一種并行的極化碼譯碼方法及裝置與流程
本發明屬于無線通信領域,特別涉及一種針對極化碼的并行譯碼方法。
背景技術:
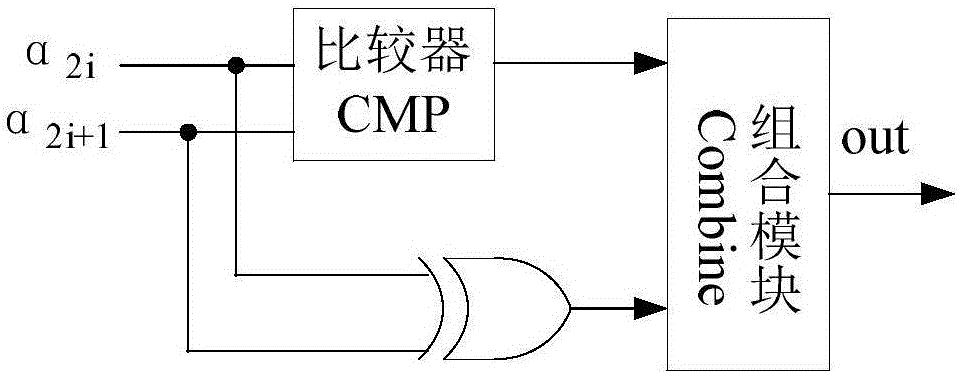
:Polar碼是目前唯一能通過嚴格的數學方法證明可以達到信道容量的編碼方式,是5G標準的有力競爭者。Arikan在2008年提出了信道極化(Channelpolarization:Amethodforconstructingcapacity-achievingcodes,ArikanE.,IEEEInternationalSymposiumonInformationTheory(ISIT),2008:1173-1177.)的理論之后,于2009年提出了SC(Successive-Cancellation)譯碼算法(Channelpolarization:Amethodforconstructingcapacity-achievingcodesforsymmetricbinary-inputmemorylesschannels,ArikanE.,IEEETrans.Inf.Theory,55(7),2009:3051-3073.),SC算法串行譯碼的性質導致了其低吞吐率、高譯碼延遲的缺點,因此對Polar碼并行譯碼的研究受到了越來越多的關注。Amin等學者于2011年提出了SSC(SimplifiedSuccessive-Cancellation)算法(ASimplifiedSuccessive-CancellationDecoderforPolarCodes,Amin,Alamdar-Yazdi,FrankR.Kschischang,IEEECommunicationsLetters,15(12),2011:1378-1380.),SSC算法中定義了RATE0和RATE1兩種節點。當節點的葉子全為固定位時,節點是RATE0節點,全為信息位時,節點是RATE1節點。這兩種節點可直接譯碼,不需要遍歷子樹,SSC算法通過裁剪SC算法的譯碼樹,減少了需要激活的節點數量,因此具有更高的吞吐率。在SSC算法的基礎上,GabiSarkis等學者于2013年提出了ML-SSC(MaxLikelihoodSimplifiedSuccessive-Cancellation)算法(IncreasingtheThroughputofPolarDecoders,GabiSarkis,WarrenJ.Gross.IEEECommunicationsLetters,17(4),2013:725-728.)。與SSC算法相比,ML-SSC算法增加了RATE0-RATE1節點,通過尋找估計值與LLR(Log-LikelihoodRatio,對數似然比)的乘積和的最大值,來獲得該種節點的譯碼結果。激活節點數量的減少使ML-SSC算法具有更高的吞吐率,但相應增加了ML-SSC算法的計算量。同樣在2013年,GabiSarkis等學者在SSC算法的基礎上又提出了Fast-SSC(FastSimplifiedSuccessive-Cancellation)算法(FastPolarDecoders:AlgorithmandImplementation,GabiSarkis,PascalGiard,AlexanderVardy,ClaudeThibeault,WarrenJ.Gross,IEEEjournalonSelectedAreasinCommunications,32(5),2014:946-957.),Fast-SSC算法在SSC基礎上增加了SPC和REP兩種節點。SPC節點只有第一位是固定位,其余位是信息位,REP節點只有最后一位是信息位,其余位是固定位。通過對SSC算法譯碼樹的裁剪,進一步提高了譯碼器的吞吐率。SSC、ML-SSC和Fast-SSC雖然具有較高的吞吐率,但譯碼延遲較長。LiBin等學者在2013年提出了Parallel-SC算法(ParallelDecodersofPolarCodes,BinLi,HuiShen,DavidTse,[2016-8-25],heep://arxiv.org/abs/1401.3753.),通過幾個SC譯碼器同時工作,可以有效的降低譯碼延遲,但采用的SC算法使譯碼器的吞吐率較低。技術實現要素:為了尋求一種譯碼延遲低、吞吐率較高的譯碼方法,本發明提出了一種并行的極化碼譯碼方法。本發明中所述極化碼(Polar碼)可由3個因素唯一的確定,碼長N=2n,碼率R=K/N,位置信息序列A。序列A是一個長度為N的(0,1)序列,0表示固定位,1表示信息位。一個長為N的Polar碼字可以拆分成兩個長為N/2的碼字,Polar碼可以表示成式(3)的形式,其相關性如式(4)所示。式(3)中x是一個長度為N的Polar碼字,a和b是從x拆分出的兩個長度為N/2的序列,v是由a和b合成x時的中間序列,n=log2N,表示F的(n-1)次克羅內克積,B是反序重排序列,B的定義如下:對L1N進行比特反序重排,得到序列S1N,即令Li=Sπ(i);比特反序函數π(i)定義如下:令i用二進制表示為(b1,b2,…,bm);則π(i)的值對應的二進制表示為(bm,bm-1,…,b1);本發明中所提出的并行的極化碼譯碼方法具體步驟如下:步驟一、構建譯碼樹,將長度為N的序列A按奇偶位拆分成兩個序列Aa和Ab,在Aa中0的位置放置固定位節點,1的位置放置信息位節點,以放置好的N/2個節點為葉子構建一棵完全二叉樹Ta,在Ab中0的位置放置固定位節點,1的位置放置信息位節點,以放置好的N/2個節點為葉子構建一棵完全二叉樹Tb;所構建的兩棵二叉樹Ta和Tb分別是兩個并行快速譯碼器PFDa和PFDb的譯碼樹;兩棵譯碼樹中的父節點根據孩子節點類型定義;在兩棵譯碼樹中,當節點的葉子全為固定位時,節點是RATE0節點;當節點的葉子全為信息位時,節點是RATE1節點;當節點的葉子只有第一位是固定位,其余位是信息位時,節點是SPC節點;當節點的葉子只有最后一位是信息位,其余位是固定位時,節點是REP節點。當節點的葉子一半是固定位,一半是信息位時,節點是RATE0-RATE1節點;除去上述5類節點及其子樹,剩余的節點是OTHER型節點。步驟二、譯碼器接收一幀信道α數據,所述信道α是一個序列,信道α的長度和譯碼使用的Polar碼字的長度相等,都為N,其取值為(α0,α1…αN-1)。步驟三、利用信道α的前一半(α0…αN/2-1)初始化譯碼樹Ta,利用后一半數據(αN/2…αN-1)初始化譯碼樹Tb,譯碼樹Ta用于并行快速譯碼器PFDa的譯碼,譯碼樹Tb用于并行快速譯碼器PFDb的譯碼。步驟四、譯碼器PFDa和PFDb由根節點開始,按照深度優先的順序同時激活兩棵譯碼樹的節點;根節點的輸入是信道α,除根節點外其他節點的輸入是中間值α,中間值α由F運算,如式(1)所示,或G運算,如式(2)所示,獲得。中間值α是譯碼樹中每個節點進行譯碼時的輸入值,中間值α是個序列中間值α的序列長度和激活節點的序列長度nv相等。式(1)和式(2)中,αv表示激活節點的α值,αl表示激活節點左孩子的中間值α,αr表示激活節點右孩子的中間值α。激活節點的輸出是該節點的子碼估值,即序列β,其長度和該節點的序列長度相等,該節點長度等于該節點的葉子數。式(2)中,βl表示激活節點左孩子的子碼估值。當兩棵譯碼樹中的RATE0、RATE1、REP或SPC節點被激活時,根據兩棵譯碼樹中激活節點的類型,譯碼器選擇不同的譯碼方法計算節點的子碼估值β1)當PFDa和PFDb中的激活節點同為RATE0節點時,兩節點合稱為RATE0-P節點;此時,PFDa和PFDb中該節點的子碼估值β同時被判定為0,即式(10)所示。βa[i]=βb[i]=0,0≤i<nv(10)2)當PFDa和PFDb中的激活節點同為RATE1節點時,兩節點合稱為RATE1-P節點;當RATE1-P節點被激活,PFDa和PFDb根據式(11)進行獨立譯碼,分別獲得兩個子碼估值βa和βb。3)當PFDa中的激活節點為SPC節點,PFDb中的激活節點為RATE1節點時,兩節點合稱為RATE1B節點,當RATE1B節點被激活,首先根據式(12)組合兩個譯碼器中相應激活節點的中間值α,之后對組合得到的中間值α進行硬判決,如式(13)所示,判決結果用序列HD表示。由于硬判決只有0和1兩種結果,因此序列HD是一個只含0、1的序列。之后對判決結果進行奇偶校驗,即檢測序列HD中1的個數,如式(14)所示,校驗結果用parity表示。如果HD中有偶數個1,即滿足奇偶校驗,則硬判決結果就是節點的子碼估值β,如果HD中有奇數個1,即不滿足奇偶校驗,則尋找絕對值最小的中間值α的判決結果,并對該判決結果進行取反運算,如果該判決結果是0,取反后變為1,如果該判決結果是1,取反后變為0。取反運算后的HD序列為該節點的子碼估值β,如式(15)和式(16)所示,其中j表示絕對值最小的中間值α的標號。α=[αaαb](12)j=argimin|α[i]|,0≤i<nv(15)4)當PFDa和PFDb中的激活節點同為REP節點時,兩節點合稱為REP-P節點,當REP-P節點被激活時,PLDa和PLDb根據式(17)獨立譯碼,分別獲得兩個子碼估值βa和βb。5)當PFDa中的激活節點為RATE0節點,PFDb中的激活節點為REP節點時,兩節點合稱為REPB節點,兩個REPB節點的譯碼結果相同,是對兩個節點共2×nv個中間值α和的硬判決,根據式(18)和式(19),獲得兩個子碼估值βa和βb。6)當PFDa和PFDb中的激活節點同為SPC節點時,兩節點合稱為SPC-P節點,。當SPC-P節點被激活,PFDa和PFDb根據式(15)(16)(17)(18)(19)獨立譯碼,分別獲得兩個子碼估值βa和βb。7)當PFDa中的激活節點為RATE0-RATE1節點,PFDb中的激活節點為SPC節點時,兩節點合稱為SPCB1節點。當SPCB1節點被激活,PFDa將RATE0-RATE1節點的中間值α作為F運算的輸入做一次F運算,運算結果用αa表示。PFDb將SPC節點的中間值α作為F運算的輸入做一次F運算,運算結果用αb表示。將αa和αb作為公式(18)的輸入計算α,將α作為公式(19)的輸入,公式(19)的輸出βa用βa0表示,公式(19)的另一個輸出βb用βb0表示。之后PFDa將αa和βa0作為G運算的輸入做一個G運算,按照正數為0負數為1的規則,將G運算的結果轉換成只含0、1的序列,用βa1表示,PFDb將αb和βb0作為G運算的輸入做一個G運算,同樣按照正數為0負數為1的規則將運算結果轉換成只含0、1的序列,用βb1表示。將[βa0,βa1]作為公式(20)的輸入,公式(20)的輸出就是RATE0-RATE1節點的β值,將[βb0,βb1]作為公式(21)的輸入,公式(21)的輸出就是SPC節點的β值。8)當PFDa中的激活節點為REP節點,PFDb中的激活節點為SPC節點時,兩節點合稱為SPCB2節點。當SPCB2節點被激活,PFDa將REP節點的中間值α作為F運算的輸入做一次F運算,運算結果用αa表示。PFDb將SPC節點的中間值α作為F運算的輸入做一次F運算,運算結果用αb表示。將αa和αb作為公式(18)的輸入計算α,將α作為公式(19)的輸入,公式(19)的輸出βa用βa0表示,公式(19)的另一個輸出βb用βb0表示。之后PFDa將αa和βa0作為G運算的輸入做一個G運算,PFDb將αb和βb0作為G運算的輸入做一個G運算。將兩個G運算的結果帶入公式(12),計算完公式(12)之后,再利用公式(13)(14)(15)(16)計算REP節點和SPC節點的β,分別用βa0和βb0表示。將βa0作為公式(20)的輸入,公式(20)的輸出就是REP節點的β值,將βb0作為公式(21)的輸入,公式(21)的輸出就是SPC節點的β值。當OTHER型節點被激活時,譯碼器計算下一個激活節點的中間值α,為譯碼下一個節點做準備。步驟五、當譯碼器PFDa和PFDb中的激活節點是RATE0、RATE1、REP、SPC時,將該節點β值乘以生成矩陣G獲得局部碼字估值u,完成一個激活節點的譯碼;所述矩陣其中m=log2nv,表示F的m次克羅內克積,B為反序重排序列。步驟六、譯碼器PFDa和PFDb更新激活節點號,激活下一個節點;步驟七、重復步驟四至步驟六,至兩棵譯碼樹中所有的節點被激活;步驟八、將譯碼器PFDa所有的局部碼字估值按獲得的順序拼接,就是譯碼器PFDa的碼字估值,將譯碼器PFDb所有的局部碼字估值按獲得的順序拼接,就是譯碼器PFDb的碼字估值。將譯碼器PFDa的碼字估值與譯碼器PFDb的碼字估值異或運算,并替換譯碼器PFDa的碼字估值。步驟九、將譯碼器PFDa的碼字估值作為序列的前一半,即譯碼器PFDb的碼字估值作為序列的后一半,即合并兩個譯碼器的碼字估值,獲得序列即步驟十、輸出序列一幀信道α數據的譯碼結束。一種用于實現該譯碼方法的譯碼裝置,包括:信道α存儲器、中間值αa存儲器、中間值αb存儲器、子碼估值βa存儲器、子碼估值βb存儲器、Ga乘生成矩陣模塊、Gb乘生成矩陣模塊、組合模塊、控制器和并行的譯碼器PFDa和PFDb。信道α存儲器接收到的信道α分為兩部分分別送入中間值αa存儲器和中間值αb存儲器,中間值αa存儲器和中間值αb存儲器分別用于存儲計算過程中的中間值αa和中間值αb;子碼估值βa存儲器和子碼估值βa存儲器分別用于存儲計算過程中的子碼估值βa和子碼估值βa;Ga乘生成矩陣模塊和Gb乘生成矩陣模塊分別用于生成矩陣G并獲得矩陣G與子碼估值βa和子碼估值βa的乘積,即各自的局部碼字估值u;模塊將Ga乘生成矩陣模塊和Gb乘生成矩陣模塊獲得的局部碼字估值u合并,輸出序列并行的譯碼器PFDa和PFDb分別讀取中間值αa存儲器、中間值αb存儲器、子碼估值βa存儲器和子碼估值βa存儲器中的中間值αa、中間值αb存儲器、子碼估值βa和子碼估值βa,并將計算得到的激活節點中間值αa和中間值αb存入中間值αa存儲器和中間值αb存儲器,將子碼估值βa和子碼估值βa存入子碼估值βa存儲器和子碼估值βa存儲器;控制器用于控制其他各個模塊按照所述譯碼方法完成譯碼的過程。并行的譯碼器PFDa和PFDb中包含如下運算架構:1)F運算用來求激活節點左孩子的α值,其硬件架構如圖2所示,選擇兩個相鄰α值的符號做異或運算,作為輸出的符號,選擇較小的絕對值作為輸出的數值位。2)G運算用來獲得激活節點右孩子的α值,硬件架構如圖3所示。G運算有三個參數,除了激活節點本身的兩個α值,還需要左孩子反饋的β值即βl。β值不同,對兩個α的運算不同,當β為0時,兩個α相加,當β為1時,兩個α相減。3)C運算將激活節點左孩子反饋來的βl和右孩子反饋來的βr計算自身的β值,硬件架構如圖4所示,其中偶數位的β值是βl與βr的異或,奇數位的β值與βr相等。4)REP和REPB運算分別用來計算REP節點和REPB節點的β值,兩個都是累加運算,硬件架構如圖5所示,根據REP節點和REPB節點的特殊結構,對激活節點的所有α值求和,對求和結果取符號位,便是激活節點的β值,其β值為全0或全1序列。5)SPC運算和RATE1B運算分別用來求SPC節點和RATE1B節點的β值,根據RATE1B節點的特殊結構,其實質上是一個較長的SPC節點,因此具有和SPC運算相同的硬件架構,如圖6所示。首先獲取輸入的符號位,并對其進行奇偶校驗,若滿足校驗則符號位便是激活節點的β值,若不滿足校驗,對絕對值最小的符號位進去取反,取反后的結果作為激活節點的β值。6)SPCB1運算用來計算SPCB1節點的β值,其硬件架構如圖7所示,SPCB1節點的結構比較復雜,首先需要將SPCB1節點拆成一個REP節點,一個RATE1節點,通過F和G運算分別計算兩個節點的α值,再將REP運算的結果和G運算的符號位合并成最終的β值。7)SPCB2運算用來計算SPCB2節點的β值,其硬件架構如圖8所示,首先需要將一個SPCB2節點拆分成一個REP節點和一個SPC節點,利用F運算和G運算分別計算兩個節點的α值,在根據REP運算和SPC運算計算兩個節點的β值,經過合并最終獲得激活節點的β值。本發明的有益效果:本發明公開的極化碼的譯碼方法,針對Fast-SSC算法高譯碼延遲的缺點,提出了并行快速方法,由兩個并行的Fast-SSC譯碼器組成,有效降低了Fast-SSC算法的譯碼延遲。與Fast-SSC具有相同的誤碼率,但譯碼速度比Fast-SSC算法更快。當兩個Fast-SSC譯碼器并行時,并行度比Fast-SSC算法提高40%左右。附圖說明圖1并行的極化碼譯碼裝置架構;圖2F運算的硬件架構;圖3G運算的硬件架構;圖4C運算的硬件架構;圖5REP和REPB運算的硬件架構;圖6SPC和RATE1B運算的硬件架構;圖7SPCB1運算的硬件架構;圖8SPCB2運算的硬件架構;圖9并行的極化碼譯碼流程圖;圖10RATE0-P節點示意圖;圖11RATE1-P節點示意圖;圖12RATE1N節點示意圖;圖13REP-P節點示意圖;圖14REPN節點示意圖;圖15SPC節點示意圖;圖16SPCB1節點及譯碼方法示意圖;圖17SPCB2節點及譯碼方法示意圖;圖18誤比特率曲線;具體實施方式本實施例中以所提出的并行的極化碼譯碼方法,如圖9所示,具體步驟如下:本實施例碼長N=1024,碼率R=0.5;位置信息A=[0000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000100000000000000000000000000000000000000000000000000000000000000010000000000000000000000000000000100000000000101110001011101111111000000000000000000000000000000000000000000000000000000000000011100000000000000000000000100010111000000010001011100111111111111110000000000000001000000010001111100000011011111110111111111111111000101110111111101111111111111110111111111111111111111111111111100000000000000000000000000000000000000000000000100000001000101110000000000000001000000010111111100000111011111110111111111111111000000000000011100010111011111110001011101111111111111111111111100011111111111111111111111111111111111111111111111111111111111110000000100010111000101111111111100111111111111111111111111111111011111111111111111111111111111111111111111111111111111111111111101111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111111];步驟一、構建譯碼樹,將序列A按奇偶位拆分成兩個序列Aa=[00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000100010111000000000000000000000000000000010000000000000001000000010111111100000000000000110001011101111111000101110111111101111111111111110000000000000000000000000000000100000000000001110001011101111111000000010001011100010111111111110011111111111111111111111111111100000001000111110111111111111111011111111111111111111111111111110111111111111111111111111111111111111111111111111111111111111111];Ab=[00000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000000100010111000000000000000000000000000000010000000000000001000000010111111100000000000000110001011101111111000101110111111101111111111111110000000000000000000000000000000100000000000001110001011101111111000000010001011100010111111111110011111111111111111111111111111100000001000111110111111111111111011111111111111111111111111111110111111111111111111111111111111111111111111111111111111111111111];在Aa中0的位置放置固定位節點,1的位置放置信息位節點,以放置好的512個節點為葉子構建一棵完全二叉樹Ta,在Ab中0的位置放置固定位節點,1的位置放置信息位節點,以放置好的512個節點為葉子構建一棵完全二叉樹Tb;所構建的兩棵二叉樹Ta和Tb分別是兩個并行快速譯碼器PFDa和PFDb的譯碼樹;兩棵譯碼樹中的父節點根據孩子節點類型定義;在兩棵譯碼樹中,當節點的葉子全為固定位時,節點是RATE0節點;當節點的葉子全為信息位時,節點是RATE1節點;當節點的葉子只有第一位是固定位,其余位是信息位時,節點是SPC節點;當節點的葉子只有最后一位是信息位,其余位是固定位時,節點是REP節點。當節點的葉子一半是固定位,一半是信息位時,節點是RATE0-RATE1節點;除去上述5類節點及其子樹,剩余的節點是OTHER型節點。Ta和Tb中的節點如表1所示。表1節點類型TaTbRATE0910RATE12224REP1413SPC1514RATE0-RATE120OTHER5960步驟二、譯碼器接收一幀信道α數據,所述信道α是一個序列,信道α的長度和譯碼使用的Polar碼字的長度相等,都為1024,其取值為(α0,α1…α1023)。步驟三、利用信道α的前一半(α0…α511)初始化譯碼樹Ta,利用后一半數據(α512…α1023)初始化譯碼樹Tb,譯碼樹Ta用于并行快速譯碼器PFDa的譯碼,譯碼樹Tb用于并行快速譯碼器PFDb的譯碼。步驟四、譯碼器PFDa和PFDb由根節點開始,按照深度優先的順序同時激活兩棵譯碼樹的節點;根節點的輸入是信道α,除根節點外其他節點的輸入是中間值α,中間值α由F運算,如式(1)所示,或G運算,如式(2)所示,獲得。中間值α是譯碼樹中每個節點進行譯碼時的輸入值,中間值α是個序列,中間值α的序列長度和激活節點的序列長度nv相等。式(1)和式(2)中,αv表示激活節點的中間值α,αl表示激活節點左孩子的中間值α,αr表示激活節點右孩子的中間值α。激活節點的輸出是該節點的子碼估值,即序列β,其長度和該節點的長度相等,該節點長度等于該節點的葉子數。式(2)中,βl表示激活節點左孩子的子碼估值。當兩棵譯碼樹中的RATE0、RATE1、REP或SPC節點被激活時,根據兩棵譯碼樹中激活節點的類型,譯碼器選擇不同的譯碼方法計算節點的子碼估值β:1)當PFDa和PFDb中的激活節點同為RATE0節點時,兩節點合稱為RATE0-P節點;此時,PFDa和PFDb中該節點的子碼估值β同時被判定為0,即式(10)所示。βa[i]=βb[i]=0,0≤i<nv(10)2)當PFDa和PFDb中的激活節點同為RATE1節點時,兩節點合稱為RATE1-P節點;當RATE1-P節點被激活,PFDa和PFDb根據式(11)進行獨立譯碼,分別獲得兩個子碼估值βa和βb。3)當PFDa中的激活節點為SPC節點,PFDb中的激活節點為RATE1節點時,兩節點合稱為RATE1B節點,當RATE1B節點被激活,首先根據式(12)組合兩個譯碼器中相應激活節點的中間值α,之后對組合得到的中間值α進行硬判決,如式(13)所示,判決結果用序列HD表示。由于硬判決只有0和1兩種結果,因此序列HD是一個只含0、1的序列。之后對判決結果進行奇偶校驗,即檢測序列HD中1的個數,如式(14)所示,校驗結果用parity表示。如果HD中有偶數個1,即滿足奇偶校驗,則硬判決結果就是節點的子碼估值β,如果HD中有奇數個1,即不滿足奇偶校驗,則尋找絕對值最小的中間值α的判決結果,并對該判決結果進行取反運算,如果該判決結果是0,取反后變為1,如果該判決結果是1,取反后變為0。取反運算后的HD序列為該節點的子碼估值β,如式(15)和式(16)所示,其中j表示絕對值最小的中間值α的標號。α=[αaαb](12)j=argimin|α[i]|,0≤i<nv(15)4)當PFDa和PFDb中的激活節點同為REP節點時,兩節點合稱為REP-P節點,當REP-P節點被激活時,PLDa和PLDb根據式(17)獨立譯碼,分別獲得兩個子碼估值βa和βb。5)當PFDa中的激活節點為RATE0節點,PFDb中的激活節點為REP節點時,兩節點合稱為REPB節點,兩個REPB節點的譯碼結果相同,是對兩個節點共2×nv個中間值α和的硬判決,根據式(18)和式(19),獲得兩個子碼估值βa和βb。6)當PFDa和PFDb中的激活節點同為SPC節點時,兩節點合稱為SPC-P節點,。當SPC-P節點被激活,PFDa和PFDb根據式(15)(16)(17)(18)(19)獨立譯碼,分別獲得兩個子碼估值βa和βb。7)當PFDa中的激活節點為RATE0-RATE1節點,PFDb中的激活節點為SPC節點時,兩節點合稱為SPCB1節點。當SPCB1節點被激活,PFDa將RATE0-RATE1節點的中間值α作為F運算的輸入做一次F運算,運算結果用αa表示。PFDb將SPC節點的中間值α作為F運算的輸入做一次F運算,運算結果用αb表示。將αa和αb作為公式(18)的輸入計算α,將α作為公式(19)的輸入,公式(19)的輸出βa用βa0表示,公式(19)的另一個輸出βb用βb0表示。之后PFDa將αa和βa0作為G運算的輸入做一個G運算,按照正數為0負數為1的規則,將G運算的結果轉換成只含0、1的序列,用βa1表示,PFDb將αb和βb0作為G運算的輸入做一個G運算,同樣按照正數為0負數為1的規則將運算結果轉換成只含0、1的序列,用βb1表示。將[βa0,βa1]作為公式(20)的輸入,公式(20)的輸出就是RATE0-RATE1節點的β值,將[βb0,βb1]作為公式(21)的輸入,公式(21)的輸出就是SPC節點的β值。8)當PFDa中的激活節點為REP節點,PFDb中的激活節點為SPC節點時,兩節點合稱為SPCB2節點。當SPCB2節點被激活,PFDa將REP節點的中間值α作為F運算的輸入做一次F運算,運算結果用αa表示。PFDb將SPC節點的中間值α作為F運算的輸入做一次F運算,運算結果用αb表示。將αa和αb作為公式(18)的輸入計算α,將α作為公式(19)的輸入,公式(19)的輸出βa用βa0表示,公式(19)的另一個輸出βb用βb0表示。之后PFDa將αa和βa0作為G運算的輸入做一個G運算,PFDb將αb和βb0作為G運算的輸入做一個G運算。將兩個G運算的結果帶入公式(12),計算完公式(12)之后,再利用公式(13)(14)(15)(16)計算REP節點和SPC節點的β,分別用βa0和βb0表示。將βa0作為公式(20)的輸入,公式(20)的輸出就是REP節點的β值,將βb0作為公式(21)的輸入,公式(21)的輸出就是SPC節點的β值。當OTHER型節點被激活時,譯碼器計算下一個激活節點的中間值α,為譯碼下一個節點做準備。步驟五、當PFDa和PFDb中的激活節點是RATE0、RATE1、REP、SPC時,將該節點β值乘以生成矩陣G獲得局部碼字估值u,完成一個激活節點的譯碼;所述矩陣其中m=log2nv,表示F的m次克羅內克積,B為反序重排序列。步驟六、譯碼器PFDa和PFDb更新激活節點號,激活下一個節點;步驟七、重復步驟四至步驟六,至兩棵譯碼樹中所有的節點被激活;步驟八、將譯碼器PFDa所有的局部碼字估值按獲得的順序拼接,就是譯碼器PFDa的碼字估值,將譯碼器PFDb所有的局部碼字估值按獲得的順序拼接,就是譯碼器PFDb的碼字估值。將PFDa的碼字估值與譯碼器PFDb的碼字估值異或運算,并替換譯碼器PFDa的碼字估值。步驟九、將譯碼器PFDa的碼字估值作為序列的前一半譯碼器PFDb的碼字估值作為序列的后一半合并兩個譯碼器的碼字估值,獲得序列即步驟十、輸出序列一幀信道α數據的譯碼結束。本實施例中所采用的一種用于實現該譯碼方法的譯碼器的架構如圖1所示,包括:信道α存儲器、中間值αa存儲器、中間值αb存儲器、子碼估值βa存儲器、子碼估值βb存儲器、Ga乘生成矩陣模塊、Gb乘生成矩陣模塊、組合模塊、控制器和并行的譯碼器PFDa和PFDb。信道α存儲器接收到的信道α分為兩部分分別送入中間值αa存儲器和中間值αb存儲器,中間值αa存儲器和中間值αb存儲器分別用于存儲計算過程中的中間值αa和中間值αb;子碼估值βa存儲器和子碼估值βa存儲器分別用于存儲計算過程中的子碼估值βa和子碼估值βa;Ga乘生成矩陣模塊和Gb乘生成矩陣模塊分別用于生成矩陣G并獲得矩陣G與子碼估值βa和子碼估值βa的乘積,即各自的局部碼字估值u;模塊將Ga乘生成矩陣模塊和Gb乘生成矩陣模塊獲得的局部碼字估值u合并,輸出序列并行的譯碼器PFDa和PFDb分別讀取中間值αa存儲器、中間值αb存儲器、子碼估值βa存儲器和子碼估值βa存儲器中的中間值αa、中間值αb存儲器、子碼估值βa和子碼估值βa,并將計算得到的激活節點中間值αa和中間值αb存入中間值αa存儲器和中間值αb存儲器,將子碼估值βa和子碼估值βa存入子碼估值βa存儲器和子碼估值βa存儲器;控制器用于控制其他各個模塊按照所述譯碼方法完成譯碼的過程。并行的譯碼器PFDa和PFDb中包含如下運算架構:1)F運算用來求激活節點左孩子的α值,其硬件架構如圖2所示,選擇兩個相鄰α值的符號做異或運算,作為輸出的符號,選擇較小的絕對值作為輸出的數值位。2)G運算用來獲得激活節點右孩子的α值,硬件架構如圖3所示。G運算有三個參數,除了激活節點本身的兩個α值,還需要左孩子反饋的β值即βl。β值不同,對兩個α的運算不同,當β為0時,兩個α相加,當β為1時,兩個α相減。3)C運算將激活節點左孩子反饋來的βl和右孩子反饋來的βr計算自身的β值,硬件架構如圖4所示,其中偶數位的β值是βl與βr的異或,奇數位的β值與βr相等。4)REP和REPB運算分別用來計算REP節點和REPB節點的β值,兩個都是累加運算,硬件架構如圖5所示,根據REP節點和REPB節點的特殊結構,對激活節點的所有α值求和,對求和結果取符號位,便是激活節點的β值,其β值為全0或全1序列。5)SPC運算和RATE1B運算分別用來求SPC節點和RATE1B節點的β值,根據RATE1B節點的特殊結構,其實質上是一個較長的SPC節點,因此具有和SPC運算相同的硬件架構,如圖6所示。首先獲取輸入的符號位,并對其進行奇偶校驗,若滿足校驗則符號位便是激活節點的β值,若不滿足校驗,對絕對值最小的符號位進去取反,取反后的結果作為激活節點的β值。6)SPCB1運算用來計算SPCB1節點的β值,其硬件架構如圖7所示,SPCB1節點的結構比較復雜,首先需要將SPCB1節點拆成一個REP節點,一個RATE1節點,通過F和G運算分別計算兩個節點的α值,再將REP運算的結果和G運算的符號位合并成最終的β值。7)SPCB2運算用來計算SPCB2節點的β值,其硬件架構如圖8所示,首先需要將一個SPCB2節點拆分成一個REP節點和一個SPC節點,利用F運算和G運算分別計算兩個節點的α值,在根據REP運算和SPC運算計算兩個節點的β值,經過合并最終獲得激活節點的β值。效果驗證本發明方法的誤比特率與Fast-SSC算法和Parallel-SC算法接近,誤比特率曲線如圖18所示。本發明方法同時具有吞吐率高和延遲小的特點。定義并行的極化碼譯碼方法在譯碼并行度與Fast-SSC相比的增長率T如式(22)所示,當被拆分成2個譯碼器PFD時并行度增長率如表2所示。表2當前第1頁1 2 3
相關技術
網友詢問留言
已有0條留言
- 還沒有人留言評論。精彩留言會獲得點贊!
1