一種基于人工智能的內容生成方法與流程
本發明涉及內容生成,尤其涉及一種基于人工智能的內容生成方法。
背景技術:
1、隨著互聯網的快速發展和信息化的普及,用戶對高質量內容的需求不斷增加。傳統的內容創作方式通常依賴人工編輯和創作,然而,這種方式不僅耗時耗力,而且創作質量受到編輯者個人能力和經驗的限制。此外,面對大規模的內容需求,傳統方法難以實現快速響應和高效產出。
2、人工智能技術,尤其是基于深度學習的自然語言處理(nlp)和生成對抗網絡(gan)等方法的發展,為內容自動生成提供了新的解決方案。通過訓練模型,使其具備理解和生成自然語言文本的能力,人工智能技術能夠在短時間內生成大量高質量的內容,包括但不限于新聞文章、產品描述、市場報告、社交媒體帖子等。
3、目前,已有多種基于人工智能的內容生成方法被提出和應用,例如,基于遞歸神經網絡(rnn)的文本生成方法、基于轉換器模型(transformer)的自然語言生成方法等。這些方法在一定程度上提高了文本生成的效率和質量,但仍存在一些問題和挑戰,無法有效的理解用戶對話的意圖和情感,對于多類型的對話無法有效識別,尤其對于圖像數據,缺乏有效的內容驗證機制和修正機制,內容生成過分依賴單一模型,容易因為模型的局部缺陷導致無法生成有效內容。
技術實現思路
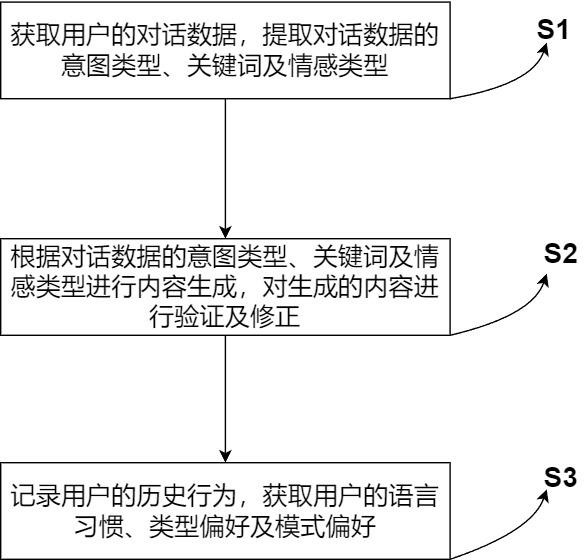
1、本發明提供一種基于人工智能的內容生成方法,包括:s1.獲取用戶的對話數據,包括文本、語音和圖像三種類型的數據,對每種類型的對話數據進行不同的處理,得到對話數據的意圖及情感類別;文本數據:對文本數據進行文法分析獲取意圖類別和關鍵詞,文法分析包括詞類分析、短語分析、句型分析和意圖分析;語音數據:使用語音識別技術將語音數據轉換為文本數據;圖像數據:將圖像數據送入圖像識別模型中進行內容識別,圖像識別模型由5個子單元構成,分別為第一區域劃分單元、第二名詞獲取單元、第三動詞獲取單元、第四形容詞獲取單元和第五文本生成單元,圖像數據經過內容識別后轉換為文本數據;對轉換的文本數據進行文法分析獲取意圖類別;對文本數據和轉換的文本數據進行文本情感分析,獲取對話數據的情感類別;s2.將用戶對話數據的文本數據、意圖類別和情感類別送入內容生成模型中進行內容生成,文本數據首先進入內容生成模型的通道選擇層,根據用戶對話數據的意圖類別、關鍵詞、情感類別、對話關聯性選擇內容生成模型的合適通道進行內容生成;內容生成模型有3條通道,分別為模版內容生成通道、規則內容生成通道和神經網絡內容生成通道;3條通道根據用戶對話數據的意圖類別和情感類別,分別進行模版匹配生成、規則匹配生成和神經網絡生成;模版匹配生成使用匹配模版替換變量后生成內容,規則匹配生成通過匹配的規則生成內容;神經網絡生成通過預訓練的神經網絡模型生成內容;進入內容生成模型的內容生成層,生成3條有差異的內容,將第一次生成的內容記為第一內容,獲取每條第一內容的意圖類別和情感類別,對第一內容進行主觀評估及客觀評估,得到第一內容的主觀評估分數及客觀評估分數,主觀評估分數基于生成內容與用戶對話的意圖類別及情感類別的匹配分數,客觀評估分數基于生成內容的邏輯性、準確性和可讀性評估分數;將主觀評估分數和客觀評估分數加權求和獲取第一內容綜合評估分數,選擇第一內容綜合評估分數最高的內容輸出,將第一內容保存在內容生成模型的內容修正層中;接收到后續的用戶對話后,再次對第一內容進行主觀評估和客觀評估,得到第一內容的修正評估分數,修正評估分數由修正主觀評估分數和修正客觀評估分數加權求和得到,修正主觀評估分數基于第一內容與后續用戶對話的意圖類別及情感類別的匹配分數,修正客觀評估分數基于第一內容與后續用戶對話連接段的邏輯性、準確性和可讀性評估分數,將第一內容的綜合評估分數和修正評估分數進行加權求和,得到修正選擇分數;若修正選擇分數與第一內容綜合評估分數對應的內容一致,則根據后續的用戶對話匹配內容生成通道進行內容生成,在連續的對話中,根據后續的用戶對話匹配內容生成通道進行內容生成得到的內容,稱為第二內容;否則,輸出意圖理解錯誤和修正分數最高的第一內容,并根據修正后的第一內容進行內容生成,在連續的對話中,根據修正后的第一內容進行內容生成得到的內容,稱為第二內容;s3.記錄每個用戶的歷史行為,獲取用戶的語言習慣、生成類型偏好、生成模式偏好。
2、作為本發明的一種優選技術方案,還包括對文本數據進行文法分析獲取意圖類別和關鍵詞;對文本進行預處理,包括文本清理、數據轉換、分節處理和分詞處理;文本清理,去除多余的空格及格式標記;數據轉換,將文本中摻雜的表情符號進行標記,并轉換為文字類型數據進行替換;分節處理,將每段話劃分為短語;分節處理,將短語劃分為詞;詞類分析,獲取每個詞的所有可能的詞類,記為獨立詞類,根據短語結構對獨立詞類進行篩選,得到每個短語的詞的所有可能的詞性組合,記為關聯詞類,根據句子結構對關聯詞類進行篩選,得到句子的每個詞的詞性,記為句的詞類,并添在每個對應的詞上進行標記;短語結構和句子結構均記錄在文法詞典中;短語分析,根據詞的詞性標記獲取短語的結構類型,根據結構類型和詞在文法詞典中匹配短語的關鍵詞;句型分析,根據句子的非短語部分在文法詞典中進行句型結構的匹配,得到句子的句型結構;意圖分析,根據短語的關鍵詞和句子的句型結構,通過文法詞典中的句法規則得出文本的意圖類別及關鍵詞。
3、作為本發明的一種優選技術方案,還包括情感分析;在文本數據中通過對情感相關詞的檢索,對檢索到的每種情感的情感相關詞進行分數疊加,每種情感的程度根據分數區間進行判定,情感相關詞的分數具體記錄在文法詞典中的情感詞區中,若一個文本數據的情感為輕度悲傷,中度憤怒,則記為ed={s1、f2}。
4、作為本發明的一種優選技術方案,還包括語音數據轉換和圖像數據轉換;語音數據通過預訓練的語音識別模型轉換為文本數據;圖像數據通過圖像識別模型中進行內容識別后轉換為文本數據,圖像識別模型由5個子單元構成,分別為第一區域劃分單元、第二名詞獲取單元、第三動詞獲取單元、第四形容詞獲取單元和第五文本生成單元;第一區域劃分單元,通過mask?r-cnn對圖片中的物體進行區域劃分,輸出物體的劃分掩碼,將掩碼傳遞至下一個子單元進行對象檢測;第二名詞獲取單元、第三動詞獲取單元和第四形容詞獲取單元通過一個卷積神經網絡構建,三個單元分別對應卷積神經網絡中不同隱藏層,第二名詞獲取單元為前三層的隱藏層,通過對劃分掩碼進行識別,得到對應的物體的識別結果,即物體名詞,第三動詞獲取單元為第五至七層的隱藏層,通過對第二名詞獲取單元的輸出進行識別,得到物體對應的動詞識別結果,第四形容詞獲取單元為第八至十層的隱藏層,通過對第三動詞獲取單元的輸出進行識別,得到物體的形容詞識別結果,模型的第四層隱藏層用于獲取不同區域的相鄰關系,三個單元的隱藏層間通過3個全連接層進行連接;最終輸出每個區域的對應的短語與區域的相鄰關系;第五文本生成單元通過文法規則,根據區域的相鄰關系和短語進行文本生成。
5、作為本發明的一種優選技術方案,內容生成模型包括通道選擇層,內容生成層和內容修正層;通道選擇層用于根據用戶對話數據的意圖類別、關鍵詞、情感類別、對話關聯性進行內容生成通道選擇,獲取用戶的意圖類別,若類別為特定領域,則選擇模版內容生成通道,計算用戶對話的復雜度,若復雜度為超出設定閾值且意圖類別不為特定領域,則選擇規則內容生成通道,若復雜度超過設定閾值則選擇神經網絡內容生成通道;復雜度的計算公式為:公式中為情感權重,用于平衡情感對復雜度的影響,為情感分數的合,輕度記為1,中度記為2,ht為意圖類別得分,為關鍵詞得分的合,意圖類別得分和關鍵詞得分在文法詞典中記錄,n為表示當前為連續的第n條對話,表示當前對話與前一條對話意圖類別的差異得分,為當前對話和前一條對話的關鍵詞的差異得分,差異得分通過矩陣中的距離差得到,若當前為第一條對話,則差異得分為0,通過該公式可根據對話數據本身的意圖類別和關鍵詞得出原始復雜度,并根據情感類別和對話間的關聯性進行復雜度的進一步評估;內容生成層用于根據用戶的意圖類別和情感類別進行內容生成,模版內容生成通道中通過設定的意圖類別對應的模版,根據關鍵詞和情感類別替換模版中的變量及取值范圍后生成對應的內容,規則內容生成通道中通過用戶的意圖類別和情感類別,在規則庫中匹配規則,按照規則邏輯生成對應的內容,神經網絡內容生成通道中通過將用戶的意圖類別和情感類別,及關鍵詞信息送入到預訓練的神經網絡內容生成模型中,生成復雜度較高的內容;內容修正層用于根據用戶的后續對話進行內容驗證及修正。
6、作為本發明的一種優選技術方案,還包括內容驗證及修正;內容驗證,對生成的內容進行文法分析和情感分析,得到各生成內容的內容類別,關鍵詞和情感類別,計算主觀評估得分,主觀評估得分的公式為:公式中為情感影響權重,表示每個用戶對話的情感類別得分,與生成內容的每個情感類別得分的差的總和,分別表示用戶對話文本與生成內容的意圖類別和關鍵詞的關聯得分,通過文法詞典中關聯向量獲取;通過該公式可以獲取主觀上的生成內容與用戶對話的關聯性;客觀評估得分計算,對生成內容進行邏輯性檢測,準確性檢測和可讀性檢測,得到客觀評估得分po,邏輯性檢測通過計算生成內容中相鄰句子的語義相似度,得到邏輯評分,準確性檢測通過計算生成內容中所有可驗證事實的準確率,得到準確評分,可讀性檢測通過smog可讀性公式計算生成內容的可讀評分;
7、綜合評估得分p=α1ps+α2po,選擇綜合評估得分最高的生成內容輸出,完成內容驗證;內容修正,獲取用戶的后續對話后,獲取后續對話的意圖類別、關鍵詞和情感類別,并計算修正評估得分,計算的公式為:,式中ks為修正評估的主觀評估部分,計算方法與ps一致,ko為修正評估的客觀評估部分,通過第一內容與用戶后續對話的連接段的邏輯性檢測,準確性檢測和可讀性檢測評分得到;計算修正選擇得分和綜合評估得分的合v=γ1p+γ2k,若v和p的值最高的為同一條內容,則繼續生成第二內容,若v和p的值最高的不為同一條內容,則輸出輸出意圖理解錯誤和v值最高的第一內容,并根據修正后的第一內容進行內容生成第二內容。
8、作為本發明的一種優選技術方案,還包括用戶行為分析;獲取用戶使用的歷史行為,為每個用戶建立使用偏好對象,偏好對象中包括用戶的語言習慣、類型偏好、模式偏好;檢測用戶的語言習慣,在生成內容時,優選選擇語言習慣對應的語言,檢測用戶的類型偏好,在生成內容時,若未檢測到用戶的內容類型需求,則生成類型偏好對應的內容類型,檢測用戶的模式偏好,在生成內容時,優選模式偏好對應的內容生成通道;語言習慣、類型偏好、模式偏好,通過需修改的記錄獲取,具體為3者各種類的初始權重一致,每產生一個歷史行為記錄,增加該種類的權重占比。
9、本發明具有以下優點:1、本發明通過對圖像數據進行區域劃分,名稱、動詞、形容詞分析后生成圖像數據對應的文本數據,并對文本數據進行詳細的文法分析,獲取文本的詞的正確詞類后,獲取文本的短語,提取短語的關鍵詞,并根據關鍵詞對文本進行意圖分析,獲取文本數據的意圖類別,通過詞典對文本數據進行情感分析,獲取文本數據的詳細情感類別,提高了在內容生成過程中,對用戶對話的理解能力。
10、2、本發明通過設置基于意圖和情感的上下文驗證及修正機制,并在驗證及修正機制中引入主觀及客觀劃分,在生成內容時,對生成的多條內容進行驗證,獲取最匹配意圖和情感的內容進行輸出,并基于后續的對話,對生成的內容進行再次驗證與選擇性修正,提高了內容生成過程中內容生成的準確性和內容的修正性能。
11、3、本發明通過設置多通道的內容生成模型,3個通道分別基于模版、規則和神經網絡,并計算復雜度以選擇合適的通道,通過這種多通道的方式,提高了資源利用能力,并防止了因為模型的局部缺陷而無法生成有效內容。
- 還沒有人留言評論。精彩留言會獲得點贊!