模型訓練方法、問答處理方法、裝置及電子設備與流程
本技術屬于計算機,可涉及人工智能、自然語言處理等領域,具體而言,本技術涉及一種模型訓練方法、問答處理方法、裝置及電子設備。
背景技術:
1、預訓練語言模型通過在大規模語料庫上進行訓練,能夠學習到通用的語言表示和知識,然而在特定領域和行業的專業知識儲備卻很有限。
2、為了讓預訓練語言模型能夠更好地適應下游任務,通常需要利用下游任務的數據對預訓練語言模型進行進一步微調。常見的微調方法有參數高效微調方法(parameter-efficient?fine-tuning,peft)、表征微調方法(representation?finetuning,reft)等。
3、其中,采用reft進行微調需要人工設定干預位置,而調試干預位置相關參數需要經過大量的實驗,耗費大量的訓練時間與計算開銷。并且,這種人工設定的方式可能存在冗余的表征干預操作。
技術實現思路
1、本技術實施例的目的旨在提供一種能夠有效縮短模型的微調時間,降低模型的計算開銷的模型訓練方法、以及基于該模型訓練方法的問答處理方法、裝置及電子設備。為實現該目的,本技術實施例提供的技術方案如下:
2、一方面,本技術實施例提供了一種模型訓練方法,所述方法包括:
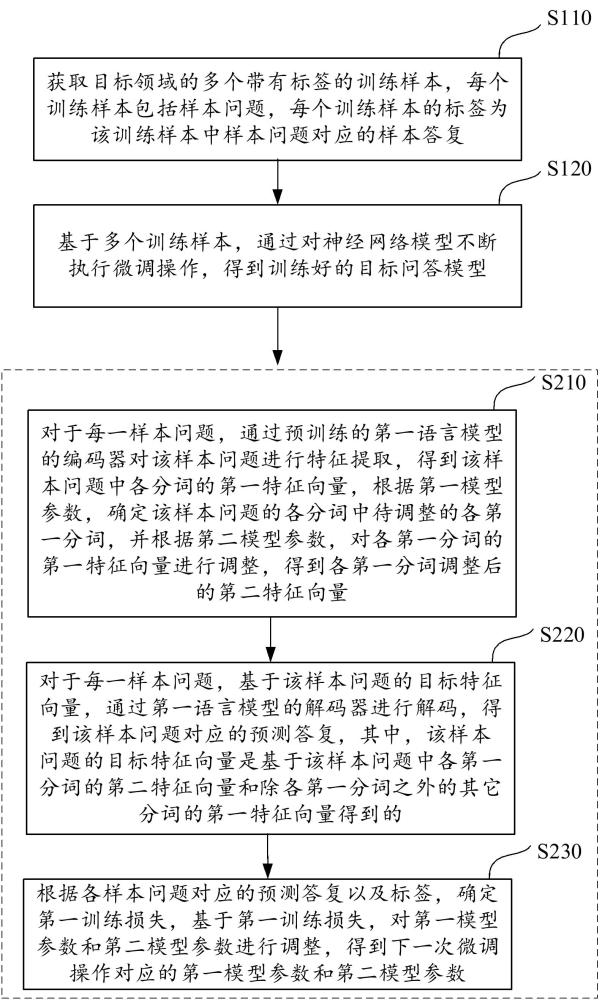
3、獲取目標領域的多個帶有標簽的訓練樣本,每個所述訓練樣本包括樣本問題,每個訓練樣本的標簽為該訓練樣本中樣本問題對應的樣本答復;
4、基于所述多個訓練樣本,通過對神經網絡模型不斷執行微調操作,得到訓練好的目標問答模型;
5、其中,所述微調操作包括:
6、對于每一樣本問題,通過預訓練的第一語言模型的編碼器對該樣本問題進行特征提取,得到該樣本問題中各分詞的第一特征向量,根據第一模型參數,確定該樣本問題的各分詞中待調整的各第一分詞,并根據第二模型參數,對各所述第一分詞的第一特征向量進行調整,得到各所述第一分詞調整后的第二特征向量;
7、對于每一樣本問題,基于該樣本問題的目標特征向量,通過所述第一語言模型的解碼器進行解碼,得到該樣本問題對應的預測答復,其中,該樣本問題的目標特征向量是基于該樣本問題中各所述第一分詞的第二特征向量和除各所述第一分詞之外的其它分詞的第一特征向量得到的;
8、根據各所述樣本問題對應的預測答復以及標簽,確定第一訓練損失,基于所述第一訓練損失,對第一模型參數和第二模型參數進行調整,得到下一次微調操作對應的第一模型參數和第二模型參數。
9、另一方面,本技術實施例還提供了一種模型訓練裝置,所述裝置包括:
10、樣本獲取模塊,用于獲取目標領域的多個帶有標簽的訓練樣本,每個所述訓練樣本包括樣本問題,每個訓練樣本的標簽為該訓練樣本中樣本問題對應的樣本答復;
11、模型微調模塊,用于基于所述多個訓練樣本,通過對神經網絡模型不斷執行微調操作,得到訓練好的目標問答模型;
12、其中,所述微調操作包括:
13、對于每一樣本問題,通過預訓練的第一語言模型的編碼器對該樣本問題進行特征提取,得到該樣本問題中各分詞的第一特征向量,根據第一模型參數,確定該樣本問題的各分詞中待調整的各第一分詞,并根據第二模型參數,對各所述第一分詞的第一特征向量進行調整,得到各所述第一分詞調整后的第二特征向量;
14、對于每一樣本問題,基于該樣本問題的目標特征向量,通過所述第一語言模型的解碼器進行解碼,得到該樣本問題對應的預測答復,其中,該樣本問題的目標特征向量是基于該樣本問題中各所述第一分詞的第二特征向量和除各所述第一分詞之外的其它分詞的第一特征向量得到的;
15、根據各所述樣本問題對應的預測答復以及標簽,確定第一訓練損失,基于所述第一訓練損失,對第一模型參數和第二模型參數進行調整,得到下一次微調操作對應的第一模型參數和第二模型參數。
16、可選的,所述編碼器包括多個級聯的特征提取層;所述第一模型參數包括至少一個特征提取層對應的層參數;
17、對于每一樣本問題,該樣本問題對應的預測答復是通過以下方式得到的:
18、將該樣本問題輸入到所述編碼器中,通過所述編碼器對該樣本問題進行特征提取,得到該樣本問題中各分詞對應于每一特征提取層的第一特征向量;
19、對于所述至少一個特征提取層中的每一特征提取層,基于該特征提取層對應的層參數,確定該樣本問題的各分詞中待調整的各第一分詞,采用第二模型參數對各所述第一分詞的第一特征向量進行調整,得到各所述第一分詞的第二特征向量,將各所述第一分詞的第二特征向量和除各所述第一分詞之外的其他分詞的第一特征向量,作為該特征提取層的目標特征向量,將該特征提取層的目標特征向量作為下一特征提取層的輸入;
20、對于除所述至少一個特征提取層外的每一特征提取層,將通過該特征提取層得到該樣本問題中各分詞的第一特征向量,作為該特征提取層的目標特征向量,將該特征提取層的目標特征向量作為下一特征提取層的輸入;
21、基于所述編碼器的最后一個特征提取層的目標特征向量,通過所述解碼器進行解碼,得到該樣本問題對應的預測答復。
22、可選的,所述第一模型參數包括樣本問題中各分詞的子參數,一個分詞的子參數用于確定是否對該分詞的第一特征向量進行調整;
23、所述模型微調模塊可以用于:
24、根據各所述樣本問題中各分詞的子參數之和,確定第二訓練損失;
25、基于所述第一訓練損失和所述第二訓練損失,對第一模型參數和第二模型參數進行調整。
26、可選的,所述第一模型參數包括樣本問題中各分詞的子參數,一個分詞的子參數用于確定是否對該分詞的第一特征向量進行調整;
27、所述模型微調模塊可以用于:
28、確定該樣本問題中各分詞各自對應的隨機噪聲;
29、基于各所述分詞各自對應的隨機噪聲對各所述分詞的子參數進行調整,得到各所述分詞的目標調整概率;
30、根據各所述分詞的目標調整概率,確定待調整的各第一分詞。
31、可選的,所述第一模型參數包括預設數量的分詞的子參數;
32、所述模型微調模塊可以用于:
33、確定該樣本問題中的分詞的第一數量;
34、若所述第一數量等于預設數量,將該樣本問題作為待處理的樣本問題;
35、若所述第一數量小于所述預設數量,則采用預設字符對所述樣本問題進行填充,并將填充后的樣本問題作為待處理的樣本問題,其中,填充后的樣本問題中分詞的數量為所述預設數量;
36、通過所述編碼器對待處理的樣本問題進行特征提取,得到待處理的樣本問題中各分詞的第一特征向量。
37、可選的,所述第一模型參數是通過以下方式確定的:
38、根據所述多個樣本問題中各分詞的內容和詞性中的至少一項,統計每個位置的分詞的重要程度;
39、根據各所述樣本問題中各位置的分詞的重要程度,確定各第一位置;
40、根據各所述第一位置的分詞的子參數,確定第一模型參數。
41、可選的,所述模型微調模塊還可以用于:
42、確定所述目標領域的領域類型;
43、若所述領域類型為第一類型,所述至少一個特征提取層包括所述多個級聯的特征提取層中的各個特征提取層;
44、若所述領域類型不是第一類型,所述至少一個特征提取層包括所述多個級聯的特征提取層中的部分特征提取層。
45、可選的,所述模型微調模塊可以用于:
46、基于該樣本問題構建對應的提示詞指令,所述提示詞指令用于指示所述神經網絡模型基于樣本問題輸出對應答復;
47、通過所述第一語言模型的編碼器對所述提示詞指令進行特征提取。
48、另一方面,本技術實施例還提供了一種問答處理方法,該方法包括:
49、獲取目標領域的待答復問題;
50、通過訓練好的目標問答模型,得到所述待答復問題對應的答復;其中,所述目標問答模型是采用本技術任一可選實施例中提供的模型訓練方法訓練得到的。
51、再一方面,本技術實施例還提供了一種問答處理裝置,該裝置包括:
52、問題獲取模塊,用于獲取目標領域的待答復問題;
53、答復模塊,用于通過訓練好的目標問答模型,得到所述待答復問題對應的答復;其中,所述目標問答模型是采用本技術任一可選實施例中提供的模型訓練方法訓練得到的。
54、另一方面,本技術實施例還提供了一種電子設備,該電子設備包括存儲器和處理器,存儲器中存儲有計算機程序,處理器執行該計算機程序以實現本技術任一可選實施例中提供的模型訓練方法,或者實現本技術任一可選實施例提供的問答處理方法。
55、另一方面,本技術實施例還提供了一種計算機可讀存儲介質,該存儲介質中存儲有計算機程序,該計算機程序被處理器執行時實現本技術任一可選實施例中提供的模型訓練方法,或者實現本技術任一可選實施例提供的問答處理方法。
56、另一方面,本技術實施例還提供了一種計算機程序產品,該計算機程序產品包括計算機程序,該計算機程序被處理器執行時實現本技術任一可選實施例中提供的模型訓練方法,或者實現本技術任一可選實施例提供的問答處理方法。
57、本技術實施例提供的技術方案帶來的有益效果如下:
58、本技術實施例提供的模型訓練方法,在基于目標領域的多個帶標簽的訓練樣本對神經網絡模型不斷進行微調的過程中,基于第一模型參數從訓練樣本的各分詞中確定待調整的各第一分詞,并根據第二模型參數對各第一分詞的第一特征向量進行調整,通過引入第一模型參數和第二模型參數,使得模型能夠自動選擇對哪些分詞的第一特征向量進行調整,而無需通過人工重復多次調試,避免引入冗余的表征干預操作,同時能夠縮短模型微調的訓練時間,有效降低模型的計算復雜度,降低模型的計算開銷。
- 還沒有人留言評論。精彩留言會獲得點贊!