分布式存儲系統中的慢故障檢測方法、裝置、設備及介質
本發明涉及一種分布式存儲系統中的慢故障檢測方法、裝置、設備及介質,屬于分布式存儲故障檢測。
背景技術:
1、慢故障,也稱為灰色故障,受到越來越多的關注。在慢故障中,軟件或硬件組件(在運行時)提供的性能低于預期。隨著新型硬件設備和軟件棧的出現,慢故障(例如,由故障nand或調度問題引起)的影響更有可能被注意到,這些影響以前可能被掩蓋為噪聲。最近的研究表明,每年的慢故障事件的發生頻率可能與每年的故障停止事件一樣頻繁。
2、準確檢測故障緩慢故障具有挑戰性。由內部因素(例如ssd垃圾回收)或外部因素(例如工作負載突發)導致的性能變化可能具有與慢故障類似的癥狀。與標準(例如軟件崩潰、數據丟失)定義明確的故障停止故障不同,確定慢故障在實踐中通常是經驗性的,因此本質上是不準確的。此外,慢故障的故障通常是暫時的,這使得現場工程師很難識別,更不用說重現或推理根本原因了。
3、ceph分布式存儲系統中osd有慢io的檢測,主要通過跟蹤時延超過一定閾值,發出告警,然后提示研發人員介入定位,但因導致慢請求的原因涉及非常多,且對于慢故障這種原因類型來說,相對比較短期難以捕捉,出現問題后再去定位已經無法追蹤。基于節點的iaso檢測框架主要采用統計超時次數計算分數得到整體分數表排名,按排名得出服務退化的嚴重程度決策是否從集群中隔離出去。但當前框架無法直接應用到ceph且對無法推斷出驅動器的慢故障狀態,仍然需要人工介入定位具體的問題根因。
4、浪潮云的數據中心遍布全國,每個數據中心中有多個存儲集群,在每個集群之上,部署了一個分布式存儲系統ceph或其他系統以支持存儲服務。每個集群少則40個硬盤,多則近10000個硬盤。默認情況下,每個節點中的數據存儲驅動器一般都屬于同一型號。目前ceph系統針對故障硬盤具備檢測并隔離的能力,但出現慢故障時,只能告警出慢請求,且難以跟蹤到這類故障,且osd中的pg具有跨故障域全局分布的特性,影響范圍很大。因此,本發明提出了一種分布式存儲系統中的慢故障檢測方法。
技術實現思路
1、為了解決上述問題,本發明提出了一種分布式存儲系統中的慢故障檢測方法、裝置、設備及介質,能夠提高ceph系統的可用性。
2、本發明為解決其技術問題所采取的技術方案是:
3、第一方面,本發明實施例提供的一種分布式存儲系統中的慢故障檢測方法,包括如下步驟:
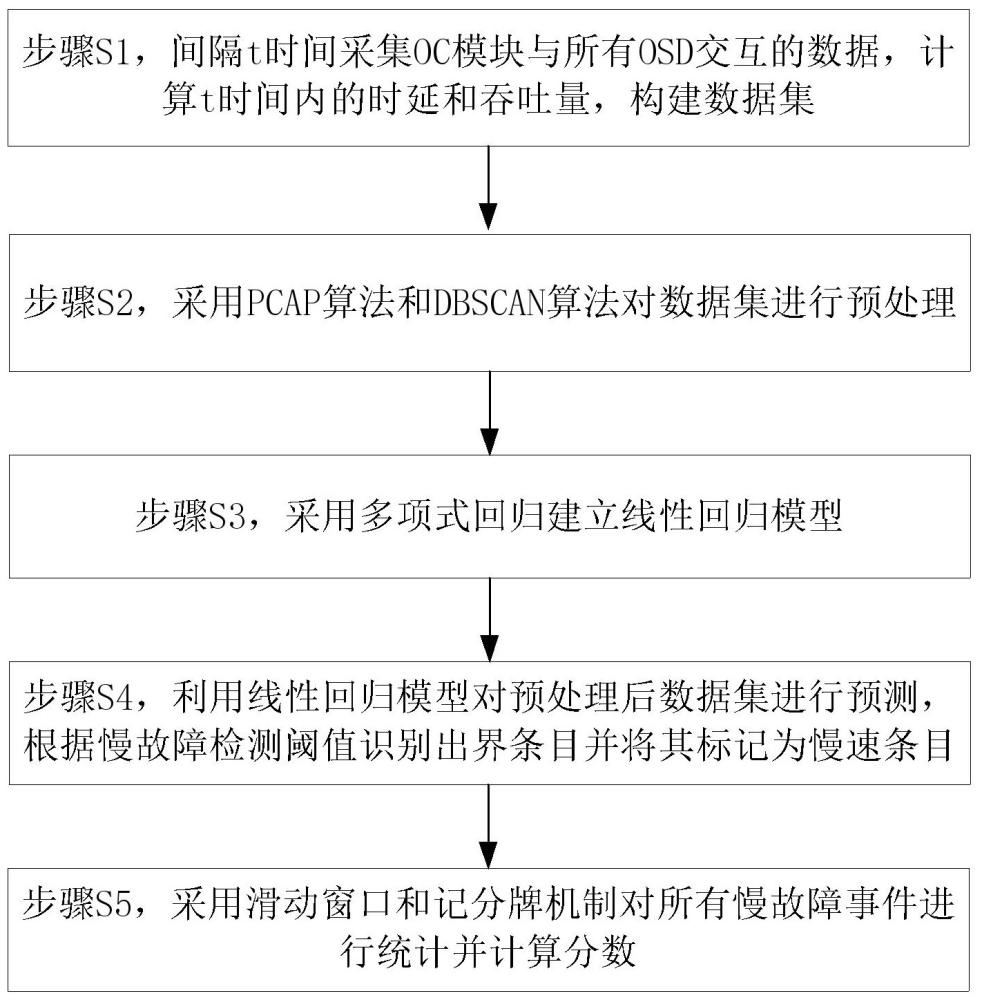
4、步驟s1,間隔t時間采集oc模塊與所有osd交互的數據,計算t時間內的時延和吞吐量,構建數據集;
5、步驟s2,采用pcap算法和dbscan算法對數據集進行預處理;
6、步驟s3,采用多項式回歸建立線性回歸模型;
7、步驟s4,利用線性回歸模型對預處理后數據集進行預測,根據慢故障檢測閾值識別出界條目并將其標記為慢速條目;
8、步驟s5,采用滑動窗口和記分牌機制對所有慢故障事件進行統計并計算分數。
9、作為本實施例一種可能的實現方式,在步驟s1中,采集的數據包括時間戳、主機、磁盤id、時延、吞吐量。
10、作為本實施例一種可能的實現方式,所述步驟s2,采用pcap算法和dbscan算法對數據集進行預處理,包括:
11、對數據集進行標準化處理;
12、采用dbscan算法識別數據集中異常值;
13、采用pcap算法丟棄數據集中異常值條目。
14、作為本實施例一種可能的實現方式,所述步驟s3,采用多項式回歸建立線性回歸模型,包括:
15、構建多項式特征并進行二項式特征轉換,建立時延和吞吐量之間的二項式關系;
16、對時延和吞吐量之間的二項式關系進行擬合,構建線性回歸模型,所述線性回歸模型輸出時延的預測結果。
17、作為本實施例一種可能的實現方式,所述步驟s4,利用線性回歸模型對預處理后數據集進行預測,根據慢故障檢測閾值識別出界條目并將其標記為慢故障條目,包括:
18、根據線性回歸模型構建出閾值:計算線性回歸模型的預測結果與實際值之間的殘差的標準差;利用統計學中的標準正態分布的特性,通過給定的置信水平確定了相應的z分位數,將標準差乘以z分位數,得到置信區間的上限,將置信區間的上限作為慢故障檢測閾值;
19、識別異常條目:對每個節點的進行預測后,定義滑動窗口,如果滑動窗口內預測值超過置信區間上限,則認為發生了慢故障事件。
20、作為本實施例一種可能的實現方式,所述步驟s5,采用滑動窗口和記分牌機制對所有慢故障事件進行統計并計算分數,包括:
21、判斷是否發生慢故障事件;
22、如果發生慢故障事件且上一時間段沒有慢故障事件,則分數score按因子下降,score初始值為10,如果score持續發生衰減且小于0,則置為0;
23、如果發生慢故障事件且上一時間段發生慢故障事件,則分數score按因子遞增,如果score超過閾值后,停止計算。
24、作為本實施例一種可能的實現方式,所述判斷是否發生慢故障事件,包括:
25、某一時間中內是否有故障慢事件的比率為:
26、,
27、其中,slowcount為慢故障條目數,totalcount為總條目數;
28、如果slowratio大于慢故障事件占比閾值,則認為發生了慢故障事件。
29、第二方面,本發明實施例提供的一種分布式存儲系統中的慢故障檢測裝置,包括:
30、數據集構建模塊,用于間隔t時間采集oc模塊與所有osd交互的數據,計算t時間內的時延和吞吐量,構建數據集;
31、數據集預處理模塊,用于采用pcap算法和dbscan算法對數據集進行預處理;
32、模型建立模塊,用于采用多項式回歸建立線性回歸模型;
33、慢故障檢測模塊,用于利用線性回歸模型對預處理后數據集進行預測,根據慢故障檢測閾值識別出界條目并將其標記為慢速條目;
34、慢故障統計模塊,用于采用滑動窗口和記分牌機制對所有慢故障事件進行統計并計算分數。
35、第三方面,本發明實施例提供的一種計算機設備,包括處理器、存儲器和總線,所述存儲器存儲有所述處理器可執行的機器可讀指令,當所述計算機設備運行時,所述處理器與所述存儲器之間通過總線通信,所述處理器執行所述機器可讀指令,以執行如上述任意分布式存儲系統中的慢故障檢測方法的步驟。
36、第四方面,本發明實施例提供的一種存儲介質,該存儲介質上存儲有計算機程序,該計算機程序被處理器運行時執行如上述任意分布式存儲系統中的慢故障檢測方法的步驟。
37、本發明實施例的技術方案所產生的有益效果如下:
38、本發明基于捕獲磁盤級時延和吞吐數據特征,利用機器學習技術建立回歸模型,并利用記分牌機制評估慢故障的嚴重程度,及時隔離出有問題的驅動器,提高了ceph系統的可用性。本發明引入了新基于節點級輕量化小型數據集回歸識別驅動器級的慢故障事件,提前發現該類問題,有效提升了系統的可用性和長尾問題。
39、本發明實施例的技術方案的一種分布式存儲系統中的慢故障檢測裝置,與本發明實施例的技術方案的一種分布式存儲系統中的慢故障檢測方法具有相同的有益效果。
- 還沒有人留言評論。精彩留言會獲得點贊!