錄音方法、裝置和系統與流程
本申請涉及語音信號處理技術領域,尤其涉及一種錄音方法、裝置和系統。
背景技術:
檢察機關在審訊過程中需要對審訊情況和問答內容進行記錄,需要耗費相當的人力,語音識別技術的發展為解決這個問題提供了有效的途徑。
相關技術中,審訊錄音大多采用普通拾音器設備,可能是一個或者多個,該設備一般放置在審訊室的墻邊或者桌上,對審訊全程的語音進行錄制。
但是,相關技術中的審訊錄音設備具有以下的缺點:首先,錄音設備距離發言人距離都比較遠,容易受到環境噪聲和房間混響的影響,從而導致錄音清晰度和可懂度不高,整體質量較差;其次,不管是一個錄音器還是多個錄音器,都會同時錄制所有人的語音,為后續的回聽回看造成很大的不方便。
技術實現要素:
本申請旨在至少在一定程度上解決相關技術中的技術問題之一。
為此,本申請的一個目的在于提出一種錄音方法,該方法能夠提高錄音質量,同時實現說話人語音分離,從而便于后續錄音轉寫時的角色分離,方便回聽回看。
本申請的另一個目的在于提出一種錄音裝置。
本申請的另一個目的在于提出一種錄音系統。
為達到上述目的,本申請第一方面實施例提出的錄音方法,包括:獲取槍型麥克風陣列采集的第一語音信號和圓型麥克風陣列采集的第二語音信號,其中,所述槍型麥克風陣列端向指向待錄音的第一方,所述第一方的人數為一人;對所述第一語音信號和所述第二語音信號分別進行波束形成,根據波束形成輸出確定待錄音的第二方說話人方向,其中,所述第二方的人數為一人或多人;根據第一方說話人方向和所述第二方說話人方向進行說話人語音分離,得到第一方和第二方分離后的錄制語音信號。
本申請第一方面實施例提出的錄音方法,通過將槍型麥克風陣列端向指向第一方,可以實現更遠距離的高質量拾音,從而能夠提高錄音質量;通過進行說話人語音分離,可以便于后續錄音轉寫時的角色分離,方便回聽回看。
為達到上述目的,本申請第二方面實施例提出的錄音裝置,包括:獲取模塊,用于獲取槍型麥克風陣列采集的第一語音信號和圓型麥克風陣列采集的第二語音信號,其中,所述槍型麥克風陣列端向指向待錄音的第一方,所述第一方的人數為一人;確定模塊,用于對所述第一語音信號和所述第二語音信號分別進行波束形成,根據波束形成輸出確定待錄音的第二方說話人方向,其中,所述第二方的人數為一人或多人;分離模塊,用于根據第一方說話人方向和所述第二方說話人方向進行說話人語音分離,得到第一方和第二方分離后的錄制語音信號。
本申請第二方面實施例提出的錄音裝置,通過將槍型麥克風陣列端向指向第一方,可以實現更遠距離的高質量拾音,從而能夠提高錄音質量;通過進行說話人語音分離,可以便于后續錄音轉寫時的角色分離,方便回聽回看。
為達到上述目的,本申請第三方面實施例提出的錄音系統,包括:槍型麥克風陣列、圓型麥克風陣列和錄音裝置;所述槍型麥克風陣列端向指向待錄音的第一方,所述第一方的人數為一人;所述槍型麥克風陣列和圓型麥克風陣列分別用于采集所述第一方和/或待錄音的第二方的語音信號,所述第二方的人數為一人或多人;所述錄音裝置用于對槍型麥克風陣列采集的語音信號和圓型麥克風陣列采集的語音信號進行語音信號處理,得到說話人分離的第一方的錄制語音信號和第二方的錄制語音信號。
本申請第三方面實施例提出的錄音系統,通過將槍型麥克風陣列端向指向第一方,可以實現更遠距離的高質量拾音,從而能夠提高錄音質量;通過進行說話人語音分離,可以便于后續錄音轉寫時的角色分離,方便回聽回看。
本申請附加的方面和優點將在下面的描述中部分給出,部分將從下面的描述中變得明顯,或通過本申請的實踐了解到。
附圖說明
本申請上述的和/或附加的方面和優點從下面結合附圖對實施例的描述中將變得明顯和容易理解,其中:
圖1是本申請一個實施例提出的錄音系統的結構示意圖;
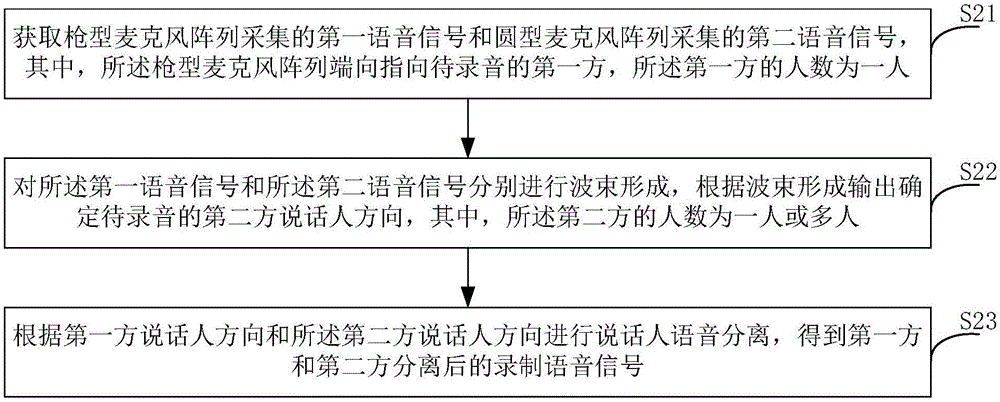
圖2是本申請一個實施例提出的錄音方法的流程示意圖;
圖3是本申請實施例中對語音信號進行波束形成及確定第二方說話人方向的方法的流程示意圖;
圖4是本申請實施例中槍型麥克風陣列空間區域劃分示意圖;
圖5是本申請實施例中圓型麥克風陣列空間區域劃分示意圖;
圖6是本申請實施例中聲源定位示意圖;
圖7是本申請實施例中單個GSC模塊的組成示意圖;
圖8是本申請一個實施例提出的錄音裝置的結構示意圖;
圖9是本申請另一個實施例提出的錄音裝置的結構示意圖。
具體實施方式
下面詳細描述本申請的實施例,所述實施例的示例在附圖中示出,其中自始至終相同或類似的標號表示相同或類似的模塊或具有相同或類似功能的模塊。下面通過參考附圖描述的實施例是示例性的,僅用于解釋本申請,而不能理解為對本申請的限制。相反,本申請的實施例包括落入所附加權利要求書的精神和內涵范圍內的所有變化、修改和等同物。
本申請的方案主要應用于雙方交談場景雙方語音數據的錄制,并且交談雙方中一方為一人,另一方為一人或多人(多人是指至少兩人)。如對犯罪嫌疑人的審訊場景,一方為一個被審訊人,另一方為多個審訊人;或者采訪場景,一方為被采訪人,另一方為多個采訪人;或者演講場景,一方為演講人,另一方為多個聽眾(聽眾會對演講者提問)等。下面以對犯罪嫌疑人的審訊場景為例,對本申請的方案進行闡述。
圖1是本申請一個實施例提出的錄音系統的結構示意圖。
如圖1所示,本實施例的系統包括:槍型麥克風陣列11、圓型麥克風陣列12錄音裝置13。
其中,槍型麥克風陣列11端向指向待錄音的第一方,所述第一方的人數為一人;例如,參見圖1,槍型麥克風陣列11端向指向被審訊人,被審訊人為一人。
圓型麥克風陣列12的放置方向不限定。
槍型麥克風陣列和圓型麥克風陣列可以分別與錄音裝置通過有線或無線進行連接。在系統設置上,槍型麥克風陣列、圓型麥克風陣列和錄音裝置可以設置成一個整體,或者分離設置。
進一步的,處于安全等方面的考慮,槍型麥克風陣列和圓型麥克風陣列可以放置在遠離被審訊人的位置,如放置在審訊桌上。
槍型麥克風陣列11和圓型麥克風陣列12分別用于采集第一方和/或待錄音的第二方的語音信號,所述第二方的人數為一人或多人。
如圖1所示,第二方為審訊人員,審訊人員可以為一人或為多人(圖1中示出了多人)。
根據當前說話人的不同,槍型麥克風陣列和圓型麥克風陣列可以采集到被審訊人的語音,或者采集到審訊人員的語音,或者采集到被審訊人和審訊人員的語音。
錄音裝置13用于對槍型麥克風陣列采集的語音信號和圓型麥克風陣列采集的語音信號進行語音信號處理,得到說話人分離的第一方的錄制語音信號和第二方的錄制語音信號。
錄音裝置的具體內容可以參見后續實施例的描述。
槍型麥克風陣列是由多個麥克風組成的線性陣列,相對于其他陣列形式,線性陣列能夠在端向形成指向性更高的波束,接收更小范圍內的語音,因此可以實現更遠距離的拾音,類似于用槍瞄準某一區域,另外這種線性陣列的硬件外觀也與獵槍相似,所以在本申請中將這種麥克風陣列稱為槍型麥克風陣列。目前的槍型麥克風陣列都是模擬陣列,而本申請中可以具體使用數字陣列,數字陣列除了能在端向實現高指向性波束外,還能在其他方向實現多個波束并根據需求控制波束形狀。
圓型麥克風陣列可以是單個環形的麥克風陣列,也可以多個同心圓環麥克風陣列,由于其結構的對稱性,對于全空間360度的任意方向,均可以實現相近的拾音波束。
在實際審訊場景中,一般只有1個被審訊人,并且在審訊過程中被審訊人的位置是固定的,為了方便和安全考慮,陣列需要放置在距離被審訊人較遠的地方,因此本申請將槍型麥克風陣列端向指向被審訊人,采用槍型麥克風陣列主要拾取被審訊人的語音。對于審訊人員,由于人數不確定(可能是1人或多人),且位置相對不固定,本申請采用圓型麥克風陣列主要拾取審訊人員的語音,由于圓形陣列可以360度拾音,所以無需特意擺放。
基于圖1所示的錄音系統,相應的錄音方法如圖2所示。
圖2是本申請一個實施例提出的錄音方法的流程示意圖。
如圖2所示,本實施例的方法包括:
S21:獲取槍型麥克風陣列采集的第一語音信號和圓型麥克風陣列采集的第二語音信號,其中,所述槍型麥克風陣列端向指向待錄音的第一方,所述第一方的人數為一人。
例如,如圖1所示,槍型麥克風陣列端向指向被審訊人,被審訊人為一人。圓型麥克風陣列的放置方向不限定。
槍型麥克風陣列和圓型麥克風陣列的麥克風數分別記為M1和M2,槍型麥克風陣列采集的第一語音信號記為xG,1(n),…,xG,M1(n),圓型麥克風陣列采集的第二語音信號記為xC,1(n),…,xC,M2(n)。其中,公式里下標中的G和C分別表示槍型麥克風陣列和圓型麥克風陣列,以下相同。
S22:對所述第一語音信號和所述第二語音信號分別進行波束形成,根據波束形成輸出確定待錄音的第二方說話人方向,其中,所述第二方的人數為一人或多人。
例如,如圖1所示,第二方是指審訊人員,審訊人員的人數為一人或多人。
波束形成的方式有多種,本實施例中可以具體采用固定波束形成。在固定波束形成時,可以對陣列空間進行劃分,得到預設個數的空間區域,對應每個空間區域進行固定波束形成,得到每個空間區域對應的固定波束形成輸出。
在固定波束形成時,可以先將語音信號從時域信號轉換為頻域信號,再采用固定波束系數對每個麥克風對應的頻域信號進行加權求和后,得到固定波束形成輸出。
假設第一語音信號對應的波束形成輸出稱為第一波束形成輸出,第二語音信號對應的波束形成輸出稱為第二波束形成輸出,可以理解的是,第一波束形成輸出和第二波束形成輸出的個數與對應的語音信號對應的空間區域的個數相同,假設第一語音信號對應的空間區域的個數和第二語音信號對應的空間區域的個數分別是N1和N2(N1和N2可以相同或不同),則第一波束形成輸出第n個方向上的波束形成輸出和第二波束形成輸出第n個方向上的波束形成輸出可以分別記為YG,n(ω,l),n=1,2,…N1和YC,n(ω,l),n=1,2,…N2。其中,ω表示傅里葉變換的角頻率,l表示語音信號的幀序號,以下相同。
進一步的,在得到上述的第一波束形成輸出YG,n(ω,l)和第二波束形成輸出YC,n(ω,l)后,可以根據第一波束形成輸出YG,n(ω,l)和第二波束形成輸出YC,n(ω,l)確定第二方說話人方向。
具體的波束形成及確定第二方說話人方向的內容可以如后續實施例所述。
S23:根據第一方說話人方向和所述第二方說話人方向進行說話人語音分離,得到第一方和第二方分離后的錄制語音信號。
由于第一方的說話人為一人,且該一人的方向已知,因此第一方說話人方向是已知的。另外,根據第一波束形成輸出和第二波束形成輸出可以確定出第二方說話人方向。在確定出上述兩方的說話人方向后,可以根據確定出的說話人方向進行說話人語音分離,得到分離后的第一方的語音信號和第二方的語音信號。
具體的說話人語音分離的內容可以如后續實施例所述。
進一步地,在得到分離后的語音信號后,還可以對分離后的語音信號進行后處理,所述后處理操作如去混響和降噪,抑制殘留的噪聲和混響成分,得到最終處理后的語音信號。在得到最終處理后的語音信號后,可以分別對其進行記錄,以得到分離后的第一方的錄制語音信號和第二方的錄制語音信號。
本實施例中,通過將槍型麥克風陣列端向指向第一方,可以實現更遠距離的高質量拾音,從而能夠提高錄音質量;通過進行說話人語音分離,可以便于后續錄音轉寫時的角色分離,方便回聽回看。
圖3是本申請實施例中對語音信號進行波束形成及確定第二方說話人方向的方法的流程示意圖。
如圖3所示,本實施例的方法包括:
S31:對第一語音信號進行固定波束形成,得到第一固定波束形成輸出。
槍型麥克風陣列采集的第一語音信號是時域信號,在固定波束形成時,可以先將時域信號轉換為頻域信號,再根據頻域信號進行固定波束形成。
具體的,對時域信號進行分幀加窗處理,再做傅里葉變換,得到頻域信號。具體過程與現有技術相同,在此不再詳述。傅里葉變換后,第一語音信號xG,1(n),…,xG,M1(n)對應的頻域信號記為XG,1(ω,l),…,XG,M1(ω,l)。
在對第一語音信號進行固定波束形成時,如圖4所示,將槍型麥克風陣列對應的空間劃分為N1個空間區域,θG,1,θG,2,…θG,N1為每個空間區域的中心方向,θG,1方向為被審訊人所在方向,該方向可以稱為槍型麥克風陣列的第一個區域的中心方向。對每個方向進行固定波束形成,得到每個方向的固定波束輸出,具體如下:
對于每一個方向設計一組固定波束系數,具體如下:
wG,n(ω)=[wG,n,1(ω),wG,n,2(ω),…wG,n,m(ω),…wG,n,M1(ω)],n=1,2,…,N1
其中,wG,n(ω)表示槍型麥克風陣列的第n個區域的固定波束系數,wG,n,m(ω)表示槍型麥克風陣列的第n個固定波束中第m個麥克風對應的系數,對麥克風采集的信號進行加權相加,得到槍型麥克風陣列的每個方向的固定波束輸出,第n個方向的固定波束輸出YG,n(w,l)為
其中上標*表示共軛,m表示槍型麥克風陣列中麥克風編號。
固定波束系數wG,n(ω)的求解方法分為兩種,即對于目標方向(被審訊人方向),對于說話人距離槍型陣列較遠的場景,如審訊場景,需要盡可能縮小拾音范圍,采用超指向性波束(Superdirective Beamformer);對于說話人距離槍型陣列較近的場景,為了實現頻率一致性,防止方向偏差導致的高頻失真,采用差分波束。對于非目標方向,固定波束形成采用線性約束最小方差(Linearly Constrained Minimum Variance LCMV)算法,約束條件為保證該區域中心方向響應為1,并且θG,1方向的響應為0;具體求解過程與現有技術相同,在此不再詳述。
S32:根據第一固定波束形成輸出確定當前說話人角色。
在得到槍型麥克風陣列的不同方向的固定波束輸出后,可以依據上述的不同方向的固定波束輸出進行當前說話人角色判決,即判斷當前說話人屬于第一方、或者屬于第二方、或者屬于第一方和第二方(即第一方和第二方同時說話)。
對于圖4中的槍型麥克風陣列空間區域劃分,在一般的審訊環境中,審訊人和被審訊人所在的空間區域是分離的。即被審訊人位于以θG,1為中心方向的區域(即第一個區域),而審訊人位于其他區域,本實施例通過對比槍型陣列第一個固定波束輸出和槍型陣列其他方向固定波束輸出的能量和,來判決當前說話人是審訊人還是被審訊人。
具體的,分別計算第一方說話人方向的第一固定波束形成輸出的波束能量P1(l)和槍型麥克風陣列其它方向的第一固定波束形成輸出的波束能量和P2(l):
再計算上述的波束能量與波束能量和之間的比值,根據比值與預設能量閾值,確定當前說話人角色:
用Speaker(l)表示當前說話人角色判決結果,共三種角色判決結果,即當前說話人為被審訊人,當前說話人為審訊人,當前說話人為被審訊人和審訊人(同時講話),具體可以使用-1,0或者1來表示三種角色判決結果,如Speaker(l)=-1表示當前說話人為被審訊人,Speaker(l)=1當前說話人為審訊人,Speaker(l)=0當前審訊人和被審訊人同時說話,如下式所示:
其中γ1和γ2是預先設定的能量閾值,滿足0<γ2<γ1,具體取值可以根據應用需求或實驗結果確定;當然所述說話人判決結果也可以采用其它表示方法,本申請不作限定。
S33:對第二語音信號進行固定波束形成,得到第二固定波束形成輸出。
圓型麥克風陣列采集的第二語音信號是時域信號,在固定波束形成時,可以先將時域信號轉換為頻域信號,再根據頻域信號進行固定波束形成。
具體的,對時域信號進行分幀加窗處理,再做傅里葉變換,得到頻域信號。具體過程與現有技術相同,在此不再詳述。傅里葉變換后,第二語音信號xC,1(n),…,xC,M2(n)對應的頻域信號記為XC,1(ω,l),…,XC,M2(ω,l)。
在對第二語音信號進行固定波束形成時,如圖5所示,將圓形麥克風陣列對應的空間均勻劃分為N2個空間區域,θC,1,θC,2,…θC,N2為每個空間區域的中心方向,第n個空間區域的角度范圍可以表示為[θC,n-Δθ,θC,n+Δθ],其中Δθ=180/N2。
類似第一語音信號的固定波束形成,在對第二語音信號進行固定波束形成時,也對上述的N2個空間區域的每個方向進行固定波束形成,得到每個方向的固定波束輸出,具體在得到每個方向的固定波束輸出時,采用固定波束系數對頻域信號進行加權求和后得到。
圓型麥克風陣列的固定波束系數的求解采用LCMV算法,對于第n個固定波束,約束條件為中心方向θC,n響應為1,邊界方向θC,n-Δθ和θC,n+Δθ的響應大于1-δ,其中δ為小于1的正實數。圓型麥克風陣列的第n個方向的固定波束輸出記為YC,n(w,l),n=1,2,…,N2。具體波束形成方法與現有技術相同,在此不再詳述。
S34:對當前說話人的方向進行聲源定位,定位出聲源方向。
其中,聲源方向可以用當前說話人的方向相對于圓型麥克風陣列的方向表示,即假設定位出的聲源個數為NSpeaker個,聲源方向的標號用{Index_1,…,Index_NSpeaker}表示,則{Index_1,…,Index_NSpeaker}是{1,2,…,N2}的子集。
具體的,先應用時頻掩碼算法對頻率點進行分類,然后對分類后的頻率點做聲源定位,可應用相位傳輸廣義互相關算法(Generalized Cross Correlation with Phase Transform,GCC-PHAT),定位出一個或多個聲源方向。如圖6為聲源定位示意圖,假設被審訊人員和審訊人員相對于圓型麥克風陣列的聲源方向分別為圓型麥克風陣列區域劃分的第1區域和第3區域,當審訊人員和被審訊人員同時說話時,可以定位到兩個聲源方向,即定位到的聲源方向數NSpeaker=2,定位到的聲源方向標號與圓型麥克風陣列波束方向標號對應關系為{Index_1,…,Index_2}={1,3}。
S35:選擇定位出的聲源方向上的第二固定波束形成輸出。
在定位出聲源方向后,可以從N2個方向的第二固定波束形成輸出中選擇聲源方向的第二固定波束形成輸出,如定位出的聲源方向{Index_1,…,Index_2}={1,3}時,則選擇第1區域方向和第3區域方向的第二固定波束形成輸出。
S36:獲取選擇出的第二固定波束形成輸出與第一方說話人方向上的第一固定波束形成輸出之間的相關系數。
如上述所示,θG,1方向為被審訊人所在方向,即第一方說話人方向,則第一方說話人方向上的第一固定波束形成輸出為YG,1(w,l),即槍型麥克風陣列第一方向上的固定波束形成輸出。
選擇出的第二固定波束形成輸出用YC,n(w,l),n=Index_1,Index_2,…,Index_NSpeaker表示,則上述的相關系數的計算公式為:
可以理解的是,在得到N2個第二固定波束形成輸出后,也可以分別計算N2個第二固定波束形成輸出中每個第二固定波束形成輸出與第一方說話人方向上的第一固定波束形成輸出之間的相關系數,從而得到N2個相關系數,之后再從N2個相關系數中選擇出NSpeaker個聲源方向對應的相關系數。
S37:根據當前說話人角色、選擇出的第二固定波束形成輸出、定位出的聲源方向個數以及獲取的相關系數,確定第二方說話人方向。
如上所示,根據第一波束形成輸出可以確定出當前說話人角色;根據聲源定位技術可以確定出聲源方向及確定聲源方向個數;根據定位出的聲源方向可以在第二固定波束形成輸出中選擇出聲源方向上的第二固定波束形成輸出;根據選擇出的第二固定波束形成輸出與第一方說話人方向上的第一固定波束形成輸出可以計算出相關系數。
在得到上述各參數后,可以據此確定第二方說話人方向,如確定審訊人員方向。
具體的,分為如下情況:
(1)當Speaker(l)=-1時,表示當前說話人為被審訊人,審訊人員方向使用上一次定位到的審訊人員方向;
(2)當Speaker(l)=1時,表示當前說話人為審訊人員,從選擇出的NSpeaker個聲源方向上的第二固定波束形成輸出中選取波束能量最大的第二固定波束形成輸出,將選取的第二固定波束形成輸出對應的方向作為審訊人員方向;
(3)當Speaker(l)=0且NSpeaker=1時(即只定位出一個聲源方向),如果ρIndex_1(l)>δρ,即定位出的聲源方向上的第二固定波束形成輸出與被審訊人方向上的第一固定波束形成輸出之間的相關度較高,則認為定位出的方向是被審訊人方向;審訊人員方向使用上一次定位到的審訊人員方向;否則,審訊人員方向為定位到的方向,即Index_1方向。其中δρ是設定的相關系數閾值,具體取值根據實驗結果或應用需求確定,滿足0<δρ<1。
(4)當Speaker(l)=0且NSpeaker>1時,在選擇出的第二固定波束形成輸出中去除上述相關系數最大的第二固定波束形成輸出,在剩余的第二固定波束形成輸出中選取波束能量最大的第二固定波束形成輸出,將選取的第二固定波束形成輸出對應的方向作為審訊人員方向。
上述確定出的第二方說話人方向用相對于圓型麥克風陣列的方向表示,所述定位出的聲源方向標號與圓型麥克風陣列的方向對應,如用Index_T表示,Index_T是1,2,…,N2中的任一值。
通過圖3所示的流程可以確定出第二方說話人方向,如審訊人員方向。由于第一方的人數是一人且已知,因此第一方說話人方向是已知的。在確定出第一方說話人方向和第二方說話人方向后,可以根據這兩個說話人方向進行說話人語音分離,得到第一方的語音信號和第二方的語音信號,如分離后的語音信號包含兩路輸出,一路僅包含被審訊人語音,另一路僅包含審訊人員語音。
具體的,可以采用兩個廣義旁瓣消除(Generalized Side lobe Canceller,GSC)進行語音分離,每個GSC模塊可以得到一路分離后的語音信號。
具體的,分別將第一方說話人方向和第二方說話人方向作為目標說話人方向,獲取目標說話人方向的固定波束輸出作為目標波束,以及獲取非目標說話人方向的固定波束輸出作為參考波束;將目標波束和參考波束作為GSC模塊的輸入,與GSC模塊的阻塞系數和自適應噪聲消除系數運算后得到GSC模塊的輸出,將輸出作為分離后的目標說話人的語音信號。
單個GSC模塊的示意圖如圖7所示,圖中省略了角頻率和幀序號(ω,l)。
如圖7所示,如圖7所示,目標波束用YT(ω,l)表示,參考波束用YR,k(ω,l),k=1,2,…,K表示,共有K個參考波束。
假設第一個GSC模塊的輸出目標是被審訊人的語音,第二個GSC模塊的輸出目標是審訊人員的語音。
相應的,第一個GSC模塊的目標波束是第一個GSC模塊的目標說話人方向的固定波束輸出,即被審訊人方向的第一固定波束輸出,即YG,1(w,l);第一個GSC模塊的參考波束是第一個GSC模塊的非目標說話人方向的固定波束輸出,即從除YG,1(w,l)之外的第一固定波束輸出和第二固定波束輸出中選取。進一步的,為了消除審訊人員的語音,第一個GSC模塊的參考波束中需包含第二方說話人方向的第二固定波束輸出,即包含YC,Index_T(w,l)。
相應的,第二個GSC模塊的目標波束是第二個GSC模塊的目標說話人方向的固定波束輸出,即審訊人員方向的第二固定波束輸出,即YC,Index_T(w,l);第二個GSC模塊的參考波束是第二個GSC模塊的非目標說話人方向的固定波束輸出,即從除YC,Index_T(w,l)之外的第二固定波束輸出和第一固定波束輸出中選取。進一步的,為了消除被審訊人的語音,第二個GSC模塊的參考波束中需包含第一方說話人方向的第一固定波束輸出,即包含YG,1(w,l)。
如圖7所示,GSC模塊的參數包括阻塞系數和自適應噪聲消除系數GSC模塊的輸入與上述系數的運算過程包括:
首先用阻塞系數消除參考波束里面泄露的目標信號,得到噪聲參考,如下式:
ER,k(ω,l)=YR,k(ω,l)-wBlock,k(ω,l)YT(ω,l)
然后用自適應噪聲消除系數消除目標波束包含的噪聲成分,得到增強的目標語音,如下式:
上述的GSC模塊的輸出ET(ω,l)就是目標說話人的語音信號,如,第一個GSC模塊的輸出是被審訊人的語音信號,第二個GSC模塊的輸出是審訊人員的語音信號。
進一步的,上述的阻塞系數和自適應噪聲消除系數可以根據輸入信號實時更新(一般初始值全設置為0)。
具體的,如果當前信號為目標語音信號時,按下式更新阻塞系數:
wBlock,k(ω,l+1)=wBlock,k(ω,l)+μ1ER,k(ω,l)YR,k(ω,l)
其中μ1為設定的更新步長。
如果當前信號為干擾語音信號時,按下式更新自適應噪聲消除系數:
wANC,k(ω,l+1)=wANC,k(ω,l)+μ2ET(ω,l)ER,k(ω,l)
其中μ2為設定的更新步長。
上述的目標語音信號和干擾語音信號的判斷可以依據當前說話人角色進行判定。再結合第一個GSC模塊的目標輸出是被審訊人的語音,第二個GSC模塊的目標輸出是審訊人員的語音,因此,當Speaker(l)=-1時更新第一個GSC模塊的阻塞系數和第二個GSC模塊的自適應噪聲消除系數,當Speaker(l)=1時更新第一個GSC模塊的自適應噪聲消除系數和第二個GSC模塊的阻塞系數。
圖8是本申請一個實施例提出的錄音裝置的結構示意圖。
如圖8所示,本實施例的裝置80包括:獲取模塊81、確定模塊82和分離模塊83。
獲取模塊81,用于獲取槍型麥克風陣列采集的第一語音信號和圓型麥克風陣列采集的第二語音信號,其中,所述槍型麥克風陣列端向指向待錄音的第一方,所述第一方的人數為一人;
確定模塊82,用于對所述第一語音信號和所述第二語音信號分別進行波束形成,根據波束形成輸出確定待錄音的第二方說話人方向,其中,所述第二方的人數為一人或多人;
分離模塊83,用于根據第一方說話人方向和所述第二方說話人方向進行說話人語音分離,得到第一方和第二方分離后的錄制語音信號。
一些實施例中,參見圖9,所述確定模塊82包括:
第一波束形成子模塊821,用于對第一語音信號進行固定波束形成,得到第一固定波束形成輸出;
角色確定子模塊822,用于根據第一固定波束形成輸出確定當前說話人角色;
第二波束形成子模塊823,用于對第二語音信號進行固定波束形成,得到第二固定波束形成輸出;
聲源定位子模塊824,用于對當前說話人的方向進行聲源定位,定位出聲源方向;
選擇子模塊825,用于選擇定位出的聲源方向上的第二固定波束形成輸出;
相關系數獲取子模塊826,用于獲取選擇出的第二固定波束形成輸出與第一方說話人方向上的第一固定波束形成輸出之間的相關系數;
說話人方向確定子模塊827,用于根據當前說話人角色、選擇出的第二固定波束形成輸出、定位出的聲源方向個數以及獲取的相關系數,確定第二方說話人方向。
一些實施例中,所述角色確定子模塊822具體用于:
分別計算第一方說話人方向的第一固定波束形成輸出的波束能量和其它方向的第一固定波束形成輸出的波束能量和;
計算所述波束能量與所述波束能量和之間的比值;
在所述比值大于或等于第一能量閾值時,確定當前說話人為第一方;
在所述比值小于或等于第二能量閾值時,確定當前說話人為第二方;
在所述比值大于第二能量閾值且小于第一能量閾值時,確定當前說話人為第一方和第二方。
一些實施例中,所述說話人方向確定子模塊827具體用于:
如果當前說話人為第一方,則確定第二方說話人方向為上一次定位到的第二方說話人方向;
如果當前說話人為第二方,在選擇出的第二固定波束形成輸出中選取波束能量最大的第二固定波束形成輸出,將選取出的第二固定波束形成輸出對應的方向確定為第二方說話人方向;
如果當前說話人為第一方和第二方,且聲源方向為一個,則當所述相關系數大于相關系數閾值時,則確定第二方說話人方向為上一次定位到的第二方說話人方向;當所述相關系數小于或等于相關系數閾值時,則將選擇出的第二固定波束形成輸出對應的方向確定為第二方說話人方向;
如果當前說話人為第一方和第二方,且聲源方向大于一個,在選擇出的第二固定波束形成輸出中去除所述相關系數最大的第二固定波束形成輸出,在剩余的第二固定波束形成輸出中選取波束能量最大的第二固定波束形成輸出,將選取的第二固定波束形成輸出對應的方向確定為第二方說話人方向。
一些實施例中,所述分離模塊83具體用于:
分別將第一方說話人方向和第二方說話人方向作為目標說話人方向,獲取目標說話人方向的固定波束輸出作為目標波束,以及獲取非目標說話人方向的固定波束輸出作為參考波束;
將目標波束和參考波束作為GSC模塊的輸入,與GSC模塊的阻塞系數和自適應噪聲消除系數運算后得到GSC模塊的輸出,將輸出作為分離后的目標說話人的語音信號。
一些實施例中,當目標說話人方向為第一方說話人方向時,所述參考波束包括:第二語音信號對應的波束形成輸出中第二方說話人方向的波束形成輸出;
當目標說話人方向為第二方說話人方向時,所述參考波束包括:第一語音信號對應的波束形成輸出中第一方說話人方向的波束形成輸出。
一些實施例中,所述阻塞系數或自適應噪聲消除系數是根據當前說話人角色進行更新的。
可以理解的是,本實施例的裝置與上述方法實施例對應,具體內容可以參見方法實施例的相關描述,在此不再詳細說明。
本實施例中,通過將槍型麥克風陣列端向指向第一方,可以實現更遠距離的高質量拾音,從而能夠提高錄音質量;通過進行說話人語音分離,可以便于后續錄音轉寫時的角色分離,方便回聽回看。
可以理解的是,上述各實施例中相同或相似部分可以相互參考,在一些實施例中未詳細說明的內容可以參見其他實施例中相同或相似的內容。
需要說明的是,在本申請的描述中,術語“第一”、“第二”等僅用于描述目的,而不能理解為指示或暗示相對重要性。此外,在本申請的描述中,除非另有說明,“多個”的含義是指至少兩個。
流程圖中或在此以其他方式描述的任何過程或方法描述可以被理解為,表示包括一個或更多個用于實現特定邏輯功能或過程的步驟的可執行指令的代碼的模塊、片段或部分,并且本申請的優選實施方式的范圍包括另外的實現,其中可以不按所示出或討論的順序,包括根據所涉及的功能按基本同時的方式或按相反的順序,來執行功能,這應被本申請的實施例所屬技術領域的技術人員所理解。
應當理解,本申請的各部分可以用硬件、軟件、固件或它們的組合來實現。在上述實施方式中,多個步驟或方法可以用存儲在存儲器中且由合適的指令執行系統執行的軟件或固件來實現。例如,如果用硬件來實現,和在另一實施方式中一樣,可用本領域公知的下列技術中的任一項或他們的組合來實現:具有用于對數據信號實現邏輯功能的邏輯門電路的離散邏輯電路,具有合適的組合邏輯門電路的專用集成電路,可編程門陣列(PGA),現場可編程門陣列(FPGA)等。
本技術領域的普通技術人員可以理解實現上述實施例方法攜帶的全部或部分步驟是可以通過程序來指令相關的硬件完成,所述的程序可以存儲于一種計算機可讀存儲介質中,該程序在執行時,包括方法實施例的步驟之一或其組合。
此外,在本申請各個實施例中的各功能單元可以集成在一個處理模塊中,也可以是各個單元單獨物理存在,也可以兩個或兩個以上單元集成在一個模塊中。上述集成的模塊既可以采用硬件的形式實現,也可以采用軟件功能模塊的形式實現。所述集成的模塊如果以軟件功能模塊的形式實現并作為獨立的產品銷售或使用時,也可以存儲在一個計算機可讀取存儲介質中。
上述提到的存儲介質可以是只讀存儲器,磁盤或光盤等。
在本說明書的描述中,參考術語“一個實施例”、“一些實施例”、“示例”、“具體示例”、或“一些示例”等的描述意指結合該實施例或示例描述的具體特征、結構、材料或者特點包含于本申請的至少一個實施例或示例中。在本說明書中,對上述術語的示意性表述不一定指的是相同的實施例或示例。而且,描述的具體特征、結構、材料或者特點可以在任何的一個或多個實施例或示例中以合適的方式結合。
盡管上面已經示出和描述了本申請的實施例,可以理解的是,上述實施例是示例性的,不能理解為對本申請的限制,本領域的普通技術人員在本申請的范圍內可以對上述實施例進行變化、修改、替換和變型。
- 還沒有人留言評論。精彩留言會獲得點贊!