一種數據智能集成化管理系統的制作方法
本發明涉及醫療數據歸檔,具體涉及一種數據智能集成化管理系統。
背景技術:
1、醫療數據中指的是以自然語言形式記錄的、描述患者健康狀況、診療過程以及治療結果的信息,這些文本數據廣泛存在于各種醫療文檔中,例如病歷記錄、診斷報告、手術記錄、醫生和護士的筆記、檢查報告和藥物處方等。
2、傳統系統依賴人工進行數據采集、處理、分類和歸檔,這樣不僅容易受到人為錯誤的影響,還需要較長的時間才能完成數據處理,尤其在醫療數據量龐大且變化頻繁的情況下,人工操作容易導致數據處理的延誤,進而影響到醫療服務的時效性和準確性;且傳統系統在數據分類和歸檔時通常依賴人工判斷,可能出現分類不準確或者缺乏一致性的情況,尤其是在醫療數據的復雜性和多樣性面前,人工分類不僅效率低下,且容易遺漏或錯誤地歸類某些數據;并且傳統系統對醫療數據的分類僅僅在原始醫療數據的基礎上,但是原始醫療數據往往沒有有效的上下文關聯,單純對原始數據進行分類往往無法挖掘出數據背后的深層次信息。
技術實現思路
1、本發明所要解決的技術問題在于克服上述現有技術的缺點,提供一種數據智能集成化管理系統。
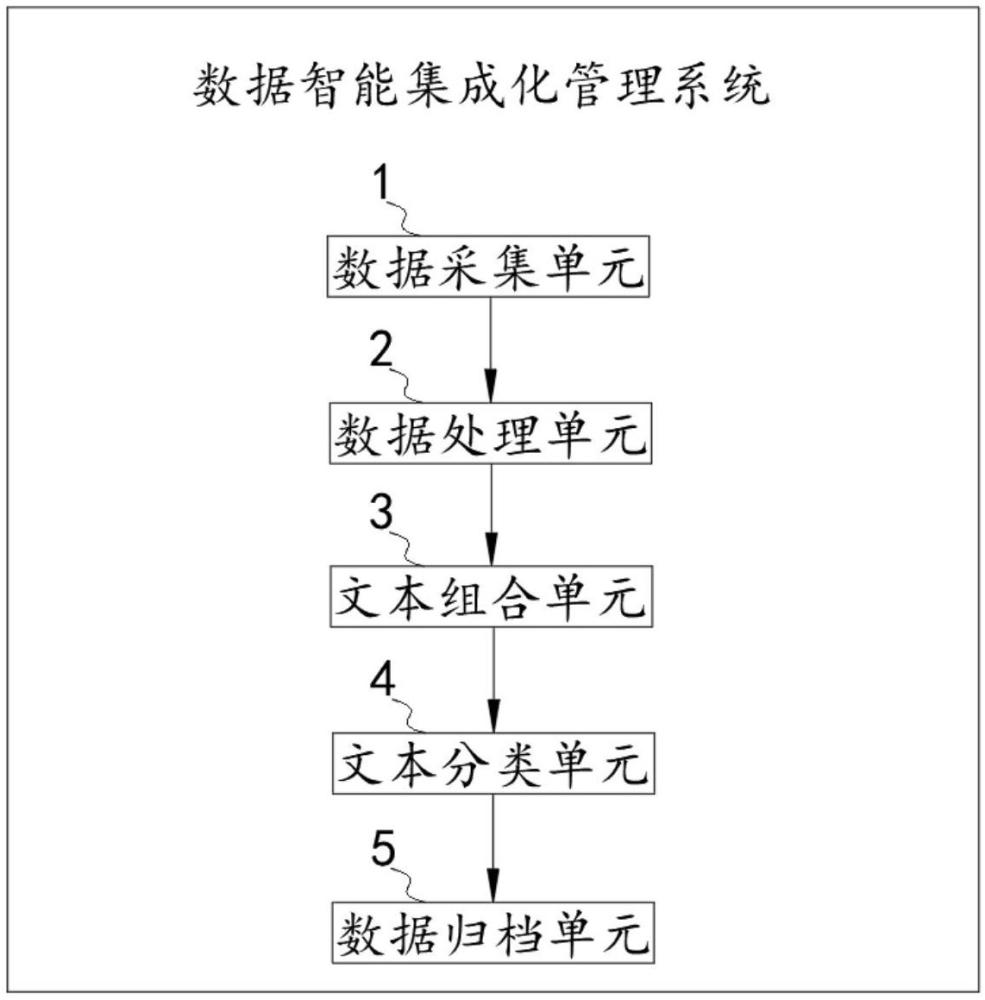
2、解決上述技術問題所采用的技術方案是:一種數據智能集成化管理系統,包括數據采集單元、數據處理單元、文本組合單元、文本分類單元和數據歸檔單元,具體地:
3、所述數據采集單元用于每隔預設的采樣周期接收多個預設的數據源上傳的醫療數據,將所述醫療數據傳輸至數據處理單元;
4、所述數據處理單元用于對數據采集單元傳輸的所述醫療數據進行接收,并對所述醫療數據進行分詞操作,以得到所述醫療數據所對應的醫療詞語序列,對所述醫療詞語序列進行特征提取,以得到所述醫療詞語序列中每個醫療詞語的詞語特征,基于所述詞語特征對所述醫療詞語序列進行排序,以得到醫療詞語順序序列,將所述醫療詞語順序序列傳輸至文本組合單元;
5、所述文本組合單元用于對數據處理單元傳輸的所述醫療詞語順序序列進行接收,并基于所述醫療詞語順序序列構建醫療組合文本,將所述醫療組合文本傳輸至文本分類單元。
6、優選的,所述文本分類單元用于對文本組合單元傳輸的所述醫療組合文本進行接收,并基于已訓練好的文本分類模型對所述醫療組合文本進行文本分類,以得到所述醫療組合文本所對應的文本標簽,即得到所述醫療數據所對應的數據標簽,將所述醫療數據所對應的數據標簽傳輸至數據歸檔單元。
7、優選的,所述數據歸檔單元用于對文本分類單元傳輸的所述醫療數據所對應的數據標簽進行接收,并基于所述醫療數據所對應的數據標簽將所述醫療數據歸檔至預設的不同類型的醫療檔案數據庫中。
8、優選的,所述醫療詞語的詞語特征的提取公式如下:
9、;
10、其中,表示醫療詞語,表示醫療數據,表示醫療詞語在醫療數據的詞語特征,表示醫療詞語在醫療數據中出現次數,表示醫療詞語的逆醫療數據詞頻,表示熵計算函數,表示類別中的醫療詞語數占所有醫療詞語數的比例,表示醫療數據中包括醫療詞語的總數,表示醫療數據中醫療詞語的總數。
11、優選的,基于所述醫療詞語順序序列構建醫療組合文本,包括:
12、基于所述醫療詞語順序序列中每個醫療詞語的順序序號獲取所述醫療詞語順序序列中每個醫療詞語的組合權重;
13、基于所述醫療詞語順序序列中每個醫療詞語的組合權重計算每個醫療詞語所需的組合字數;
14、將所述醫療詞語順序序列中每個醫療詞語與預設的醫療詞語知識庫進行匹配,以得到所述醫療詞語順序序列中每個醫療詞語所對應的醫療詞語解釋;
15、基于所述醫療詞語順序序列中每個醫療詞語所需的組合字數對所述醫療詞語解釋進行截取,以得到所述醫療詞語順序序列中每個醫療詞語所對應的標準醫療詞語解釋;
16、基于醫療詞語順序序列和所述醫療詞語順序序列中每個醫療詞語所對應的標準醫療詞語解釋構建醫療組合文本。
17、優選的,所述組合字數的計算公式如下:
18、;
19、其中,表示醫療詞語順序序列中第個醫療詞語所需的組合字數,表示所有醫療詞語組合權重的總和,表示醫療組合文本的總字數;
20、所述組合權重的計算公式如下:
21、;
22、其中,表示醫療詞語順序序列中第個醫療詞語的組合權重,表示醫療詞語的順序序號。
23、優選的,所述文本分類模型包括語義特征表示模塊、注意力模塊和特征分類模塊;所述語義特征表示模塊用于通過bilstm網絡捕獲輸入的所述醫療組合文本的語義特征,并將所述語義特征切分為多個特征塊;所述注意力模塊用于對每個所述特征塊獲取在一個標簽層級上的標簽特定加權特征表示;所述特征分類模塊用于將細粒度特征注入粗粒度標簽中,并通過分類器輸出最終的文本標簽。
24、優選的,所述語義特征表示模塊用于通過bilstm網絡捕獲輸入的所述醫療組合文本的語義特征,并將所述語義特征切分為多個特征塊,包括:
25、通過詞嵌入技術對所述醫療組合文本中每個醫療詞語進行向量表示,以得到嵌入向量矩陣;
26、將所述嵌入向量矩陣輸入至bilstm網絡,通過所述bilstm網絡輸出每個所述嵌入向量在兩個方向隱藏狀態的拼接向量,以得到語義特征矩陣;
27、將所述語義特征矩陣從特征維度進行切分,以將所述語義特征矩陣切分為多個相同的子語義特征矩陣,且每個所述子語義特征矩陣對應一個粒度層級。
28、優選的,所述特征分類模塊用于將細粒度特征注入粗粒度標簽中,并通過分類器輸出最終的文本標簽,包括:
29、對于每個標簽特定加權特征表示采用均值池化進行降維,以得到特征映射向量,將標簽特定特征矩陣與特征映射向量進行拼接,以得到特征拼接向量,將所述特征拼接向量輸入至分類器中,以得到標簽的概率,所述標簽的概率計算公式如下:
30、;
31、其中,表示第粒度層級的標簽的概率,表示第粒度層級的帶偏置的單層前饋網絡,表示第粒度層級的特征映射向量,表示向量的拼接操作。
32、優選的,所述注意力模塊用于對每個所述特征塊獲取在一個標簽層級上的標簽特定加權特征表示,包括:
33、通過多個分類器對多個子語義特征矩陣進行分類,并對每個所述粒度層級的分類添加相應的注意力權重,以得到所述特征塊獲取在一個標簽層級上的標簽特定加權特征表示,所述注意力權重計算公式如下:
34、;
35、其中,表示第粒度層級的標簽特定特征矩陣,表示第粒度層級的注意力權重矩陣,表示第粒度層級的子語義特征矩陣,且,表示軟最大激活函數,表示第個粒度層級的變換矩陣,表示第個粒度層級的經過函數激活的向量矩陣,且,表示第個粒度層級的權重矩陣,表示雙曲正切激活函數。
36、本發明的有益效果如下:(1)本發明通過自動化的數據采集、處理和歸檔流程,避免了人工處理過程中可能出現的誤差和延遲,這對于醫療行業的數據處理尤為重要,因為醫療數據通常具有高時效性和復雜性,自動化的流程可以提高工作效率,確保數據及時、準確地處理和存檔,且將醫療數據進行分詞、特征提取、排序和分類等步驟,能夠將非結構化或半結構化的醫療文本數據轉化為結構化的標準格式。這種結構化的數據便于后續的查詢、分析和利用,降低了數據處理的復雜性;(2)本發明通過與預設的醫療詞語知識庫匹配,能夠準確獲取醫療詞語的標準解釋,并對醫療詞語進行有效的截取和整合,這使得醫療數據不僅僅是原始的文本信息,而是可以在更高層次上進行分析和推理,從而支持醫療決策、研究與應用,且通過訓練好的文本分類模型,系統能夠根據醫療數據的內容自動為醫療數據打上相應的標簽,從而實現個性化的分類和歸檔,這不僅減少了人工干預的需求,還能提高數據歸檔的準確性與精確性,方便后期的檢索與利用,且由于對醫療數據添加有標準解釋,使得分類和歸檔更加準確;(3)本發明能夠根據數據標簽將醫療數據歸檔至不同類型的醫療檔案數據庫中,優化了醫療數據的存儲結構,提升了數據管理的效率,從而醫療機構可以根據需要快速定位和檢索不同類別的醫療數據,提高了檔案管理的精確度和便利性。
- 還沒有人留言評論。精彩留言會獲得點贊!