分量的過程被稱作色度ARP(子PU ARP)。
短語“用于時間殘余的ARP”可用以指代在當前塊具有時間運動向量(即,指示參考圖片中具有與當前圖片的POC值不同的圖片次序計數(POC)值的位置的運動向量)時ARP的使用。POC值是與每一圖片相關聯的變量,使得當相關聯圖片將從經解碼圖片緩沖器輸出時,所述POC值指示所述相關聯圖片在輸出次序中相對于同一CVS中將從經解碼圖片緩沖器輸出的其它圖片的輸出次序位置的位置。用于時間殘余的ARP在第4次JCT3V會議中的3D-HEVC標準中采用,如張等人的“CE4:用于多視圖譯碼的高級殘余預測(CE4:Advanced residual prediction for multiview coding)”(ITU-T SG 16WP 3和ISO/IEC JTC 1/SC 29/WG 11的3D視頻譯碼擴展開發聯合合作小組第4次會議:韓國仁川,2013年4月20-26日,文獻JCT3V-D0177(下文為“JCT3V-D0177”))中所提議。
圖4說明多視圖視頻譯碼中用于時間殘余(即,一個參考圖片列表中的當前參考圖片是時間參考圖片)的ARP的實例預測結構。如圖4中所示,在當前塊的預測中調用以下塊。
1.當前塊:Curr
2.通過視差向量(DV)導出的參考/基礎視圖中的參考塊:Base。
3.與通過當前塊的(時間)運動向量(標示為TMV)導出的塊Curr相同的視圖中的塊:CurrTRef。
4.與通過當前塊的時間運動向量(TMV)導出的塊Base相同的視圖中的塊:BaseTRef。此塊是使用與當前塊Curr進行比較的TMV+DV向量進行識別。
在圖4的實例中,Curr在當前圖片70中,CurrTRef在參考圖片72中,Base在參考圖片74中,且BaseTRef在參考圖片76中。
殘余預測符表示為BaseTRef-Base,其中減法運算應用于所表示像素陣列的每一像素。換句話說,殘余預測符的每一相應樣本可等于BaseTRef的相應對應樣本減去Base的相應對應樣本。將加權因數w進一步乘以殘余預測符。因此,當前塊的最終預測符表示為:CurrTRef+w*(BaseTRef-Base)。換句話說,當前塊(Curr)的最終預測符(即,最終預測性塊)的每一相應樣本是基于CurrTRef的對應相應樣本以及經加權殘余預測符的相應對應樣本的總和,即,w*(BaseTRef-Base)。下文和圖4的描述都是基于應用單向預測的假設。當延伸到雙向預測的情況時,以上步驟應用于每一參考圖片列表。
在一些實例中,在ARP中使用三個加權因數,即0、0.5和1。導致當前CU的最小速率失真成本的加權因數可被選擇為最終加權因數,且在CU層級在位流中發射對應加權因數索引(分別對應于加權因數0、1和0.5的0、1和2)。在一些實例中,一個CU中的所有PU預測共享相同加權因數。當加權因數等于0時,ARP不用于當前CU。
所提議的在解碼器側的ARP的主要程序可描述如下。首先,視頻解碼器30獲得如3D-HEVC草案文本4中指定的指向目標參考視圖的視差向量。隨后,在同一存取單元內的參考視圖的圖片中,通過視差向量定位對應塊。其次,再使用當前塊的運動信息以導出參考塊的運動信息。視頻解碼器30基于當前塊以及參考塊的參考視圖中的所導出參考圖片的同一運動向量應用用于對應塊的運動補償以導出殘余塊。
圖5是說明當前塊和參考塊之間的實例關系的概念圖。具體來說,圖5展示當前塊、對應塊和運動補償塊之間的實例關系。將參考視圖(V0)中具有與當前視圖(Vm)的參考圖片相同的POC值的參考圖片選擇為對應塊的參考圖片。第三,解碼器30將加權因數應用于殘余塊以獲得經加權殘余塊,且將經加權殘余塊的值添加到經預測樣本。
在圖5的實例中,當前塊80在時間實例T1處在視圖V1中發生。對應塊82在與當前塊80不同的視圖(即,視圖V0)中且在與當前塊80相同的時間實例(即,時間實例T1)中。視頻譯碼器可使用當前塊80的視差向量以識別對應塊82。在圖5的實例中,當前塊80是雙向預測性的。因此,當前塊80具有第一運動向量84和第二運動向量86。運動向量84指示參考圖片88中的位置。參考圖片88在視圖V1中和時間實例T0中。運動向量86指示參考圖片90中的位置。參考圖片90在視圖V0中和時間實例T3中發生。
在ARP中,視頻譯碼器可將運動向量84和運動向量86應用于對應塊82的位置以確定參考塊93和95(即,運動補償塊)的位置。參考塊93和95分別包含參考圖片92和參考圖片94的樣本或是從所述樣本內插。因為當前塊80是雙向幀間預測的,所以視頻譯碼器可基于參考塊93和95確定摻合的參考塊。摻合參考塊的每一相應樣本是參考塊93的相應對應樣本和參考塊95的相應對應樣本的加權平均。視頻譯碼器可使用當前塊80的兩個運動向量以確定第一殘余預測符和第二殘余預測符。另外,視頻譯碼器可確定第一初始預測性塊和第二初始預測性塊。第一初始預測性塊可為參考塊93和第一殘余預測符的總和。第二初始預測性塊可為參考塊95和第二殘余預測符的總和。當前塊80的最終殘余預測符的每一樣本可為第一和第二初始預測性塊的對應樣本的加權平均。
短語“用于視圖間殘余的ARP”可用以指代在當前塊具有視差運動向量(即,指示參考圖片中屬于與當前圖片的視圖不同的視圖的位置的運動向量)時ARP的使用。當ARP應用于視圖間殘余時,當前PU是使用視圖間ARP。當ARP應用于時間殘余時,當前PU是使用時間ARP。在以下描述中,如果一個參考圖片列表的對應參考是時間參考圖片且應用ARP,那么其指示為時間ARP。否則,如果用于一個參考圖片列表的對應參考是視圖間參考圖片且應用ARP,那么其指示為視圖間ARP。
類似于用于時間殘余的ARP設計,在當前PU使用視圖間參考圖片時,可啟用視圖間殘余的預測。首先,視頻譯碼器計算不同存取單元內的視圖間殘余,隨后視頻譯碼器使用計算的殘余信息來預測當前塊的視圖間殘余。此部分是在張等人的“CE4:高級殘余預測的進一步改進(CE4:Further improvements on advanced residual prediction)”(ITU-T SG 16WP 3和ISO/IEC JTC 1/SC 29/WG 11的3D視頻譯碼擴展聯合合作小組第6次會議:瑞士日內瓦,2013年10月25日-11月1日,文獻JCT3V-F0123(下文為“JCT3V-F0123”))中提出,其已采用到3D-HEVC中。
圖6是說明用于視圖間殘余的ARP的概念圖。實際上,識別三個相關塊:參考視圖中通過當前塊(由Base表示)的視差運動向量定位的參考塊;參考視圖中通過時間運動向量(mvLX)和由Base包含的參考索引(如果可用)定位的Base的參考塊(由BaseRef表示);當前視圖中通過再使用來自Base的時間運動信息產生的參考塊(由CurrRef表示),如圖6中所示。在一些實施方案中,視頻解碼器將CurrRef確定為在由BaseRef的位置坐標減視差運動向量(DMV)指示的位置,其等于由Curr的位置坐標加時間運動向量(mvLX)指示的位置。在圖6的實例中,Curr在當前圖片100中,Base是基于參考圖片102中的樣本,BaseRef是基于參考圖片104中的樣本,且CurrRef是基于參考圖片106中的樣本。
以所識別的三個塊,視頻譯碼器可將當前PU(即,Curr)的殘余信號的殘余預測符計算為不同存取單元中這兩個塊之間的差:CurrRef-BaseRef。換句話說,Curr的殘余預測符的每一相應樣本可基于CurrRef的相應對應樣本減去BaseRef的相應對應樣本。此外,視頻編碼器20可將視圖間預測符乘以如當前ARP中使用的加權因數。視頻解碼器30可執行移位運算以反轉加權因數的作用。視頻編碼器20可產生Curr的最終預測性塊以使得最終預測性塊的每一相應樣本是基于Base的相應對應樣本減去潛在地經加權殘余預測符的相應對應樣本。舉例來說,最終殘余塊的每一相應樣本可等于Base的相應對應樣本減去潛在地經加權殘余預測符的相應對應樣本。Curr的殘余的每一相應樣本可基于Curr的預測塊的相應對應樣本減去Curr的最終預測性塊的對應相應樣本。
類似于用于時間殘余的ARP,視頻譯碼器可使用雙線性濾波器以產生三個相對塊。此外,當由Base包含的時間運動向量指向當前PU(即,Curr)的第一可用時間參考圖片的不同存取單元中的參考圖片時,視頻譯碼器可首先將所述時間運動向量按比例縮放為第一可用時間參考圖片。視頻譯碼器接著可使用經按比例縮放運動向量來定位不同存取單元中的兩個塊(即,BaseRef和CurrRef)。
在張等人的“3D-CE4:用于多視圖譯碼的高級殘余預測(3D-CE4:Advanced residual prediction for multiview coding)”(ITU-T SG 16WP 3和ISO/IEC JTC 1/SC 29/WG 11的3D視頻譯碼擴展開發聯合合作小組第3次會議:瑞士日內瓦,2013年1月17-23日,文獻編號JCT3V-C0049,下文為“JCT3V-C0049”)中,以非零加權因數譯碼的PU的參考圖片可在塊之間不同。因此,可能需要存取來自參考視圖的不同圖片以產生對應塊的經運動補償塊(即,圖4中的BaseTRef)。當加權因數不等于0時,對于時間殘余,在執行對于殘余和殘余預測符產生過程兩者的運動補償之前,朝向固定圖片按比例縮放當前PU的運動向量。當ARP應用于視圖間殘余時,參考塊(即,圖4中的Base)的時間運動向量朝向固定圖片按比例縮放,然而執行用于殘余和殘余預測符產生過程的運動補償。在JCT3V-C0049中,對于兩種情況(即,時間殘余或視圖間殘余),將所述固定圖片界定為每一參考圖片列表的第一可用時間參考圖片。當經解碼的運動向量并不指向固定圖片時,首先按比例縮放經解碼運動向量,且接著將其用以識別CurrTRef和BaseTRef。用于ARP的此參考圖片稱為目標ARP參考圖片。在當前切片(即,含有當前塊的切片)是B切片時,目標ARP參考圖片與參考圖片列表相關聯。因此,可使用兩個目標ARP參考圖片。
視頻譯碼器可執行針對目標ARP參考圖片的可用性檢查。舉例來說,將與參考圖片列表X(其中X是0或1)相關聯的目標ARP參考圖片表示為“RpRefPicLX”,且將視圖中具有等于從NBDV過程導出的視圖次序索引的視圖次序索引且具有RpRefPicLX的相同POC值的圖片表示為“RefPicInRefViewLX”。在以下條件中的一者是假時,針對參考圖片列表X停用ARP:
-RpRefPicLX不可用。
-RefPicInRefViewLX未存儲在經解碼圖片緩沖器中。
-RefPicInRefViewLX未包含在通過來自NBDV過程的視差向量或當前塊的(即,與其相關聯)DMV而定位的對應塊(即,圖4和圖6中的Base)的參考圖片列表中的任一者中。
在一些實施方案中,當應用ARP時,視頻譯碼器當產生殘余和殘余預測符時始終使用雙線性濾波器。即,ARP過程中涉及的排除當前塊的三個塊是使用雙線性濾波器產生(例如,圖4中的Base、BaseTRef和CurrTRef以及圖6中的Base、BaseRef和CurrRef)。
在HEVC版本1中,為了得到一個經幀間譯碼PU的預測性塊,需要兩個步驟:
1)以HEVC 8分支/6分支濾波器的可能的分數內插以確定具有增加的位深度的中間預測信號,(可在HEVC版本1的子條款8.5.3.3.3中找到細節)。
2)經加權樣本預測過程,其中調用使中間預測信號移位回到原始位深度精度和削減操作以確保不存在溢出(參見子條款8.5.3.3.4)。
一般來說,濾波器的“分支”的數目對應于用以確定濾波器的輸出值的樣本的數目。
在3D-HEVC草案文本4中,當應用ARP時,視頻解碼器使用類似于H.264/AVC規范的經界定雙線性濾波過程。供ARP與一起使用的3D-HEVC草案文本4中界定的雙線性濾波過程導致與輸入信號相同的位深度中的中間預測信號,即,3D-HEVC譯碼工具性能評估中使用的共同測試條件(CTC)下的8位。如3D-HEVC草案文本4的子條款I.8.5.3.3.7.2中所描述,視頻解碼器使用以下等式執行雙線性濾波過程:
predPartLX[x][y]=(refPicLX[xA][yA]*(8-xFrac)*(8-yFrac)+
refPicLX[xB][yB]*(8-yFrac)*xFrac+
refPicLX[xC][yC]*(8-xFrac)*yFrac+
refPicLX[xD][yD]*xFrac*yFrac)>>6 (I-238)
然而,濾波過程隨后,調用如HEVC版本1的子條款8.5.3.3.4中的經加權樣本預測過程,且右移操作(例如,CTC下為6)造成錯誤預測值。以下是經加權樣本預測過程中的移位操作的一些實例。如下界定最終預測信號predSamples:
●對于具有等于0的weighted_pred_flag的P切片中的單向預測塊,以下適用:
predSamples[x][y]=Clip3(0,(1<<bitDepth)-1,
(predSamplesLX[x][y]+offset1)>>shift1)
其中predSamplesLX指示作為雙線性濾波過程的輸出的預測信號,且shift1設定成等于(14-bitDepth)且當shift1不等于0時offset1等于1<<(shift1-1)。最終預測信號預期在CTC情況中具有6的右移位以使濾波器系數的量值的總和正規化。
●對于具有等于0的weighted_bipred_flag的B切片中的雙向預測塊,以下適用:
predSamples[x][y]=Clip3(0,(1<<bitDepth)-1,
(predSamplesL0[x][y]+predSamplesL1[x][y]+offset2)>>shift2)(8-239)
在上方等式中,shift2設定成等于(15-bitDepth)且offset2等于1<<(shift2-1)。最終預測信號預期在CTC情況中具有7的右移位。3D-HEVC草案文本4的雙線性內插是以類似于如等式I-238中的不可分離的濾波器的方式完成。
3D-HEVC草案文本4的當前設計具有若干問題。舉例來說,3D-HEVC草案文本4的設計保持雙線性運動補償數據的錯誤精度,即當輸入視頻是8位時的8位。在另一實例中,用于3D-HEVC草案文本4的參考軟件至少針對單向預測情況削減所有中間數據,因為當前實施方案重新使用HEVC內插功能。這導致針對單向預測ARP每像素削減操作數目的三倍,因為以內插過程產生三個預測塊。以下等式描述所述削減:
predSamplesLXL[x][y]=clipy(predSamplesLXL[x][y])+
((clipy(rpSamplesLXL[x][y])-clipy(rpRefSamplesLXL[x][y]))>>shiftVal)(I-227)
此增加數目的削減操作可減慢編碼和解碼速度和/或不必要的降低經解碼圖片的視覺質量。
以下技術可獨立地或組合地實施,如所屬領域的技術人員將了解。確切地說,實例可包含以下方面中的任一者以解決上述問題或另外改善譯碼性能。更具體來說,實例可包含改善ARP的性能的以下方式中的一或多者。
在涉及ARP的一個實例技術中,可分離的雙線性內插濾波器經配置以通過改變系數而使用HEVC版本1的HEVC運動補償內插方案,以使得每一階段的濾波器的系數(a,b)的總和加起來等于64,與HEVC版本1中使用的其它內插濾波器的總和相同。在此實例中,(a,b)可等于(x*8,(8-x)*8),其中整數x等于在0到8的范圍內的值。
術語“可分離的濾波器”應用于可寫成兩個或更多個濾波器的乘積的濾波器。相比之下,不可分離的濾波器無法寫成兩個或更多個濾波器的乘積。在本發明的一些技術中使用的雙線性內插濾波器的情況下,雙線性內插濾波器是“可分離的”,因為應用第一濾波器以確定在主要子整數位置的樣本的值。主要子整數位置從整數像素位置嚴格地垂直或水平。將第二濾波器應用于在主要子整數位置的樣本以確定在輔助子整數位置的樣本的值。輔助子整數位置并不從整數像素位置嚴格地垂直或水平。在此上下文中,術語“階段”指代子整數位置。
當應用ARP時可分離的雙線性內插濾波器的使用可減少當應用雙線性內插濾波器時執行的削減操作的數目。此外,因為內插濾波器中針對每一子整數位置(即,階段)使用的系數共計64,所以當應用ARP時使用的雙線性內插濾波器可允許用于運動補償的基礎HEVC中使用的雙線性內插濾波器硬件的再使用。
因此,在單向ARP實例中,視頻編碼器20可基于視頻數據的當前圖片中的當前塊的運動向量確定第一參考圖片中的第一參考塊的位置。在圖4的實例中,第一參考塊標記為CurrTRef。在圖6的實例中,第一參考塊標記為Base。視頻編碼器20將可分離的雙線性內插濾波器應用于第一參考圖片的樣本以確定第一參考塊的樣本。此外,在此單向ARP實例中,視頻編碼器20確定第二參考圖片中的第二參考塊的位置。在圖4的實例中,第二參考塊標記為BaseTRef。在圖6的實例中,第二參考塊標記為CurrRef。此外,在此實例中,視頻編碼器20可將可分離的雙線性內插濾波器應用于第一參考圖片的樣本以確定第一參考塊的樣本。視頻編碼器20將相同或不同的可分離的雙線性內插濾波器應用于第二參考圖片的樣本以確定第二參考塊的樣本。視頻編碼器20將相同或不同的可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本。在圖4的實例中,第三參考塊標記為Base。在圖6的實例中,第三參考塊標記為BaseRef。
在此實例中,視頻編碼器20確定預測性塊。預測性塊的每一相應樣本可等于第一參考塊的相應樣本減去相應殘余預測符樣本。在此實例中,相應殘余預測符樣本可等于加權因數(例如,非零加權因數)乘以第二參考塊的相應樣本與第三參考塊的相應樣本之間的差。第一參考塊的相應樣本、第二參考塊的相應樣本以及第三參考塊的相應樣本在第一、第二和第三參考塊內對應于預測性塊的相應樣本的位置的位置處。另外,在此實例中,視頻編碼器20確定殘余塊。在此實例中,殘余塊的每一相應樣本等于當前塊的相應樣本與預測性塊的相應樣本之間的差。當前塊的相應樣本和預測性塊的相應樣本對應于殘余塊的相應樣本的位置。視頻編碼器20在位流中包含表示殘余塊的數據。
在類似實例中,視頻解碼器30基于視頻數據的當前圖片中的當前塊的運動向量確定第一參考圖片中的第一參考塊的位置。視頻解碼器30可將可分離的雙線性內插濾波器應用于第一參考圖片的樣本以確定第一參考塊的樣本。在圖4的實例中,第二參考塊標記為CurrTRef。在圖6的實例中,第二參考塊標記為Base。另外,在此實例中,視頻解碼器30確定第二參考圖片中的第二參考塊的位置。在圖4的實例中,第二參考塊標記為BaseTRef。在圖6的實例中,第三參考塊標記為CurrRef。在此實例中,視頻解碼器30將可分離的雙線性內插濾波器應用于第二參考圖片的樣本以確定第二參考塊的樣本。視頻解碼器30將可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本。在圖4的實例中,第三參考塊標記為Base。在圖6的實例中,第三參考塊標記為BaseRef。
此外,在此實例中,視頻解碼器30確定預測性塊。預測性塊的每一相應樣本等于第一參考塊的相應樣本加相應殘余預測符樣本。在此實例中,相應殘余預測符樣本等于加權因數乘以第二參考塊的相應樣本與第三參考塊的相應樣本之間的差。第一參考塊的相應樣本、第二參考塊的相應樣本以及第三參考塊的相應樣本在第一、第二和第三參考塊內對應于預測性塊的相應樣本的位置的位置處。在此實例中,視頻解碼器30從位流獲得表示殘余塊的數據。視頻解碼器30部分地基于殘余塊和預測性塊而重構當前圖片的譯碼塊。
在一些實例中,根據上文提供的視頻編碼器20和視頻解碼器30的實例,每一階段的可分離的雙線性內插濾波器的系數的總和等于64。在此些實例中,可分離的雙線性內插濾波器的系數(a,b)的總和等于(x*8,(8-x)*8),其中x等于在0到8的范圍內的值。
此外,根據上文提供的視頻編碼器20和視頻解碼器30的實例,視頻編碼器20和視頻解碼器30可使用ARP用于時間殘余。在其中視頻編碼器20和視頻解碼器30使用ARP用于時間殘余的實例中,當前圖片(即,圖4中的當前圖片70)在第一視圖(即,圖4中的V0)中。第二參考圖片(即,參考圖片76)和第三參考圖片(即,參考圖片74)都在不同于第一視圖的第二視圖(即,圖4中的V1)中。此外,在此實例中,當前塊的運動向量是當前塊的時間運動向量(即,TMV)。第三參考圖片的POC值(即,圖4中的T0)等于當前圖片的POC值。在此實例中,視頻譯碼器(例如,視頻編碼器20和/或視頻解碼器30)可確定第一參考圖片(即,參考圖片72)。第一參考圖片的POC值(即,T1)等于第二參考圖片的POC值。視頻譯碼器可基于當前塊的運動信息的參考索引確定第一參考圖片。第一參考圖片的POC值和第二參考圖片的POC值不同于當前圖片的POC值。此外,在此實例中,視頻譯碼器基于當前塊的視差向量(即,DV)確定第三參考塊(即,Base)的位置。在此實例中,視頻譯碼器確定第二參考塊(即,BaseTRef)的位置以使得第二參考塊的位置由當前塊的時間運動向量和當前塊的視差向量的總和指示。
在其中視頻編碼器20和視頻解碼器30使用ARP用于視圖間殘余的另一實例中,當前圖片(例如,圖6中的當前圖片100)和第二參考圖片(例如,圖6中的參考圖片106)都在第一視圖(例如,圖6中的V0)中。在此實例中,第三參考圖片(例如,圖6中的參考圖片102)在不同于第一視圖的第二視圖(例如,圖6中的V1)中。此外,在此實例中,當前塊的運動向量是當前塊的視差運動向量。第二參考圖片的POC值(例如,圖6中的T1)不同于當前圖片的POC值(例如,圖6中的T0)。第三參考圖片的POC值不同于當前圖片的POC值(例如,圖6中的T0)且等于第二參考圖片的POC值。在此實例中,視頻譯碼器(例如,視頻編碼器20和/或視頻解碼器30)基于當前塊的視差運動向量確定第一參考塊(例如,圖6中的Base)。第一參考圖片具有與當前圖片相同的POC值(例如,圖6中的T0)且在第二視圖(例如,圖6中的V1)中。在此實例中,視頻譯碼器確定第三參考塊(例如,圖6中的BaseRef)的位置以使得第三參考塊的位置由第一參考塊的時間運動向量指示。此外,在此些實例中,視頻譯碼器通過再使用參考塊的時間運動向量確定第二參考塊的位置來確定第二參考塊(例如,圖6中的CurrRef)的位置。舉例來說,在一些實例中,視頻譯碼器可確定第二參考塊的位置以使得第二參考塊的位置由第三參考塊(例如,圖6中的BaseRef)的位置坐標減去當前塊的視差運動向量而指示。在一些實例中,視頻譯碼器可確定第二參考塊的位置以使得第二參考塊的位置由第一參考塊的時間運動向量的位置坐標指示。
在涉及ARP的另一實例技術中,無論是使用可分離的雙線性內插濾波器還是如3D-HEVC草案文本4中使用不可分離的雙線性內插濾波器,運動補償的結果都可以如下方式來布置:結果可通過(14-bitDepth)的右移位而經正規化,以與經加權樣本預測過程對準,例如,如HEVC版本1的子條款8.5.3.3.4中的等式(8-239)。在此實例中,bitDepth是當前分量的位深度。
在一個替代的實例中,如果使用可分離的雙線性濾波器,那么每一階段的濾波器的系數(a,b)合計等于64。替代地,每一階段的濾波器的系數(a,b)合計等于8,然而,在第二粗糙濾波(垂直)之后的移位值可能需要改變到較小值,此處移位值從6改變到0。在另一替代實例中,如果如3D-HEVC草案文本4中使用不可分離的雙線性濾波器,那么更改內插以使得使用(bitDepth-8)的右移位而不是如3D-HEVC草案文本4中的6的右移位。
在可涉及在ARP期間用于運動補償中間信號的相對高位深度的包含以上實例的一些實例中,無論使用單向預測還是雙向預測,針對那些中間信號都不執行削減。舉例來說,可僅在HEVC版本1中的經加權樣本預測過程中執行削減操作。替代地,為了以16位的范圍保持作為潛在地在基于運動補償信號的兩個雙線性內插之間的減法的殘余預測符,殘余預測符的削減可應用于使經削減的數據處于[-215,215-1]的范圍內。所述兩個值-215、215-1指示在削減之后的最小值和最大值(包含性),因此唯一地界定削減函數。
多視圖視頻譯碼中的照明補償(IC)用于補償不同視圖之間的照明差異,因為每一相機可具有對光源的不同曝光。通常,使用權重因數和/或偏移量來補償不同視圖中的經譯碼塊與預測塊之間的差。所述參數可或可不顯式地發射到視頻解碼器。
根據劉等人的“3D-CE2.h:用于視圖間預測的照明補償的結果(3D-CE2.h:Results of Illumination compensation for inter-view prediction)”(ITU-T SG 16WP 3和ISO/IEC JTC 1/SC 29/WG 11的3D視頻譯碼擴展開發聯合合作小組第2次會議:中國上海2012年10月13-19日,文獻JCT3V-B0045(下文為“JCT3V-B0045”))中所提議的設計,在CU層級用信號表示照明補償,且通過如參考塊的樣本的當前塊的相鄰樣本導出參數。隨后,改變模式的信令,如井貝(Ikai)等人的“3D-CE5.h:用于照明補償的剖析相依性的移除(3D-CE5.h:Removal of parsing dependency for illumination compensation)”(ITU-T SG 16WP 3和ISO/IEC JTC 1/SC 29/WG 11的3D視頻譯碼擴展聯合合作小組第4次會議:韓國仁川,2013年4月20-26日,文獻JCT3V-D0060(下文為“JCT3V-D0060”))中所提議。
引入照明補償來改進從視圖間參考圖片預測的塊的譯碼效率。因此,照明補償可僅應用于通過視圖間參考圖片預測的塊。因此,對于當前PU,在頂部相鄰列和左邊相鄰列中的其相鄰樣本連同參考塊的對應相鄰樣本是用于線性模型的輸入參數。所述線性模型可通過最小平方解而導出按比例縮放因數a和偏移b。參考視圖中的對應相鄰樣本是由當前PU的視差運動向量識別,如圖7中所示。
在從視圖間參考圖片的運動補償之后,將線性模型應用于預測塊的每一值以更新當前PU的預測信號。進一步以a經按比例縮放且進一步以b相加預測塊的每一值,如圖7中所示。照明補償中的AMVP和合并模式可在切片層級自適應地經啟用或停用,以便減少額外位和不必要的計算。
圖7是說明用于照明補償(IC)參數的導出的實例相鄰樣本的概念圖。在圖7的實例中,非基礎視圖圖片120包含當前PU 122。視頻譯碼器使用當前PU 122的視差運動向量以確定基礎視圖圖片126中的參考PU 124。視頻譯碼器基于當前PU 122的相鄰樣本和參考PU 124的相鄰樣本確定按比例縮放因數a和偏移b。在圖7的實例中,相鄰樣本展示為由正方形封閉的圓。對于當前PU 122的預測性塊的每一相應樣本,視頻譯碼器可將相應樣本設定為等于參考PU 124的相應對應樣本由按比例縮放因數a按比例縮放加上偏移b的值。
在3D-HEVC草案文本4中,當針對雙向預測PU啟用IC時,當與HEVC相比時每個像素需要四次額外削減。具體地說,對于每一預測方向,將運動補償樣本和照明補償樣本兩者削減到[0,(1<<BitDepth)-1],其中BitDepth是當前分量的位深度。
將PredMcLX[x]和IcPredLX[x]分別表示為從預測方向X在位置x處的運動補償樣本和IC樣本,其中X等于0或1。分別將aLX和bLX表示為預測方向X中的當前PU的IC參數。將shift1設定為等于14-BitDepth,將offset1設定為等于1<<(shift1-1),將shift2設定為等于15-BitDepth,且將offset2設定為等于1<<(shift2-1)。將Pred[x]表示為在位置x處的最終預測樣本。Pred[x]可根據以下步驟產生:
1.步驟1:運動補償樣本的削減。
PredMcLX[x]=clip3(0,(1<<BitDepth)-1,(PredMcLX[x]+offset1)>>shift1) (1)
2.步驟2:照明補償樣本的產生和削減。
IcPredLX[x]=aLX*PredMcLX[x]+bLX (2)
IcPredLX[x]=clip3(0,(1<<BitDepth)-1,IcPredMcLX[x]) (3)
3.步驟3:在經加權樣本預測過程之前設定信號(編輯批注以使得等式(5)和(6)看起來與等式(7)和(8)相同)。
PredLX[x]=IcPredMcLX[x] (4)
4.經加權樣本預測過程。
a.如果當前PU是從方向X單向預測,則
Pred[x]=clip3(0,(1<<BitDepth)-1,(PredL0[x]+offset1)>>shift1) (5)
b.如果當前PU是雙向預測,則
Pred[x]=clip3(0,(1<<BitDepth)-1,(IcPredL0[x]+IcPredL1[x]+offset2)>>shift2) (6)
在以上步驟中,步驟1和步驟2兩者中針對每一預測方向需要一個削減操作,且在步驟3中針對雙向預測情況需要一個削減操作。總之,當IC經啟用時,針對雙向預測和單向預測分別需要五次削減和兩次削減。
然而,在雙向預測情況中,因為Pred[x]在步驟4中經削減到[0,(1<<BitDepth)-1],所以不必在步驟1和步驟2中另外削減中間結果(即,運動補償樣本和照明補償樣本)到[0,(1<<BitDepth)-1]。同樣,在單向預測情況中,因為IcPredLX[x]在步驟2中經削減到[0,(1<<BitDepth)-1],所以不必在步驟1中另外削減運動補償樣本。
當IC停用時,Pred[x]可產生為:
1.如果當前PU是從方向X單向預測,則
Pred[x]=clip3(0,(1<<BitDepth)-1,(PredL0[x]+offset1)>>shift1) (7)
2.如果當前PU是雙向預測,則
Pred[x]=clip3(0,(1<<BitDepth)-1,(PredL0[x]+PredL1[x]+offset2)>>shift2) (8)
因此,當IC停用時,針對雙向預測和單向預測兩者需要僅一個削減操作。
從以上分析,當是經啟用時需要多達四次額外削減操作,這是極復雜的且不必要的。每一削減操作需要至少兩次比較,且針對每一例如8x8塊,比較的次數是192。因此,在IC中,執行了不必要次數的削減。舉例來說,在雙向預測IC的情況下為四次額外削減。此增加次數的削減操作可減慢編碼和解碼速度。
本發明的特定技術減少IC中涉及的削減操作。舉例來說,根據本發明的技術,在IC中,移除了在步驟1和2、等式(1)和(3)中的所有以上所提到的削減。在另一實例中,在IC中,如等式(1)的步驟1中應用了應用于運動補償信號的削減操作。然而,在此實例中,應用了如在步驟2等式(3)中對IC信號的削減操作,以使得IC信號在范圍[0,216-1]內。所述兩個值0、216-1指示在削減之后的最小值和最大值(包含性),且因此唯一地界定削減函數。
為了停用IC對經加權預測的應用,在經加權預測過程的一些實例中,可檢查IC是否經啟用,以使得經加權預測不應用于IC補償塊。替代地,當隱式經加權預測以不等于(1,0)、(0,1)或(0.5,0.5)的權重(例如,由等于1的weightedPredFlag指示)應用時可強加約束,以使得針對整個切片停用IC,即,slice_ic_enable_flag將等于1。
圖8是說明可實施本發明的技術的實例視頻編碼器20的框圖。圖8是出于解釋的目的而提供,且不應被視為將技術限制為本發明中所大致例示和描述。出于解釋的目的,本發明描述在HEVC譯碼的上下文中的視頻編碼器20。然而,本發明的技術可以適用于其它譯碼標準或方法。
在圖8的實例中,視頻編碼器20包含預測處理單元200、殘余產生單元202、變換處理單元204、量化單元206、逆量化單元208、逆變換處理單元210、重構單元212、濾波器單元214、經解碼圖片緩沖器216以及熵編碼單元218。預測處理單元200包含幀間預測處理單元220和幀內預測處理單元226。幀間預測處理單元220包含運動估計單元222和運動補償單元224。在其它實例中,視頻編碼器20可包含更多、更少或不同的功能組件。
視頻編碼器20接收視頻數據。視頻數據存儲器201存儲待由視頻編碼器20的組件編碼的視頻數據。存儲在視頻數據存儲器201中的視頻數據可例如從視頻源18獲得。經解碼圖片緩沖器216可為存儲參考視頻數據用于由視頻編碼器20在對視頻數據進行編碼過程中使用(例如,在幀內或幀間譯碼模式中)的參考圖片存儲器。視頻數據存儲器201和經解碼圖片緩沖器216可由多種存儲器裝置中的任一者形成,例如動態隨機存取存儲器(DRAM),包含同步DRAM(SDRAM)、磁阻式RAM(MRAM)、電阻式RAM(RRAM)或其它類型的存儲器裝置。視頻數據存儲器201和經解碼圖片緩沖器216可由相同存儲器裝置或單獨的存儲器裝置提供。在各種實例中,視頻數據存儲器201可與視頻編碼器20的其它組件一起在芯片上,或相對于所述組件在芯片外。
視頻編碼器20可對視頻數據的圖片的切片中的每個CTU進行編碼。因此,對于切片的每一相應CTU,視頻編碼器20產生表示相應CTU的相應經編碼數據。CTU中的每一者可具有大小相等的明度譯碼樹塊(CTB)和圖片的對應CTB。作為對CTU進行編碼的一部分,預測處理單元200可執行四叉樹分割以將CTU的CTB劃分為逐漸更小的塊。較小塊可為CU的譯碼塊。例如,預測處理單元200可將CTU的CTB分割成四個大小相等的子塊,將子塊中的一或多者分割成四個大小相等的子子塊等。
視頻編碼器20可對CTU的CU進行編碼以產生CU的經編碼表示(即,經譯碼的CU)。換句話說,對于CTU的每一相應的CU,視頻編碼器20產生表示所述相應的CU的相應經編碼數據。作為對CU進行編碼的一部分,預測處理單元200可以在CU的一或多個PU當中分割CU的譯碼塊。因此,每一PU可具有明度預測塊和對應的色度預測塊。視頻編碼器20和視頻解碼器30可支持具有各種大小的PU。CU的大小可指CU的明度譯碼塊的大小并且PU的大小可指PU的明度預測塊的大小。假定特定CU的大小為2Nx2N,視頻編碼器20及視頻解碼器30可支持用于幀內預測的2Nx2N或NxN的PU大小,及用于幀間預測的2Nx2N、2NxN、Nx2N、NxN或類似大小的對稱PU大小。視頻編碼器20以及視頻解碼器30還可以支持用于幀間預測的2NxnU、2NxnD、nLx2N以及nRx2N的PU大小的非對稱分割。
幀間預測處理單元220可通過對CU的每一PU執行幀間預測產生用于PU的預測性數據。PU的預測性數據可包含PU的預測性塊和PU的運動信息。取決于PU是在I切片中、P切片中或B切片中,幀間預測處理單元220可對CU的PU執行不同操作。在I切片中,所有PU都是經幀內預測。因此,如果PU是在I切片中,則幀間預測處理單元220并不對PU執行幀間預測。
如果PU是在P切片中,則運動估計單元222可以對用于PU的參考區域搜索參考圖片列表(例如,“RefPicList0”)中的參考圖片。用于PU的參考區可為參考圖片內含有最接近地對應于PU的預測塊的樣本的區。運動估計單元222可產生指示含有PU的參考區的參考圖片的RefPicList0中的位置的參考索引。另外,運動估計單元222可產生指示PU的譯碼塊與和參考區相關聯的參考位置之間的空間位移的運動向量。舉例來說,運動向量可以是提供從當前圖片中的坐標到參考圖片中的坐標的偏移的二維向量。運動估計單元222可將參考索引及運動向量作為PU的運動信息輸出。運動補償單元224可基于由PU的運動向量指示的參考位置處的實際或內插樣本產生PU的預測性塊。
如果PU是在B切片中,則運動估計單元222可以對PU執行單向預測或雙向預測。為了對PU執行單向預測,運動估計單元222可以搜索RefPicList0的參考圖片,或用于PU的參考區域的第二參考圖片列表(RefPicList1)。運動估計單元222可以將指示含有參考區的參考圖片的RefPicList0或RefPicList1中的位置的參考索引、指示PU的預測塊與相關聯于參考區的參考位置之間的空間移位的運動向量以及指示參考圖片是在RefPicList0中或在RefPicList1中的一或多個預測方向指示符輸出為PU的運動信息。運動補償單元224可以至少部分基于由PU的運動向量指示的參考位置處的實際樣本或經內插樣本來產生PU的預測性塊。
為了對PU執行雙向幀間預測,運動估計單元222可在用于PU的參考區的RefPicList0中搜索參考圖片,并且還可在用于PU的另一參考區的RefPicList1中搜索參考圖片。運動估計單元222可產生指示含有參考區的參考圖片的RefPicList0及RefPicList1中的位置的參考索引。另外,運動估計單元222可產生指示與參考區相關聯的參考位置與PU的預測塊之間的空間移位的運動向量。PU的運動信息可包含PU的參考索引和運動向量。運動補償單元224可至少部分基于在由PU的運動向量指示的參考位置處的實際或內插樣本產生PU的預測性塊。
幀內預測處理單元226可通過對PU執行幀內預測來產生PU的預測性數據。PU的預測性數據可包含PU的預測性塊和各種語法元素。幀內預測處理單元226可對I切片、P切片以及B切片中的PU執行幀內預測。
為了對PU執行幀內預測,幀內預測處理單元226可使用多個幀內預測模式產生PU的預測性塊的多個集合。當使用特定幀內預測模式執行幀內預測時,幀內預測處理單元226可使用來自相鄰塊的樣本的特定集合產生PU的預測性塊。假定對于PU、CU及CTU采用從左到右、從上到下的編碼次序,相鄰塊可在PU的預測塊的上方、右上方、左上方或左方。幀內預測處理單元226可使用各種數目的幀內預測模式,例如,33個定向幀內預測模式。在一些實例中,幀內預測模式的數目可取決于PU的預測塊的大小。
預測處理單元200可從用于PU的由幀間預測處理單元220產生的預測性數據或用于PU的由幀內預測處理單元226產生的預測性數據當中選擇用于CU的PU的預測性數據。在一些實例中,預測處理單元200基于預測性數據集合的速率/失真量度選擇CU的PU的預測性數據。所選預測性數據的預測性塊在本文中可被稱作所選預測性塊。
預測處理單元200可執行ARP以產生PU的預測性塊。根據本發明的實例技術,預測處理單元200基于當前圖片中的當前PU的運動向量確定第一參考圖片中的第一參考塊的位置。此第一參考塊可為由運動補償單元224確定的預測性塊。在此實例中,預測處理單元200確定第二參考圖片中的第二參考塊的位置。此外,在此實例中,預測處理單元200將可分離的雙線性內插濾波器應用于第二參考圖片的樣本以確定第二參考塊的樣本。另外,在此實例中,預測處理單元200將可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本。在此實例中,預測處理單元200確定預測性塊。預測性塊的每一相應樣本等于第一參考塊的相應樣本減去相應殘余預測符樣本。在此實例中,相應殘余預測符樣本等于加權因數乘以第二參考塊的相應樣本與第三參考塊的相應樣本之間的差。第一參考塊的相應樣本、第二參考塊的相應樣本以及第三參考塊的相應樣本在第一、第二和第三參考塊內對應于預測性塊的相應樣本的位置的位置處。
殘余產生單元202可基于CU的譯碼塊和CU的PU的選定預測性塊而產生CU的殘余塊。舉例來說,殘余產生單元202可基于CU的明度、Cb和Cr譯碼塊以及CU的PU的選定預測性明度、Cb和Cr塊而產生CU的明度、Cb和Cr殘余塊。在一些實例中,殘余產生單元202可產生CU的殘余塊以使得殘余塊中的每一樣本具有等于CU的譯碼塊中的樣本與CU的PU的對應所選預測性塊中的對應樣本之間的差的值。
變換處理單元204可執行四叉樹分割以將CU的殘余塊分割成CU的TU的變換塊。因此,TU可具有明度變換塊和兩個對應的色度變換塊。CU的TU的變換塊的大小和位置可以或可不基于CU的PU的預測塊的大小和位置。
變換處理單元204可以通過將一或多個變換應用到TU的變換塊而產生用于CU的每一TU的變換系數塊。變換處理單元204可將各種變換應用于TU的變換塊。例如,變換處理單元204可以將離散余弦變換(DCT)、定向變換或概念上類似的變換應用于變換塊。在一些實例中,變換處理單元204不將變換應用于變換塊。在此類實例中,變換塊可被視作變換系數塊。
量化單元206可以量化變換系數塊中的變換系數。量化過程可減少變換系數中的一些或全部的位深度。舉例來說,n位變換系數可在量化期間舍入到m位變換系數,其中n大于m。量化單元206可基于CU的量化參數(QP)值量化CU的TU的變換系數塊。視頻編碼器20可通過調整用于CU的QP值而調整應用于CU的變換系數塊的量化程度。量化可能使得信息丟失,因此經量化的變換系數可以具有比原始變換系數更低的精度。
逆量化單元208和逆變換處理單元210可分別將逆量化和逆變換應用于變換系數塊,以從所述變換系數塊重構殘余塊。重構單元212可以將經重構的殘余塊添加到來自由預測處理單元200產生的一或多個預測性塊的對應樣本,以產生TU的經重構變換塊。通過以此方式重構CU的每一TU的變換塊,視頻編碼器20可重構CU的譯碼塊。
濾波器單元214可執行一或多個解塊操作來減少CU的譯碼塊中的成塊假象。經解碼圖片緩沖器216可在濾波器單元214對經重構的譯碼塊執行一或多個解塊操作之后存儲經重構的譯碼塊。幀間預測處理單元220可使用含有經重構譯碼塊的參考圖片來對其它圖片的PU執行幀間預測。另外,幀內預測處理單元226可使用經解碼圖片緩沖器216中的經重構譯碼塊來對與CU處于相同圖片中的其它PU執行幀內預測。
熵編碼單元218可以從視頻編碼器20的其它功能組件接收數據。例如,熵編碼單元218可以從量化單元206接收變換系數塊,并且可以從預測處理單元200接收語法元素。熵編碼單元218可以對所述數據執行一或多個熵編碼操作以產生經熵編碼的數據。例如,熵編碼單元218可以對數據執行上下文自適應可變長度譯碼(CAVLC)操作、CABAC操作、可變到可變(V2V)長度譯碼操作、基于語法的上下文自適應二進制算術譯碼(SBAC)操作、概率區間分割熵(PIPE)譯碼操作、指數哥倫布編碼操作或另一類型的熵編碼操作。視頻編碼器20可輸出包含由熵編碼單元218產生的經熵編碼數據的位流。
圖9是說明可實施本發明的技術的實例視頻解碼器30的框圖。圖9是出于解釋的目的而提供,且并不將技術限制為本發明中所大致例示及描述的。出于解釋的目的,本發明描述在HEVC譯碼的背景下的視頻解碼器30。然而,本發明的技術可以適用于其它譯碼標準或方法。
在圖9的實例中,視頻解碼器30包含經譯碼圖片緩沖器250、熵解碼單元252、預測處理單元254、逆量化單元256、逆變換處理單元258、重構單元260、濾波器單元262以及經解碼圖片緩沖器264。預測處理單元254包含運動補償單元266和幀內預測處理單元268。在其它實例中,視頻解碼器30可包含更多、更少或不同的功能組件。
CPB 250接收且存儲位流的經編碼視頻數據(例如,NAL單元)。存儲在CPB 250中的視頻數據可例如從信道16獲得,例如,從例如相機等局部視頻源、經由視頻數據的有線或無線網絡通信或通過存取物理數據存儲媒體。CPB 250可形成存儲來自經編碼視頻位流的經編碼視頻數據的視頻數據存儲器。經解碼圖片緩沖器264可為參考圖片存儲器,其存儲用于通過視頻解碼器30(例如)以幀內或幀間譯碼模式對視頻數據進行解碼的參考視頻數據。CPB 250和經解碼圖片緩沖器264可由多種存儲器裝置中的任一者形成,例如,動態隨機存儲器(DRAM)(包含同步DRAM(SDRAM))、磁阻式RAM(MRAM)、電阻式RAM(RRAM)或其它類型的存儲器裝置。CPB 250和經解碼圖片緩沖器264可由相同存儲器裝置或單獨的存儲器裝置提供。在各種實例中,CPB 250可與視頻解碼器30的其它組件一起在芯片上,或相對于那些組件在芯片外。
熵解碼單元252可從CPB 250接收NAL單元,并剖析NAL單元以從位流獲得語法元素。熵解碼單元252可對NAL單元中的經熵編碼的語法元素進行熵解碼。預測處理單元254、逆量化單元256、逆變換處理單元258、重構單元260和濾波器單元262可基于從位流獲得的語法元素而產生經解碼視頻數據。
位流的NAL單元可包含經譯碼切片的NAL單元。作為解碼位流的部分,熵解碼單元252可對來自經譯碼切片NAL單元的語法元素進行熵解碼。經譯碼切片中的每一者可包含切片標頭以及切片數據。切片標頭可以含有關于切片的語法元素。
除了從位流獲得語法元素之外,視頻解碼器30可對CU執行解碼操作。通過對CU執行解碼操作,視頻解碼器30可重構CU的譯碼塊。作為對CU執行解碼操作的部分,逆量化單元256可逆量化(即,解量化)CU的TU的系數塊。逆量化單元256可使用TU的CU的QP值來確定量化的程度,及同樣逆量化單元256將應用的逆量化的程度。即,可通過調整當量化變換系數時所使用的QP的值來控制壓縮比,即用以表示原始序列以及經壓縮的序列的位的數目的比率。壓縮比還可取決于所采用的熵譯碼的方法。
在逆量化單元256逆量化系數塊之后,逆變換處理單元258可以將一或多個逆變換應用于系數塊以便產生TU的殘余塊。例如,逆變換處理單元258可以將逆DCT、逆整數變換、逆卡忽南-拉維(Karhunen-Loeve)變換(KLT)、逆旋轉變換、逆定向變換或另一逆變換應用于變換系數塊。
如果使用幀內預測對PU進行編碼,那么幀內預測處理單元268可執行幀內預測以產生用于PU的預測性塊。舉例來說,幀內預測處理單元268可執行幀內預測以產生PU的明度、Cb及Cr預測性塊。幀內預測處理單元268可使用幀內預測模式以基于空間相鄰PU的預測塊產生PU的預測性塊。幀內預測處理單元268可基于從位流獲得的一或多個語法元素確定用于PU的幀內預測模式。
預測處理單元254可基于從位流提取的語法元素來構造第一參考圖片列表(RefPicList0)及第二參考圖片列表(RefPicList1)。此外,如果PU是使用幀間預測經編碼,那么運動補償單元254可基于由熵解碼單元252從位流獲得的語法元素而確定PU的運動信息。運動補償單元266可以基于PU的運動信息確定用于PU的一或多個參考區。運動補償單元266可基于在用于PU的所述一或多個參考塊處的樣本而產生PU的預測性塊。舉例來說,運動補償單元266可以基于PU的所述一或多個參考塊的樣本產生PU的明度、Cb及Cr預測性塊。
預測處理單元254可執行ARP以確定PU的預測性塊。根據本發明的實例技術,預測處理單元254基于視頻數據的當前圖片中的當前塊的運動向量而確定第一參考圖片中的第一參考塊的位置。此第一參考塊可為由運動補償單元266產生的預測性塊。此外,在此實例中,預測處理單元254確定第二參考圖片中的第二參考塊的位置。在此實例中,預測處理單元254將可分離的雙線性內插濾波器應用于第二參考圖片的樣本以確定第二參考塊的樣本。另外,預測處理單元254將可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本。在此實例中,預測處理單元254確定預測性塊。預測性塊的每一相應樣本等于第一參考塊的相應樣本減去相應殘余預測符樣本。在此實例中,相應殘余預測符樣本等于加權因數乘以第二參考塊的相應樣本與第三參考塊的相應樣本之間的差。第一參考塊的相應樣本、第二參考塊的相應樣本以及第三參考塊的相應樣本在第一、第二和第三參考塊內對應于預測性塊的相應樣本的位置的位置處。
重構單元260可使用來自CU的TU的變換塊和CU的PU的預測性塊的殘余值來重構CU的譯碼塊。舉例來說,重構單元260可使用來自CU的TU的明度、Cb及Cr變換塊和CU的PU的預測性明度、Cb及Cr塊的殘余值來重構CU的明度、Cb及Cr譯碼塊。舉例來說,重構單元260可將變換塊的樣本添加到預測性塊的對應樣本以重構CU的譯碼塊。
濾波器單元262可執行解塊操作以減少與CU的譯碼塊相關聯的成塊假象。視頻解碼器30可將CU的譯碼塊存儲在經解碼圖片緩沖器264中。經解碼圖片緩沖器264可提供參考圖片用于后續運動補償、幀內預測和在顯示裝置(例如圖1的顯示裝置32)上呈現。舉例來說,視頻解碼器30可基于經解碼圖片緩沖器264中的塊對其它CU的PU執行幀內預測或幀間預測操作。以此方式,視頻解碼器30可從位流獲得系數塊的變換系數層級,逆量化變換系數層級,對變換系數層級應用變換以產生變換塊,至少部分基于變換塊而產生譯碼塊,且輸出譯碼塊以用于顯示。
如上文所指出,在本發明的一些實例技術中,視頻譯碼器經配置以當確定ARP中的參考塊時使用可分離的雙線性內插濾波器。以下文字展示對3D-HEVC草案文本4(即,文獻JCT3V-H1001_v2)的實例改變以實施此些實例技術。在以下文字中,方括號中所示的斜體文字是從3D-HEVC草案文本4刪除的文字。帶下劃線的文字是添加到3D-HEVC草案文本4的文字。此外,以下文字中提到的圖I-1作為本發明的圖10而再現。圖10是說明雙線性內插中的分數樣本位置相依變量以及周圍的整數位置樣本的概念圖。以下文字中提到的圖x-x作為本發明的圖11而再現。
I.8.5.3.3.7.1雙線性樣本內插過程
子條款8.5.3.3.3.1中的規范適用于以下修改:
-子條款8.5.3.3.3.2中指定的過程的所有調用被子條款I.8.5.3.3.7.2中指定的過程的調用替換,其中等于0的chromaFlag作為額外輸入。
-子條款8.5.3.3.3.3中指定的過程的所有調用被子條款I.8.5.3.3.7.2中指定的過程的調用替換,其中等于1的chromaFlag作為額外輸入。
I.8.5.3.3.7.2雙線性明度和色度樣本內插過程
對此過程的輸入是:
-全樣本單元(xInt,yInt)中的位置,
-分數樣本單元(xFrac,yFrac)中的位置偏移,
-樣本參考陣列refPicLX,
-旗標chromaFlag。
此過程的輸出是預測樣本值predPartLX[x][y]。
[[在圖I-1中,標記有A、B、C和D的位置表示在樣本的給定二維陣列refPicLX內的全樣本位置處的樣本。
1.圖I-1雙線性內插中的分數樣本位置相依變量以及周圍的整數位置樣本A、B、C和D]]
變量picWidthInSamples設定成等于pic_width_in_luma_samples且變量picHeightInSamples設定成等于pic_height_in_luma_samples。
-如果chromaFlag等于0,那么xFrac設定成等于(xFrac<<1)且yFrac設定成等于(yFrac<<1)。
-否則(chromaFlag等于1),picWidthInSamples設定成等于(picWidthInSamples/SubWidthC)且picHeightInSamples設定成等于(picHeightInSamples/SubHeightC)。
[[如下導出位置A、B、C和D的坐標:
xA=Clip3(0,picWidthInSamples-1,xInt) (I-230)
xB=Clip3(0,picWidthInSamples-1,xInt+1) (I-231)
xC=Clip3(0,picWidthInSamples-1,xInt) (I-232)
xD=Clip3(0,picWidthInSamples-1,xInt+1) (I-233)
yA=Clip3(0,picHeightInSamples-1,yInt) (I-234)
yB=Clip3(0,picHeightInSamples-1,yInt) (I-235)
yC=Clip3(0,picHeightInSamples-1,yInt+1) (I-236)
yD=Clip3(0,picHeightInSamples-1,yInt+1) (I-237)]]
在HEVC規范的圖8-5中,加陰影塊內標記有大寫字母Bi,j的位置表示取決于chromaFlag在明度/色度樣本的給定二維陣列refPicLX內的全樣本位置處的明度/色度樣本。這些樣本可以用于產生預測明度/色度樣本值predSampleLX[x,y]。分數樣本單元(xFracC,yFracC)中的位置偏移指定在全樣本和分數樣本位置處的所產生樣本中的哪些指派給預測樣本值predSampleLX[x,y]。此指派如表8-8中指定,其中xFracC被xFrac代替,yFracC被yFrac代替,且predSampleLXC[xC,yC]被predSampleLX[x,y]代替。輸出是predSampleLX[x,y]的值。
如下導出給定陣列refPicLX內對應樣本Bi,j中的每一者的位置(xBi,j,yBi,j):
xBi,j=Clip3(0,picWidthInSamples-1,xIntC+i) (x-xxx)
yBi,j=Clip3(0,picHeightInSamples-1,yIntC+j) (x-xxx)
將變量BitDepth設定為等于chromaFlag?BitDepthC:BitDepthY。
如下導出變量shift1、shift2和shift3:
-變量shift1設定成等于BitDepth-8,變量shift2設定成等于6,且變量shift3設定成等于14-BitDepth。
給定在全樣本位置(xBi,j,yBi,j)的色度樣本Bi,j,如下導出在分數樣本位置的色度樣本ab0,0到hh0,0:
-標記有ab0,0、ac0,0、ad0,0、ae0,0、af0,0、ag0,0和ah0,0的樣本是通過將2分支濾波器應用于最近整數位置樣本而導出,如下:
[Ed.(CY):需要調整以下等式數目。]
ab0,0=(56*B0,0+8*B1,0)>>shift1 (8-216)
ac0,0=(48*B0,0+16*B1,0)>>shift1 (8-217)
ad0,0=(40*B0,0+24*B1,0)>>shift1 (8-218)
ae0,0=(32*B0,0+32*B1,0)>>shift1 (8-219)
af0,0=(24*B0,0+40*B1,0)>>shift1 (8-220)
ag0,0=(16*B0,0+48*B1,0)>>shift1 (8-221)
ah0,0=(8*B0,0+56*B1,0)>>shift1 (8-222)
-標記有ba0,0、ca0,0、da0,0、ea0,0、fa0,0、ga0,0和ha0,0的樣本是通過將2分支濾波器應用于最近整數位置樣本而導出,如下:
ba0,0=(56*B0,0+8*B0,1)>>shift1 (8-223)
ca0,0=(48*B0,0+16*B0,1)>>shift1 (8-224)
da0,0=(40*B0,0+24*B0,1)>>shift1 (8-225)
ea0,0=(32*B0,0+32*B0,1)>>shift1 (8-226)
fa0,0=(24*B0,0+40*B0,1)>>shift1 (8-227)
ga0,0=(16*B0,0+48*B0,1)>>shift1 (8-228)
ha0,0=(8*B0,0+56*B0,1)>>shift1 (8-229)
-標記有bX0,0、cX0,0、dX0,0、eX0,0、fX0,0、gX0,0和hX0,0(X分別被b、c、d、e、f、g和h代替)的樣本是通過在垂直方向上將2分支濾波器應用于中間值aX0,i(其中i=-1..2)而導出,如下:
bX0,0=(56*aX0,0+8*aX0,1)>>shift2 (8-230)
cX0,0=(48*aX0,0+16*aX0,1)>>shift2 (8-231)
dX0,0=(40*aX0,0+24*aX0,1)>>shift2 (8-232)
eX0,0=(32*aX0,0+32*aX0,1)>>shift2 (8-233)
fX0,0=(24*aX0,0+40*aX0,1)>>shift2 (8-234)
gX0,0=(16*aX0,0+48*aX0,1)>>shift2 (8-235)
hX0,0=(8*aX0,0+56*aX0,1)>>shift2 (8-236)
圖x-x-針對八分之一樣本內插的整數樣本(具有大寫字母的加陰影塊)和分數樣本位置(具有小寫字母的不加陰影塊)[Ed.(CY):所述圖可在當前3D-HEVC WD文字中移除,因為所述文字參考HEVC版本1規范。此處為了清楚目的而將其保持。]
[[如以下指定導出predPartLX[x][y]的值:
predPartLX[x][y]=(refPicLX[xA][yA]*(8-xFrac)*(8-yFrac)+
refPicLX[xB][yB]*(8-yFrac)*xFrac+
refPicLX[xC][yC]*(8-xFrac)*yFrac+
refPicLX[xD][yD]*xFrac*yFrac)>>6(I-238)]]
注意-:當chromaFlag等于0時,所述兩個變量(即,xFrac和yFrac)是經修改的輸入,其中xFrac%2和yFrac%2兩者將等于0。
圖11是說明用于八分之一樣本內插的實例整數樣本和分數樣本位置的概念圖。在圖11的實例中,具有大寫字母名稱的加陰影正方形對應于全整數像素位置。如以上文字中所示,視頻譯碼器使用不同濾波器等式(即,濾波器等式8-216到8-236)以確定用于不同子整數像素位置處的樣本的經濾波值。濾波器等式表示可分離的雙線性內插濾波器。
此雙線性內插濾波器是“可分離的”,因為第一濾波器應用于確定主要子整數位置處的樣本的值。主要子整數位置從整數像素位置嚴格地垂直或水平。在圖11中,主要子整數位置是位置ab0,0、ac0,0、ad0,0、ae0,0、af0,0、ag0,0、ah0,0、ba0,0、ca0,0、da0,0、ea0,0、fa0,0、ga0,0、ha0,0、ab0,1、ac0,1、ad0,1、ae0,1、af0,1、ag0,1、ah0,1、ba1,0、ca1,0、da1,0、ea1,0、fa1,0和ga1,0。第二濾波器應用于主要子整數位置處的樣本以確定在輔助子整數位置處的樣本的值。輔助子整數位置并不從整數像素位置嚴格地垂直或水平。在圖11中,輔助子整數位置是由整數像素位置(即,B0,0、B1,0、B0,1和B1,1)和主要子整數位置界定的框內的子整數位置。
在此上下文中,術語“階段”指代子整數位置。因此,每一相應主要子整數位置和輔助子整數是相應“階段”。如上文所指出,每一階段的濾波器的系數的總和合計達64。濾波器等式8-216到8-236中的每一者涉及兩個系數,其可界定為a和b。在濾波器等式8-216到8-236中的每一者中,系數a和b的總和等于64。舉例來說,用于子整數位置ab0,0的濾波器等式(即,等式8-216)包含兩個系數56和8,其共計為64。
如以上文字中所示,雙線性內插過程先前涉及視頻譯碼器用以導出位置A、B、C和D的坐標的一系列削減操作(即,等式I-230到I-237),如圖10中所示。此外,如本發明中在別處所論述,削減操作增加了譯碼過程的復雜性。此實例實施方案的經修改文字通過使用如等式(8-216到8-236)中所示的可分離的雙線性內插濾波器而不是先前使用的不可分離的內插濾波器而減少削減操作的數目。
根據本發明的另一實例技術,通過利用用于雙線性濾波器的較小系數可進一步簡化以上文字。此實例不一定提供與以上實例實施方案相比位準確的結果。下文以帶下劃線的文字展示相對于上述實例實施方案實施此簡化實例的改變。
…
-變量shift1設定成等于BitDepth-8,變量shift2設定成等于[[6]]0,且變量shift3設定成等于14-BitDepth。
給定在全樣本位置(xBi,j,yBi,j)的色度樣本Bi,j,如下導出在分數樣本位置的色度樣本ab0,0到hh0,0:
-標記有ab0,0、ac0,0、ad0,0、ae0,0、af0,0、ag0,0和ah0,0的樣本是通過將2分支濾波器應用于最近整數位置樣本而導出,如下:
ab0,0=(7*B0,0+1*B1,0)>>shift1 (8-216)
ac0,0=(6*B0,0+2*B1,0)>>shift1 (8-217)
ad0,0=(5*B0,0+3*B1,0)>>shift1 (8-218)
ae0,0=(4*B0,0+4*B1,0)>>shift1 (8-219)
af0,0=(3*B0,0+5*B1,0)>>shift1 (8-220)
ag0,0=(2*B0,0+6*B1,0)>>shift1 (8-221)
ah0,0=(1*B0,0+7*B1,0)>>shift1 (8-222)
-標記有ba0,0、ca0,0、da0,0、ea0,0、fa0,0、ga0,0和ha0,0的樣本是通過將2分支濾波器應用于最近整數位置樣本而導出,如下:
ba0,0=(7*B0,0+1*B0,1)>>shift1 (8-223)
ca0,0=(6*B0,0+2*B0,1)>>shift1 (8-224)
da0,0=(5*B0,0+3*B0,1)>>shift1 (8-225)
ea0,0=(4*B0,0+4*B0,1)>>shift1 (8-226)
fa0,0=(3*B0,0+5*B0,1)>>shift1 (8-227)
ga0,0=(2*B0,0+6*B0,1)>>shift1 (8-228)
ha0,0=(1*B0,0+7*B0,1)>>shift1 (8-229)
-標記有bX0,0、cX0,0、dX0,0、eX0,0、fX0,0、gX0,0和hX0,0(X分別被b、c、d、e、f、g和h代替)的樣本是通過在垂直方向上將2分支濾波器應用于中間值aX0,i(其中i=-1..2)而導出,如下:
bX0,0=(7*aX0,0+1*aX0,1)>>shift2 (8-230)
cX0,0=(6*aX0,0+2*aX0,1)>>shift2 (8-231)
dX0,0=(5*aX0,0+3*aX0,1)>>shift2 (8-232)
eX0,0=(4*aX0,0+4*aX0,1)>>shift2 (8-233)
fX0,0=(3*aX0,0+5*aX0,1)>>shift2 (8-234)
gX0,0=(2*aX0,0+6*aX0,1)>>shift2 (8-235)
hX0,0=(1*aX0,0+7*aX0,1)>>shift2 (8-236)
…
在本發明的其它實例技術中,使用雙線性濾波器的不可分離的實施方案。在其中使用雙線性濾波器的不可分離的實施方案的實例中,僅需要對如3D-HEVC草案文本4的I.8.5.3.3.7.1中的等式I-238的以下修改。此實例實施方案不一定提供與上述兩個實例實施方案相比位準確的結果。
predPartLX[x][y]=(refPicLX[xA][yA]*(8-xFrac)*(8-yFrac)+
refPicLX[xB][yB]*(8-yFrac)*xFrac+
refPicLX[xC][yC]*(8-xFrac)*yFrac+
refPicLX[xD][yD]*xFrac*yFrac)>>[[6]]shift0
在以上等式中,shift0等于bitDepth-8。
如上文所指出,照明補償過程可涉及不需要的削減操作。在解決IC中的冗余削減操作問題的一個實例中,移除IC中的所有冗余削減。此實例移除用于運動補償樣本和照明補償樣本兩者的削減,即通過跳過等式(1)和(3)中的計算(即,分別為PredMcLX[x]=clip3(0,(1<<BitDepth)-1,(PredMcLX[x]+offset1)>>shift1)以及IcPredLX[x]=clip3(0,(1<<BitDepth)-1,IcPredMcLX[x])。在此實例中,以與HEVC版本1相同的方式,當IC經啟用時針對雙向預測和單向預測兩者執行僅一個削減。
在解決IC中的冗余削減操作的另一實例中,將照明補償樣本削減到[0,32767]以顯式地保證IC可由16位存儲元件執行。此實例移除運動補償樣本的削減,即通過跳過等式(1)中的計算。另外,此實例如下改變照明補償樣本的削減(即,等式(3)):
IcPredLX[x]=clip3(0,32767,IcPredLX[x]) (8)
在此些實例中,當IC經啟用時分別針對雙向預測和單向預測執行三次削減和兩次削減。這些實例均支持IC中以非規范性方式從雙向預測到單向預測的轉換(如果兩個運動向量及其相關聯參考圖片是相同的,那么雙向預測可作為單向預測執行)。
以下文字展示對3D-HEVC草案文本4的改變以減少或消除IC中的冗余削減操作。在以下文字中,加下劃線指示添加的文字且雙方括號中的斜體文字是從3D-HEVC草案文本4刪除的文字。
I.8.5.3.3.6照明補償樣本預測過程
對此過程的輸入是:
-相對于當前圖片的左上方樣本指定當前明度譯碼塊的左上方樣本的位置(xCb,yCb),
-當前明度譯碼塊nCbS的大小,
-相對于當前譯碼塊的左上方樣本指定當前預測塊的左上方樣本的位置(xBl,yBl),
-此預測塊的寬度及高度nPbW及nPbH,
-兩個(nPbW)×(nPbH)陣列predSamplesL0及predSamplesL1,
-兩個預測列表利用旗標predFlagL0及predFlagL1,
-兩個參考索引refIdxL0及refIdxL1,
-兩個運動向量mvL0和mvL1,
-顏色分量索引cIdx。
此過程的輸出是:
-預測樣本值的(nPbW)×(nPbH)陣列predSamples。
[[如下導出變量shiftl、shift2、offsetl和offset2:
-變量shift1設定成等于14-bitDepth且變量shift2設定成等于15-bitDepth,
-如下導出變量offset1:
-如果shift1大于0,那么offset1設定成等于1<<(shift1-1)。
-否則的話(shift1等于0),offset1設定成等于0。
-變量offset2設定為等于1<<(shift2-1)。]]
如下導出變量bitDepth:
-如果cIdx等于0,那么bitDepth設定成等于BitDepthY。
-否則(cIdx等于1或2),bitDepth設定成等于BitDepthC。
調用用于如子條款I.8.5.3.3.6.1中指定的照明補償模式可用性和參數的導出過程,其中明度位置(xCb,yCb)、當前明度譯碼塊nCbS的大小、預測列表利用旗標、predFlagL0和predFlagL1、參考索引refIdxL0和refIdxL1、運動向量mvL0和mvL1、樣本的位深度bitDepth、指定顏色分量索引的變量cIdx作為輸入,且輸出是旗標puIcFlagL0和puIcFlagL1以及指定用于照明補償的權重的變量icWeightL0和icWeightL1、指定用于照明補償的偏移的變量icOffsetL0和icOffsetL1。
取決于predFlagL0和predFlagL1的值,如下導出照明補償預測樣本predSamplesIcLX[x][y],其中x=0..(nPbW)-1且y=0..(nPbH)-1:
-對于在0到1的范圍內(包含性)的X,以下適用:
-當predFlagLX等于1時以下適用:
[[clipPredVal=
Clip3(0,(1<<bitDepth)-1,(predSamplesLX[x][y]+offset1)>>shift1)(I-192)]]
predSamplesIcLX[x][y][[predValX]]=!puIcFlagLX?predSamplesLX[x][y][[clipPredVal]]:
([[Clip3(0,(1<<bitDepth)-1,]]([[clipPredVal]]predSamplesLX[x][y]*icWeightLX)>>5)+(icOffsetLX<<(14-bitDepth))[[)]](I-193)
-[[如果predFlagL0等于1且predFlagL1等于1,那么以下適用:
predSamples[x][y]=Clip3(0,(1<<bitDepth)-1,(predVal0+predVal1+offset2)>>shift2)(I-194)
-否則(predFlagL0等于0或predFlagL1等于0),以下適用:
predSamples[x][y]=predFlagL0?predVal0:predVal1(I-195)]]
通過調用子條款8.5.3.3.4中指定的經加權樣本預測過程而導出陣列predSamples,其中預測塊寬度nPbW、預測塊高度nPbH以及樣本陣列predSamplesIcL0和predSamplesIcL1、以及變量predFlagL0、predFlagL1、refIdxL0、refIdxL1和cIdx作為輸入。
經加權樣本預測過程
綜述
對此過程的輸入是:
-指定明度預測塊的寬度及高度的兩個變量nPbW及nPbH,
-兩個(nPbW)×(nPbH)陣列predSamplesL0及predSamplesL1,
-預測列表利用旗標predFlagL0及predFlagL1,
-參考索引refIdxL0及refIdxL1,
-指定顏色分量索引的變量cIdx。
此過程的輸出是預測樣本值的(nPbW)x(nPbH)陣列predSamples。
如下導出變量bitDepth:
-如果cIdx等于0,那么bitDepth設定成等于BitDepthY。
-否則,bitDepth設定成等于BitDepthC。
如下導出變量weightedPredFlag:
-如果slice_type等于P,那么weightedPredFlag設定成等于weighted_pred_flag。
-否則(slice_type等于B),weightedPredFlag設定成等于weighted_bipred_flag。
以下適用:
-如果weightedPredFlag等于0或ic_flag等于1,那么通過調用如子條款8.5.3.3.4.2中指定的默認經加權樣本預測過程而導出預測樣本,其中明度預測塊寬度nPbW、明度預測塊高度nPbH、兩個(nPbW)x(nPbH)陣列predSamplesL0和predSamplesL1、預測列表利用旗標predFlagL0和predFlagL1以及位深度bitDepth作為輸入。
-否則(weightedPredFlag等于1),通過調用如子條款8.5.3.3.4.3中指定的經加權樣本預測過程而導出預測樣本的陣列predSample,其中明度預測塊寬度nPbW、明度預測塊高度nPbH、兩個(nPbW)x(nPbH)陣列predSamplesL0和predSamplesL1、預測列表利用旗標predFlagL0和predFlagL1、參考索引refIdxL0和refIdxL1、顏色分量索引cIdx以及位深度bitDepth作為輸入。
…
圖12是說明根據本發明的技術的視頻編碼器20的實例操作的流程圖。提供本發明的流程圖作為實例。其它實例可包含更多、更少或不同的動作,或可包含呈不同次序或并行的動作。在圖12的實例中,視頻編碼器20基于視頻數據的當前圖片中的當前塊的運動向量確定第一參考圖片中的第一參考塊的位置(300)。視頻編碼器20可將可分離的雙線性內插濾波器應用于第一參考圖片的樣本以確定第一參考塊的樣本(301)。
另外,視頻編碼器20確定第二參考圖片中的第二參考塊的位置(302)。此外,視頻編碼器20將可分離的雙線性內插濾波器應用于第二參考圖片的樣本以確定第二參考塊的樣本(304)。視頻編碼器20將可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本(306)。第一、第二和第三參考圖片中的每一者是不同圖片。
在一些實例中,每一階段的可分離的雙線性內插濾波器的系數的總和等于64。舉例來說,可分離的雙線性內插濾波器的系數(a,b)的總和等于(x*8,(8-x)*8),其中x等于在0到8的范圍內的值。因此,在一些實例中,對于第一參考塊、第二參考塊或第三參考塊的每一相應樣本,視頻解碼器30可基于相應樣本的位置應用以下公式中的一或多者以確定相應樣本:
ab0,0=(56*B0,0+8*B1,0)>>shift1,
ac0,0=(48*B0,0+16*B1,0)>>shift1,
ad0,0=(40*B0,0+24*B1,0)>>shift1,
ae0,0=(32*B0,0+32*B1,0)>>shift1,
af0,0=(24*B0,0+40*B1,0)>>shift1,
ag0,0=(16*B0,0+48*B1,0)>>shift1,
ah0,0=(8*B0,0+56*B1,0)>>shift1,
ba0,0=(56*B0,0+8*B0,1)>>shift1,
ca0,0=(48*B0,0+16*B0,1)>>shift1,
da0,0=(40*B0,0+24*B0,1)>>shift1,
ea0,0=(32*B0,0+32*B0,1)>>shift1,
fa0,0=(24*B0,0+40*B0,1)>>shift1,
ga0,0=(16*B0,0+48*B0,1)>>shift1,
ha0,0=(8*B0,0+56*B0,1)>>shift1,
bX0,0=(56*aX0,0+8*aX0,1)>>shift2,
cX0,0=(48*aX0,0+16*aX0,1)>>shift2,
dX0,0=(40*aX0,0+24*aX0,1)>>shift2,
eX0,0=(32*aX0,0+32*aX0,1)>>shift2,
fX0,0=(24*aX0,0+40*aX0,1)>>shift2,
gX0,0=(16*aX0,0+48*aX0,1)>>shift2,
hX0,0=(8*aX0,0+56*aX0,1)>>shift2,
在以上等式中,對于標記有bX0,0、cX0,0、dX0,0、eX0,0、fX0,0、gX0,0和hX0,0的樣本,X分別被b、c、d、e、f、g和h代替。Shift1等于相應樣本的位深度減8且shift2等于6。圖11展示上文指示的位置。
視頻編碼器20確定預測性塊(308)。預測性塊的每一相應樣本等于第一參考塊的相應樣本減去相應殘余預測符樣本。相應殘余預測符樣本等于加權因數乘以第二參考塊的相應樣本與第三參考塊的相應樣本之間的差。第一參考塊的相應樣本、第二參考塊的相應樣本以及第三參考塊的相應樣本在第一、第二和第三參考塊內對應于預測性塊的相應樣本的位置的位置處。舉例來說,預測性塊的相應樣本可在坐標(4,5)處,其中所述坐標是相對于預測性塊的左上方樣本。在此實例中,第一、第二和第三參考塊的相應樣本可在坐標(4,5)處,其中所述坐標是分別相對于第一、第二和第三參考塊的左上方樣本。在一些實例中,加權因數等于0、0.5或1。因為加權因數可等于1,所以在根本不應用加權因數的實例中,相應殘余預測符樣本仍等于加權因數(即,1)乘以第二參考塊的相應樣本與第三參考塊的相應樣本之間的差。
視頻編碼器20確定殘余塊(310)。在其中當前塊是單向的實例中,殘余塊的每一相應樣本等于當前塊的相應樣本與預測性塊的相應樣本之間的差。當前塊的相應樣本和預測性塊的相應樣本對應于殘余塊的相應樣本的位置。如本發明中在別處所描述,在其中當前塊是雙向的實例中,預測性塊是第一預測性塊,且視頻編碼器20基于第一預測性塊中的樣本、第二預測性塊中的樣本和當前塊中的樣本確定殘余塊。
視頻編碼器20在位流中包含表示殘余塊的數據(312)。舉例來說,視頻編碼器20可基于殘余塊產生一或多個變換系數塊。此外,在此實例中,視頻編碼器20可量化變換系數塊且可產生表示經量化變換系數塊的語法元素。視頻編碼器20可對所述語法元素進行熵編碼且在位流中包含經熵編碼語法元素。因此,在此實例中,經熵編碼語法元素包括表示殘余塊的數據。
圖13是說明根據本發明的技術的視頻解碼器30的實例操作的流程圖。在圖13的實例中,視頻解碼器30基于視頻數據的當前圖片中的當前塊的運動向量確定第一參考圖片中的第一參考塊的位置(350)。視頻解碼器30可將可分離的雙線性內插濾波器應用于第一參考圖片的樣本以確定第一參考塊的樣本(351)。
另外,視頻解碼器30確定第二參考圖片中的第二參考塊的位置(352)。視頻解碼器30將可分離的雙線性內插濾波器應用于第二參考圖片的樣本以確定第二參考塊的樣本(354)。此外,視頻解碼器30將可分離的雙線性內插濾波器應用于第三參考圖片的樣本以確定第三參考塊的樣本(356)。第一、第二和第三參考圖片中的每一者是不同圖片。在一些實例中,視頻解碼器30應用可分離的雙線性內插濾波器以確定第一參考塊的樣本。
在某一實例中,每一階段的可分離的雙線性內插濾波器的系數的總和等于64。舉例來說,可分離的雙線性內插濾波器的系數(a,b)的總和等于(x*8,(8-x)*8),其中x等于在0到8的范圍內的值。因此,在一些實例中,對于第一參考塊、第二參考塊或第三參考塊的每一相應樣本,視頻解碼器30可基于相應樣本的位置應用以下公式中的一或多者以確定相應樣本:
ab0,0=(56*B0,0+8*B1,0)>>shift1,
ac0,0=(48*B0,0+16*B1,0)>>shift1,
ad0,0=(40*B0,0+24*B1,0)>>shift1,
ae0,0=(32*B0,0+32*B1,0)>>shift1,
af0,0=(24*B0,0+40*B1,0)>>shift1,
ag0,0=(16*B0,0+48*B1,0)>>shift1,
ah0,0=(8*B0,0+56*B1,0)>>shift1,
ba0,0=(56*B0,0+8*B0,1)>>shift1,
ca0,0=(48*B0,0+16*B0,1)>>shift1,
da0,0=(40*B0,0+24*B0,1)>>shift1,
ea0,0=(32*B0,0+32*B0,1)>>shift1,
fa0,0=(24*B0,0+40*B0,1)>>shift1,
ga0,0=(16*B0,0+48*B0,1)>>shift1,
ha0,0=(8*B0,0+56*B0,1)>>shift1,
bX0,0=(56*aX0,0+8*aX0,1)>>shift2,
cX0,0=(48*aX0,0+16*aX0,1)>>shift2,
dX0,0=(40*aX0,0+24*aX0,1)>>shift2,
eX0,0=(32*aX0,0+32*aX0,1)>>shift2,
fX0,0=(24*aX0,0+40*aX0,1)>>shift2,
gX0,0=(16*aX0,0+48*aX0,1)>>shift2,
hX0,0=(8*aX0,0+56*aX0,1)>>shift2,
在以上等式中,對于標記有bX0,0、cX0,0、dX0,0、eX0,0、fX0,0、gX0,0和hX0,0的樣本,X分別被b、c、d、e、f、g和h代替。Shift1等于相應樣本的位深度減8且shift2等于6。圖11展示上文指示的位置。
視頻解碼器30確定預測性塊(358)。在一些實例中,預測性塊的每一相應樣本等于第一參考塊的相應樣本加相應殘余預測符樣本。在此些實例中,相應殘余預測符樣本等于加權因數乘以第二參考塊的相應樣本與第三參考塊的相應樣本之間的差。第一參考塊的相應樣本、第二參考塊的相應樣本以及第三參考塊的相應樣本在第一、第二和第三參考塊內對應于預測性塊的相應樣本的位置的位置處。舉例來說,預測性塊的相應樣本可在坐標(4,5)處,其中所述坐標是相對于預測性塊的左上方樣本。在此實例中,第一、第二和第三參考塊的相應樣本可在坐標(4,5)處,其中所述坐標是分別相對于第一、第二和第三參考塊的左上方樣本。
視頻解碼器30從位流獲得表示殘余塊的數據(360)。舉例來說,視頻解碼器30可對位流中的位序列進行熵解碼以恢復表示經量化變換系數值的語法元素。在此實例中,視頻解碼器30可逆量化經量化變換系數且應用逆變換以恢復殘余塊的樣本。
此外,視頻解碼器30至少部分地基于殘余塊和預測性塊而重構當前圖片的譯碼塊(362)。舉例來說,當前塊可為具有對應于CU的譯碼塊中的一些或全部的預測塊的PU。在此實例中,假定PU是單向的,視頻解碼器30可重構PU的預測塊(即,譯碼塊的對應于PU的部分)以使得預測塊的每一相應樣本等于殘余塊的相應樣本加預測性塊的相應樣本。殘余塊的相應樣本和預測性塊的相應樣本是在殘余塊和預測性塊內對應于PU的預測塊的相應樣本的位置的相應位置處。
在圖12和圖13的實例操作中,視頻譯碼器(例如,視頻編碼器20或視頻解碼器30)可執行進一步執行類似操作用于雙向幀間預測塊。因此,上文所提及的預測性塊可視為第一預測性塊。舉例來說,視頻譯碼器可基于當前塊的第二運動向量確定第四參考圖片中的第四參考塊(例如,CurrTRef)的位置。視頻譯碼器可將可分離的雙線性內插濾波器應用于第四參考圖片的樣本以確定第四參考塊的樣本。另外,視頻譯碼器可部分地基于第二運動向量確定第五參考圖片中的第五參考塊(例如,BaseTRef)的位置。此外,視頻譯碼器可將可分離的雙線性內插濾波器應用于第五參考圖片的樣本以確定第五參考塊的樣本。視頻譯碼器可將可分離的雙線性內插濾波器應用于第六參考圖片的樣本以確定第六參考塊(例如,Base)的樣本。第四、第五和第六參考圖片中的每一者是不同圖片。在一些實例中,視頻譯碼器還可應用可分離的雙線性內插濾波器以確定第四參考塊(例如,CurrTRef)的樣本。此外,視頻譯碼器可確定第二預測性塊。第二預測性塊的每一相應樣本等于第四參考塊(例如,CurrTRef)的相應樣本加相應殘余預測符樣本。在此實例中,相應殘余預測符樣本等于加權因數乘以第五參考塊(例如,BaseTRef)的相應樣本與第六參考塊(例如,Base)的相應樣本之間的差。第四參考塊的相應樣本、第五參考塊的相應樣本以及第六參考塊的相應樣本在第四、第五和第六參考塊內對應于第二預測性塊的相應樣本的位置的位置處。在一些實例中,第五和第六參考塊中的至少一者相同于第二或第三參考塊。
在此實例中,如果視頻譯碼器是視頻解碼器,那么視頻譯碼器可至少部分地基于殘余塊而重構第一預測性塊并且還有第二預測性塊,當前圖片的譯碼塊。舉例來說,視頻解碼器可基于第一預測性塊和第二預測性塊確定最終預測性塊。最終預測性塊的每一相應樣本可為第一預測性塊和第二預測性塊的對應樣本的加權平均。在此實例中,經重構譯碼塊的每一相應樣本可等于殘余塊和最終預測性塊中的對應樣本的總和。
如果視頻譯碼器是視頻編碼器,那么視頻譯碼器可至少部分地基于第一預測性塊和第二預測性塊而確定殘余塊。舉例來說,在此實例中,視頻譯碼器可以上文所描述的方式確定最終預測性塊。在此實例中,殘余塊的每一相應樣本等于當前塊的相應樣本與最終預測性塊的對應相應樣本之間的差。第二塊的相應樣本和第二預測性塊的相應樣本對應于第二殘余塊的相應樣本的位置。視頻編碼器可在位流中包含表示殘余塊的數據。
在一或多個實例中,所描述功能可以硬件、軟件、固件或其任何組合來實施。如果用軟件實施,則所述功能可作為一或多個指令或代碼在計算機可讀媒體上存儲或傳輸,且由基于硬件的處理單元執行。計算機可讀媒體可包含計算機可讀存儲媒體,其對應于有形媒體(例如,數據存儲媒體),或包含任何促進將計算機程序從一處傳送到另一處(例如,根據通信協議)的媒體的通信媒體。以此方式,計算機可讀媒體通常可以對應于(1)有形計算機可讀存儲媒體,其是非暫時的,或(2)通信媒體,例如信號或載波。數據存儲媒體可為可由一或多個計算機或一或多個處理器存取以檢索用于實施本發明中描述的技術的指令、代碼及/或數據結構的任何可用媒體。計算機程序產品可以包含計算機可讀媒體。
借助于實例而非限制,此類計算機可讀存儲媒體可包括RAM、ROM、EEPROM、CD-ROM或其它光盤存儲裝置、磁盤存儲裝置或其它磁性存儲裝置、快閃存儲器或可以用來存儲指令或數據結構的形式的期望程序代碼并且可以由計算機存取的任何其它媒體。并且,任何連接被恰當地稱作計算機可讀媒體。舉例來說,如果使用同軸纜線、光纖纜線、雙絞線、數字訂戶線(DSL)或例如紅外線、無線電和微波等無線技術從網站、服務器或其它遠程源傳輸指令,那么同軸纜線、光纖纜線、雙絞線、DSL或例如紅外線、無線電和微波等無線技術包含在媒體的定義中。但是,應理解,所述計算機可讀存儲媒體和數據存儲媒體并不包含連接、載波、信號或其它暫時媒體,而是實際上針對于非暫時性有形存儲媒體。如本文中所使用,磁盤和光盤包含壓縮光盤(CD)、激光光盤、光學光盤、數字多功能光盤(DVD)、軟性磁盤和藍光光盤,其中磁盤通常以磁性方式再現數據,而光盤利用激光以光學方式再現數據。以上各項的組合也應包含在計算機可讀媒體的范圍內。
可由例如一或多個數字信號處理器(DSP)、通用微處理器、專用集成電路(ASIC)、現場可編程邏輯陣列(FPGA)或其它等效集成或離散邏輯電路等一或多個處理器來執行指令。因此,如本文中所使用的術語“處理器”可指前述結構或適合于實施本文中所描述的技術的任一其它結構中的任一者。另外,在一些方面中,本文中所描述的功能性可以在經配置用于編碼和解碼的專用硬件和/或軟件模塊內提供,或者并入在組合編解碼器中。而且,所述技術可完全實施于一或多個電路或邏輯元件中。
本發明的技術可在廣泛多種裝置或設備中實施,包括無線手持機、集成電路(IC)或一組IC(例如,芯片組)。本發明中描述各種組件、模塊或單元是為了強調經配置以執行所公開的技術的裝置的功能方面,但未必需要由不同硬件單元實現。實際上,如上文所描述,各種單元可以結合合適的軟件及/或固件組合在編解碼器硬件單元中,或者通過互操作硬件單元的集合來提供,所述硬件單元包含如上文所描述的一或多個處理器。
描述了各種實例。這些及其它實例在所附權利要求書的范圍內。
- 還沒有人留言評論。精彩留言會獲得點贊!