基于YOLOv9和擴散模型的輸電線路異物檢測方法
本發明屬于圖像目標檢測,涉及一種基于yolov9和擴散模型的輸電線路異物檢測方法。
背景技術:
1、各種輸電線路遍布在居民區、鐵路網等地方,容易被氣球、風箏、鳥巢等異物附著,從而影響到輸電線路的電力傳輸。為了防止發生這些事故,及時發現輸電線路上的異物是重中之重。如果僅用傳統人工的方式來查看輸電線路是否存在異物將會是巨大的工程,隨著深度學習在計算機視覺中的目標檢測領域的發展,其分為了兩階段目標檢測方法和單階段目標檢測方法,均可部署到邊緣設備,通過目標檢測算法結合邊緣設備來識別復雜繁多的輸電線路上的異物會更加適合。
2、其中,兩階段目標檢測方法雖然精度更高,但是耗費算力更大,推理很慢,由于邊緣設備本身算力小,會導致推理速度以及精度都會急劇降低,若推理速度慢,就不能夠及時發現輸電線路的異物,若檢測精度低,會導致檢測的異物不準確,甚至無法檢測出異物,都會使得輸電線路安全性降低。而單階段目標檢測方法,如yolov9算法,由于其實時性以及端到端的特性,相對于兩階段目標檢測方法,推理速度快,算力要求更低。但使用yolov9算法部署到邊緣設備仍會有算力不足的問題,導致推理效果不好;并且輸電線路異物數據集收集繁瑣且數據量少,需要補充大量數據集來訓練模型。
3、由于輸電線路的異物本身出現的概率低、情況少,收集數據集時困難,會使得訓練數據集也較少,而yolo系列(包括yolov9)的模型都比較復雜,如果訓練數據集較少,會導致模型過擬合,所以需要數據增強來加強模型的訓練。但傳統的剪切、粘貼、mosaic等數據增強方法都會丟失圖像本身的真實性,使模型無法學習到真實特征;也有使用生成對抗網絡(gan)生成圖像進行數據增強的方式,但是生成對抗網絡(gan)由于其訓練模型時不穩定,生成的圖像容易良莠不齊,并且沒有多樣性。
4、而文生圖擴散模型由于其穩定、生成的圖像真實以及可根據文本標簽生成同類別的其他物體的特性,可用于作為數據增強的方法來提升模型的泛化能力以及精度。因此,如何設計一個輕量化的實時目標檢測網絡yolov9,并且利用文生圖擴散模型生成效果真實的圖像來增強數據,以實現在算力低的情況下還能夠達到輸電線路異物檢測的良好效果,這對輸電線路安全有重要意義。
5、由于實時檢測輸電線路異物的設備都為邊緣設備,由于邊緣設備本身算力低,而使用yolo系列(包括yolov9)算法需要兼顧推理速度、fps和精度的情況下仍需要足夠的算力,因此將部署到邊緣設備的模型進行輕量化改進是至關重要的。
技術實現思路
1、針對現有技術的不足,本發明提出了一種基于yolov9和擴散模型的輸電線路異物檢測方法。
2、本發明通過下述技術方案來實現。
3、基于yolov9和擴散模型的輸電線路異物檢測方法,包括以下步驟:
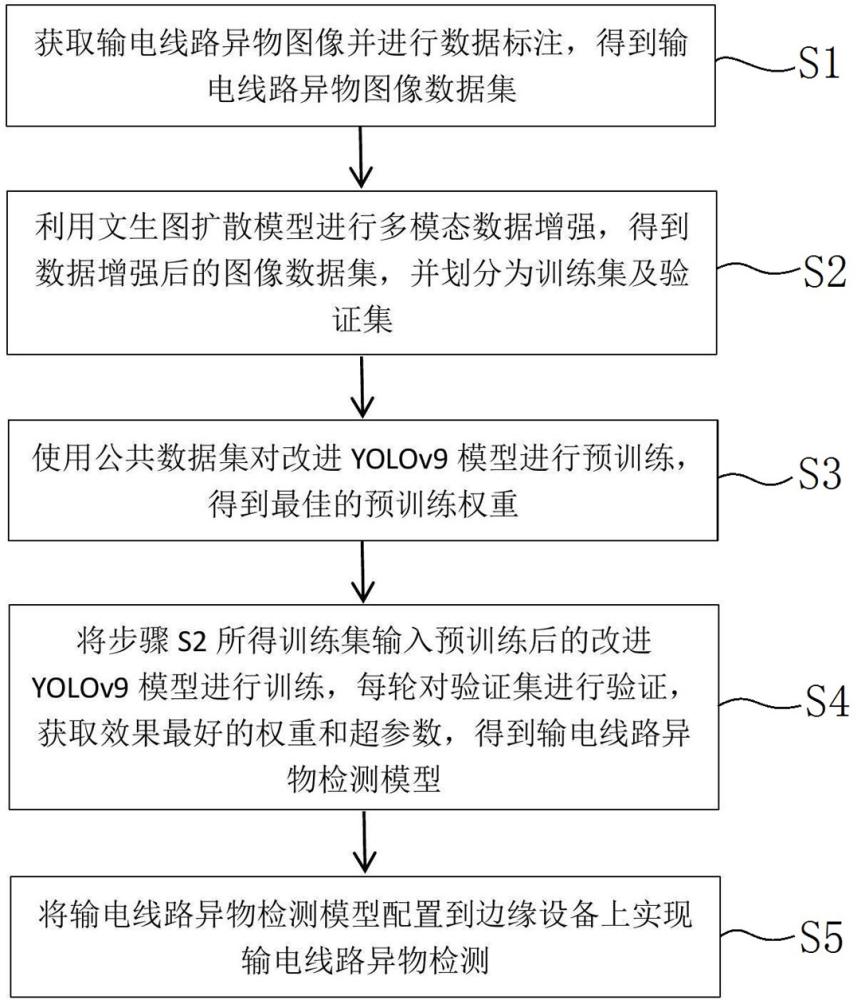
4、s1、獲取輸電線路異物圖像并進行數據標注,得到輸電線路異物圖像數據集;
5、s2、利用文生圖擴散模型進行多模態數據增強,得到數據增強后的圖像數據集,并劃分為訓練集及驗證集;
6、s3、使用公共數據集(coco2017)對改進yolov9模型進行預訓練,得到最佳的預訓練權重;
7、s4、將步驟s2所得訓練集輸入預訓練后的改進yolov9模型進行訓練,每輪對驗證集進行驗證,獲取效果最好的權重和超參數,得到輸電線路異物檢測模型;
8、s5、將輸電線路異物檢測模型配置到邊緣設備上實現輸電線路異物檢測;
9、其中,所述改進yolov9模型包括骨干網絡、頸部網絡和頭部網絡和可編程梯度信息模塊;骨干網絡、頸部網絡和頭部網絡依次連接構成主分支,可編程梯度信息模塊連接骨干網絡,可編程梯度信息模塊作為輔助分支,頸部網絡采用高層次篩選特征融合金字塔(hs-fpn);采用mobilenetv4-small網絡作為骨干網絡,骨干網絡包括依次設置的mnv4-1模塊、mnv4-2模塊、mnv4-3模塊、mnv4-4模塊和mnv4-5模塊,其中mnv4-1模塊包含一個卷積歸一化模塊(convbn),mnv4-2模塊由連續兩個卷積歸一化模塊串聯而成,mnv4-3模塊由一個第一通用倒置瓶頸塊(uib1)、三個第二通用倒置瓶頸塊(uib2)及另一個第一通用倒置瓶頸塊(uib1)串聯而成,mnv4-4模塊由連續兩個第一通用倒置瓶頸塊(uib1)及四個通用倒置瓶頸塊(uib2)串聯而成,mnv4-5模塊由兩個卷積歸一化模塊(convbn)串聯而成。
10、進一步優選,文生圖擴散模型包括語言模型、文本編碼器、圖像編碼器、圖文配對的多模態模型(clip)、變分自編碼器(vae)和u-net網絡,變分自編碼器(vae)包括編碼器和解碼器,通過語言模型、文本編碼器和圖像編碼器對輸電線路異物圖像數據集進行處理,得到對應的文本特征向量和圖像特征向量,用于訓練圖文配對的多模態模型,向訓練后的圖文配對的多模態模型輸入異物的文本描述及背景的文本描述,生成文本編碼向量;將隨機矩陣輸入變分自編碼器(vae)的編碼器中生成潛在空間低維矩陣,將潛在空間低維矩陣、文本編碼向量、自定義的異物位置信息、背景初始信息、噪點強度輸入u-net網絡中進行噪聲裁剪及合并操作,以及擴散加噪操作和反向擴散去噪操作,生成低維圖像矩陣,將低維圖像矩陣輸入變分自編碼器(vae)的解碼器之中進行解碼,生成重構圖像,重構圖像和原有的輸電線路異物圖像組成數據增強后的圖像數據集。
11、進一步優選,訓練圖文配對的多模態模型時,將文本特征向量及圖像特征向量構建為圖像-文本對,計算圖像-文本對的相似度對比損失,用于訓練圖文配對的多模態模型。
12、進一步優選,向訓練后的圖文配對的多模態模型輸入異物的文本描述及背景的文本描述所構成的文本信息t,通過圖文配對的多模態模型生成文本編碼向量zt={t1,?t2,…,tn,tbg?}?,其中,?t1,?t2,…,tn分別為第1,2,…,n條對異物的文本描述所對應的文本編碼向量,tbg為背景的文本編碼向量。
13、進一步優選,生成低維圖像矩陣的過程為:
14、步驟1:給定自定義的異物位置信息以及固定的背景初始信息,其中分別為第1,2,…,m個異物的位置信息,m≤n,即一個異物至少有一條文本描述;將異物位置信息以及固定的背景初始信息輸入u-net網絡中生成異物位置噪聲信息zlm={zl1,?zl2,…,zlm}以及背景噪聲信息zbg,其中zl1,?zl2,…,zlm分別為第1,2,…,m個異物位置噪聲信息;?然后在背景噪聲信息上進行異物位置噪聲信息的裁剪和合并操作,得到裁剪和合并之后的含有所有異物位置噪聲信息的噪聲?:
15、;
16、其中,為噪點強度;
17、步驟2:變分自編碼器(vae)的編碼器將輸入的隨機矩陣映射到潛在空間中得到潛在空間低維矩陣z,,其中為給定隨機矩陣時潛在空間低維矩陣??的條件概率分布,為編碼器生成的均值,為編碼器生成的標準差,為編碼器的參數;
18、步驟3:將文本編碼向量zt、含有所有異物位置噪聲信息的噪聲和潛在空間低維矩陣輸入u-net網絡,不斷執行擴散加噪過程和反向擴散去噪過程,生成低維圖像矩陣。
19、進一步優選,頸部網絡使用的高層次篩選特征融合金字塔(hs-fpn)和三個repncspelan4特征融合模塊,?高層次篩選特征融合金字塔包括三個坐標注意力機制模塊、兩個選擇性特征融合模塊,首先將mnv4-3模塊提取的8倍下采樣特征、mnv4-4模塊提取的16倍下采樣模塊及mnv4-5模塊提取的32倍下采樣模塊分別經過三個坐標注意力機制模塊消除冗余數據,壓縮特征,然后分別經過1×1卷積層改變通道數,分別得到低級特征、中級特征和高級特征;
20、高級特征通過其中一個repncspelan4特征融合模塊進行特征融合之后得到第一個輸出特征;
21、通過其中一個選擇性特征融合模塊將高級特征和中級特征融合,然后經過一個repncspelan4特征融合模塊進行特征融合之后得到第二個輸出特征;
22、通過另一個選擇性特征融合模塊將高級特征和低級特征融合,然后經過一個repncspelan4特征融合模塊進行特征融合之后得到第三個輸出特征。
23、進一步優選,對于mobilenetv4-small網絡的參數設計采用兩階段神經搜索架構(tu-nas),分別確定最佳卷積核尺寸和通用倒置瓶頸塊(uib)配置。
24、進一步優選,對卷積歸一化模塊進一步改進,改進后的卷積歸一化模塊包括普通卷積和深度可分離卷積,首先通過普通卷積提取到圖像的特征,然后使用深度可分離卷積進行空間特征的再次提取,然后將提取到的特征通道進行拆分成兩部分,一部分不變,另一部分進行點卷積操作,點卷積將通道特征進行融合,然后經過星形運算進行逐元素相乘操作,將兩個分支的特征進一步融合,然后進行批歸一化,并使用h-swish激活函數。
25、進一步優選,將骨干網絡中提取出來的8倍、16倍以及32倍下采樣特征輸入可編程梯度信息模塊之中,可編程梯度信息模塊將得到的分類以及回歸的梯度信息補充到主分支之中。
26、進一步優選,頭部網絡使用聚焦損失函數(focaler-iou),并引入調節因子d和u:
27、;
28、其中,為重構后的真實框和預測框的交并比,iou為交并比,d和u均為調節因子,調節因子取值范圍在(0,1)區間,聚焦損失函數(focaler-iou)的損失為。
29、本發明具有以下優點:
30、(1)本發明提出使用文生圖擴散模型進行多模態數據增強,因為文生圖擴散模型訓練十分穩定,生成的圖像普遍良好且真實,不會出現時好時壞的情況,并且可以基于輸入的文本生成所想要生成的圖像,大大增加圖像的多樣性。本發明的多模態數據增強可以生成真實的、布局符合邏輯的圖像,不會丟失其真實信息,并且生成過程穩定,圖像質量普遍良好,且可以通過輸入文本以及異物真實框位置信息來得到所想要生成的圖像,使得圖像更具有多樣性,且得到符合真實框位置信息的數據增強的圖像,不需要額外進行人工標注,利于訓練yolov9模型,并且提高其泛化能力。
31、(2)本發明采用mobilenetv4-small網絡作為骨干網絡,并利用兩階段的神經搜索架構(tu?nas)進行神經網絡架構搜索,得到符合算力較低的邊緣設備的帕累托最優的網絡結構,可以最大程度的利用好該邊緣設備的算力。改進卷積歸一化模塊,使用h-swish激活函數更好地緩解梯度消失,提高一定的泛化能力。
32、(3)頸部網絡使用更輕量的高層次篩選特征融合金字塔(hs-fpn)來融合特征,并且保留不基于錨框的方式,將分類和回歸進行解耦,可以有效減少錨框的冗余,可以提高模型的推理效率。邊界框回歸損失函數使用聚焦損失函數(focaler-iou)進行改進,計算損失時更加簡便,并且引入調節因子,降低檢測正確的樣本以后的損失貢獻,增加對困難樣本損失貢獻,提高輕量網絡的利用率。
33、(4)頭部網絡不使用非極大值抑制(nms),即使用nms-free模塊,在訓練時采用一個真實框分配多個預測框分支(one-many一對多分支)與一個真實框分配一個預測框分支(one-one一對一分支)并行的方式豐富信息,采用統一的匹配度量,并且利用可編程梯度信息進一步對nms-free模塊進行優化,而推理時拋棄一對多分支,采用一對一分支,能夠在不丟失過多信息的情況下,加快推理速度。提高了端到端部署能力以及推理速度和每秒處理幀數(fps)。
- 還沒有人留言評論。精彩留言會獲得點贊!