用于GPGPU系統的線程資源調度方法、設備及介質與流程
本技術涉及計算機,尤其涉及一種用于通用圖形處理器(general-purpose?computing?on?graphics?processing?units,gpgpu)系統的線程資源調度方法、設備及介質。
背景技術:
1、在當今復雜多變的實際計算場景中,任務要求往往既復雜又多樣,同時伴隨著高昂的部署和試錯成本。這些挑戰促使了模擬建模技術的廣泛應用,尤其是在那些對精度、效率和成本均有嚴格要求的領域。
2、在空間3d建模等高度并行的模擬建模任務中,傳統的中央處理器(centralprocessing?unit,cpu)計算已難以滿足其巨大的數據處理需求。因此,gpgpu憑借其強大的并行處理能力成為了這類任務的首選平臺。
3、然而,要充分發揮gpgpu執行上述任務的性能優勢,必須解決計算資源的高效利用問題。在gpgpu中,計算單元(compute?unit,cu)、流多處理器(stream?multiprocessor,sm)的利用率直接決定了整體性能。合理的線程塊及線程調度策略是優化利用率的關鍵,現有的調度方法往往依賴于人工經驗和反復試驗。
4、但復雜的應用程序、多樣化的數據集以及不同的數據流模式給調度設計帶來了巨大挑戰。此外,不同型號的gpgpu具有不同的硬件特性和優化空間,這進一步增加了為特定應用找到最佳執行配置的難度。這造成現有調度方法效率低下且成本高昂,無法兼顧gpgpu性能及投入成本的平衡,影響任務處理進度,給用戶帶來不佳的使用體驗。
技術實現思路
1、為解決上述問題,本技術實施例提供了一種用于gpgpu系統的線程資源調度方法、設備及介質。
2、一方面,本技術實施例提供了一種用于gpgpu系統的線程資源調度方法,該方法包括:
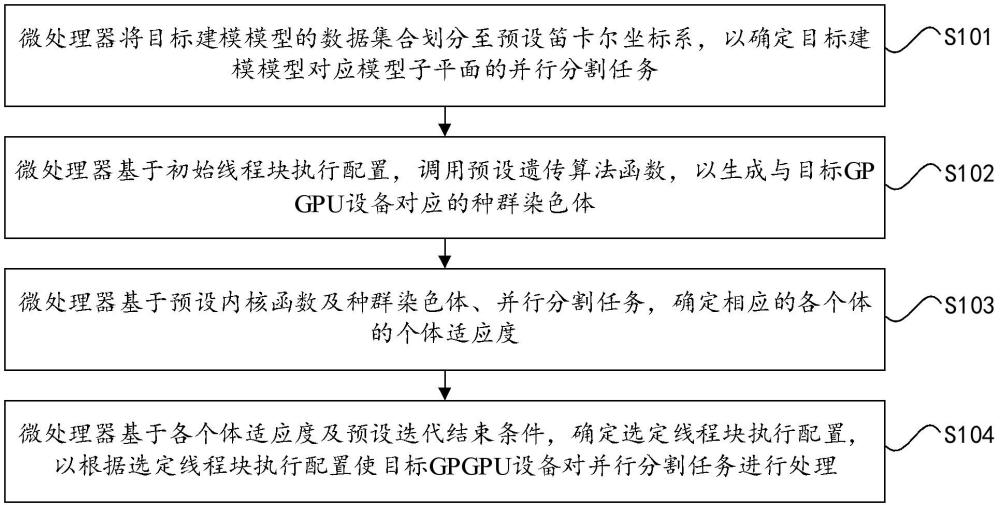
3、將目標建模模型的數據集合劃分至預設笛卡爾坐標系,以確定所述目標建模模型對應模型子平面的并行分割任務;所述模型子平面包括處于同一選定平面中的所述數據集合對應數據點;
4、基于初始線程塊執行配置,調用預設遺傳算法函數,以生成與目標gpgpu設備對應的種群染色體;其中,所述預設遺傳算法函數中所述目標gpgpu設備中每個內核的線程塊執行配置分別為一個染色體;一個所述目標gpgpu設備對應的各所述染色體組成種群染色體;
5、基于預設內核函數及所述種群染色體、所述并行分割任務,確定相應的各個體的個體適應度;
6、基于各所述個體適應度及預設迭代結束條件,確定選定線程塊執行配置,以根據所述選定線程塊執行配置使所述目標gpgpu設備對所述并行分割任務進行處理。
7、在本技術的一種實現方式中,基于初始線程塊執行配置,調用預設遺傳算法函數,以生成與目標gpgpu設備對應的種群染色體,具體包括:
8、在接收到來自用戶終端的所述初始線程塊執行配置之后,根據所述初始線程塊執行配置對所述目標gpgpu設備進行配置;其中,所述初始線程塊執行配置包括線程塊在各維度對應的線程塊數量、線程塊中線程在各維度對應的線程數量;
9、調用所述預設遺傳算法函數,以將所述目標gpgpu設備內各內核對應的線程塊執行配置作為所述種群染色體。
10、在本技術的一種實現方式中,基于預設內核函數及所述種群染色體、所述并行分割任務,確定相應的各個體的個體適應度,具體包括:
11、根據所述種群染色體,將所述并行分割任務分配至所述目標gpgpu設備,以執行所述預設內核函數,得到任務執行結果;
12、基于所述任務執行結果,確定各所述內核對應的內核功耗延遲積;
13、根據所述內核功耗延遲積,確定相應的所述個體的所述個體適應度;所述內核功耗延遲積與所述個體適應度為反比例關系。
14、在本技術的一種實現方式中,基于所述任務執行結果,確定各所述內核對應的內核功耗延遲積,具體包括:
15、根據所述任務執行結果,確定所述目標gpgpu設備對應的靜態功耗值、資源利用率、利用率功耗相關系數、資源峰值功耗值、模型功耗影響系數、預設復雜度函數;
16、將所述利用率功耗相關系數作為指數、所述資源利用率及相應的預設資源最大利用率的比值作為底數,并與所述資源峰值功耗值計算乘積值,確定第一計算值;
17、將所述模型功耗影響系數與所述預設復雜度函數進行乘積運算,并將乘積運算結果加1,得到第二計算值;
18、將所述第一計算值與所述第二計算值的乘積值,作為第三計算值;
19、將所述第三計算值與所述靜態功耗值的和值,作為任務執行功耗,以基于所述任務執行功耗,確定各所述內核對應的所述內核功耗延遲積。
20、在本技術的一種實現方式中,基于所述任務執行結果,確定各所述內核對應的內核功耗延遲積,具體包括:
21、根據所述任務執行結果,確定任務執行的各階段工作量值、階段處理能力、階段并行度、階段依賴延遲、依賴關系影響系數;其中,所述階段依賴延遲為一個任務執行階段與相應的依賴階段集合中各依賴階段之間的執行延遲;
22、將所述階段處理能力與相應的所述階段并行度的乘積值作為分母,將所述階段工作量值作為分子,確定第四計算值;
23、將所述階段依賴延遲與相應的所述依賴關系影響系數的乘積值,作為第五計算值;
24、分別確定各所述任務執行階段對應的所述第四計算值與所述第五計算值的和值,為第六計算值;
25、將各所述第六計算值中的最大值,作為任務執行延遲,以根據所述任務執行功耗及所述任務執行延遲的乘積值,確定所述內核功耗延遲積。
26、在本技術的一種實現方式中,在基于各所述個體適應度及預設迭代結束條件,確定選定線程塊執行配置之前,所述方法還包括:
27、在遺傳計算器的累加數小于最大迭代次數的情況下,確定不滿足所述預設迭代結束條件;
28、根據所述預設遺傳算法函數,將所述種群染色體隨機劃分為兩組染色體組,并根據所述個體適應度,分別確定所述兩組染色體組中最大個體適應度對應的個體,并作為父代;
29、對所述父代對應的染色體進行交叉處理,以生成子代個體對應的種群染色體,并將所述遺傳計算器的累加數加1;
30、根據所述子代個體對應的種群染色體確定相應的所述個體適應度。
31、在本技術的一種實現方式中,在對所述父代對應的染色體進行交叉處理之前,所述方法還包括:
32、根據所述交叉處理對應的個體占用字節及種群規模值,確定所述交叉處理對應的交叉操作需求內存;
33、將所述交叉操作需求內存與預設可用內存比較;
34、在所述交叉操作需求內存大于所述預設可用內存的情況下,根據預設交叉概率更新規則,將當前交叉概率更新,以根據更新后的交叉概率對所述父代對應的染色體進行交叉處理。
35、在本技術的一種實現方式中,在基于預設內核函數及所述種群染色體、所述并行分割任務,確定相應的各個體的個體適應度之前,所述方法還包括:
36、確定所述種群染色體對應的種群個體數量;
37、在所述種群個體數量小于預設隨機生成閾值的情況下,根據預設隨機算子,生成補充線程塊執行配置,并作為新個體添加至所述種群染色體,直至相應的所述種群個體數量大于或等于所述預設隨機生成閾值;所述預設隨機生成閾值用于判斷所述種群染色體是否需要補充新個體;
38、否則,基于所述預設內核函數及所述種群染色體、所述并行分割任務,確定相應的各個體的個體適應度。
39、另一方面,本技術實施例還提供了一種用于gpgpu系統的線程資源調度設備,所述設備包括:
40、至少一個處理器;以及,與所述至少一個處理器通信連接的存儲器;其中,所述存儲器存儲有可被所述至少一個處理器執行的指令,所述指令被所述至少一個處理器執行,以使所述至少一個處理器能夠執行如上述所述的用于gpgpu系統的線程資源調度方法。
41、再一方面,本技術實施例還提供了一種非易失性計算機存儲介質,存儲有計算機可執行指令,所述計算機可執行指令能夠執行如上述所述的用于gpgpu系統的線程資源調度方法。
42、本技術與現有技術相比,其顯著效果如下:
43、通過上述技術方案,可以利用遺傳算法進行自適應地生成gpgpu的執行配置,得到計算資源利用高的最優執行配置,從而靈活調度gpgpu計算資源,無需耗費人力進行gpgpu執行配置的設置。而且通過結合并行計算、遺傳算法優化和gpu加速技術,顯著提高了目標建模模型并行分割任務的處理效率和性能,同時保持了良好的靈活性和可擴展性。
- 還沒有人留言評論。精彩留言會獲得點贊!