可持續學習的集裝箱提箱序列預測方法、系統和存儲介質
本發明涉及港口碼頭堆場智能管理,具體涉及可持續學習的集裝箱提箱序列預測方法、系統和存儲介質。
背景技術:
1、隨著國際貿易活動的發展,集裝箱運輸作為海上運輸的主流方式,其效率和成本管理對港口基礎設施的運作至關重要。港口貨物吞吐量的上升,使得傳統的裝卸作業計劃和缺乏數據驅動的調度決策已經無法滿足當前的需求,導致作業效率低下和成本增加。在這樣的背景下,如果能夠預測集裝箱的提箱順序,即預測集裝箱在港口堆場的停留時間(停留時間越長意味著提箱時間越遲),那么管理人員在規劃裝卸作業和選擇集裝箱堆垛位置時,就可以更加科學合理。通過提前了解哪些集裝箱將被優先提取,管理人員可以設計出更加高效的堆垛方案,減少不必要的翻箱作業和車輛移動,從而有效降低操作成本,提高整體作業效率。這種方法不僅能夠優化資源配置,還能提升港口的服務質量和競爭力。
2、集裝箱的提箱順序主要是基于集裝箱卡車(簡稱集卡)在到達港口前進行的預約安排來決定的。然而,即使是具備預約系統的港口,也面臨著一些挑戰和不足之處。首先,集裝箱的預約提箱流程是在貨物從貨船卸載到堆場之后才開始的,這意味著無法在貨物卸載時根據預測的提箱順序來制定堆存計劃。其次,預約提箱通常是按照時間段來安排的,但由于外部因素如交通狀況、氣候條件等不可預測的變化,這些預約時間段的實際參考價值可能會受到影響。此外,對于一些規模較小的集裝箱碼頭,甚至可能沒有實行預約機制,這進一步增加了管理難度和作業的不確定性。
3、目前求解該問題采用的主要技術方法有以下兩類:
4、(1)通過分析集裝箱歷史操作數據,基于分類器對不同堆存天數范圍的集裝箱進行分類以確定大致的提箱序列。該方法對不同范圍的堆存天數進行劃分,例如0-5天、6-10天、10天以上,將堆存天數的回歸預測問題轉為一個分類問題,將不同范圍堆存天數的集裝箱進行歸類堆垛。
5、(2)通過分析集裝箱歷史操作數據,基于svr、隨機森林等回歸預測算法對集裝箱堆存天數進行預測,根據具體的預測天數排序后對集裝箱進行堆垛。
6、以上方法存在的缺點(勞鈕鈔,劉秀峰,楊錦禮,等.基于隨機森林構建集裝箱堆存時間預測分類器的港口翻箱研究[j].裝備制造技術,?2022(002):000.):
7、(1)基于分類器的算法預測過于粗糙,無法確定同一堆存天數范圍內的集裝箱的細分堆存天數,落地可行性較低;
8、(2)基于svr、隨機森林等回歸預測算法雖然在實驗數據有較好的預測表現,但是隨著業務的發展,模型的泛化表現可能會面臨挑戰,需要不斷的重新收集數據訓練模型,且訓練時間較長,成本較高。
技術實現思路
1、為了應對現有集裝箱堆存時間預測的局限性,本發明開發一種基于數據分析和機器學習技術的集裝箱提箱序列預測方法,旨在提前預測集裝箱的提箱序列,并通過增量學習持續優化模型,從而提升提箱效率,降低作業成本。
2、本發明的目的至少通過如下技術方案之一實現。
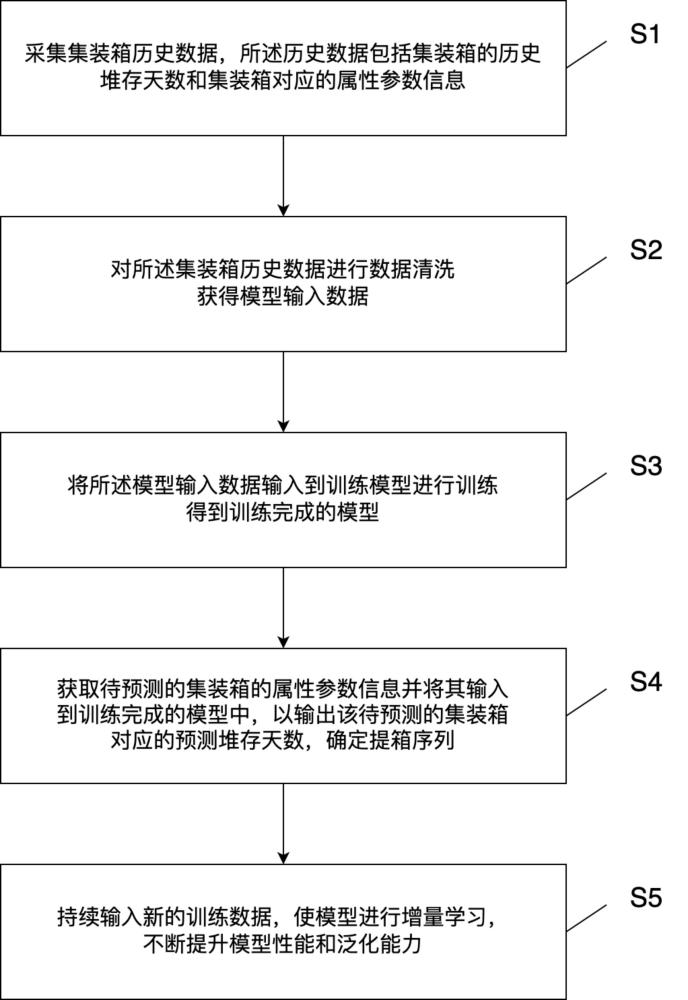
3、可持續學習的集裝箱提箱序列預測方法,包括以下步驟:
4、s1、執行集裝箱歷史數據采集操作,集裝箱歷史數據包括每個集裝箱的歷史堆存時間以及與集裝箱關聯的屬性參數信息;
5、s2、對采集到的集裝箱歷史數據執行數據清洗過程,旨在凈化數據集,獲得經過清洗的模型輸入數據;
6、s3、將經過清洗的模型輸入數據送入訓練算法中,以此進行寬度學習系統(boardlearning?system,bls)模型訓練操作,最終得到一個訓練完成的寬度學習系統模型;
7、s4、當需要對新的集裝箱進行堆存時間預測時,首先獲取該集裝箱的屬性參數信息,然后將這些信息輸入到訓練完成的寬度學習系統模型中,寬度學習系統模型將處理這些輸入信息,并輸出該集裝箱的預測堆存時間,根據該集裝箱的預測堆存時間得到集裝箱的提箱序列,堆存時間越大,代表著越久來提,即將堆存時間從小到大排序得到集裝箱的提箱序列;
8、s5、基于可持續學習的增量學習算法,不斷基于新的集裝箱歷史數據更新模型,不斷提升模型的性能,更新模型后,返回步驟s4中等待下一次對新的集裝箱進行堆存時間預測。
9、進一步地,步驟s1的具體步驟為:
10、s1.1、采集碼頭歷史的集裝箱數據,數據采集范圍包括集裝箱所在堆場的信息、集裝箱自有屬性、集裝箱內的貨物屬性、集裝箱關聯碼頭作業單屬性、監管部門的監管信息屬性、集裝箱作業集卡預約信息屬性以及集裝箱歷史的堆存時間,其中,堆存時間為預測目標,模型根據其余采集的數據預測堆存時間;
11、s1.2、通過統計學的方式,統計不同特征與集裝箱堆存時間的相關關系,按照設定的相關性閾值,篩選出相關性符合要求的作為數據集的核心特征。
12、進一步地,步驟s2的具體實現步驟為:
13、s2.1、對數據集中不符合邏輯的數據進行清洗;
14、s2.2、對數據集中的非數值型數據采用特征工程進行數值化處理,對數據集中的缺失值采用其他歷史數據中與該集裝箱裝有相同貨物和相同集裝箱中的數據的均值進行替代;
15、s2.3、對數據集進行劃分,按照設定的比例劃分數據為訓練集和測試集。
16、進一步地,步驟s3中,包括以下步驟:
17、s3.1、基于步驟s2.3中獲得的訓練集數據對寬度學習系統(board?learningsystem,bls)模型進行訓練,并記錄訓練過程及保存訓練完成的模型文件;寬度學習系統(bls)的提出最早源于澳門大學科技學院院長陳俊龍和其學生于2018年1月發表在ieeetransactions?on?neural?networks?and?learning?systems,vol.?29,?no.?1?的一篇文章,題目叫《broad?learning?system:?an?effective?and?efficient?incrementallearning?system?without?the?need?for?deep?architecture?》。
18、s3.2、將步驟s2.3中獲得的測試集數據作為訓練完成的寬度學習系統模型的輸入數據,獲得寬度學習系統模型預測的集裝箱堆存時間,并將集裝箱記錄按照船名航次(即同一艘船到達港口碼頭)進行分組,并將分組內的集裝箱實際堆存時間按照從小到大進行排序;
19、s3.3、按照步驟s3.2中的分組,將記錄中的實際堆存時間和預測堆存時間進行比較以評估訓練完成的寬度學習系統模型的性能,包括使用均方誤差mse進行評估以及使用曲線單調性對模型預測效果進行評估,若模型預測效果不符合要求,則通過完善補充模型特征,增加訓練數據,直至模型預測精度符合要求。
20、進一步地,步驟s3.3中,將記錄中的實際堆存時間和預測堆存時間進行比較以評估訓練完成的寬度學習系統模型的性能,包括使用均方誤差mse進行評估以及使用曲線單調性對模型預測效果進行評估;
21、所述使用曲線單調性對模型預測效果進行評估為通過判斷曲線的單調性來確定預測與實際的相對序列是否匹配,即在步驟s3.2的基礎上,判斷預測堆存時間曲線的單調性,即根據預測堆存時間曲線的單調性判斷預測的集裝箱的提箱序列是否正確;
22、均方誤差mse用于評估預測時間是否準確,曲線單調性用于評估預測的集裝箱的提箱序列是否準確。
23、進一步地,步驟s5中,當實際業務產生變化,或原模型的泛化效果無法支撐新的集裝箱數據的堆存時間預測,基于訓練完成的寬度學習系統模型,采用寬度學習系統模型的增量學習特點,進行增量訓練,進一步提升模型性能。
24、進一步地,步驟s5中,若實際業務產生變化,包括主營貨類發生變化或合作客戶發生變化,導致原模型的泛化效果無法支撐新的集裝箱數據的堆存時間預測,此時返回步驟s1中重新獲取集裝箱歷史數據,執行步驟s1~s3,得到重新訓練完成的寬度學習系統模型。
25、進一步地,步驟s5中,在設定的一段時間內,若實際業務沒有產生變化,但寬度學習系統模型不符合預測精度要求,則根據該段時間內的集裝箱數據,返回步驟s3中重新對寬度學習系統模型進行訓練,得到重新訓練完成的寬度學習系統模型。
26、可持續學習的集裝箱提箱序列預測系統,包括存儲器和處理器,存儲器中存儲有計算機程序,處理器連接存儲器,處理器用于執行所述計算機程序,以實現所述的可持續學習的集裝箱提箱序列預測方法。
27、一種存儲介質,存儲有計算機程序,所述計算機程序被執行時用于實現所述的可持續學習的集裝箱提箱序列預測方法。
28、與現有發明相比,本發明的有益效果:
29、(1)本發明充分利用了集裝箱歷史數據,從數據中挖掘與堆存時間相關的特征,無需提箱序列預測的先驗知識。
30、(2)相比與分類器模型,本發明采用回歸預測模型能更加精細的預測每個集裝箱的預估堆存時間,幫助計劃調度人員更為合理的制定堆場堆存計劃,極大地減少堆場機械的無功作業量,縮短作業等待時間,大幅提升作業效率,實現“降本增效”。
31、(3)相比與其他的回歸預測模型,本發明采用bls模型,能夠大幅降低訓練時長,同時支持增量學習,對于集裝箱碼頭這種業務變化比較頻繁的場景,可以更加方便的獲得基于增量數據訓練后的新模型,提升模型的性能和泛化效果。
- 還沒有人留言評論。精彩留言會獲得點贊!