一種基于多智能體的SQL語句端到端批量生成方法與流程
本發明涉及人工智能和數據處理,尤其涉及一種基于多智能體的sql語句端到端批量生成方法。
背景技術:
1、隨著大數據時代的到來,數據管理和分析變得越來越重要。在數據處理任務中,將自然語言查詢轉換為sql語句(即text-to-sql)是一個關鍵環節,但現代數據處理的需求遠不止于此。許多應用場景要求系統能夠生成多樣化的文本內容,包括但不限于sql查詢、報告、摘要、代碼片段等。
2、現有技術生成sql語句之前,需要大量高質量的文本數據,需要從多種渠道收集,包括公開數據集、用戶提交的查詢記錄、專業數據庫等。這些渠道的數據質量和可用性各異,增加了數據收集的難度。其次,收集的文本數據存在噪聲、錯誤或不一致的情況,清洗和預處理這些數據需要額外的時間和資源。再次,數據的匿名化和合規使用是一項復雜的任務,增加了數據收集的難度。最后,生成復雜sql所需的文本數據通常需要人工標注,標注人員由于不清楚特殊的業務邏輯,標注過程耗時費力,成本高昂,且容易出現標注錯誤。
3、傳統的sql生成方法主要依賴于規則匹配和模板生成,該方法實現簡單、易于維護,生成的sql語句規范、易于理解,在處理簡單和規范的查詢時表現良好。但在處理復雜和多樣化的自然語言查詢時,其覆蓋范圍和靈活性有限。對于未預見的查詢類型或語法結構,這些方法往往無法提供準確的sql生成結果。并且維護成本高。隨著查詢類型的增加,規則和模板的數量會迅速增加,管理和維護這些規則和模板的成本也相應增加。這不僅需要大量的時間和人力投入,還可能導致規則和模板的不一致性和錯誤。
4、基于序列到序列(seq2seq)模型是早期深度學習在text-to-sql中的典型應用,通過編碼器-解碼器架構,能夠處理復雜的語言結構和語義關系,但是在處理長文本和復雜查詢時,對長依賴關系的處理能力有限,容易出現生成結果不連貫的問題;在生成復雜sql語句時,處理速度較慢,尤其是在高并發請求時,性能瓶頸明顯。這會影響系統的響應時間和用戶體驗;處理特定領域的復雜查詢時,可能會出現過擬合現象,這導致生成的sql語句可能不符合預期,影響查詢的準確性和效率。
5、大語言模型(如bert、gpt系列、qwen系列)通過在大規模語料庫上進行預訓練,具備了強大的語言理解和生成能力。這些模型能夠生成高質量、多樣化的sql語句,適用于多種復雜查詢場景。然而,對于復雜任務,如端到端生成復雜sql語句,若大語言模型缺乏有效的組織管理和交互,那么在資源調度和任務處理方面,存在以下顯著不足:
6、1、資源利用率低,在處理高并發請求時,資源利用率低,容易出現性能瓶頸,無法有效利用多核或多機的計算資源,導致整體處理效率低下;
7、2、響應時間長,生成復雜sql語句時,大語言模型處理速度較慢,尤其是在高并發請求下,響應時間顯著增加,影響用戶體驗;
8、3、處理能力有限,大語言模型在處理復雜和多樣化的自然語言查詢時,處理能力有限,面對復雜的sql語句生成任務,無法有效地處理所有子任務,導致生成的sql語句不準確或不完整;
9、4、缺乏靈活性,大語言模型難以根據任務的復雜度和類型動態調整資源分配,缺乏靈活性和適應性,面對不同類型的查詢時,性能和準確性難以保證;
10、5、批量生成能力不足,在不同應用場景下,比如:業務人員需要定期生成報表;開發團隊需要大量測試用例;智能客服需要處理用戶的自然語言查詢等等,這些都需要將大量自然語言查詢轉換為sql語句,那么批量生成sql語句就顯得尤為重要。
11、因此,本領域的技術人員致力于開發一種基于多智能體的sql語句端到端批量生成方法。
技術實現思路
1、有鑒于現有技術的上述缺陷,本發明所要解決的技術問題是sql生成任務如何提高資源利用率和減少響應時間。
2、多智能體系統(mas)是一種分布式計算范式,涉及多個智能體(agents)之間的交互和協作,以完成共同的任務或解決問題。每個智能體都是一個自主的計算實體,具有一定的自主性和決策能力,能夠獨立處理特定的子任務,并通過協作和通信機制共同完成整體任務。具體來說,多智能體系統的并行處理能力可以顯著提高系統的吞吐量和響應速度;任務分解與協作機制可以提高系統的處理效率和靈活性;動態適應性可以優化資源利用;容錯性和魯棒性可以確保系統的穩定性和可靠性;每個整體的專業性與專長提高了特定任務的完成質量和可靠性。
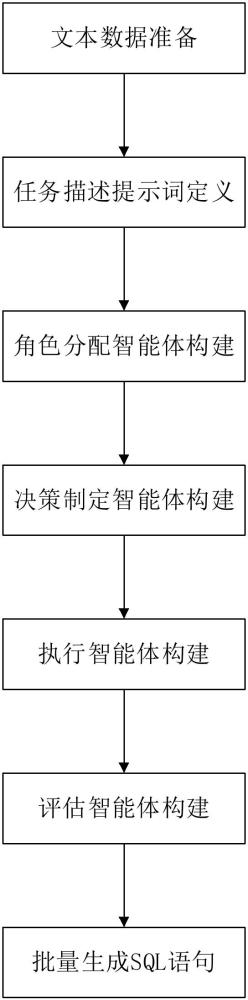
3、本發明的一個實施例中,提供了一種基于多智能體的sql語句端到端批量生成方法,包括:
4、s100、文本數據準備,從數據庫中導出所有表的表結構信息進行規范化,使用大語言模型生成每張表的表描述,將表描述添加到規范化的表結構信息,輸入大語言模型生成文本數據,將文本數據結構化;
5、s200、任務描述提示詞定義,定義sql語句生成任務描述提示詞,sql語句生成任務描述提示詞包括任務要求和結構化的文本數據;
6、s300、角色分配智能體構建,構建角色分配智能體,根據sql語句生成任務描述提示詞招募角色;
7、s400、決策制定智能體構建,構建決策制定智能體,根據sql語句生成任務描述提示詞生成sql語句并解析保存;
8、s500、執行智能體構建,構建執行智能體,連接數據庫并執行sql語句,捕獲sql語句的執行結果并保存;
9、s600、評估智能體構建,構建評估智能體,對sql語句的執行結果進行評估,并將評估結果反饋給角色分配智能體和決策制定智能體;
10、s700、批量生成sql語句,制定角色分配智能體、決策制定智能體、執行智能體和評估智能體之間的通信和協作環境,完成sql語句生成任務。
11、可選地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,步驟s100包括:
12、s110、表結構信息導出,從數據庫中導出所有表的表結構信息,表結構信息包括索引信息和字段信息;
13、s120、表結構信息規范化,對表結構信息進行規范化,表結構信息包括表名、索引字段和非索引字段;
14、s130、生成表描述,將規范化的表結構信息輸入大語言模型,對每張表進行總結,生成每張表的表描述,再將表描述添加到規范化的表結構信息中,得到最終的表結構信息;
15、s140、文本數據生成,將最終的表結構信息作為提示詞輸入大語言模型,批量生成文本數據,文本數據包括基于當前數據庫結構的一個自然語言查詢問題和回答該問題可能用到的相關表名;
16、s150、文本數據結構化,將相關表名轉換為具體的表結構信息,得到結構化的文本數據,包括問題、表名、表描述、索引字段和非索引字段。
17、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,步驟s110中,如果沒有數據庫,則先建立一個數據庫,然后再創建表。
18、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,數據庫滿足如下條件:
19、s111、表的數量不少于50張;
20、s112、表結構的字段類型應選擇合適的數據類型;
21、s113、根據應用場景,對需要經常查詢的字段創建索引;
22、s114、表字段添加解釋信息。
23、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,索引信息包含表名稱、字段名稱、索引名稱和索引序號,字段信息包含表名稱、字段名稱和字段解釋。
24、優選地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,大語言模型選擇qwen2.5-72b。
25、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,索引字段包括字段名稱、字段類型、字段解釋和索引信息,非索引字段包括字段名稱、字段類型?和字段解釋。
26、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中。
27、可選地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,步驟s140包括:
28、s141、建立向量數據庫,設置生成文本數據的數量;
29、s142、輸入大語言模型,隨機調整所述最終的表結構信息的數量,輸入所述大語言模型,生成文本數據;
30、s143、計算相似度,計算所述文本數據與所述向量數據庫中歷史生成的每一條數據的相似度;
31、s144、完成文本數據生成,當所述相似度小于設定相似度閾值時,把生成的文本數據嵌入所述向量數據庫,否則重新執行s142-s144,直到嵌入所述向量數據庫的文本數據達到設置的生成文本數據的數量。
32、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,相似度閾值為0.9。
33、可選地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,sql語句生成任務描述提示詞在定義時要求:明確表達任務要求,避免模棱兩可的表述;強調表結構信息以便大語言模型理解數據庫結構。
34、可選地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,步驟s300包括:
35、s310、角色分配智能體定義,定義智能體的類型為角色分配,并對角色分配智能體進行命名;
36、s320、角色分配智能體的前置提示詞模板定義,定義角色分配智能體的前置提示詞模板,包括招募角色解決sql語句生成任務的需求和建議,sql語句生成任務的需求包括sql語句生成任務描述提示詞;
37、s330、角色分配智能體的后置提示詞模板定義,定義角色分配智能體的后置提示詞模板,包括響應格式和響應示例;
38、s340、角色分配智能體的大語言模型配置,配置角色分配智能體的大語言模型,包括角色分配智能體的大語言模型名稱、溫度和最大token數;
39、s350、解析角色分配智能體響應的方法定義,定義解析角色分配智能體響應的方法;
40、s360、招募角色,根據sql語句生成任務描述提示詞招募角色,將所述角色的信息分離出來。
41、進一步地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,角色分配智能體的大語言模型的名稱為qwen2_5-72b-gptq-int4、角色分配智能體的大語言模型的溫度為0-1之間的小數,角色分配智能體的大語言模型的最大token數為0-32768之間的整數。
42、進一步地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,角色分配智能體的大語言模型的溫度為0,角色分配智能體的大語言模型的最大token數為4096。
43、進一步地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,角色分配智能體的前置提示詞模板的sql語句生成任務的需求包括任務描述、招募人數和建議。
44、可選地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,步驟s400包括:
45、s410、決策制定智能體定義,定義智能體的類型為解決者,并對決策制定智能體進行命名;
46、s420、決策制定智能體的前置提示詞模板定義,定義決策制定智能體的前置提示詞模板,包括輸入數據描述,數據描述包括sql語句生成任務描述提示詞;
47、s430、決策制定智能體的后置提示詞模板定義,定義決策制定智能體的后置提示詞模板,包括步驟提示詞、建議、響應格式和響應要求;
48、s440、決策制定智能體的大語言模型配置,配置所述決策制定智能體的大語言模型,包括所述決策制定智能體的大語言模型的名稱、溫度和最大token數;
49、s450、解析決策制定智能體響應的方法定義,定義解析決策制定智能體響應的方法;
50、s460、生成sql語句,決策制定智能體根據sql語句生成任務提示詞生成sql語句,并解析保存。
51、進一步地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,步驟提示詞包括:
52、s431、編寫sql語句,基于業務邏輯問題和表結構編寫sql語句;
53、s432、解釋推理過程,逐步說明如何構建sql語句;
54、s433、確保sql語句在語法和邏輯上的正確性。
55、進一步地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,決策制定智能體的大語言模型的名稱為qwen2_5-72b-gptq-int4,決策制定智能體的大語言模型的溫度為0-1之間的小數,決策制定智能體的大語言模型的最大token數為0-32768之間的整數;
56、進一步地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,決策制定智能體的大語言模型的溫度為0,決策制定智能體的大語言模型的最大token數為4096。
57、可選地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,步驟s500包括:
58、s510、執行智能體定義,定義智能體類型為執行者,并對執行智能體進行命名;
59、s520、執行智能體的大語言模型配置,配置執行智能體的大語言模型,包括執行智能體的大語言模型的名稱、溫度和最大token數;
60、s530、數據庫連接信息配置,包括連接數據庫的ip地址、端口和名稱;
61、s540、解析執行智能體的執行結果的方法定義,定義解析執行智能體的執行結果的方法;
62、s550、執行sql語句,執行智能體執行sql語句,解析執行結果并保存,執行結果包括sql查詢結果或執行過程中的報錯信息。
63、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,執行智能體的大語言模型的名稱為qwen2_5-72b-gptq-int4,執行智能體的大語言模型的溫度為0-1之間的小數,執行智能體的大語言模型的最大token數為0-32768之間的整數。
64、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,執行智能體的大語言模型的溫度為0,執行智能體的大語言模型的最大token數為4096。
65、可選地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,步驟s600包括:
66、s610、評估智能體定義,定義智能體類型為評估者,并對評估智能體進行命名;
67、s620、評估思路定義,定義評估智能體的評估思路;
68、s630、評估智能體的前置提示詞模板定義,定義評估智能體的前置提示詞模板,包括評估sql語句生成任務描述、解答結果和評估思路,評估sql生成任務描述包括sql語句生成任務描述提示詞,解答結果包括s400生成的sql語句和s500的執行結果;
69、s640、評估智能體的后置提示詞模板定義,定義評估智能體的后置提示詞模板,包括響應格式和響應要求;
70、s650、評估智能體大語言模型配置,配置評估智能體的大語言模型,包括評估智能體的大語言模型的名稱、溫度和最大token數。
71、s660、解析評估智能體響應的方法定義,定義解析評估智能體響應的方法;
72、s670、評估sql語句執行結果,評估智能體對sql語句執行結果進行評估,向角色分配智能體和決策制定智能體反饋評估結果,根據評估結果,分別更新角色分配智能體的前置提示詞模板和決策制定智能體的后置提示詞模板。
73、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,評估智能體的評估思路包括:
74、s621、原始sql查詢語句的語法是否正確;
75、s622、sql執行結果是否匹配業務邏輯問題的要求,允許查詢結果為空;
76、s623、sql執行結果是否準確回答了業務邏輯問題。
77、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,評估智能體的大語言模型的名稱為qwen2_5-72b-gptq-int4,評估智能體的大語言模型的溫度為0-1之間的小數,評估智能體的大語言模型的最大token數為0-32768之間的整數。
78、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,評估智能體的大語言模型的溫度為0.3,評估智能體的大語言模型的最大token數為4096。
79、可選地,在上述任一實施例中的基于多智能體的sql語句端到端批量生成方法中,步驟s700包括:
80、s710、創建線程池,提交指定數量的sql語句生成任務到線程池,定義最大線程數;
81、s720、定義單個sql語句生成任務,定義單個sql語句生成任務的最大輪次,限定所述角色分配智能體可招募的角色數量,讀取當前生成sql語句任務的文本數據;
82、s730、初始化智能體,初始化角色分配智能體的前置提示詞模板,初始化決策制定智能體的后置提示詞模板;
83、s740、整合角色分配智能體,整合單個sql語句生成任務的任務描述提示詞和角色分配智能體的前置提示詞模板為系統提示詞,角色分配智能體的后置提示詞模板為查詢提示詞,角色分配智能體根據查詢提示詞和系統提示詞開始招募角色,并解析招募的角色,并將招募的角色信息進行保存;
84、s750、整合決策制定智能體,整合單個sql語句生成任務的任務描述提示詞、決策制定智能體的前置提示詞模板和角色分配智能體招募的角色信息為系統提示詞,決策制定智能體的后置提示詞模板為查詢提示詞,決策制定智能體根據查詢提示詞和系統提示詞進行決策制定,即生成sql語句,并進行保存;
85、s760、保存執行結果,執行智能體連接數據庫,執行sql語句,并將執行結果進行保存,執行結果包括sql查詢結果和執行過程中的錯誤;
86、s770、整合評估智能體,整合單個sql語句生成任務的任務描述提示詞、角色分配智能體招募的角色信息和評估智能體的前置提示詞模板為系統提示詞,評估智能體的后置提示詞模板為查詢提示詞,評估智能體根據查詢提示詞和系統提示詞評估本次sql語句生成任務是否成功,將評估結果進行保存;
87、s780、完成全部sql語句生成任務,如果本次sql語句生成任務經評估智能體評估為成功或超出單個sql語句生成任務的最大輪次,則返回步驟s720,直至完成指定數量的sql語句生成任務;如果本次sql語句生成任務經評估智能體評估為失敗,則返回步驟s740。
88、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,指定數量的sql語句生成任務為5000個。
89、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,最大線程數為6,即同時處理的sql生成任務最多為6。
90、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,單個sql語句生成任務的最大輪次為5。
91、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,限定角色分配智能體可招募的角色數量為2。
92、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,角色分配智能體的前置提示詞模板中的建議為“當前沒有任何建議”。
93、進一步地,在上述實施例中的基于多智能體的sql語句端到端批量生成方法中,決策制定智能體的后置提示詞模板中的建議為“當前沒有任何建議”。
94、本發明通過構建角色分配智能體、決策制定智能體、執行智能體、評估智能體,制定智能體間的通信和協作環境,實現了從自然語言查詢請求到復雜sql語句的轉換。顯著提高了批量sql生成的準確性和效率。本發明通過多智能體,利用多個大語言模型的并行處理能力,顯著提高了資源利用率,減少了響應時間。多智能體可以根據任務的復雜度和類型,動態調整資源分配,避免性能瓶頸,確保在高并發請求下仍能保持高效的處理速度。
95、以下將結合附圖對本發明的構思、具體結構及產生的技術效果做進一步說明,以充分地了解本發明的目的、特征和效果。
- 還沒有人留言評論。精彩留言會獲得點贊!