用于處理音頻信號的方法和裝置與流程
本發明涉及用于處理娛樂系統中的音頻信號的方法和裝置。
背景技術:
娛樂系統當前使用各種不同的音頻源。這里每個音頻源典型地具有特定音量,該音量由所使用的各硬件、軟件和相關音頻軌道預定。在改變音頻源之后,用戶通常被迫調整或重新調整主音量以獲得與先前主觀感知相同的音量。被稱作術語“響度”的感知的音量取決于音頻信號的頻率、振幅和時間位置。
根據線上維基百科全書,響度是人類音量感知的比例映射量(比照http://www.wikipedia.de標題“Lautheit”[響度],2015年8月3日版)。
響度是心理聲學術語,其描述若干測試人員主要評估感知音量的方式。響度取決于聲壓水平、頻譜和聲音隨時間推移的特性。響度的感知由內耳中聲音的處理類型和方式引起。根據神經細胞的激勵強度,聲音被評估為更大聲或更小聲。當聲音被感知為兩倍大時,響度總體是兩倍大。
已知用于定量確定響度的標準化測量方法。然而,在本發明的上下文中使用的術語“響度”總體意在被理解為心理聲學加權音量,其可以對應于根據標準化測量方法限定的響度(以宋(sone)測量),但也可以利用可選的方法(在適當情況下簡化)限定。
在實時處理期間調整音頻信號的音量的算法是已知的。然而,這些算法使用均衡器、壓縮器或限制器改變相關聲音軌道或由于該調整使它們降低動態范圍。此外,這種類型的算法通常需要高的處理和存儲能力。
關于現有技術,僅以示例的形式參照WO 2013/154823A2、WO 2004/111994A2、EP 1 805 891B1、EP 1 629 463A2、EP 1 835 487A2和EP 1 763 923A1。
技術實現要素:
本發明的目標是提供一種用于處理音頻信號的方法和裝置,其中可以獲得在每種情況下對來自不同音頻源的音頻信號中主觀感知的音量或響度的最佳對應效果。
該目標通過根據獨立權利要求1的特征的方法和根據權利要求8的特征的裝置來實現。
在根據本發明的用于處理娛樂系統中的音頻信號的方法中,來自至少一個音頻源的音頻信號在由娛樂系統回放期間被改變以調整到心理聲學響度設置值,其中在每種情況下基于平均心理聲學響度最大值執行該改變,平均心理聲學響度最大值是在預定時間間隔中針對相關音頻源所確定的。
根據一個實施例,來自至少兩個不同音頻源的音頻信號在娛樂系統回放期間被改變以調整到心理聲學響度設置值。
本發明尤其基于執行將不同音頻源實時調整到心理聲學響度設置值的構思。根據本發明的方法尤其基于音頻流的實時數據,而不需要知道未來值。而且,來自一個或多個音頻源的音頻信號在每種情況下被處理,該處理對每種情況下來自其它音頻源的音頻信號沒有依賴性。
根據本發明的方法不需要用于例如由相同音頻源回放的不同音樂或歌曲的音量調整。作為替代,來自娛樂系統不同音頻源的音頻信號的動態調整根據各自最大主觀感知的響度而實施。
如上文中已經提到的,術語“響度”表示與用戶心理聲學感知的音量近似成比例的量。該響度可以根據相關標準計算,但也可以由簡化的粗略計算限定。尤其地,可以根據機動車輛中的特定標準而調整用于響度限定所需的頻率加權(例如通過將典型的背景噪聲譜納入考慮)。
根據一個實施例,音頻信號在每種情況下在改變事件中乘以振幅,該振幅取決于各相關音頻源。
根據一個實施例,該振幅在每種情況下計算為響度設置值和平均心理聲學響度最大值的商。
根據一個實施例,平均心理聲學響度最大值的估算基于針對各音頻源存儲的響度數據而實施。
本發明還設計用于處理音頻信號的裝置,其中來自至少一個音頻源的音頻信號在娛樂系統回放期間可被改變以調整到心理聲學響度設置值,其中該裝置配置用于實施具有上述特性的方法。關于該裝置的優勢和有利設計,參照上述與本發明的方法相關作出的陳述。
根據本發明的處理尤其基于長期的信號信息。這通過極端數據簡化來實現。由于在通常情況下振幅的變化只是在無內存重寫的情況下非常緩慢地進行,因此娛樂系統的聽眾或用戶不能感知到動態音量或響度變化。而且,因此調整過程非常穩定并僅需要相對較低的處理能量。
本發明進一步的設計存在于說明書和從屬權利要求中。
在下文中使用優選實施例并參照附圖更詳細地說明本發明。
附圖說明
在圖中:
圖1示出了說明根據本發明用于音量調整的方法的示意圖;
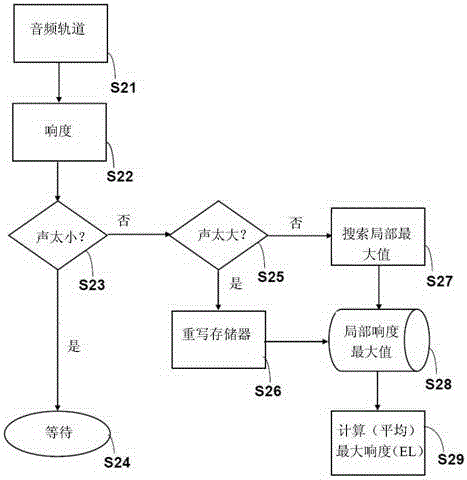
圖2示出了用于說明使用根據本發明的方法執行的最大響度估算的流程圖;
圖3示出了用于說明根據圖2中的步驟S22的響度限定的可行實施方式;以及
圖4示出了根據圖2的步驟S29計算平均最大響度的示意性表示。
具體實施方式
根據圖1,在根據本發明的用于音量調整的方法中,輸入音頻信號11通過乘以由源決定和時間決定的振幅15來改變,從而獲得輸出音頻信號16。振幅15由常數計算得出,通過音量設置值(SET)13除以來自音量存儲器14的估算平均最大心理聲學音量12(在下文中參照圖2更詳細地說明)得到該常數。為了避免由于振幅15突變所引起的信號失真,振幅值優選地隨隨時間逐漸減弱。
為了計算振幅,根據本發明的方法尤其需要心理聲學音量平均最大值的估算,其中針對該估算實施的過程在下文中參照圖2的流程圖描述。
此處,估算的平均最大響度在下文被稱作EL值(EL=“估算的平均最大響度”)。使用過去可用的各音頻源音頻信號的音量數據計算EL值。
為了計算EL值,首先根據特定音頻軌道的信號頻率測量當前響度(圖2中步驟S21和S22)。以這種方式測量的響度值被用于確定固定時間間隔內的局部最大值。各當前響度最大值被存儲在存儲器中,其中在每種情況下根據詢問S25(“太大聲”?),如果各自存在的EL值超出了限定的公差,那么存儲在該存儲器中的值在步驟S26中被重寫。如果音頻軌道的當前響度小于預定值,那么調整在步驟S23(“太小聲”?)中暫停。
在每種情況下根據步驟S28獲得存儲音頻軌道響度特性的數據,其依據固定時間間隔內的局部最大值的搜索(步驟S27)。因此存在于存儲器中的值包含相關音頻源的音頻信號的各響度最大值。根據存儲的響度最大值計算EL值(步驟S29)。
如果沒有可用的以前的音量值(例如由于涉及新的未知音頻源)或者如果當前音量大體大于EL值,執行新EL值的快速近似確定。該近似值基于傳入音頻軌道的新響度最大值。只要發現新的平均最大值,利用該值重寫存儲器內容并且再次執行根據本發明的計算。
圖3示出了用于圖2的步驟22中的響度限定的示意性算法的示例。音頻軌道(S22a)被細分為單獨的頻率成分(例如通過傅里葉分析)。在步驟S22b中,心理聲學估算濾波器被應用到該離散譜中,例如帶通濾波器,該濾波器可以具有向下開放的拋物線形,其在人耳感知最大值處具有最大值。以這種方式獲得的加權譜成分的平方被加和并且與步驟S22c中的標準化常數相乘以產生表示當前響度的值(S22d)。除了圖3中所示的響度限定之外,也可以想到針對響度限定的各種其它算法。
圖4示出了用于確定圖2的步驟S29所使用的平均最大響度的可行方法,其僅以示例方式給出。存在于存儲器中的音頻信號優選——但并非必須——在步驟30細分為單獨的框(在該情形中是三個)。在步驟31,函數被應用到單獨的區段,函數提供與最大值(對應于步驟S28)接近的值,例如和/或和/或其中意指適用的全部值(mean=平均值,max=最大值并且std=標準偏差)。在32處,“遺忘因子”λ可以可選地被應用到與最大值接近的單獨的值,其中0<λ<1。因此,與最近的信號相比,以前的信號被給予較少的權重。最終,在33處,以這種方式獲得的值被相加以形成和(如必要,在之前的平方之后)并且因此在34處獲得值EL。此外,用于確定EL值的各種其它算法是明顯可行的。
- 還沒有人留言評論。精彩留言會獲得點贊!