基于交叉融合與置信評估的情緒識別智能合約構建方法
本發明涉及半監督表情識別,尤其是指一種基于交叉融合與置信評估的情緒識別智能合約構建方法。
背景技術:
1、康養,是一種針對老年人群體的綜合性養老服務模式。它不僅關注老年人的基本生活照料,更強調通過康復、養生等手段,提升老年人的身體健康水平,同時注重心理健康和精神生活的豐富,以實現老年人身心健康的全面提升。老年人由于生理機能的衰退和社會角色的轉變,往往更容易出現孤獨、抑郁、焦慮等情緒問題。這些情緒問題如果得不到及時的發現和干預,可能會進一步發展為嚴重的心理疾病,如抑郁癥、焦慮癥等。通過情緒識別,可以實時監測老年人的情緒狀態,一旦發現異常,就能立即采取措施進行干預,從而有效預防心理疾病的發生。
2、在過去的幾十年中,情緒識別方法取得了顯著進展,并提出了眾多創新方案,但大多數方法依賴于有監督學習。由于標注面部表情需要分析師的專業知識,獲取大規模的標注數據需要付出大量的人力、物力和財力,有監督的面部表情識別在實際應用中存在較大的局限性。半監督學習旨在利用少量標記樣本訓練模型的同時,減少對大規模手工標注的依賴。一致性正則化和偽標簽法是現代半監督學習設計的兩個基本方法。一致性正則化通過鼓勵模型在輸入空間中具有一致性的方式進行訓練,減少模型在未標記數據上的預測誤差;但可能會導致模型在未標記數據上過度擬合,降低模型的泛化能力。偽標簽法利用標記數據進行監督學習,使用模型對未標記數據進行預測,選擇置信度較高的預測結果作為偽標簽,將偽標簽與標記數據一起用于訓練;一旦模型生成了錯誤的偽標簽,這些錯誤可能會在后續的訓練過程中被傳遞并放大,導致模型性能下降。
3、且在目前區塊鏈網絡中,區塊鏈技術憑借其去中心化、高透明性以及不可篡改的獨特特性,已經廣泛應用于包括醫療在內的多個領域,展現出其強大的應用潛力和價值。在區塊鏈技術應用與康養產業中,如何記錄情緒數據成為一個問題。區塊鏈雖然能保證數據的不可篡改性,但現有的技術缺乏有效的數據驗證機制,比如在數據添加進區塊鏈之前,對表情數據進行分析。這種缺乏分析的環節容易導致老年人的不穩定情緒數據直接被寫入區塊鏈中,從而影響對老年人的情緒檢測,無法有效的及時介入。
4、綜上所述,現有的依賴于有監督學習的識別方法,由于標注面部表情需要分析師的專業知識,獲取大規模的標注數據需要付出大量的人力、物力和財力,在實際應用中存在較大的局限性;且獲取的標注數據若由于存儲不當導致數據異常,也會使得訓練出的模型不夠準確,進而導致識別結果不準確,無法及時獲取異常情緒并進行干預。
技術實現思路
1、為此,本發明所要解決的技術問題在于克服現有技術中無法準確識別出面部表情的情緒類型,且對于獲取的表情數據存在存儲不安全,導致影響模型訓練精度的問題。
2、為解決上述技術問題,本發明提供了一種基于交叉融合與置信評估的情緒識別智能合約構建方法,包括:
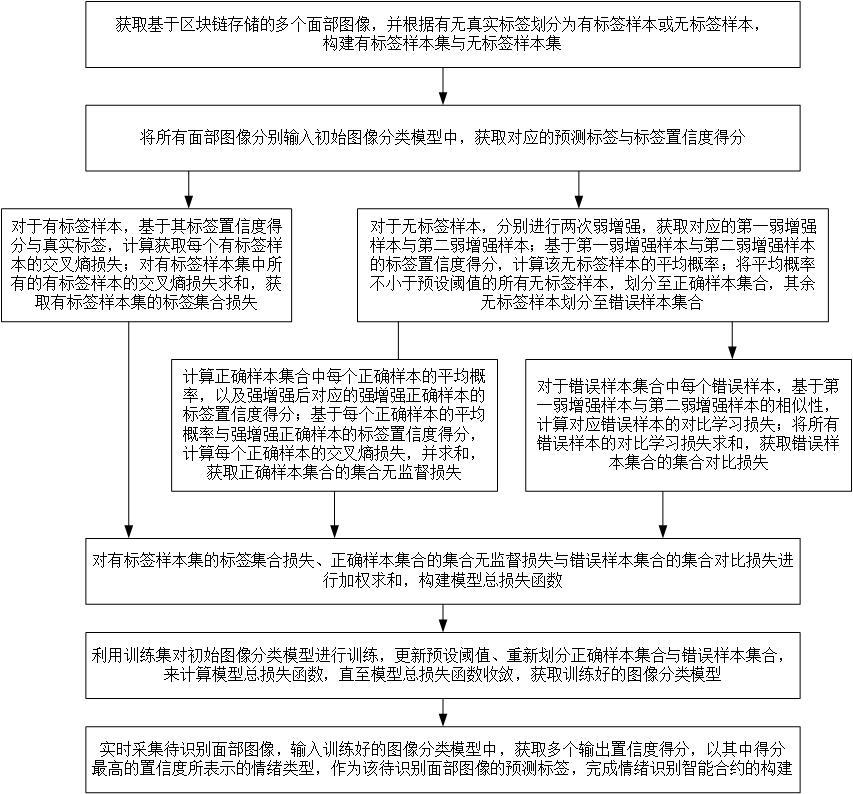
3、獲取基于區塊鏈存儲的多個面部圖像,并根據有無真實標簽劃分為有標簽樣本或無標簽樣本,構建有標簽樣本集與無標簽樣本集;
4、將所有面部圖像分別輸入初始圖像分類模型中,獲取對應的預測標簽與標簽置信度得分;
5、對于有標簽樣本,基于其標簽置信度得分與真實標簽,計算獲取每個有標簽樣本的交叉熵損失;對有標簽樣本集中所有的有標簽樣本的交叉熵損失求和,獲取有標簽樣本集的標簽集合損失;
6、對于無標簽樣本,分別進行兩次弱增強,獲取對應的第一弱增強樣本與第二弱增強樣本;基于第一弱增強樣本與第二弱增強樣本的標簽置信度得分,計算該無標簽樣本的平均概率;將平均概率不小于預設閾值的所有無標簽樣本,劃分至正確樣本集合,其余無標簽樣本劃分至錯誤樣本集合;
7、計算正確樣本集合中每個正確樣本的平均概率,以及強增強后對應的強增強正確樣本的標簽置信度得分;基于每個正確樣本的平均概率與強增強正確樣本的標簽置信度得分,計算每個正確樣本的交叉熵損失,并求和,獲取正確樣本集合的集合無監督損失;
8、對于錯誤樣本集合中每個錯誤樣本,基于第一弱增強樣本與第二弱增強樣本的相似性,計算對應錯誤樣本的對比學習損失;將所有錯誤樣本的對比學習損失求和,獲取錯誤樣本集合的集合對比損失;
9、對有標簽樣本集的標簽集合損失、正確樣本集合的集合無監督損失與錯誤樣本集合的集合對比損失進行加權求和,構建模型總損失函數;
10、利用訓練集對初始圖像分類模型進行訓練,更新預設閾值、重新劃分正確樣本集合與錯誤樣本集合,來計算模型總損失函數,直至模型總損失函數收斂,獲取訓練好的圖像分類模型;
11、實時采集待識別面部圖像,輸入訓練好的圖像分類模型中,獲取多個輸出置信度得分,以其中得分最高的置信度所表示的情緒類型,作為該待識別面部圖像的預測標簽,完成情緒識別智能合約的構建。
12、優選地,將面部圖像輸入圖像分類模型中,獲取對應的預測標簽與標簽置信度得分,包括:
13、將面部圖像輸入圖像分類模型中,經過特征提取器,獲取出對應的面部特征圖;
14、將面部特征圖輸入塊轉換模塊中,劃分為多個相同大小的patch,組成patch特征圖;每個patch均包括多個token;
15、將patch特征圖輸入交叉多頭注意力機制模塊中,將patch特征圖中的所有token劃分至多個通道上;所述通道的數量與交叉多頭注意力機制模塊中的head數量相同;
16、在每個通道上,對位于不同patch上相同位置處有相同head索引的token,執行kqv計算,獲取每個token的注意力權重,并進行加權求和后,依次經過沿正傳播方向串聯的層歸一化單元、線性層單元、激活函數單元、線性層單元與層歸一化單元,獲取加權特征向量;
17、將加權特征向量輸入分類器中,依次經過全局平均池化單元與全連接層,輸出面部圖像樣本的每種情緒類別的置信度得分;
18、獲取其中置信度得分最高的情緒類別,作為面部圖像的預測標簽,其對應的置信度得分作為面部圖像的標簽置信度得分。
19、優選地,所述特征提取器為截斷resnet。
20、優選地,獲取待識別面部圖像的預測標簽后,還包括:將所述待識別面部圖像的預測標簽作為真實標簽,與待識別面部圖像構建為有標簽樣本,存儲至區塊鏈中。
21、優選地,所述對于有標簽樣本,基于其標簽置信度得分與真實標簽,計算獲取每個有標簽樣本的交叉熵損失;對有標簽樣本集中所有的有標簽樣本的交叉熵損失求和,獲取有標簽樣本集的標簽集合損失,表示為:
22、;
23、其中,表示有標簽樣本集的標簽集合損失,表示訓練的批量大小;表示交叉熵損失;有標簽樣本集,表示有標簽樣本集合中第個有標簽樣本的真實標簽,表示有標簽樣本的總數量;表示有標簽樣本集合中第個有標簽樣本的標簽置信度得分。
24、優選地,所述預設閾值,表示為:
25、;
26、其中,表示第輪訓練中第類情緒類別的閾值,表示情緒類別總數量,;表示訓練輪次,當時,預設閾值的起始值為;為預設超參數,表示訓練的批量大小,表示第個無標簽樣本屬于第類情緒類別的標簽置信度得分。
27、優選地,所述對于無標簽樣本,分別進行兩次弱增強,獲取對應的第一弱增強樣本與第二弱增強樣本;基于第一弱增強樣本與第二弱增強樣本的標簽置信度得分,計算該無標簽樣本的平均概率;將平均概率不小于預設閾值的所有無標簽樣本,劃分至正確樣本集合,其余無標簽樣本劃分至錯誤樣本集合,包括:
28、將無標簽樣本集中每個無標簽樣本進行兩次弱增強,獲取每個無標簽樣本對應的第一弱增強樣本與第二弱增強樣本;與分別表示第一弱增強操作與第二弱增強操作,表示無標簽樣本集中無標簽樣本總個數;
29、基于無標簽樣本對應的第一弱增強樣本與第二弱增強樣本的標簽置信度得分,計算該無標簽樣本的平均概率,表示為:;
30、若該無標簽樣本的平均概率不小于預設閾值,則將該無標簽樣本劃分至正確樣本集合,表示正確樣本集合中正確樣本總個數;
31、若該無標簽樣本的平均概率小于預設閾值,則將該無標簽樣本劃分至錯誤樣本集合。
32、優選地,所述計算正確樣本集合中每個正確樣本的平均概率,以及強增強后對應的強增強正確樣本的標簽置信度得分;基于每個正確樣本的平均概率與強增強正確樣本的標簽置信度得分,計算每個正確樣本的交叉熵損失,并求和,獲取正確樣本集合的集合無監督損失,包括:
33、對正確樣本進行強增強,獲取強增強正確樣本,計算強增強正確樣本的標簽置信度得分;
34、基于該正確樣本的平均概率與強增強正確樣本的標簽置信度得分,計算該正確樣本的交叉熵損失;
35、對所有正確樣本的交叉熵損失求和,獲取正確樣本集合的集合無監督損失,表示為:;
36、其中,表示正確樣本集合中正確樣本總個數;表示交叉熵損失。
37、優選地,所述對于錯誤樣本集合中每個錯誤樣本,基于第一弱增強樣本與第二弱增強樣本的相似性,計算對應錯誤樣本的對比學習損失;將所有錯誤樣本的對比學習損失求和,獲取錯誤樣本集合的集合對比損失,包括:
38、獲取第一弱增強樣本與第二弱增強樣本對應的面部表情特征與,計算樣本相似性,表示為:;
39、計算錯誤樣本的對比學習損失,表示為:;
40、將所有錯誤樣本的對比學習損失求和,獲取錯誤樣本集合的集合對比損失,表示為:;
41、其中,表示范數,表示錯誤樣本集合中錯誤樣本總個數;,;表示預設比值。
42、優選地,完成情緒識別智能合約的構建后,還包括對情緒識別智能合約進行編譯后,部署至區塊鏈。
43、本發明的上述技術方案相比現有技術具有以下有益效果:
44、本發明所述的基于交叉融合與置信評估的情緒識別智能合約構建方法,將獲取的面部圖像按照有標簽與無標簽劃分;對于有標簽樣本集,計算其每個有標簽樣本的交叉熵損失求和,獲取標簽集合損失;對于無標簽樣本集,計算每個無標簽樣本的平均概率與預設閾值比較,劃分為正確樣本與錯誤樣本,計算正確樣本的交叉熵損失與錯誤樣本的對比學習損失,分別求和,獲取正確樣本集合的集合無監督損失與錯誤樣本集合的集合對比損失;對有標簽樣本集的標簽集合損失、正確樣本集合的集合無監督損失與錯誤樣本集合的集合對比損失進行加權求和,構建模型總損失函數,來訓練圖像分類模型;其中,預設閾值根據訓練次數自適應更新,從而更加有效地利用未標記數據進行訓練,提升模型性能,并且在面部表情識別任務中取得了顯著的性能提升,提高了圖像分類模型的預測準確度。
45、本發明將待識別面部圖像的預測標簽作為真實標簽,與待識別面部圖像構建為有標簽樣本,存儲至區塊鏈中,更新有標簽樣本集,顯著提升了對面部圖像進行處理的實時性與準確性,還確保了數據的不可篡改性與高度安全性,為康養行業提供了更加科學、可靠的情緒監測與管理手段,從而全面提升了服務質量和老年人的生活質量。
46、本發明利用截斷resnet作為特征提取器,并且通過使用預訓練權重來減少對樣本的過擬合風險;在特征提取時,截斷resnet已經考慮了局部特征的重要性,因此在進行全局建模時,并不需要對細節和局部特征進行過深的觀察。且利用塊轉換模塊,將面部特征圖分割成相同大小的patch,而每個patch中包含若干個token;每個token只需考慮與不同patch中相同位置的token之間的關系,專注于局部patch,能夠更有效地過濾掉無關信息,專注于對表情識別有用的特征,增強不同表情之間的區分能力,并且利用多頭交叉注意力機制,從patch特征圖中提取特征向量,每個head獨立計算注意力分數,然后將結果進行拼接和線性變換,以捕捉到不同子空間中的信息,進一步提高了模型預測的準確性;在保證性能的同時提高計算效率,提高了對康養產業中圖像智能識別的準確度。
- 還沒有人留言評論。精彩留言會獲得點贊!