CDR中基于共享機制的準循環LDPC編碼器的制作方法
本發明涉及信道編碼領域,特別涉及一種cdr系統中基于共享機制的qc-ldpc編碼器。
背景技術:
低密度奇偶校驗(low-densityparity-check,ldpc)碼是高效的信道編碼技術之一,而準循環ldpc(quasi-cyclicldpc,qc-ldpc)碼是一種特殊的ldpc碼。qc-ldpc碼的生成矩陣g和校驗矩陣h都是由循環矩陣構成的陣列,具有分塊循環的特點,故被稱為qc-ldpc碼。循環矩陣的首行是末行循環右移1位的結果,其余各行都是其上一行循環右移1位的結果,因此,循環矩陣完全由其首行來表征。通常,循環矩陣的首行被稱為它的生成多項式。
cdr標準采用系統形式的qc-ldpc碼,其生成矩陣g的左半部分是一個單位矩陣,右半部分是由e×c個b×b階循環矩陣gi,j(0≤i<e,e≤j<t,t=e+c)構成的陣列,如下所示:
其中,i是b×b階單位矩陣,0是b×b階全零矩陣。g的連續b行和b列分別被稱為塊行和塊列。由式(1)可知,g有e塊行和t塊列。cdr標準采用了一種碼率η=1/4的qc-ldpc碼,對于該碼,t=36,e=9,c=27,b=256。
cdr標準中1/4碼率qc-ldpc編碼器的現有解決方案是基于c個i型移位寄存器加累加器(type-ishift-register-adder-accumulator,sraa-i)電路的串行編碼器。由c個sraa-i電路構成的串行編碼器,在e×b個時鐘周期內完成編碼。該方案需要2×c×b個寄存器、c×b個二輸入與門和c×b個二輸入異或門,還需要e×c×b比特rom存儲循環矩陣的生成多項式。該方案有兩個缺點:一是需要大量存儲器,導致電路成本高;二是串行輸入信息比特,編碼速度慢。
技術實現要素:
cdr系統中1/4碼率qc-ldpc編碼器的現有實現方案存在成本高、編碼速度慢的缺點,針對這些技術問題,本發明提供了一種基于共享機制的qc-ldpc編碼器。
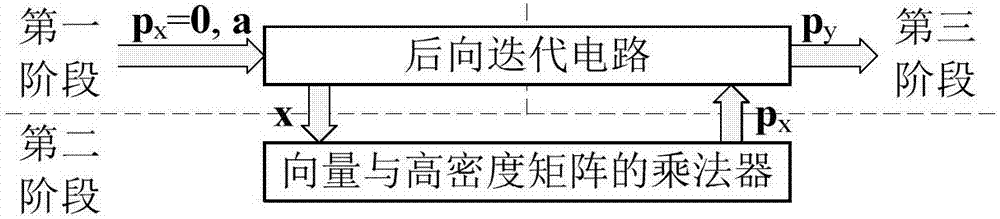
如圖2所示,cdr系統中基于共享機制的qc-ldpc編碼器主要由2部分組成:后向迭代電路和向量與高密度矩陣的乘法器。編碼過程分3步完成:第1步,使用后向迭代電路計算向量py和x;第2步,使用向量與高密度矩陣的乘法器計算部分校驗向量px;第3步,使用后向迭代電路計算部分校驗向量py,從而得到校驗向量p=(px,py)。
本發明提供的cdr系統中1/4碼率qc-ldpc編碼器結構簡單,能在顯著提高編碼速度的條件下,減少存儲器,從而降低成本,提高吞吐量。
關于本發明的優勢與方法可通過下面的發明詳述及附圖得到進一步的了解。
附圖說明
圖1是行列交換后近似下三角校驗矩陣的結構示意圖;
圖2是基于共享機制的qc-ldpc編碼過程;
圖3是后向迭代電路;
圖4是循環左移累加器rla電路的功能框圖;
圖5是由u個rla電路構成的一種向量與高密度矩陣的乘法器;
圖6總結了編碼器各編碼步驟以及整個編碼過程所需的硬件資源和處理時間。
具體實施方式
下面結合附圖對本發明的較佳實施例作詳細闡述,以使本發明的優點和特征能更易于被本領域技術人員理解,從而對本發明的保護范圍作出更為清楚明確的界定。
循環矩陣的行重和列重相同,記作w。如果w=0,那么該循環矩陣是全零矩陣。如果w=1,那么該循環矩陣是可置換的,稱為置換矩陣,它可通過對單位矩陣i循環右移若干位得到。qc-ldpc碼的校驗矩陣h是由c×t個b×b階循環矩陣hi,k(1≤i≤c,1≤k≤t,t=e+c)構成的如下陣列:
通常情況下,校驗矩陣h中的任一循環矩陣要么是全零矩陣(w=0)要么是置換矩陣(w=1)。令循環矩陣hi,k的首行gi,k是其生成多項式。因為h是稀疏的,所以gi,k只有1個‘1’,甚至沒有‘1’。
h的前e塊列對應的是信息向量a,后c塊列對應的是校驗向量p。以b比特為一段,信息向量a被等分為e段,即a=(a1,a2,…,ae);校驗向量p被等分為c段,即p=(p1,p2,…,pc)。
對校驗矩陣h進行行交換和列交換操作,將其變換成近似下三角形狀halt,如圖1所示。在圖1中,所有矩陣的單位都是b比特而不是1比特。a是由(c-u)×e個b×b階循環矩陣構成,b是由(c-u)×u個b×b階循環矩陣構成,t是由(c-u)×(c-u)個b×b階循環矩陣構成,c是由u×e個b×b階循環矩陣構成,d是由u×u個b×b階循環矩陣構成,e是由u×(c-u)個b×b階循環矩陣構成。t是下三角矩陣,u反映了校驗矩陣halt與下三角矩陣的接近程度。在圖1中,矩陣a和c對應信息向量a,矩陣b和d對應一部分校驗向量px,矩陣t和e則對應余下的校驗向量py。p=(px,py)。上述矩陣和向量滿足如下關系:
pxt=φ(et-1aat+cat)(3)
pyt=t-1(aat+bpxt)(4)其中,φ=(et-1b+d)-1,上標t和-1分別表示轉置和逆。眾所周知,循環矩陣的逆、乘積、和仍然是循環矩陣。因此,φ也是由循環矩陣構成的陣列。雖然矩陣e、t、b和d都是稀疏矩陣,但通常情況下φ不再稀疏而是高密度的。
令qt=t–1aat,xt=eqt+cat以及pxt=φxt(或px=xφt)。那么,式(3)和(4)可變為:
和
[abt][apxpy]t=0(6)因為式(5)和(6)中的兩個矩陣與t一樣都是下三角矩陣,所以式(5)中的x和式(6)中的py都可采用后向迭代的計算方式。
如果px=0,那么pyt=t–1aat=qt,且式(5)可改寫為
其中,
v=[apxpyx](8)
也就是說,如果px初始化為全零,那么x也可由式(7)計算出來。清零矩陣x對角線上所有的單位矩陣,可得
對比式(10)和圖1可見,h′只是比h少了些非零循環矩陣。
式(7)可展開為如下一組等式:
根據以上討論,可給出一種分三階段的qc-ldpc編碼過程,如圖2所示。φ涉及向量與高密度矩陣的乘法,而x涉及后向迭代計算。第二階段使用向量與高密度矩陣的乘法器實現px=xφt。因為x是下三角矩陣,所以第一和第三階段共享同一后向迭代電路分別計算x和py。在第一階段,px被初始化為全零,py實際上是q;在第三階段,px和py是各自的實際值,且無需計算x。
令v=(v1,v2,…,vt+u),其中,每一段vk都是v的連續b比特組成,1≤k≤t+u。由式(7)和圖1可知,[pyx]=(vt–c+u+1,vt–c+u+2,…,vt+u)。以vt–c+u+i=vi′為例,其中,i′=t–c+u+i,1≤i≤c,t–c+u+1≤i′≤t+u。對于給定的qc-ldpc碼,i′與i同步變化。因為下三角矩陣x是從h派生而來,所以hi,i′=i,且當k>i′時,hi,k=0。由式(7)可知,x的第i塊行與vt的乘積滿足
非零循環矩陣hi,k相對于b×b階單位矩陣的循環右移位數是si,k,其中,0≤si,k<b,假設在h′的第i塊行中有n個非零循環矩陣,它們的塊列號分別是k1、k2、…、kn,且1≤k1<k2<…<kn<i′。那么,式(12)變為
或者說
其中,上標rs(s)和ls(s)分別表示對矩陣(或向量)循環右移或循環左移s位。
如果vi′按照i′升序依次由式(14)計算,那么py和x可逐段計算出來。該后向迭代過程可由圖3所示電路加以實現。該后向迭代電路由1個桶形移位器、3個累加器、2個延時器、2個比較器、1個復用器、1塊只讀存儲器(rom)和1塊隨機訪問存儲器(ram)組成。在圖3中,桶形移位器采用二分結構和流水線機制,固有延時是τ個時鐘周期,其中,τ={log2b}表示τ是不小于log2b的最小整數。桶形移位器對一個b比特數循環左移若干位,累加器1對桶形移位器的輸出進行累加。如圖3所示,h′中所有非零循環矩陣,即h1,k1、h1,k2、…、h1,kn、h2,k1、h2,k2、…、hi,kn、hi+1,k1、…、hc,kn的塊列號和移位數逐塊行地存儲于rom中。通常,hi,kn的下標kn大于hi+1,k1的下標k1。因此,當rom輸出的源地址k變小時,式(14)中目的地址i′和塊行號i應同時加1。與此同時,累加器1的內容,即目的操作數vi′被寫入ram中,然后被清零,以便計算下一個目的操作數。延時器1延時1個時鐘周期,它與比較器1配合判斷k是否變小。延時器2延時τ個時鐘周期是為了補償桶形移位器的固有延時。累加器3產生目的地址i′。ram根據rom輸出的源地址k輸出源操作數vk,把目的操作數vi′寫入目的地址i′。
從理論上講,在式(14)中,源地址k一定小于目的地址i′。實際上,由于延時器2延時τ個時鐘周期,可能會出現k≥i′。當出現這種情況時,ram輸出的vk是無效的,這是因為vi′還未計算出來,更不要說vk。當k≥i′時,rom暫停輸出新數據,且送入桶形移位器的數不是vk而是0。根據比較器2的輸出,累加器2產生rom的地址,復用器從vk和0中二選一送給桶形移位器。
在第三階段,如果b的前r塊列是全零,那么py的前r段也無需計算,這是因為這些段恰好等于第一階段計算出來的py的前r段。又因為在第三階段無需計算x,故在第三階段無需使用h′的前r塊行和后u塊行。假設在h′中及其中間的(c–r–u)塊行分別有α和β個非零循環矩陣。由于存在路徑延時,在第一和第三階段計算x和py所花的總時間下限是(α+β+2τ)個時鐘周期。對于cdr系統中的1/4碼率qc-ldpc碼,α和β分別是84和47。
如果只考慮圖3中rom、ram、桶形移位器和累加器1等主要組成部分的資源消耗,那么該后向迭代電路需要τb個觸發器、b個二輸入異或門、(t+u)b比特的ram和({log2t}+{log2b})β比特的rom。
使用后向迭代電路計算向量py和x的步驟如下:
第1步,清零累加器1和累加器2,初始化累加器3為i′=t–c+u+1;
第2步,rom根據累加器2產生的地址輸出源地址k及移位數si,k;
第3步,ram根據源地址k輸出源操作數vk,比較器2判斷源地址k是否小于目的地址i′,若k<i′,則比較器2輸出1,否則,比較器2輸出0,延時器1與比較器1配合判斷k是否變小,若變小,則比較器1輸出1,否則,比較器1輸出0,累加器3對延時τ個時鐘周期的比較器1輸出進行累加,產生目的地址i′;
第4步,根據比較器2的輸出,累加器2產生rom地址,復用器從vk和0中二選一送給桶形移位器,若比較器2的輸出是1,則累加器2遞增rom地址,復用器把vk送給桶形移位器,否則,累加器2保持rom地址不變,復用器把0送給桶形移位器;
第5步,桶形移位器對復用器的輸出循環左移si,k位,累加器1對桶形移位器的輸出進行累加,當延時器2的輸出為1時,累加器1的內容即為目的操作數vi′,vi′被寫入ram的目的地址i′中,與此同時,累加器1被清零,以便計算下一個目的操作數;
第6步,重復步驟2~5,直到[pyx]=(vt–c+u+1,vt–c+u+2,…,vt+u)逐段存儲于ram中。
由式(7)、圖1和v=(v1,v2,…,vt+u)可知,px=(vt–c+1,vt–c+2,…,vt–c+u)和x=(vt+1,vt+2,…,vt+u)。pxt=φxt等價于px=xφt。令x=(x1,x2,…,xu×b)。定義u比特向量sn=(xn,xn+b,…,xn+(u-1)×b),其中1≤n≤b。令φj(1≤j≤u)是由φt的第j塊列中所有循環矩陣生成多項式構成的u×b階矩陣。則有
vt-c+j=(…((0+s1φj)ls(1)+s2φj)ls(1)+…+sbφj)ls(1)(15)
由式(15)可得到一種循環左移累加器(rotate-left-accumulator,rla)電路,如圖4所示。查找表的索引是u比特向量sn,查找表lj事先存儲可變的u比特向量與固定的φj的所有可能乘積,故需2ub比特的只讀存儲器(read-onlymemory,rom)。b比特寄存器r1,r2,…,ru分別用于緩沖向量x的向量段vt+1,vt+2,…,vt+u,b比特寄存器ru+j用于存儲px的校驗段vt–c+j。1個rla電路計算向量vt–c+j需要b個時鐘周期。
對于cmmb系統,使用u=3個rla電路同時計算px=(vt–c+1,vt–c+2,…,vt–c+u)是一種合理方案,如圖5所示的向量與高密度矩陣的乘法器。向量與高密度矩陣的乘法器由u個查找表l1,l2,…,lu、2u個b比特寄存器r2,1,r2,2,…,r2,2u和u個b位二輸入異或門x2,1,x2,2,…,x2,u組成。查找表l1,l2,…,lu分別存儲可變的u比特向量與固定的矩陣φ1,φ2,…,φu的所有可能乘積,寄存器r2,1,r2,2,…,r2,u分別用于緩沖向量x的向量段vt+1,vt+2,…,vt+u,寄存器r2,u+1,r2,u+2,…,r2,2u分別用于存儲px的校驗段vt–c+1,vt–c+2,…,vt–c+u。u個rla電路需使用ub個二輸入異或門,2uub比特的rom和2ub個寄存器。u個rla電路計算向量px需要b個時鐘周期。使用向量與高密度矩陣的乘法器計算向量px的步驟如下:
第1步,清零寄存器r2,u+1,r2,u+2,…,r2,2u,輸入向量段vt+1,vt+2,…,vt+u,將它們分別存入寄存器r2,1,r2,2,…,r2,u中;
第2步,寄存器r2,1,r2,2,…,r2,u同時循環左移1次,異或門x2,1,x2,2,…,x2,u分別對查找表l1,l2,…,lu的輸出和寄存器r2,u+1,r2,u+2,…,r2,2u的內容進行異或,異或結果被循環左移1次后分別存回寄存器r2,u+1,r2,u+2,…,r2,2u;
第3步,重復第2步b-1次,完成后,寄存器r2,u+1,r2,u+2,…,r2,2u存儲的內容分別是校驗段vt–c+1,vt–c+2,…,vt–c+u,它們構成了部分校驗向量px。
本發明提供了一種基于共享機制的qc-ldpc編碼方法,適用于cdr系統中的1/4碼率qc-ldpc碼,其編碼步驟描述如下:
第1步,使用后向迭代電路計算向量py和x;
第2步,使用向量與高密度矩陣的乘法器計算部分校驗向量px;
第3步,使用后向迭代電路計算部分校驗向量py,從而得到校驗向量p=(px,py)。
圖6總結了編碼器各編碼步驟以及整個編碼過程所需的硬件資源消耗和處理時間。
從圖6不難看出,整個編碼過程大約共需(α+β+2τ+b)=403個時鐘周期,遠小于基于c個sraa-i電路的串行編碼方法所需的e×b=2304個時鐘周期。
cdr標準中1/4碼率qc-ldpc編碼器的現有解決方案需要e×c×b=62208比特rom,而本發明需要({log2t}+{log2b})β+2uub=1688比特rom。
綜上可見,與傳統的串行sraa法相比,本發明具有編碼速度快、存儲器消耗少等優點。
以上所述,僅為本發明的具體實施方式之一,但本發明的保護范圍并不局限于此,任何熟悉本領域的技術人員在本發明所揭露的技術范圍內,可不經過創造性勞動想到的變化或替換,都應涵蓋在本發明的保護范圍之內。因此,本發明的保護范圍應該以權利要求書所限定的保護范圍為準。
- 還沒有人留言評論。精彩留言會獲得點贊!