一種農田氮淋失預測方法、設備及介質
本技術涉及氮淋失預測領域,特別是涉及一種農田氮淋失預測方法、設備及介質。
背景技術:
1、由于人口增長和人們生活水平的提高,糧食產量需求持續增長,大量水肥投入成為提高作物產量的主要措施。農田中過量施用的氮肥一部分在土壤中殘留,而很大一部分則會隨水分遷移并淋失到作物根區以外的區域,進入地下水體,造成面源污染和水體富營養化等諸多環境問題。因此,明確農田生產中的氮淋失特征,對氮淋失進行定量預測,對提高農業生產效益和保護環境具有重要意義。
2、目前對于氮淋失的預測模型中主要關注單個因素對氮淋失的影響,且多為指數和線性模型。由于不同試驗區域土壤和環境條件的多樣性并且差異較大,通過單一因素對氮淋失進行預測并不能充分解釋氮淋失的復雜變化情況。而一些機理模型【反硝化-分解模型(denitrification-decomposition,dndc)、水氮管理模型(water?and?nitrogenmanagement?model,wnmm)等】需要參數較多,模擬精度受多種條件影響。
3、現有的能夠定量預測農田氮淋失方法主要是單因素線性、指數或多項式回歸和多因素線性或逐步回歸,但大部分線性、指數或多項式回歸和多因素線性或逐步回歸基于最小二乘法的數學原理(通過最小化殘差平方和來估計回歸系數,使得模型預測值與實際觀測值的差異最小化)建立相關模型,基于此,現有技術存在以下缺點:
4、(1):常規的擬合模型擬合度較低,預測效果較差。
5、(2):需要逐步篩選較多的指標,從而最后確定需要的相關指標,操作過程較為繁瑣。
6、(3):常規回歸方法對如土壤類型等文本類型變量難以操作。
7、(4):常規模型預測結果準確性受土壤異質性等影響大,模型多適用于特定地點、特定試驗條件,在較大區域適用性差。
8、為了解決現有技術存在的上述問題,現在多采用機器學習的方式進行氮淋失預測(例如中國專利申請cn115965121a),但是,由于機器學習的“黑盒效應”會造成,預測結果難以解釋的情況,并不能真正意義上實現氮淋失量的準確和全面預測。
技術實現思路
1、本技術的目的是提供一種農田氮淋失預測方法、設備及介質,能夠解決由于機器學習“黑盒效應”造成的結果難以解釋的問題,同時,能夠實現氮淋失量的準確和全面預測。
2、為實現上述目的,本技術提供了如下方案:
3、第一方面,本技術提供了一種農田氮淋失預測方法,包括:
4、獲取農田氮淋失試驗數據;所述農田氮淋失試驗數據包括:土壤性質、采樣措施、農田管理措施和總氮淋失量;所述土壤性質包括:土壤ph、有機質含量、土壤全氮含量、粘粒含量、砂粒含量和土壤類型;采樣措施包括:采樣方法和采樣深度;農田管理措施包括:還田秸稈量、總施氮量和水分投入量;總施氮量包括:化肥施氮量、秸稈還田輸入氮量和有機肥輸入氮量;水分投入量包括:降雨量和灌溉量;
5、對所述農田氮淋失試驗數據進行預處理;
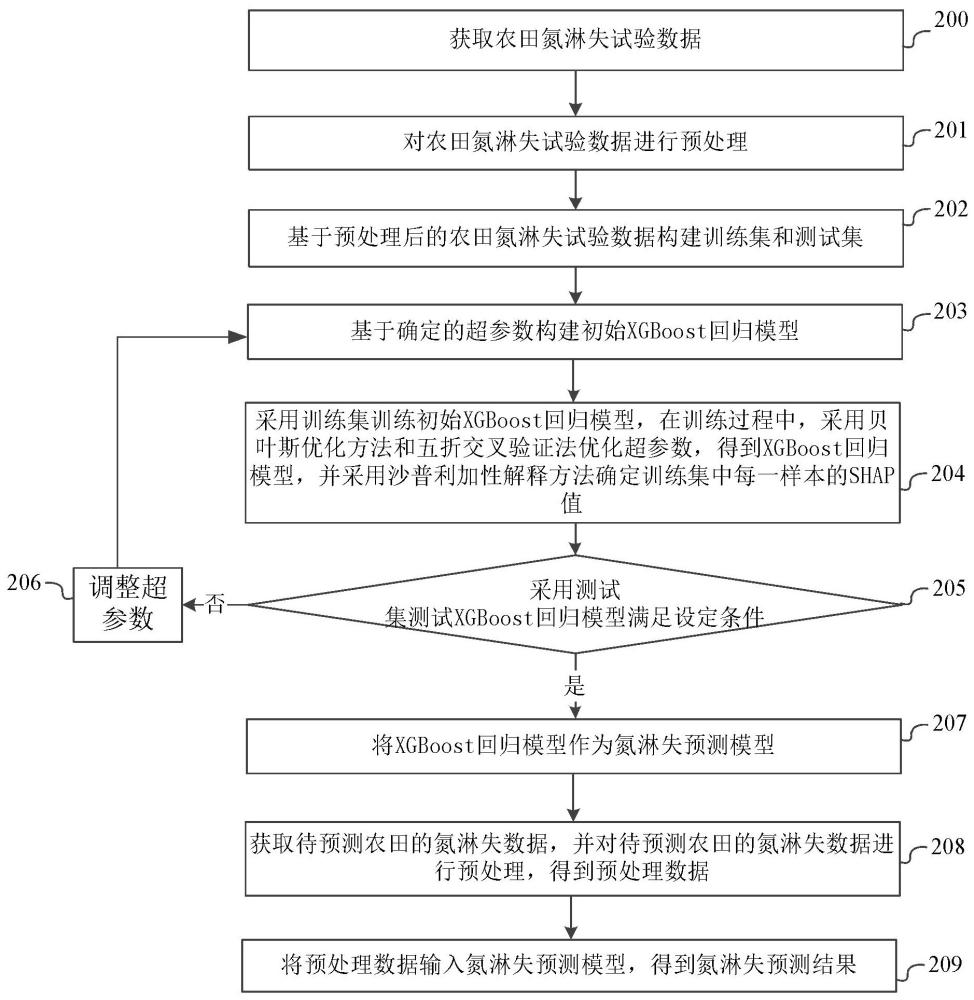
6、基于預處理后的所述農田氮淋失試驗數據構建訓練集和測試集;
7、基于確定的超參數構建初始xgboost回歸模型;
8、采用訓練集訓練所述初始xgboost回歸模型,在訓練過程中,采用貝葉斯優化方法和五折交叉驗證法優化超參數,得到xgboost回歸模型,并采用沙普利加性解釋方法確定所述訓練集中每一樣本的shap值;
9、采用測試集測試所述xgboost回歸模型是否滿足設定條件;
10、如果所述xgboost回歸模型不滿足設定條件,則調整超參數,返回基于確定的超參數構建初始xgboost回歸模型的步驟;
11、如果所述xgboost回歸模型滿足設定條件,則將所述xgboost回歸模型作為氮淋失預測模型;
12、獲取待預測農田的氮淋失數據,并對所述待預測農田的氮淋失數據進行預處理,得到預處理數據;所述待預測農田的氮淋失數據包括:待預測農田的土壤性質、待預測農田的采樣措施、待預測農田的農田管理措施和待預測農田的總氮淋失量;
13、將所述預處理數據輸入所述氮淋失預測模型,得到氮淋失預測結果。
14、可選地,所述預處理包括:缺失值處理、對數處理、數據標準化和獨熱編碼處理。
15、可選地,對所述農田氮淋失試驗數據進行預處理,包括:
16、對所述農田氮淋失試驗數據進行缺失值處理,得到第一處理數據;
17、對所述第一處理數據進行對數處理,得到第二處理數據;
18、對所述第二處理數據進行標準化處理,得到第三處理數據;
19、對所述第三處理數據進行獨熱編碼處理,得到預處理后的所述農田氮淋失試驗數據。
20、可選地,對所述農田氮淋失試驗數據進行缺失值處理,包括:
21、當土壤性質、采樣措施或農田管理措施缺失時,刪除土壤性質、采樣措施或農田管理措施缺失的數據;
22、當總氮淋失量缺失時,對于存在硝態氮淋失量的數據,將缺失的總氮淋失量按照硝態氮淋失量占比為95%的比例進行換算;對于不存在硝態氮淋失量的數據,刪除總氮淋失量缺失的數據。
23、可選地,基于預處理后的所述農田氮淋失試驗數據構建訓練集和測試集,包括:
24、利用pandas庫將所述農田氮淋失試驗數據劃分為自變量和因變量;所述自變量包括:土壤性質、采樣措施和農田管理措施;所述因變量包括:總氮淋失量;
25、利用sklearn庫,對所述自變量和所述因變量進行隨機劃分,得到所述訓練集和所述測試集。
26、可選地,采用貝葉斯優化方法和五折交叉驗證法優化超參數,包括:
27、在設定的超參數范圍中隨機采樣一組超參數作為初始超參數,進行貝葉斯優化;
28、在每次貝葉斯優化迭代中,根據當前的代理模型和已有的觀察結果,計算所有候選點的采樣函數值,并選擇具有最高采樣函數值的點作為貝葉斯優化的下一個點;
29、采取五折交叉驗證法,將所述訓練集分成n個子集,輪流使用其中n-1個子集進行下一個點的訓練,使用剩下的一個子集進行下一個點的驗證,分別計算n次均方誤差,并且確定n次均方誤差的平均值;
30、在優化過程結束后,選取均方誤差平均值最小的點對應的超參數作為優化后的超參數。
31、可選地,采用沙普利加性解釋方法確定所述訓練集中每一樣本的shap值,包括:
32、采用kernel?shap方法,基于shapley值的概念,使用核函數確定所述訓練集中每一樣本的shap值。
33、可選地,采用沙普利加性解釋方法確定所述訓練集中每一樣本的shap值,包括:
34、采用tree?shap方法,利用樹結構的性質,通過迭代地向上遍歷樹的方式確定所述訓練集中每一樣本的shap值。
35、第二方面,本技術提供了一種計算機設備,包括:存儲器、處理器以及存儲在存儲器上并可在處理器上運行的計算機程序,所述處理器執行所述計算機程序以實現上述提供的農田氮淋失預測方法的步驟。
36、第三方面,本技術提供了一種計算機可讀存儲介質,其上存儲有計算機程序,該計算機程序被處理器執行時實現上述提供的農田氮淋失預測方法的步驟。
37、根據本技術提供的具體實施例,本技術公開了以下技術效果:
38、本技術提供了一種農田氮淋失預測方法、設備及介質,本技術通過以包括土壤性質、采樣措施、農田管理措施和總氮淋失量的農田氮淋失試驗數據為數據基礎,進行模型構建,考慮了多個因素對總氮淋失量的影響,解決了常規模型通過單一變量進行預測效果差的問題。在訓練過程中,采用沙普利加性解釋方法確定訓練集中每一樣本的shap值,可以快速篩選重要程度較高的數據,解決了由于機器學習“黑盒效應”造成結果難以解釋的問題。通過采用貝葉斯優化方法和五折交叉驗證法優化超參數,能夠提高模型預測的準確性,進而實現了氮淋失量的準確和全面預測。