一種大數據聯盟算法的云平臺搭建方法及系統與流程
本發明涉及云計算,尤其涉及一種大數據聯盟算法的云平臺搭建方法及系統。
背景技術:
1、云平臺是一種基于云服務的平臺,用于數據存儲、處理和分析。云平臺可以根據需求動態擴展或縮減資源,企業可以根據實際工作負載靈活調整計算和存儲能力,而無需投資昂貴的服務器和硬件。此外,還具有安全性及訪問便捷性等諸多優點。
2、然而,云平臺對用戶提供服務往往需要大量的數據作為支撐,例如,想要了解用戶興趣為用戶進行推送,或者提供最新最全面的農業資訊供用戶檢索,都需要采集大量的數據。集到的數據量的質量,決定著云平臺服務質量。例如農業網站等更領域專業化的平臺,想要進一步提高云平臺對用戶群體的服務質量,就必須解決采集用戶數據時數據來源單一性、質量較差問題。
技術實現思路
1、本發明提供一種大數據聯盟算法的云平臺搭建方法及系統,其主要目的在于解決采集用戶數據時數據來源單一性、質量較差問題。
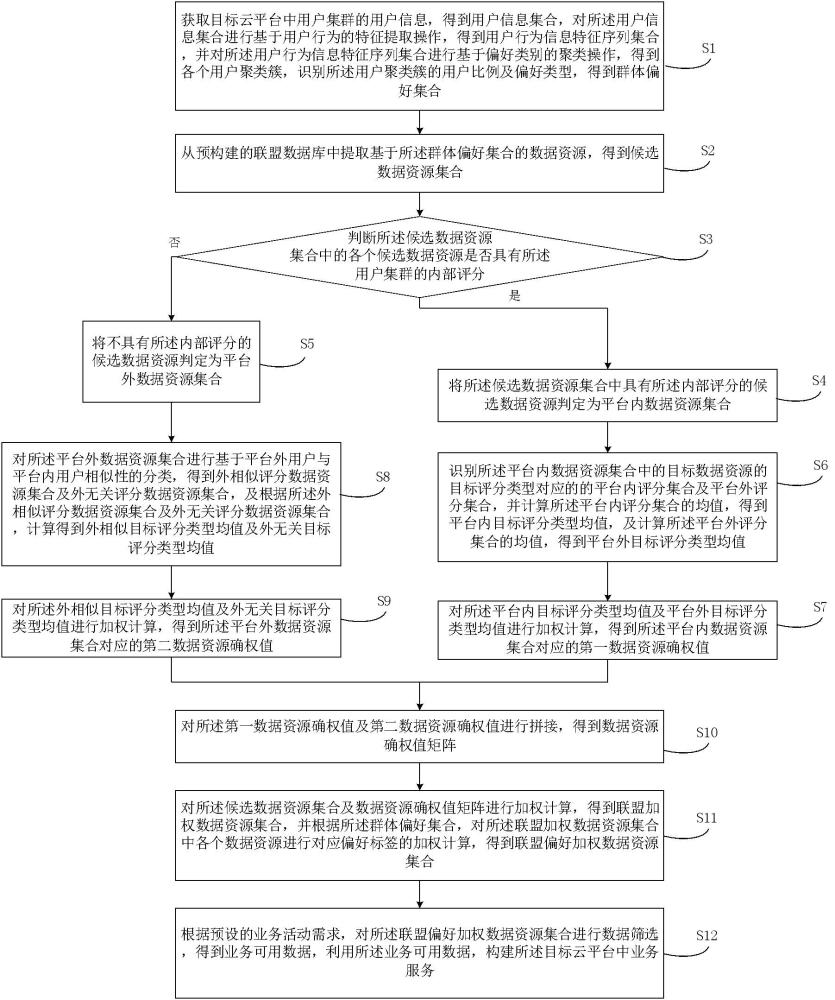
2、為實現上述目的,本發明提供的一種大數據聯盟算法的云平臺搭建方法,包括:
3、獲取目標云平臺中用戶集群的用戶信息,得到用戶信息集合,對所述用戶信息集合進行基于用戶行為的特征提取操作,得到用戶行為信息特征序列集合,并對所述用戶行為信息特征序列集合進行基于偏好類別的聚類操作,得到各個用戶聚類簇,識別所述用戶聚類簇的用戶比例及偏好類型,得到群體偏好集合;
4、從預構建的聯盟數據庫中提取基于所述群體偏好集合的數據資源,得到候選數據資源集合;
5、判斷所述候選數據資源集合中的各個候選數據資源是否具有所述用戶集群的內部評分,其中,所述內部評分為包括準確性、完整性、及時性及易用性的各個評分類型的分數集合;
6、將所述候選數據資源集合中具有所述內部評分的候選數據資源判定為平臺內數據資源集合;
7、將不具有所述內部評分的候選數據資源判定為平臺外數據資源集合;
8、識別所述平臺內數據資源集合中的目標數據資源的目標評分類型對應的平臺內評分集合及平臺外評分集合,并計算所述平臺內評分集合的均值,得到平臺內目標評分類型均值,及計算所述平臺外評分集合的均值,得到平臺外目標評分類型均值;
9、對所述平臺內目標評分類型均值及平臺外目標評分類型均值進行加權計算,得到所述平臺內數據資源集合對應的第一數據資源確權值;
10、對所述平臺外數據資源集合進行基于平臺外用戶與平臺內用戶相似性的分類,得到外相似評分數據資源集合及外無關評分數據資源集合,及根據所述外相似評分數據資源集合及外無關評分數據資源集合,計算得到外相似目標評分類型均值及外無關目標評分類型均值;
11、對所述外相似目標評分類型均值及外無關目標評分類型均值進行加權計算,得到所述平臺外數據資源集合對應的第二數據資源確權值;
12、對所述第一數據資源確權值及第二數據資源確權值進行拼接,得到數據資源確權值矩陣;
13、對所述候選數據資源集合及數據資源確權值矩陣進行加權計算,得到聯盟加權數據資源集合,并根據所述群體偏好集合,對所述聯盟加權數據資源集合中各個數據資源進行對應偏好標簽的加權計算,得到聯盟偏好加權數據資源集合;
14、根據預設的業務活動需求,對所述聯盟偏好加權數據資源集合進行數據篩選,得到業務可用數據,利用所述業務可用數據,構建所述目標云平臺中業務服務。
15、可選的,所述對所述用戶信息集合進行基于用戶行為的特征提取操作,得到用戶行為信息特征序列集合,包括:
16、利用預構建的結巴分詞工具對所述用戶信息集合進行分詞處理,得到分詞詞語集合,并對所述分詞詞語集合進行停用詞刪除操作,得到簡潔分詞集合;
17、利用預構建的word2vec模型,對所述簡潔分詞集合進行基于分詞順序的詞量化操作,得到分詞向量集合;
18、對所述分詞向量集合進行特征識別操作,得到用戶特征序列集合;
19、對所述用戶特征序列集合進行基于用戶行為的特征分類操作,得到用戶行為信息特征序列集合。
20、可選的,所述對所述用戶行為信息特征序列集合進行基于偏好類別的聚類操作,得到各個用戶聚類簇,識別所述用戶聚類簇的用戶比例及偏好類型,得到群體偏好集合,包括:
21、對所述用戶行為信息特征序列集合進行預設特征工程維度的空間映射操作,得到用戶行為特征點集合;
22、對所述用戶行為特征點集合進行自適應k值的k-means聚類操作,得到k個用戶聚類簇;
23、獲取各個用戶聚類簇的用戶比例,根據所述用戶比例,對各個用戶聚類簇進行排列,并篩選用戶比例最大的n個用戶聚類簇對應的偏好類型,得到群體偏好集合。
24、可選的,所述判斷所述候選數據資源集合中的各個候選數據資源是否具有所述用戶集群的內部評分,包括:
25、獲取各個候選數據資源的評分對應的評分用戶id,并根據預構建的實名制關聯關系,利用各個評分用戶id,構建用戶馬甲畫像;
26、判斷各個用戶馬甲畫像中是否存在屬于所述目標云平臺的注冊用戶的評分用戶id;
27、當所述用戶馬甲畫像中存在屬于所述注冊用戶的評分用戶id,則判定所述用戶馬甲畫像中的各個評分用戶id均屬于平臺內用戶;
28、當所述用戶馬甲畫像中不存在屬于所述注冊用戶的評分用戶id,則判定所述用戶馬甲畫像中的各個評分用戶id均不屬于平臺內用戶;
29、根據各個評分對應的評分用戶id是否均屬于所述平臺內用戶,判斷所述候選數據資源是否具有所述用戶集群的內部評分;
30、當所述候選數據資源中存在評分的評分用戶id是屬于所述平臺內用戶時,判定所述候選數據資源具有所述用戶集群的內部評分;
31、當所述候選數據資源中不存在評分的評分用戶id是屬于所述平臺內用戶時,判定所述候選數據資源不具有所述用戶集群的內部評分。
32、可選的,所述平臺內目標評分類型均值及平臺外目標評分類型均值,分別表示為:
33、
34、
35、式中,表示平臺內目標評分類型均值,表示平臺外目標評分類型均值,表示平臺內評分集合中評分的個數,表示平臺外評分集合中評分的個數,表示平臺內評分集合中的第個評分,,表示平臺外評分集合中的第個評分,,表示所述評分類型中的一個,,其中,分別代表{準確性、完整性、及時性及易用性的}。
36、可選的,所述第一數據資源確權值,表示為
37、
38、式中,表示第一數據資源確權值,表示所述平臺內目標評分類型均值的調節因子,被設置為,表示所述平臺內目標評分類型均值的影響默認大于平臺外目標評分類型均值的影響。
39、可選的,所述對所述平臺外數據資源集合進行基于平臺外用戶與平臺內用戶相似性的分類,得到外相似評分數據資源集合及外無關評分數據資源集合,包括:
40、根據皮爾遜相關系數,計算所述平臺外數據資源集合中各評分對應的平臺外用戶與所述平臺內數據資源集合中各評論對應的平臺內用戶之間的相似度:
41、
42、式中,表示相似度,表示所述平臺內用戶,表示平臺外用戶,n1表示平臺內數據資源集合,n2表示平臺外數據資源集合,表示所述平臺內數據資源集合及平臺外數據資源集合的公有數據資源的交集數據量,表示所述平臺內數據資源集合及平臺外數據資源集合的并集數據量,表示所述平臺內用戶及平臺外用戶均進行評分的候選數據資源,表示平臺內用戶對候選數據資源的評分,表示平臺外用戶對候選數據資源的評分,表示平臺內用戶對候選數據資源的全部評分的均值,表示平臺外用戶對候選數據資源的全部評分的均值;
43、判斷各個平臺外用戶的相似度是否大于預設的相似閾值;
44、判定相似度大于所述相似閾值的平臺外用戶作為平臺外相似用戶,得到所述平臺外相似用戶對應的外相似評分數據資源集合;
45、判定相似度小于或等于所述相似閾值的平臺外用戶作為平臺外無關用戶,得到所述平臺外無關用戶對應的外無關評分數據資源集合。
46、可選的,所述第二數據資源確權值,表示為:
47、
48、式中,表示第二數據資源確權值,表示所述外相似目標評分類型均值的調節因子,被設置為,表示所述外相似目標評分類型均值的影響默認大于外無關目標評分類型均值的影響。
49、可選的,所述數據資源確權值矩陣,表示為:
50、
51、式中,表示數據資源確權值矩陣,表示第個候選數據資源的第個評分類型的權重值,,表示候選數據資源集合中數據總量,。
52、為實現上述目的,本發明還提供一種大數據聯盟算法的云平臺搭建系統,包括:
53、群體偏好采集模塊,用于獲取目標云平臺中用戶集群的用戶信息,得到用戶信息集合,對所述用戶信息集合進行基于用戶行為的特征提取操作,得到用戶行為信息特征序列集合,并對所述用戶行為信息特征序列集合進行基于偏好類別的聚類操作,得到各個用戶聚類簇,識別所述用戶聚類簇的用戶比例及偏好類型,得到群體偏好集合;
54、聯盟大數據采集模塊,用于從預構建的聯盟數據庫中提取基于所述群體偏好集合的數據資源,得到候選數據資源集合,及判斷所述候選數據資源集合中的各個候選數據資源是否具有所述用戶集群的內部評分,其中,所述內部評分為包括準確性、完整性、及時性及易用性的各個評分類型的分數集合,及將所述候選數據資源集合中具有所述內部評分的候選數據資源判定為平臺內數據資源集合,及將不具有所述內部評分的候選數據資源判定為平臺外數據資源集合;
55、平臺內數據資源確權模塊,用于識別所述平臺內數據資源集合中的目標數據資源的目標評分類型對應的平臺內評分集合及平臺外評分集合,并計算所述平臺內評分集合的均值,得到平臺內目標評分類型均值,及計算所述平臺外評分集合的均值,得到平臺外目標評分類型均值,及對所述平臺內目標評分類型均值及平臺外目標評分類型均值進行加權計算,得到所述平臺內數據資源集合對應的第一數據資源確權值;
56、平臺外數據資源確權模塊,用于對所述平臺外數據資源集合進行基于平臺外用戶與平臺內用戶相似性的分類,得到外相似評分數據資源集合及外無關評分數據資源集合,及根據所述外相似評分數據資源集合及外無關評分數據資源集合,計算得到外相似目標評分類型均值及外無關目標評分類型均值,及對所述外相似目標評分類型均值及外無關目標評分類型均值進行加權計算,得到所述平臺外數據資源集合對應的第二數據資源確權值;
57、聯盟偏好加權模塊,用于對所述第一數據資源確權值及第二數據資源確權值進行拼接,得到數據資源確權值矩陣,及對所述候選數據資源集合及數據資源確權值矩陣進行加權計算,得到聯盟加權數據資源集合,并根據所述群體偏好集合,對所述聯盟加權數據資源集合中各個數據資源進行對應偏好標簽的加權計算,得到聯盟偏好加權數據資源集合;
58、服務搭建模塊,用于根據預設的業務活動需求,對所述聯盟偏好加權數據資源集合進行數據篩選,得到業務可用數據,利用所述業務可用數據,構建所述目標云平臺中業務服務。
59、為了解決上述問題,本發明還提供一種電子設備,所述電子設備包括:
60、存儲器,存儲至少一個指令;及
61、處理器,執行所述存儲器中存儲的指令以實現上述所述的大數據聯盟算法的云平臺搭建方法。
62、為了解決上述問題,本發明還提供一種計算機可讀存儲介質,所述計算機可讀存儲介質中存儲有至少一個指令,所述至少一個指令被電子設備中的處理器執行以實現上述所述的大數據聯盟算法的云平臺搭建方法。
63、本發明為解決背景技術所述問題,本發明首先采集本云平臺內用戶的群體偏好,從而對于云平臺業務擴展、活動舉辦或者界面推送提供方向;然后本發明通過聯盟算法實現海量數據的采集,有利于提高數據資源推送水平;本發明通過群體偏好對聯盟數據庫進行一次篩選,得到候選數據資源集合,所述候選數據資源集合可以用于作為云平臺業務展開的底層數據;其中,所述候選數據資源集合中含有云平臺用戶評分的數據,也有未經云平臺用戶評分的數據;本發明對于含有平臺內用戶的評分的候選數據資源,通過評分就可以對數據資源的選擇產生決定性作用;而對于僅僅有平臺外用戶的評分的候選數據資源,考慮到平臺外用戶中與平臺內用戶相似的平臺外相似用戶,平臺外相似用戶的評分對推薦結果的影響程度會比平臺外無關用戶的影響高,因此將平臺外數據資源集合的外相似評分數據資源集合作為云平臺運維的重要參考;本發明計算平臺內數據資源集合對應的第一數據資源確權值,及平臺外數據資源集合對應的第二數據資源確權值,再根據包含用戶比例及偏好類型的群體偏好集合進行綜合加權,得到考慮了聯盟數據資源的質量與本平臺用戶的偏好的聯盟偏好加權數據資源集合;云平臺可以根據所述聯盟偏好加權數據資源集合實現業務開發及活動運維。因此,本發明可解決采集用戶數據時數據來源單一性、質量較差問題。
- 還沒有人留言評論。精彩留言會獲得點贊!