一種車輛工作流的生成方法、設備、介質及程序產品與流程
本技術涉及汽車領域,尤其涉及一種車輛工作流的生成方法、設備、介質及程序產品。
背景技術:
1、目前,車輛支持用戶自定義不同場景下的車輛工作流,每一車輛工作流包含需由車輛執行的多個任務。比如,車主可以設置在回家場景下,車輛工作流包括自動規劃最優回家路徑、調節座椅至記憶位置、調節車內溫度至記憶溫度這三個任務。基于此,當車主在車內說出“回家”時,車輛可以自動執行前述預先設置的車輛工作流。
2、然而,相關技術中,車輛工作流必須由用戶手動設置或編排,這一過程既繁瑣又耗時,特別是對于不熟悉操作的用戶來說更是如此。而且,即便在同一場景下,同一用戶的用車方式也可能有所不同。但車輛在執行工作流的過程中,只能嚴格按照用戶事先設定的任務參數來執行任務,無法靈活調整,這往往導致車輛的任務執行效果無法滿足用戶的需求,從而影響用戶體驗。
技術實現思路
1、本技術提供一種車輛工作流的生成方法、設備、介質及程序產品,以解決相關技術中的不足。
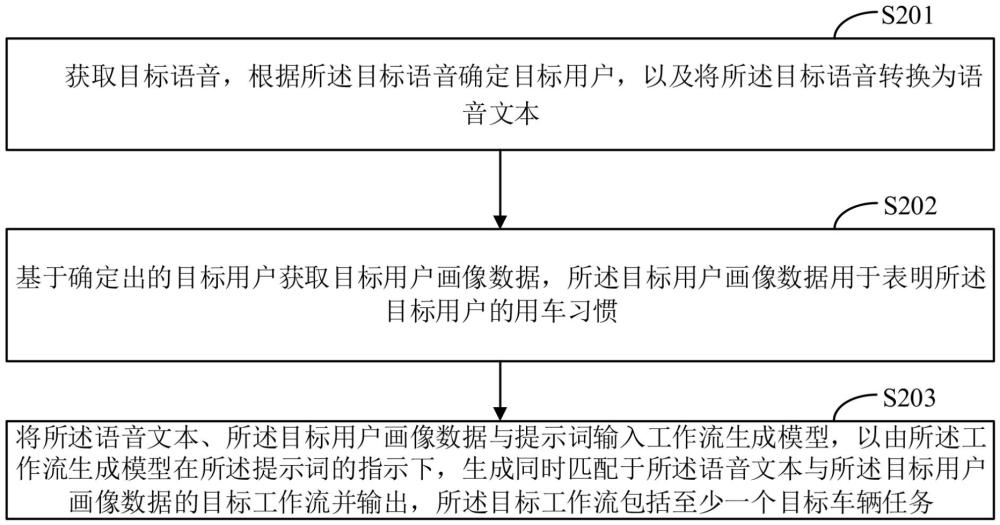
2、根據本技術一個或多個實施例的第一方面,提供一種車輛工作流的生成方法,該方法包括:
3、獲取目標語音,根據所述目標語音確定目標用戶,以及將所述目標語音轉換為語音文本;
4、基于確定出的目標用戶獲取目標用戶畫像數據,所述目標用戶畫像數據用于表明所述目標用戶的用車習慣;
5、將所述語音文本、所述目標用戶畫像數據與提示詞輸入工作流生成模型,以由所述工作流生成模型在所述提示詞的指示下,生成同時匹配于所述語音文本與所述目標用戶畫像數據的目標工作流并輸出,所述目標工作流包括至少一個目標車輛任務。
6、可選的,所述根據所述目標語音確定目標用戶,包括:識別所述目標語音的發起方是否為當前駕駛車輛的第一駕駛員;在識別出所述目標語音的發起方為所述第一駕駛員的情況下,將所述第一駕駛員確定為所述目標用戶;在識別出所述目標語音的發起方并非為所述第一駕駛員、且預定義標準包括將語音發起方確定為目標用戶的規則的情況下,將所述目標語音的發起方確定為所述目標用戶。
7、可選的,所述方法還包括:獲取所述車輛的車輛數據,所述車輛數據包括所述車輛的駕駛環境數據和/或所述車輛的車輛狀態數據;基于所述車輛數據在預設規則庫中進行檢索,所述預設規則庫中包含多條候選預設規則,每一候選預設規則包含對相應車輛任務進行更新的觸發條件以及相應車輛任務的更新方案;在檢索結果表明所述預設規則庫中存在與所述車輛數據相匹配的目標預設規則的情況下,判斷所述車輛數據是否滿足所述目標預設規則包含的目標觸發條件;在判定所述車輛數據滿足所述目標觸發條件的情況下,根據所述目標預設規則中包含的目標更新方案對相應車輛任務進行更新。
8、可選的,所述方法還包括:向所述車輛的駕乘人員輸出所述目標工作流,并在接收到所述駕乘人員針對所述目標工作流的確認指令的情況下,控制所述目標工作流中各目標車輛任務分別對應的目標功能組件執行相應目標車輛任務。
9、可選的,所述方法還包括:監控所述目標工作流中每一目標車輛任務的執行情況;在監控到任一目標車輛任務發生執行異常的情況下,啟用所述任一目標車輛任務對應的備選任務方案進行執行。
10、可選的,在所述目標工作流包括至少兩個所述目標車輛任務的情況下,該至少兩個目標車輛任務之間存在特定執行順序,所述方法還包括:監控所述目標工作流中各個目標車輛任務是否按所述特定執行順序執行;在監控到所述各個目標車輛任務的執行順序區別于所述特定執行順序的情況下,向所述車輛的駕乘人員展示所述目標工作流執行順序有誤的提示信息,和/或,是否調整所述目標工作流的提示信息,以使所述駕乘人員基于展示的提示信息調整所述目標工作流。
11、根據本技術一個或多個實施例的第二方面,提供一種工作流生成模型的訓練方法,該方法包括:
12、獲取針對車輛的樣本文本,以及所述樣本文本對應的樣本用戶畫像數據、樣本工作流;
13、將所述樣本文本、所述樣本用戶畫像數據與樣本提示詞輸入預訓練的工作流生成模型,以由所述預訓練的工作流生成模型在所述樣本提示詞的指示下,生成同時匹配于所述樣本文本與所述樣本用戶畫像數據的樣本預測工作流并輸出;
14、根據所述樣本工作流與所述樣本預測工作流之間的差異,調整所述樣本提示詞以及對所述預訓練的工作流生成模型進行迭代訓練。
15、根據本技術一個或多個實施例的第三方面,提供一種車輛工作流的生成裝置,該裝置包括:
16、語音獲取單元,用于獲取目標語音,根據所述目標語音確定目標用戶,以及將所述目標語音轉換為語音文本;
17、用戶畫像數據獲取單元,用于基于確定出的目標用戶獲取目標用戶畫像數據,所述目標用戶畫像數據用于表明所述目標用戶的用車習慣;
18、工作流生成單元,用于將所述語音文本、所述目標用戶畫像數據與提示詞輸入工作流生成模型,以由所述工作流生成模型在所述提示詞的指示下,生成同時匹配于所述語音文本與所述目標用戶畫像數據的目標工作流并輸出,所述目標工作流包括至少一個目標車輛任務。
19、根據本技術一個或多個實施例的第四方面,提供一種工作流生成模型的訓練裝置,該裝置包括:
20、樣本獲取單元,用于獲取針對車輛的樣本文本,以及所述樣本文本對應的樣本用戶畫像數據、樣本工作流;
21、工作流預測單元,用于將所述樣本文本、所述樣本用戶畫像數據與樣本提示詞輸入預訓練的工作流生成模型,以由所述預訓練的工作流生成模型在所述樣本提示詞的指示下,生成同時匹配于所述樣本文本與所述樣本用戶畫像數據的樣本預測工作流并輸出;
22、迭代單元,用于根據所述樣本工作流與所述樣本預測工作流之間的差異,調整所述樣本提示詞以及對所述預訓練的工作流生成模型進行迭代訓練。
23、根據本技術一個或多個實施例的第五方面,提供一種電子設備,包括:
24、處理器;
25、用于存儲處理器可執行指令的存儲器;
26、其中,所述處理器通過運行所述可執行指令以實現如上述第一方面或第二方面中任一實施例中所述的方法。
27、根據本技術一個或多個實施例的第六方面,提供一種計算機可讀存儲介質,其上存儲有計算機指令,該指令被處理器執行時實現如上述第一方面或第二方面中任一實施例中所述方法的步驟。
28、根據本技術一個或多個實施例的第七方面,提供一種計算機程序產品,包括計算機程序和/或指令,所述計算機程序和/或指令被處理器執行時實現如上述第一方面或第二方面中任一實施例中所述方法的步驟。
29、由以上技術方案可見,本技術一個或多個實施例中,基于獲取到的目標語音確定目標用戶,同時將獲取到的目標語音轉換為語音文本,進而根據確定結果獲取目標用戶畫像數據。然后,將語音文本、目標用戶畫像數據和提示詞輸入工作流生成模型,以由工作流生成模型生成同時匹配于語音文本與目標用戶畫像數據的目標工作流并輸出。上述方式實現了根據用戶語音自動生成目標工作流,無需用戶手動設置或編排,大大提升了用戶操作的便捷性。并且,由于目標用戶畫像數據基于目標用戶的用車習慣生成,即目標用戶畫像數據可以體現目標用戶的用車習慣與偏好,加之語音文本能夠反映發出目標語音的用戶當下的用車需求,因此,基于語音文本與目標用戶畫像數據生成的目標工作流,不僅能夠滿足發出目標語音的用戶的用車需求,還能夠靈活適應目標用戶的用車習慣/偏好,從而顯著提升駕乘人員的用車體驗,確保為用戶提供個性化服務。
30、應當理解的是,以上的一般描述和后文的細節描述僅是示例性和解釋性的,并不能限制本技術。
- 還沒有人留言評論。精彩留言會獲得點贊!