一種智能模擬面試的處理方法、裝置及電子設備與流程
本技術涉及數據處理,具體涉及一種智能模擬面試的處理方法、裝置及電子設備。
背景技術:
1、隨著科技的發展和市場的不斷變化,企業對求職者的要求也在不斷提高,尤其是對于初涉職場的大學生群體而言,普遍面臨實戰經驗匱乏,特別是面試環節上顯得尤為不足。智能模擬面試技術應運而生,作為一種創新的教育與培訓手段,以深入了解市場動態即企業特定的招牌偏好與用人標準。鑒于智能模擬面試系統廣泛覆蓋了跨行業、多崗位的面試題庫,學生得以借此機會深入檢索不同企業以職位的具體要求,進而精確定位個人職業規劃方向。
2、在準備參與智能模擬面試的過程中,學生往往會基于目標崗位特性,預先搜集并整理出潛在的面試問題集。然而,面對這些問題,學生可能因缺乏實戰經驗而感到困惑,難以構思出即貼合崗位需求又展現個人優勢的答案。現有的智能平臺允許學生輸入具體的面試問題,并根據問題自動生成對應的面試回答,但當前生成的回答內容比較簡單模糊,無法給出詳細且具體的回復,導致不符合學生回答面試問題的需求。
3、因此,亟需可解決上述技術問題的一種智能模擬面試的處理方法、裝置及電子設備。
技術實現思路
1、本技術提供了一種智能模擬面試的處理方法、裝置及電子設備,該方法根據第一用戶發送的第一面試問題,進而從預設數據庫中搜索出多個預存方案,對預存方案進行篩選、拆分以及替換處理,使得輸出的面試答案能夠更符合學生的回答面試問題的需求,還可提高答復的效率。
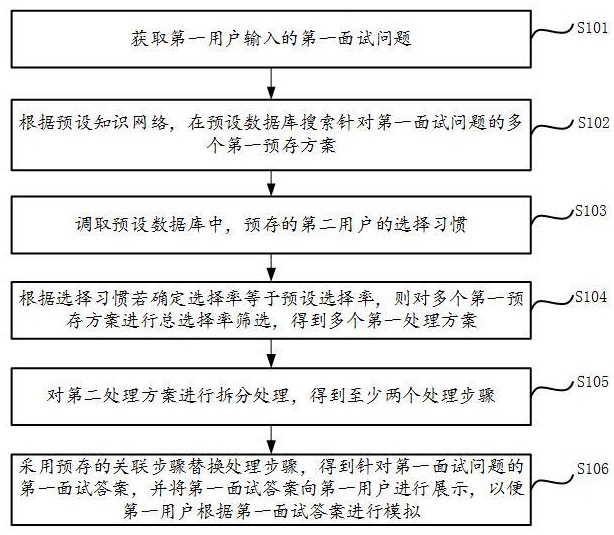
2、第一方面,本技術提供了一種智能模擬面試的處理方法,方法包括:獲取第一用戶輸入的第一面試問題;根據預設知識網絡,在預設數據庫搜索針對第一面試問題的多個第一預存方案;調取預設數據庫中,預存的第二用戶的選擇習慣,選擇習慣包括第二用戶對預存方案的選擇率,選擇率為第二用戶選擇預存方案的次數與顯示的預存方案的數量之比;根據選擇習慣若確定選擇率低于預設選擇率,則對多個第一預存方案進行總選擇率篩選,得到多個第一處理方案,第一處理方案為多個第一預存方案中,總選擇率高于預設總選擇率的第一預存方案,總選擇率為對應第一預存方案的被選擇總數與被顯示總數之比;對第二處理方案進行拆分處理,得到至少兩個處理步驟,第二處理方案為多個第一處理方案中的任意一個第一處理方案;采用預存的關聯步驟替換處理步驟,得到針對第一面試問題的第一面試答案,并將第一面試答案向第一用戶進行展示,以便第一用戶根據第一面試答案進行模擬。
3、通過采用上述技術方案,在根據第一用戶的第一面試問題搜索出預設數據庫中的多個預存方案后,再進一步分析第二用戶的選擇習慣,根據第二用戶對預存方案的選擇率,判斷出第二用戶很少選擇預存方案從而采用預存方案,則直接對預存方案依次進行篩選、拆分以及替換處理,使最終得到的面試答案能夠更符合第一用戶的需求。從多個預存方案中篩選出總選擇率較高的預存方案,即篩選出其中在用戶群體中受歡迎的、點擊率較高的預存方案,從而避免推薦需對不受歡迎或不相關的內容,提高了答案的質量和相關性,接著對篩選得到的第一處理方案進行拆分成多個步驟,最后采用關聯步驟替換原來的處理步驟。由于預設數據庫根據第二用戶的選擇習慣對給出的答復進行多重加工,而不需要第一用戶一次次對答復進行調節限定,從而提高答復的效率。
4、可選的,在采用預存的關聯步驟替換處理步驟,得到針對第一面試問題的第一面試答案之前,方法還包括:根據預設知識網絡,確定第一處理步驟對應的第二面試問題,第一處理步驟為多個處理步驟中的任意一個處理步驟;根據預設知識網絡,在預設數據庫搜索針對第二面試問題的多個第二預存方案;對多個第二預存方案的總選擇率按照從大到小的順序進行排序,得到排序結果;從排序結果中獲取末位對應的目標選擇率,確定目標選擇率對應的第二面試答案;確定第二面試答案為第二處理步驟,第二處理步驟為多個關聯步驟中,第一處理步驟對應的關聯步驟。
5、通過采用上述技術方案,提高根據預設知識網絡確定第一處理步驟對應第二面試問題,然后搜索出第二面試問題的多個第二預存方案,因為均是針對同一問題的方案,從而使得找出的第二預存方案與第二處理方案的關聯度更高,還可再篩選出排序結果中末位對應的目標選擇率,以得到第二預測方案,并將第二預存方案進行拆分用于后續替換,從而能夠使回復的結果既與原始回復有較高關聯度,并且還是一些偏新穎的方案。
6、可選的,對第二處理方案進行拆分處理,得到至少兩個處理步驟,具體包括:對第二處理方案進行關鍵特征提取,得到多個名詞短語性關鍵特征和多個動詞性關鍵特征;對第二處理方案進行順序邏輯結構識別,確定第二處理方案中包含的多個順序邏輯連接詞,順序邏輯連接詞用于在面試答案中建立句與句或者段與段之間的順序邏輯關系;確定第一邏輯連接詞與第二邏輯連接詞之間的第一關鍵特征和第二關鍵特征,第一邏輯連接詞與第二邏輯連接詞為多個順序連接詞中,任意相鄰的兩個順序邏輯連接詞,第一關鍵特征為多個名詞性關鍵特征中的任意一個名詞性關鍵特征中,第二關鍵特征為多個動詞關鍵特征中的任意一個動詞性關鍵特性;對第一關鍵特征和第二關鍵特征進行組合,得到第一處理步驟。
7、通過采用上述技術方案,通過提取多個名詞短語性關鍵特征和多個動詞性關鍵特征,能夠捕捉面試答案中的重要概念和關鍵動作,有助于從大段文本中抽取關鍵信息,通過識別第二處理方案中包含的順序邏輯連接詞,確定了句與句或段與段之間的邏輯關系,這使得面試答案的結構更加清晰,進而更容易理解各個步驟之間的順序和關聯性,最后通過邏輯連接詞之間的關鍵特征的組合,實現了處理步驟的生成。
8、可選的,在采用預存的關聯步驟替換處理步驟,得到針對第一面試問題的第一面試答案之前,方法還包括:根據預設知識網絡,確定第一處理步驟對應的第二面試問題,第一處理步驟為多個處理步驟中的任意一個處理步驟;根據預設知識網絡,在預設數據庫搜索針對第二面試問題的多個第二預存方案;對第一處理步驟進行特征提取,得到多個第一特征,對目標預存方案進行特征提取,得到多個第二特征,目標預存方案為多個第二預存方案中的任意一個第二預存方案;
9、根據多個第一特征以及多個第二特征,計算第一處理步驟與目標預存方案的關聯度,具體計算公式如下:;其中d(x,y)為第一處理步驟x與目標預存方案y的關聯度,df(u)為第u個第一特征的特征頻率,df(v)為第v個第二特征的特征頻率,argmin(d(u,v)×puv)為流量分配矩陣,puv為第u個第一特征到第v個第二特征的流量分配,即將第u個第一特征移動到第v個第二特征所分配的流量數量,d(u,v)為第一特征的特征向量與第二特征的特征向量之間的距離;若確定關聯度大于或等于預設閾值,則確定目標預存方案為關聯步驟。
10、通過采用上述技術方案,通過在預設知識網絡中確定第一處理步驟對應的第二面試問題,保證了關聯步驟與原始處理步驟在知識領域上有相關性,確保替換后的方案更符合第一用戶的面試需求。通過計算關聯度的公式,綜合考慮了特征的頻率、流量分配和特征向量之間的距離,使關聯度計算更加全面和準確。若確定關聯度大于或等于預設閾值,則確定目標預存方案為關聯步驟。這種機制確保了替換方案的選擇更加可靠,僅在關聯性較高時才進行替換,避免無關或低關聯度的替換,從而提高了回復的準確性。
11、可選的,通過如下公式計算第一特征的特征頻率:;其中,df(u)為第u個第一特征的特征頻率,mu為包含第一特征的預存方案的數量,mu為預存方案的總數量;
12、通過如下公式計算第二特征的特征頻率:;其中,df(v)為第v個第二特征的特征頻率,mv為包含第二特征的預存方案的數量,mv為預存方案的總數量;通過如下公式計算第一特征的特征向量與第二特征的特征向量之間的距離:;其中,d(u,v)為第一特征的特征向量與第二特征的特征向量之間的距離,uk為第一特征在第k個維度的特征向量,vk為第二特征在第k個維度的特征向量。
13、可選的,在調取預設數據庫中,預存的第二用戶的選擇習慣之前,方法還包括:在第一用戶輸入面試問題后,記錄檢索出的針對面試問題的預存方案的第一數量;記錄第二用戶未經任何處理,選擇預存方案的第二數量;根據第二數量與第一數量的比值,得到選擇率。
14、通過采用上述技術方案,通過計算選擇率,能夠評估第一用戶對預存方案的關注程度。較高的選擇率表明第二用戶更可能對提供的方案感興趣,而較低的選擇率則可能表示第二用戶對方案的興趣較低。記錄第二用戶的選擇率有助于更智能地調整預存方案的權重。在后續的處理步驟中,可以根據選擇率高的方案更優先地推薦相關內容,從而提高第一用戶滿意度。
15、可選的,在預設數據庫搜索針對第一面試問題的多個第一預存方案,具體包括:確定第一面試問題與預設數據庫中多個預存面試問題的相似度;確定多個預存面試問題中,相似度大于或等于預設相似度閾值的預存面試問題;確定各個相似度大于或等于預設相似度閾值的預存面試問題對應的多個第一預存方案。
16、通過采用上述技術方案,通過計算第一面試問題與預存面試問題的相似度,能夠精準匹配與第一用戶提問相近的問題。這有助于提高所搜索到的預存方案與第一用戶實際問題的相關性。設置相似度閾值可以過濾掉相似度較低的預存面試問題,確保僅保留與第一用戶問題高度相關的問題。這樣可以有效降低噪音干擾,提高檢索結果的質量。確定相似度大于或等于預設相似度閾值的預存面試問題后,能夠獲取這些問題對應的多個第一預存方案,從而提供第一用戶多樣化的解決方案選擇,增加了答案的全面性。
17、在本技術的第二方面提供了一種智能模擬面試的處理裝置,裝置包括獲取單元、處理單元以及拆分單元;獲取單元,獲取第一用戶輸入的第一面試問題;處理單元,根據預設知識網絡,在預設數據庫搜索針對第一面試問題的多個第一預存方案;調取預設數據庫中,預存的第二用戶的選擇習慣,選擇習慣包括第二用戶對預存方案的選擇率,選擇率為第二用戶選擇預存方案的次數與顯示的預存方案的數量之比;根據選擇習慣若確定選擇率低于預設選擇率,則對多個第一預存方案進行總選擇率篩選,得到多個第一處理方案,第一處理方案為多個第一預存方案中,總選擇率高于預設總選擇率的第一預存方案,總選擇率為對應第一預存方案的被選擇總數與被顯示總數之比;拆分單元,對第二處理方案進行拆分處理,得到至少兩個處理步驟,第二處理方案為多個第一處理方案中的任意一個第一處理方案;采用預存的關聯步驟替換處理步驟,得到針對第一面試問題的第一面試答案,并將第一面試答案向第一用戶進行展示,以便第一用戶根據第一面試答案進行模擬。
18、可選的,處理單元用于根據預設知識網絡,確定第一處理步驟對應的第二面試問題,第一處理步驟為多個處理步驟中的任意一個處理步驟;根據預設知識網絡,在預設數據庫搜索針對第二面試問題的多個第二預存方案;對多個第二預存方案的總選擇率按照從大到小的順序進行排序,得到排序結果;獲取單元用于從排序結果中獲取末位對應的目標選擇率,確定目標選擇率對應的第二面試答案;處理單元用于確定第二面試答案為第二處理步驟,第二處理步驟為多個關聯步驟中,第一處理步驟對應的關聯步驟。
19、可選的,處理單元用于對第二處理方案進行關鍵特征提取,得到多個名詞短語性關鍵特征和多個動詞性關鍵特征;對第二處理方案進行順序邏輯結構識別,確定第二處理方案中包含的多個順序邏輯連接詞,順序邏輯連接詞用于在面試答案中建立句與句或者段與段之間的順序邏輯關系;確定第一邏輯連接詞與第二邏輯連接詞之間的第一關鍵特征和第二關鍵特征,第一邏輯連接詞與第二邏輯連接詞為多個順序連接詞中,任意相鄰的兩個順序邏輯連接詞,第一關鍵特征為多個名詞性關鍵特征中的任意一個名詞性關鍵特征中,第二關鍵特征為多個動詞關鍵特征中的任意一個動詞性關鍵特性;對第一關鍵特征和第二關鍵特征進行組合,得到第一處理步驟。
20、可選的,處理單元用于根據預設知識網絡,確定第一處理步驟對應的第二面試問題,第一處理步驟為多個處理步驟中的任意一個處理步驟;根據預設知識網絡,在預設數據庫搜索針對第二面試問題的多個第二預存方案;對第一處理步驟進行特征提取,得到多個第一特征,對目標預存方案進行特征提取,得到多個第二特征,目標預存方案為多個第二預存方案中的任意一個第二預存方案;根據多個第一特征以及多個第二特征,計算第一處理步驟與目標預存方案的關聯度,具體計算公式如下:;其中d(x,y)為第一處理步驟x與目標預存方案y的關聯度,df(u)為第u個第一特征的特征頻率,df(v)為第v個第二特征的特征頻率,argmin(d(u,v)×puv)為流量分配矩陣,puv為第u個第一特征到第v個第二特征的流量分配,即將第u個第一特征移動到第v個第二特征所分配的流量數量,d(u,v)為第一特征的特征向量與第二特征的特征向量之間的距離;若確定關聯度大于或等于預設閾值,則確定目標預存方案為關聯步驟。
21、可選的,處理單元用于通過如下公式計算第一特征的特征頻率:;其中,df(u)為第u個第一特征的特征頻率,mu為包含第一特征的預存方案的數量,mu為預存方案的總數量;通過如下公式計算第二特征的特征頻率:;其中,df(v)為第v個第二特征的特征頻率,mv為包含第二特征的預存方案的數量,mv為預存方案的總數量;通過如下公式計算第一特征的特征向量與第二特征的特征向量之間的距離:;其中,d(u,v)為第一特征的特征向量與第二特征的特征向量之間的距離,uk為第一特征在第k個維度的特征向量,vk為第二特征在第k個維度的特征向量。
22、可選的,處理單元用于在第一用戶輸入面試問題后,記錄檢索出的針對面試問題的預存方案的第一數量;記錄第二用戶未經任何處理,選擇預存方案的第二數量;根據第二數量與第一數量的比值,得到選擇率。
23、可選的,處理單元用于確定第一面試問題與預設數據庫中多個預存面試問題的相似度;確定多個預存面試問題中,相似度大于或等于預設相似度閾值的預存面試問題;確定各個相似度大于或等于預設相似度閾值的預存面試問題對應的多個第一預存方案。
24、在本技術第三方面提供一種電子設備,電子設備包括處理器、存儲器、用戶接口及網絡接口,存儲器用于存儲指令,用戶接口和網絡接口用于與其他設備通信,處理器用于執行存儲器中存儲的指令,使得一種電子設備執行如本技術上述中任意一項的方法。
25、在本技術第四方面提供一種計算機可讀存儲介質,計算機可讀存儲介質存儲有指令,當指令被執行時,執行本技術上述中任意一項的方法。
26、綜上,本技術實施例中提供的一個或多個技術方案,至少具有如下技術效果或優點:
27、1、在根據第一用戶的第一面試問題搜索出預設數據庫中的多個預存方案后,再進一步分析第二用戶的選擇習慣,根據第二用戶對預存方案的選擇率,判斷出第一用戶很少選擇預存方案從而采用預存方案,則直接對預存方案依次進行篩選、拆分以及替換處理,使最終得到的面試答案能夠更符合第一用戶的需求。從多個預存方案中篩選出總選擇率較高的預存方案,即篩選出其中在用戶群體中受歡迎的、點擊率較高的預存方案,從而避免推薦需對不受歡迎或不相關的內容,提高了答案的質量和相關性,接著對篩選得到的第一處理方案進行拆分成多個步驟,最后采用關聯步驟替換原來的處理步驟。由于預設數據庫根據第二用戶的選擇習慣對給出的答復進行多重加工,而不需要第一用戶一次次對答復進行調節限定,從而提高答復的效率。
28、2、提高根據預設知識網絡確定第一處理步驟對應第二面試問題,然后搜索出第二面試問題的多個第二預存方案,因為均是針對同一問題的方案,從而使得找出的第二預存方案與第二處理方案的關聯度更高,還可再篩選出排序結果中末位對應的目標選擇率,以得到第二預測方案,并將第二預存方案進行拆分用于后續替換,從而能夠使回復的結果既與原始回復有較高關聯度,并且還是一些偏新穎的方案。
29、3、通過提取多個名詞短語性關鍵特征和多個動詞性關鍵特征,能夠捕捉面試答案中的重要概念和關鍵動作,有助于從大段文本中抽取關鍵信息,通過識別第二處理方案中包含的順序邏輯連接詞,確定了句與句或段與段之間的邏輯關系,這使得面試答案的結構更加清晰,進而更容易理解各個步驟之間的順序和關聯性,最后通過邏輯連接詞之間的關鍵特征的組合,實現了處理步驟的生成。
- 還沒有人留言評論。精彩留言會獲得點贊!