一種基于深度學習的不完全多視圖聚類方法及系統
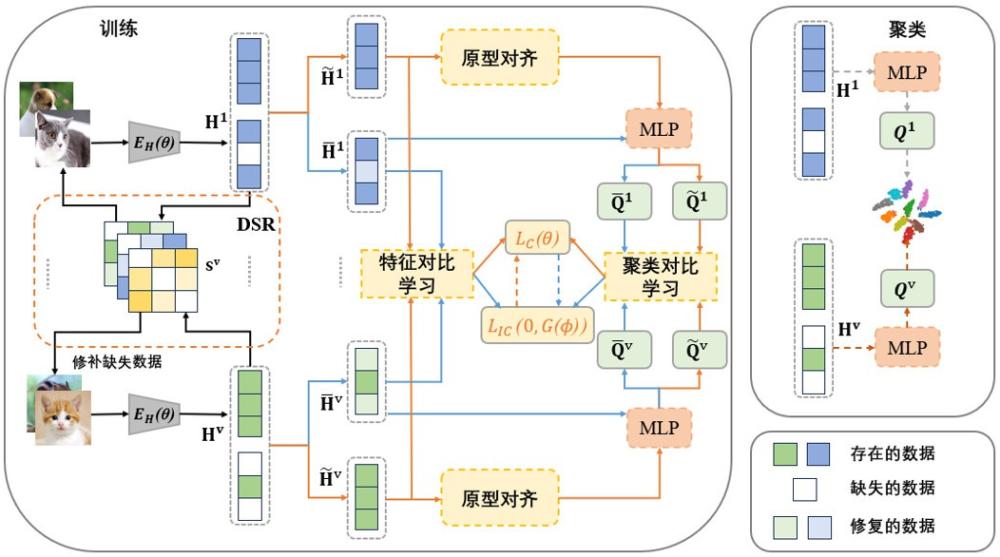
本發明涉及數據挖掘,尤其是涉及一種基于深度學習的不完全多視圖聚類方法及系統。
背景技術:
1、imvc?是不完全多視圖聚類(incomplete?multi-view?clustering)的縮寫。它是一種聚類方法,主要用于處理多視圖數據中存在數據缺失的情況。
2、當前的?imvc?方法在實際應用中面臨著一些挑戰。由于現實生活中收集到的數據往往存在缺失,這導致了不完全多視圖聚類問題的出現。當某些視圖缺失時,多個視圖之間相同實例的自然對齊屬性就會被破壞,從而影響對互補和一致信息的探索。此外,修復后的缺失數據如果與缺失數據的語義不一致,將會導致聚類性能下降。
3、現有的?imvc?主要包括基于?encoder?(編碼器)的方法、基于高斯的方法、基于gcns?(圖卷積神經網絡)的方法和基于對比的方法。基于?encoder?的方法通過從數據中提取特征表示,能夠獲得一致的特征表示來填補缺失數據,從而獲得良好的聚類性能。基于高斯的方法利用生成式對抗網絡對多視圖數據中的缺失部分進行挖掘和填充,通過生成器和鑒別器的相互競爭,不斷提高生成器的能力。基于?gcns?的方法通過學習多個視圖中的結構信息,探索多個視圖的共同表示。基于對比的方法通過比較多個視圖來完成缺失數據,并探索一致性的表示。
4、盡管這些方法取得了一定的進展,但許多?imvc?方法仍然側重于完整部分的學習,而忽略了缺失部分的低質量輸入對聚類的影響。因此,如何更好地處理缺失數據,提高聚類性能,仍然是?imvc?領域需要解決的重要問題。
技術實現思路
1、為了解決上述提到的問題,本發明提供一種基于深度學習的不完全多視圖聚類方法及系統。
2、第一方面,本發明提供的一種基于深度學習的不完全多視圖聚類方法,采用如下的技術方案:
3、一種基于深度學習的不完全多視圖聚類方法,包括:
4、s1.獲取跨視圖訓練集,包括完整數據集和不完整數據集;
5、s2.構建聚類模型,包括編碼器網絡和解碼器網絡;
6、s3.利用聚類模型對跨視圖訓練集進行特征提取和重構,并計算重構損失,對重構損失進行優化;
7、s4.基于重構損失,分別利用完整數據集和不完整數據集對聚類模型進行訓練;
8、s5.利用訓練好的聚類模型進行預測。
9、進一步地,所述利用聚類模型對跨視圖訓練集進行特征提取和重構包括:
10、a1.?將所述多視圖訓練集輸入編碼器網絡,得到多視圖訓練集高級語義特征;
11、a2.?將多視圖訓練集高級語義特征輸入解碼器網絡中對多視圖訓練集高級特征進行重構,并計算重構損失;
12、a3.?利用最優傳輸計算跨視圖對齊損失,對重構損失和跨視圖對齊損失進行優化。
13、進一步地,所述利用最優傳輸計算跨視圖對齊損失,包括:
14、b1.基于跨視圖訓練集獲取每個視圖對應的原型,計算所述視圖中每個特征到每個原型的距離得到總距離,使總距離最小化,確定特征空間中唯一原型集;
15、b2.利用最優輸運對原型集中每個視圖的原型進行對齊,使相同原型中的示例在不同視圖中表示一致,并計算對齊損失。
16、進一步地,所述利用最優輸運對原型集中每個視圖的原型進行對齊,包括:
17、b21.計算原型之間的相似關系,包括根據相似關系構建代價矩陣,計算視圖的每個原型與另一個視圖每個原型進行匹配的總代價;
18、b22.利用最優輸運得到總代價最小的代價矩陣下的匹配方案,利用所述匹配方案將不同視圖的原型進行對齊。
19、進一步地,所述基于重構損失,分別利用完整數據集和不完整數據集對聚類模型進行訓練,包括:
20、c1.通過平均運算修復不完整數據集得到修復的不完整數據集;
21、c2.分別選取完整數據集和不完整數據集構建原始數據空間,將原始數據空間投影到低維特征空間中,分別得到完整數據集高級語義特征和不完整數據集高級語義特征;
22、c3.分別對和采用譜對比學習,得到特征對比損失;通過多層感知機網絡對高級語義特征進行處理,根據軟聚類分配得到數據標簽對比損失,在標簽對比損失中加入正則化項,對正則化項進行聯合優化,計算正則化損失;
23、c4.構建并優化加權函數g,分別計算對于完整部分的損失和不完整部分的損失為,
24、其中,,表示參數,?是加權函數表示權重,是參數;
25、c5.將聚類模型訓練的損失反向傳播,優化損失函數,更新相似矩陣,得到新的修復數據,對聚類模型進行多次訓練,使損失函數收斂,完成聚類模型的訓練。
26、進一步地,所述通過平均運算修復不完整數據集得到修復的不完整數據集,包括:
27、c11計算同一視圖每次迭代的樣本之間的相似度矩陣,其中,t表示更新迭代的次數,表示視圖,i和j表示樣本;
28、c12.利用不同視圖的相似度矩陣識別當前缺失視圖的相似樣本,包括對第個視圖中的第個不完整樣本,在第t次迭代時,構建與所述第個不完整樣本相似的相似樣本集;
29、c13.通過對相似樣本集中的樣本進行平均運算,恢復第個缺失的樣本值。
30、進一步地,所述構建并優化加權函數g,包括:
31、c41.定義一個雙層優化,所述雙層優化包括上層和下層,所述雙層優化的損失函數表示為:
32、,其中表示使損失值最小化的參數集合,表示上層優化參數,表示下層優化參數,g是加權函數;
33、c42.下層對完整數據和修復的不完整數據進行特征學習和聚類分配學習,通過梯度下降優化確定使最小的參數;
34、c43.上層利用更新的最小參數優化加權函數中的,多次上層和下層的優化迭代,完成對加權函數的優化。
35、第二方面,一種基于深度學習的不完全多視圖聚類系統,包括:
36、數據獲取模塊,被配置為,獲取跨視圖訓練集,包括完整數據集和不完整數據集;
37、模型構建模塊,被配置為,構建聚類模型,包括編碼器網絡和解碼器網絡;
38、特征提取模塊,被配置為,利用聚類模型對跨視圖訓練集進行特征提取和重構,并計算重構損失,對重構損失進行優化;
39、模型訓練模塊,被配置為,基于重構損失,分別利用完整數據集和不完整數據集對聚類模型進行訓練;
40、模型預測模塊,被配置為,利用訓練好的聚類模型進行預測。
41、第三方面,本發明提供一種計算機可讀存儲介質,其中存儲有多條指令,所述指令適于由終端設備的處理器加載并執行所述的一種基于深度學習的不完全多視圖聚類方法。
42、第四方面,本發明提供一種終端設備,包括處理器和計算機可讀存儲介質,處理器用于實現各指令;計算機可讀存儲介質用于存儲多條指令,所述指令適于由處理器加載并執行所述的一種基于深度學習的不完全多視圖聚類方法。
43、綜上所述,本發明具有如下的有益技術效果:
44、1.本發明提出的高質量的一種基于深度學習的不完全多視圖聚類方法及系統,能夠獲得高質量的確實視圖修復數據,本發明通過跨視圖動態結構學習的缺失視圖修復策略,能夠更為精準地計算每個視圖內高語義特征之間的動態結構關系。這些修復后的數據具有更高的完整性和準確性,極大地減少了因數據缺失而可能導致的信息偏差。這為后續的聚類分析提供了極為可靠的基礎,使得聚類結果更加準確和有意義。
45、2.本發明提出的高質量的一種基于深度學習的不完全多視圖聚類方法及系統,包含原型、特征和聚類分配的三重交叉視圖對齊方法,是一種創新性的解決方案,能夠有效地應對從不同視圖獲得的位置偏差問題。通過設計的對齊機制,能夠確保原型、特征和聚類分配在不同視圖之間實現高度的一致性。這種一致性使得不同視圖之間的表示更加協調和統一,從而顯著提高了聚類的準確性和可靠性。
46、3.本發明提出的高質量的一種基于深度學習的不完全多視圖聚類方法及系統,充分利用不完整視圖數據提高聚類性能,通過交替迭代設計完整視圖特征和修復特征的雙優化過程,能夠充分挖掘不完整視圖數據中的潛在信息。這種方法能夠處理缺失數據,使得模型能夠更好地適應不完整數據的特性,從而有效地提高了聚類性能。
47、4.本發明提出的高質量的一種基于深度學習的不完全多視圖聚類方法及系統,提高模型的泛化能力,該方法在處理多視圖數據中的缺失情況時表現出色,能夠有效地提高模型對不同數據分布的適應性。通過學習和適應各種復雜的數據情況,模型能夠發展出更強的泛化能力,即在面對新的、未曾見過的數據時,也能夠做出準確的預測和分析。
- 還沒有人留言評論。精彩留言會獲得點贊!