基于生成式模型和分層訓練的熱線文本智能轉派方法
本公開涉及信息處理領域,進一步涉及自然語言數據處理領域,具體涉及文本分類方法,尤其涉及一種基于生成式模型和分層訓練的熱線文本智能轉派的方法、系統、電子設備和可讀存儲介質。
背景技術:
1、過去十年,為了解決城市問題,提高城市的治理有效性和高效性,全國各地涌現出了許多智慧城市項目。這些項目為市民提供了更加便捷的民生服務系統,使得市民能夠方便地報告諸如城市服務和交通等民生問題,并與管理部門保持持續聯系。以最為重要的12345熱線服務為例,該服務有助于提高在市場監管、社會工作、生態環境保護等公共服務能力,也有助于在相關領域實施行政精簡、優化服務。
2、該平臺提供全天候人工服務,24小時不間斷,市民可以通過電話或線上平臺隨時隨地提交城市的非緊急服務問題。相關部門會在期限期內準確、迅速地處理并反饋結果,以滿足市民的需求。
3、12345民生服務熱線本身具有特殊性,主要特點是“接訴即辦”,它的處理流程可以概括為:平臺的話務員接收群眾的訴求,如果是咨詢類問題且可以在知識庫中找到答案,則直接在線回復;如果無法解決,則會生成工單文本并存入系統平臺,坐席員會將工單下派到其他部門。這種方式仍存在以下問題:
4、(1)工單量龐大,人力資源短缺。根據某市2021年第四季度群眾訴求辦理情況的報告,共受理了60.31萬件,平均每天受理5000余件工單,話務員承受了較大的壓力,需要管理部門投入更多的人力。
5、(2)三定方案不夠明確導致工單流轉周期長。在“接訴即辦”的業務中,人工事件轉派的周期長,效率低下。此外,事件轉派的質量很大程度上取決于話務員的經驗和對業務部門的了解程度,這可能會導致事件流轉錯誤。
6、(3)復雜業務導致工單流轉的層級和時間增加。對于一些涉及到村、小區等的工單,由于涉及范圍較廣,可能會導致層級過長,需要多個坐席員進行處理,這也會增加工單流轉的難度。這種情況會影響工單處理的效率。
7、當下熱線業務日益繁重,海量的熱線文本信息急需進行及時處理,僅依靠手工分類派發完全無法滿足處理需求。隨著計算機信息處理技術的發展,越來越多的行業和部門采用自動信息處理來替代原始的人工信息處理方式。好的文本信息處理結果能幫助實現社會職能管理部門的精細化準確管理,有利于減輕人工處理負擔,提高管理效率,增強民眾滿意度。然而現有的一些文本信息處理方法還無法滿足這些龐亂復雜熱線案件的特殊處理需求。
8、因此,對這些諸如12345民生服務熱線等的特殊文本數據進行針對性研究,探索新的文本分類方法對這些信息進行處理,以便將如此龐雜的熱點問題及時有效地進行準確分類處理,實現向社會職能管理部門進行準確地精細化分配管理,成為亟待解決的技術問題。
9、公開內容
10、本公開要解決的技術問題是,探索實用的針對諸如12345民生服務熱線等的特殊文本數據進行的新的文本分類方法,對所述文本數據信息進行處理,實現對熱線文本的智能轉派。
11、為解決所述技術問題,經過比較研究,本公開提出基于生成式模型和分層訓練的12345熱線智能轉派的方法。
12、生成式模型是一類機器學習模型,其目標是學習數據的分布并能夠生成類似于訓練數據的新樣本。與判別式模型不同,判別式模型的目標是學習并判別不同類別之間的決策邊界。
13、現有技術中解決熱線智能轉派任務所使用的方法大多都是基于判別式模型,然而,使用判別式模型實現12345熱線智能轉派,會面臨如下困難:
14、(1)數據不平衡;
15、(2)忽略各部門之間的層次關系;
16、(3)錯誤傳遞問題。
17、而生成式模型的核心思想是學習數據的生成過程,以便模型能夠生成新的、與訓練數據相似的樣本。生成模型在概率統計的背景下被廣泛使用,它們試圖對觀測數據的潛在分布進行建模。但生成式模型在解決熱線智能轉派任務的場景中并無應用實例可循。
18、大語言模型也屬于生成式模型的一種,大語言模型(英文:large?languagemodel,縮寫llm),也稱大型語言模型,是一種人工智能模型,旨在理解和生成人類語言。通常,llm是指包含數千億(或更多)參數的transformer語言模型,例如gpt-3,palm,llama和glm。它們在大量的文本數據上進行訓練,可以執行廣泛的任務,包括文本總結、翻譯、情感分析等等。llm的特點是規模龐大,包含數十億的參數,幫助它們學習語言數據中的復雜模式。這些模型通常基于深度學習架構,如轉化器,這有助于它們在各種nlp任務上取得令人印象深刻的表現。
19、經過長時間的發展,llm進化到了當前的狀態,通用且有能力的學習者。在這個過程中,人們提出了許多重要的技術,大大提升了llm的能力,包括擴展,訓練,能力引導,對齊微調以及工具操作等。
20、(1)擴展:transformer語言模型存在明顯的擴展效應,更大的模型和更多的訓練計算通常會導致模型能力的提升。作為兩個代表性的模型,gpt-3和palm通過增加模型規模分別達到了1750億和5400億。此外,由于計算預算通常是有限的,可以利用擴展法則來更高效地分配計算資源。
21、(2)訓練:由于巨大的模型規模,成功訓練一種能力強的llm是非常具有挑戰性的。分布式訓練算法是學習llm網絡參數所必需的,其中通常聯合使用各種并行策略。為了支持分布式訓練,已經發布了一些優化框架來促進并行算法的實現和部署,例如deepspeed和megatron-lm。此外,優化技巧對于訓練穩定性和模型性能也很重要,例如重新開始以克服訓練損失激增和混合精度訓練。
22、(3)能力引導:在大規模語料庫上預訓練之后,llm具備了作為通用任務求解器的潛在能力。然而,當llm執行一些特定任務時,這些能力可能不會顯式地展示出來。作為技術手段,設計合適的任務指令或具體的icl策略可以激發這些能力。此外,我們還可以使用自然語言表達的任務描述對llm進行指令微調,以提高llm在未見任務上的泛化能力。
23、(4)對其微調:由于llm被訓練用來捕捉預訓練語料庫的數據特征(包括高質量和低質量的數據),它們可能會為人類生成有毒、偏見甚至有害的內容。因此,有必要使llm與人類價值觀保持一致,例如有用性、誠實性和無害性。instructgpt設計了一種有效的微調方法,使llm能夠按照期望的指令進行操作,其中利用了基于人類反饋的強化學習技術,它將人類納入訓練循環中,采用精心設計的標注策略。
24、(5)工具操作:從本質上講,llm是基于海量純文本語料庫進行文本生成訓練的,因此在那些不適合以文本形式表達的任務上表現不佳(例如數字計算)。此外,它們的能力也受限于預訓練數據,例如無法獲取最新信息。為了解決這些問題,最近提出了一種技術,即利用外部工具來彌補llm的不足。例如,llm可以利用計算器進行準確計算,利用搜索引擎檢索未知信息。
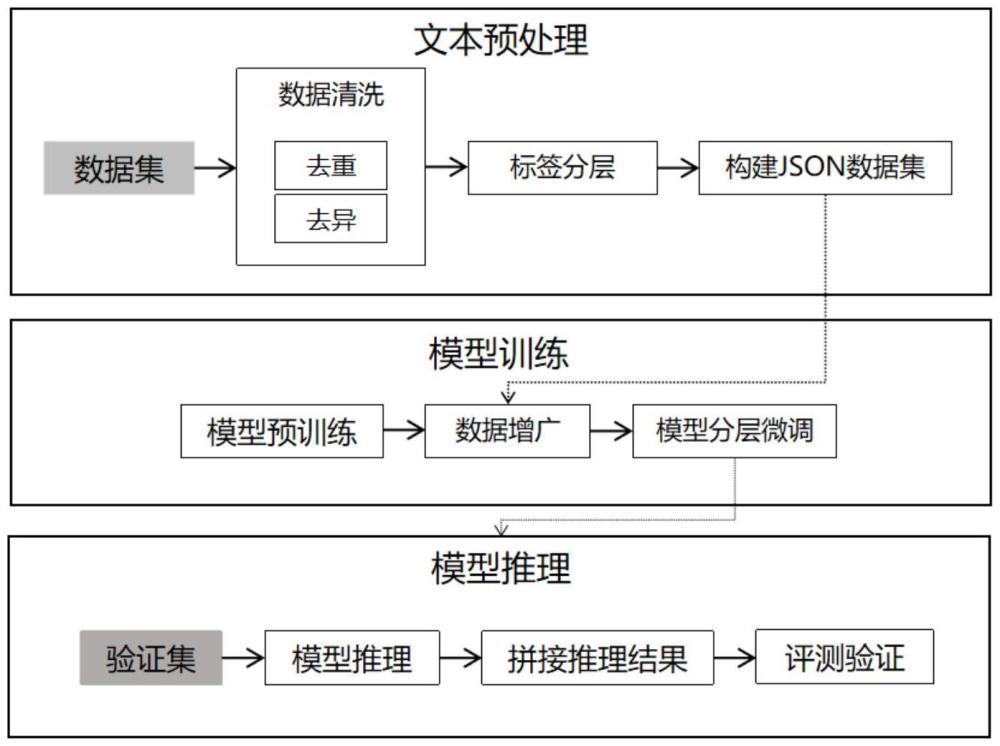
25、因此,本公開提出了一種基于生成式模型和分層訓練的熱線文本智能轉派的方法,使用清華大學研發的大語言模型glm對數據進行增強,然后使用增強后的數據以及相關地區的部門信息對語言模型進行微調訓練。在訓練階段,將轉派部門分類成多個不同層級的部門,為每個層級單獨訓練模型。
26、為了實現上述目的,根據本公開的一個方面,提供了一種基于生成式模型和分層訓練的熱線文本智能轉派方法,包括如下步驟:
27、第一步,文本預處理,具體包括:
28、第1.1步,獲取熱線文本數據集;所述熱線文本數據集的數據來源于熱線電話或網頁所記錄的熱線文本數據;每條所述熱線文本數據包含“文本”和“標簽”兩部分;
29、第1.2步,數據清洗;對熱線文本數據集進行清洗包括處理贅余字符和對數據集進行去重處理兩部分;
30、第1.3步,標簽分層;標簽記錄了部門的流轉路徑,對所有標簽構建層次結構樹;
31、第1.4步,構建json數據集:首先是對數據集拆分,根據層次結構樹的層將數據集分為“文本”相同“標簽”不同的若干數據集,然后對所述數據集分別進行轉碼處理;
32、第二步,模型訓練,具體包括:
33、第2.1步,模型預訓練:以清華大學自主研發的glm預訓練語言模型框架為基礎模型;通過優化一個自回歸空白填充目標來訓練改進模型;
34、第2.2步,數據增廣:利用預訓練完成的模型對數據集做平衡處理;
35、第2.3步,模型分層微調:將所有數據集分別傳入模型中進行微調;
36、第三步,模型推理,具體包括:
37、將驗證集分別輸入所述預訓練模型中,模型架構與transformer轉換器相似,使用自注意力機制;推理輸出過程如公式所示,其中q代表查詢向量query所組成的矩陣,k代表鍵向量所組成的矩陣,kt代表k的轉置矩陣,v代表值向量組成的矩陣,softmax表示歸一化指數函數,dk為k矩陣的維度;自注意力計算的是將查詢向量query和鍵向量和值向量組成的key-value鍵值對的一組集合映射到輸出,輸出被計算為值向量values的加權和,其中分配給每個值向量value的權重由查詢向量query與對應的鍵向量key的相似性函數計算得來;然后將多頭自注意力self-attention處理后的特征向量λ送到前饋層中,它由兩個線性變換組成,激活函數如下:
38、
39、其中λ表示特征向量λ,erf表示誤差函數。
40、優選地,
41、所述“文本”為熱線電話或網頁所收到的投訴或反饋信息,所述“標簽”為職能部門所記錄的熱線文本數據的流轉路徑。
42、優選地,
43、采用python程序對熱線文本數據集進行清洗;所述贅余字符包括空格、制表符以及換行符;
44、所述處理贅余字符包括將每條數據的“文本”和“標簽”分別提取處理,首先判斷每條樣本提取的“標簽”是否為空字符,若為空字符,將“文本”記錄下來并對下一條樣本進行重復操作,直到提取的“標簽”為正常字符,將記錄的“文本”合并組成新樣本,最后將“文本”中制表符、空格以及非末位的換行符都進行刪除;
45、所述對數據集進行去重處理包括:一、如果存在兩條完全相同的數據,則只保留第一次出現的樣本;二、如果樣本的“標簽”的內容與其“文本”內容相同,或“標簽”為其他亂碼,則將這些樣本單獨提取出來進行人工標注或刪除。
46、優選地,
47、采用python程序對所有標簽構建層次結構樹;把捆綁出現的部門作為同層級標簽,對構建的層次結構樹進行層序遍歷,如果當前結點有且只有一個子結點,則將該結點的子結點與其合并。
48、優選地,
49、所述層次結構樹為根節點只有一個的四層結構,只根據層次結構樹的2、3、4層將數據集分為三個“文本”相同“標簽”不同的數據集,分別命名為數據集1,數據集2和數據集3,然后對這三個數據集分別進行轉碼處理。
50、優選地,
51、使用python程序進行轉碼處理,json數據集中每條樣本都有兩個鍵,分別為“text”鍵和“label”鍵,分別對應著原熱線文本數據集中的“文本”和“標簽”。
52、優選地,
53、給定一個輸入文本x=[x1,...,xn],x即為熱線文本數據向量,x1為所述向量的第1項,xn為所述向量的第n項,n為輸入文本的項數,從中采樣多個文本片段{s1,...,sm},其中每個片段si(i=1,…,m),對應與x中的一系列連續的詞[si,1,...,si,l],其中i取1到m之間的整數,m為多個文本片段的片段數量,si,1表示第一個詞,si,l表示第l個詞;每個片段都用一個單獨的[mask]符號替換,形成一個損壞的文本xcorrupt;模型以自回歸的方式從損壞的文本中預測缺失的詞,在預測一個片段中的缺失詞時,模型訪問損壞的文本和之前預測的片段;為了充分捕捉不同片段之間的相互依賴關系,隨機打亂片段的順序;與前文片段數量對應,令zm為長度數量為m的索引序列,令sz<i表示索引長度小于i的索引序列所對應的片段,其中,為第一項,為第i-1項;預訓練目標函數表示為:
54、
55、其中,表示對期望求最大值,θ代表取最大值時需要遍歷取最優值的變量,其中z~zm表示將zm索引序列作為期望的預期變量z,pθ表示生成片段si的概率,表示索引長度為i的索引序列zi所對應的片段,xcorrupt表示片段中有[mask]符號掩碼的損壞文本,表示索引序列的長度是有限制的,其長度小于數量j;
56、按照從左到右的順序生成每個空白中的詞,即生成片段si的概率可以分解為:
57、
58、其中,表示存在xcorrupt時生成片段si的概率,表示存在xcorrupt時生成片段si中的詞si,j的概率的乘積,li代表片段si的長度,表示索引長度為i的索引序列zi所對應的片段,xcorrupt表示片段中有[mask]符號掩碼的損壞文本,表示索引序列的長度是有限制的,長度應當小于數量j,si,<j表示片段si中連續的詞的數量也是有限制的,其數量小于數量j。
59、優選地,輸入文本x被分成兩部分,分別記為part?a和part?b,其中,part?a是損壞的文本xcorrupt,part?b是被遮蓋的片段;part?a中的詞可以相互看到,但不能看到part?b中的任何詞;part?b中的詞可以看到part?a和part?b中的前置詞,但不能看到part?b中的后續詞;每個片段都用特殊的符號開始標志[start]和結束標志[end]進行填充,分別用于輸入和輸出。
60、優選地,還包括如下步驟:
61、(1)所述輸入文本x=[x1,x2,x3,x4,x5,x6],所述輸入文本隨機進行連續[mask]掩碼,圖中[mask]掩碼屏蔽掉了第三輸入詞[x3]和第五第六輸入詞[x5,x6];
62、(2)將第三輸入詞[x3]和第五第六輸入詞[x5,x6]替換為[m]標志,為了捕捉跨度之間的內在聯系,隨機交換跨度的順序;
63、(3)將part?a以part?b輸入模型,模型自回歸的生成part?b,每個片段在輸入時頭部插入[s]標志,在輸出時尾部插入[e]標志;模型在生成時采用的自注意力掩碼與傳統transformer轉換器有所不同,其中有一部分被掩蓋,part?a的詞語可以獲得自身的全部信息,但不能獲得part?b的信息;part?b中的詞語可以看到part?a和所在序列此詞語之前的信息;除此之外在輸入時,part?a還會插入兩個位置編碼分別記為position1和position2,其中position1和position2是輸入的二維編碼,position1記錄了part?b中的片段在parta中的相對位置,position2記錄了part?b中每個片段內部的相對位置。
64、優選地,所述平衡處理包括:首先構建數據增廣所需的專用數據集,將數據集3即最后一層數據集中每個標簽對應的所有文本提取出來,進行兩兩配對,組成新的數據集,記為文本數據集,所述文本數據集的兩個鍵值記為“text1”和“text2”,分別對應著配對成功的兩條文本,每對文本只生成一條新數據;其中,有的標簽隨對應的文本過于稀少或無法配對時,則在數據集2即上一層數據集中查找對應文本的上級標簽,使用其上級標簽進行配對;對每個標簽都進行配對后,生成新的數據集。
65、優選地,微調方式采用p-tuning?v2提示微調,所述p-tuning?v2提示微調包括:
66、對于數據集中的輸入文本[x1,…,xn],在句首加上開始標志[cls]作為中間輸入文本接下來凍結模型參數,并在前加入prompt?embedding提示向量得到模型原始輸入文本x:
67、
68、prompt?embedding=[h0,...,hi]
69、x=[h0,...,hi][cls][x1,…,xn]
70、其中,[cls]表示開始標志,表示輸入文本[x1,…,xn]前加上開始標志[cls]所形成的中間輸入文本,[h0,...,hi]表示prompt?embedding提示向量中的多個詞向量,x表示模型原始輸入文本;
71、模型在微調過程中僅對prompt?embedding提示向量中的參數進行調整優化,每次輸出y會通過一個線性層和優化器,用來調整prompt?embedding提示向量中的參數;其中,
72、y=glm(x)
73、prompt?embedding=optimization(a·y+b)
74、其中y表示模型原始輸入文本x經過預訓練語言模型glm后所輸出的向量,optimization(a·y+b)表示p-tuning?v2提示微調中的線性優化器,a,b表示線性優化器的優化參數。
75、根據本公開的另一個方面,提供了一種基于生成式模型和分層訓練的熱線文本智能轉派系統,包括:
76、文本預處理單元,具體包括:
77、獲取熱線文本數據集單元;所述熱線文本數據集的數據來源于熱線電話或網頁所記錄的熱線文本數據;每條所述熱線文本數據包含“文本”和“標簽”兩部分;
78、數據清洗單元;對熱線文本數據集進行清洗包括處理贅余字符和對數據集進行去重處理兩部分;
79、標簽分層單元;標簽記錄了部門的流轉路徑,對所有標簽構建層次結構樹;
80、構建json數據集單元:首先是對數據集拆分,根據層次結構樹的層將數據集分為“文本”相同“標簽”不同的若干數據集,然后對所述數據集分別進行轉碼處理;
81、模型訓練單元,具體包括:
82、模型預訓練單元:以清華大學自主研發的glm預訓練語言模型框架為基礎模型;通過優化一個自回歸空白填充目標來訓練改進模型;
83、數據增廣單元:利用預訓練完成的模型對數據集做平衡處理;
84、模型分層微調單元:將所有數據集分別傳入模型中進行微調;
85、模型推理單元,具體包括:
86、將驗證集分別輸入所述預訓練模型中,模型架構與transformer轉換器相似,使用自注意力機制;推理輸出過程如公式所示,其中q代表查詢向量query所組成的矩陣,k代表鍵向量所組成的矩陣,kt代表k的轉置矩陣,v代表值向量組成的矩陣,softmax表示歸一化指數函數,dk為k矩陣的維度;自注意力計算的是將查詢向量query和鍵向量和值向量組成的key-value鍵值對的一組集合映射到輸出,輸出被計算為值向量values的加權和,其中分配給每個值向量value的權重由查詢向量query與對應的鍵向量key的相似性函數計算得來;然后將多頭自注意力self-attention處理后的特征向量λ送到前饋層中,它由兩個線性變換組成,激活函數如下:
87、
88、其中λ表示特征向量λ,erf表示誤差函數。
89、根據本公開的再一個方面,本公開提供了一種電子設備,包括:
90、存儲器,所述存儲器存儲執行指令;以及
91、處理器,所述處理器執行所述存儲器存儲的執行指令,使得所述處理器執行上述方法。
92、根據本公開的又一個方面,本公開提供了一種可讀存儲介質,所述可讀存儲介質中存儲有執行指令,所述執行指令被處理器執行時用于實現上述方法。
93、本公開的有益效果:
94、與現有技術相比,本公開所具有的突出的實質性特點和顯著進步如下:
95、(1)以往解決熱線智能轉派任務所使用的方法大多都是基于判別式模型,因此基于生成式模型來解決12345熱線智能轉派問題是社區治理問題大背景下的一個新的嘗試。
96、(2)針對數據集中存在的數據不平衡問題,本方法基于生成式模型通過相同標簽數據配對進行了數據增廣,將少量標簽的樣本多樣化,從而有效的緩解了數據不平衡的問題。
97、(3)自從transformer的出現,文本分類的任務難度大大降低,但傳統的基于transformer的判別式模型只能關注到每條樣本單獨的信息,無法關注到每條樣本之間的聯系,例如語境的相似程度。所以本方法采用了生成式模型來對數據分布進行建模,可以更好的理解數據集中的樣本內容以及每條樣本的上下文信息,因此在進行分類時能夠考慮到文本中的全局信息,能夠更好地識別文本中的關鍵特征和模式,從而提高分類的準確性。
98、(4)傳統的基于生成式模型的文本分類方法中,經常會出現“幻覺問題”,即模型生成的部門并不存在,或生成的部門與上級部門并無關聯關系。所以,本方法提出分層訓練模型,并且在訓練低層級部門對應的模型時,數據集中會包含前一層級的部門信息,使模型更專注當前層級的部門信息以及與上一層級部門的關聯性,改善了由于部門流轉途徑過長而導致的幻覺問題。
技術實現思路
- 還沒有人留言評論。精彩留言會獲得點贊!