用于大數據分析的異常數據清洗消除方法及系統與流程
本發明涉及數據清洗,具體涉及一種用于大數據分析的異常數據清洗消除方法及系統。
背景技術:
1、通過大數據分析平臺對不同醫藥類型的銷量數據進行分析,能夠及時發現不同醫藥類型的銷量數據的變化趨勢,并針對性的對不同醫藥產品的生產做出調整,但在醫藥銷量數據的獲取、傳輸和存儲過程中,部分數據會不可避免的出現偏差,因此需要對大數據分析平臺的醫藥銷量數據進行清洗,以保證平臺的分析精度。
2、相關技術中,通常利用局部異常異常因子算法(local?outlier?factor,lof)或孤立森林算法(isolation?forest,iforest)等異常檢測算法對醫藥銷量數據進行異常檢測,并對異常數據進行清洗,但由于各類型的醫藥通常會通過多種渠道進行銷售,多種渠道下的醫藥銷量數據相互影響,某個渠道的醫藥銷量數據的變化會影響到其他渠道的醫藥銷量數據發生改變,導致現有方法無法準確檢測出異常銷量數據,進而降低對醫藥銷量數據清洗的效果。
技術實現思路
1、為了解決多種渠道下的醫藥銷量數據相互影響,導致現有方法無法準確檢測出異常的銷量數據,進而降低對醫藥銷量數據清洗的效果的技術問題,本發明的目的在于提供一種用于大數據分析的異常數據清洗消除方法及系統,所采用的技術方案具體如下:
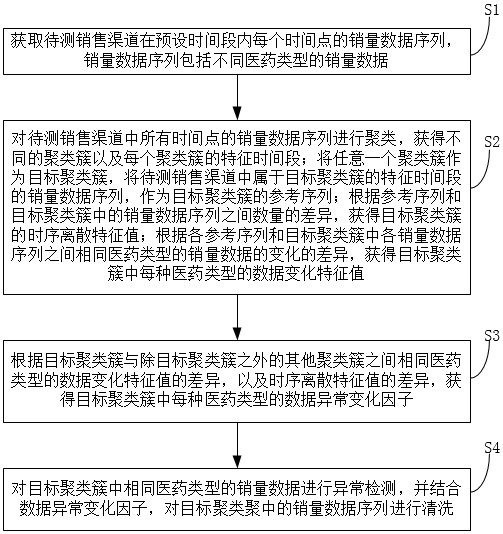
2、本發明提出了一種用于大數據分析的異常數據清洗消除方法,所述方法包括:
3、獲取待測銷售渠道在預設時間段內每個時間點的銷量數據序列,所述銷量數據序列包括不同醫藥類型的銷量數據;
4、對所述待測銷售渠道中所有時間點的銷量數據序列進行聚類,獲得不同的聚類簇以及每個聚類簇的特征時間段;將任意一個聚類簇作為目標聚類簇,將待測銷售渠道中屬于目標聚類簇的所述特征時間段的銷量數據序列,作為目標聚類簇的參考序列;根據所述參考序列和目標聚類簇中的銷量數據序列之間數量的差異,獲得目標聚類簇的時序離散特征值;根據各參考序列和目標聚類簇中各銷量數據序列之間相同醫藥類型的銷量數據的變化的差異,獲得目標聚類簇中每種醫藥類型的數據變化特征值;
5、根據目標聚類簇與除目標聚類簇之外的其他聚類簇之間相同醫藥類型的所述數據變化特征值的差異,以及所述時序離散特征值的差異,獲得目標聚類簇中每種醫藥類型的數據異常變化因子;
6、對目標聚類簇中相同醫藥類型的銷量數據進行異常檢測,并結合所述數據異常變化因子,對目標聚類聚中的銷量數據序列進行清洗。
7、進一步地,所述獲得目標聚類簇中每種醫藥類型的數據變化特征值包括:
8、對目標聚類簇中所有時間點的銷量數據序列中每種醫藥類型的銷量數據的離散程度,以及各醫藥類型的銷量數據之間的相關性進行分析,獲得目標聚類簇中每種醫藥類型的第一數據變化參數;
9、對所有時間點的所述參考序列中每種醫藥類型的銷量數據的離散程度,以及各醫藥類型的銷量數據之間的相關性進行分析,獲得待測銷售渠道在目標聚類簇的特征時間段中每種醫藥類型的第二數據變化參數;
10、根據相同醫藥類型的所述第一數據變化參數和所述第二數據變化參數的差異,獲得目標聚類簇中每種醫藥類型的數據變化特征值。
11、進一步地,所述獲得目標聚類簇中每種醫藥類型的第一數據變化參數包括:
12、構建第一狀態矩陣,所述第一狀態矩陣的行表示時間點,所述第一狀態矩陣的列表示醫藥類型,所述第一狀態矩陣的行元素為目標聚類簇中每個時間點的銷量數據序列;
13、將所述第一狀態矩陣輸入至critic客觀賦權算法中,將輸出的每列的客觀權重值,作為目標聚類簇中每種醫藥類型的第一數據變化參數。
14、進一步地,所述獲得待測銷售渠道在目標聚類簇的特征時間段中每種醫藥類型的第二數據變化參數包括:
15、構建第二狀態矩陣,所述第二狀態矩陣的行表示時間點,所述第二狀態矩陣的列表示醫藥類型,所述第二狀態矩陣的行元素為每個時間點的參考序列;
16、將所述第二狀態矩陣輸入至critic客觀賦權算法中,將輸出的每列的客觀權重值,作為待測銷售渠道在目標聚類簇的特征時間段中每種醫藥類型的第二數據變化參數。
17、進一步地,所述獲得目標聚類簇中每種醫藥類型的數據異常變化因子包括:
18、將除目標聚類簇之外的其他聚類簇作為參考聚類簇;
19、根據目標聚類簇與每個參考聚類簇之間所述時序離散特征值的差異,獲得目標聚類簇與每個參考聚類簇之間的第一特征值差異;
20、根據目標聚類簇與每個參考聚類簇之間相同醫藥類型的所述數據變化特征值的差異,獲得目標聚類簇與每個參考聚類簇之間每種醫藥類型的第二特征值差異;
21、對所述第一特征值差異和所述第二特征值差異進行綜合,獲得目標聚類簇與每個參考聚類簇之間每種醫藥類型的綜合特征值差異;
22、對目標聚類簇與所有參考聚類簇之間每種醫藥類型的所述綜合特征值差異的整體水平分析后并進行歸一化處理,獲得目標聚類簇中每種醫藥類型的數據異常變化因子,其中,目標聚類簇中所有醫藥類型的所述數據異常變化因子的和值等于數值1。
23、進一步地,所述對目標聚類簇中相同醫藥類型的銷量數據進行異常檢測,并結合所述數據異常變化因子,對目標聚類聚中的銷量數據序列進行清洗包括:
24、分別將目標聚類簇中所有銷量數據序列中的相同醫藥類型的銷量數據輸入至異常檢測算法中,獲得目標聚類簇中每個銷量數據序列中每種醫藥類型的銷量數據的異常評估值;
25、利用目標聚類簇中每種醫藥類型的所述數據異常變化因子,對目標聚類簇中每個銷量數據序列中每種醫藥類型的銷量數據的所述異常評估值進行加權求和后并進行歸一化處理,獲得目標聚類簇中每個銷量數據序列的清洗判斷值;
26、基于所述清洗判斷值,對目標聚類簇中的銷量數據序列進行清洗。
27、進一步地,所述基于所述清洗判斷值,對目標聚類簇中的銷量數據序列進行清洗包括:
28、在目標聚類簇中,將所述清洗判斷值大于預設清洗閾值的銷量數據序列進行刪除。
29、進一步地,所述對所述待測銷售渠道中所有時間點的銷量數據序列進行聚類,獲得不同的聚類簇以及每個聚類簇的特征時間段包括:
30、基于待測銷售渠道中各銷量數據序列中相同醫藥類型的醫藥數據的差異,對所有的銷量數據序列進行聚類,獲得不同的聚類簇;
31、在每個聚類簇中,將所有銷量數據序列對應的時間點的最小值和最大值之間的時間段,作為每個聚類簇的特征時間段。
32、進一步地,所述根據所述參考序列和目標聚類簇中的銷量數據序列之間數量的差異,獲得目標聚類簇的時序離散特征值包括:
33、將所有參考序列的數量作分子,將目標聚類簇中所有銷量數據序列的數量作分母,將比值作為目標聚類簇的時序離散特征值。
34、本發明還提出了一種用于大數據分析的異常數據清洗消除系統,所述系統包括存儲器、處理器以及存儲在所述存儲器中并可在所述處理器上運行的計算機程序,所述處理器執行所述計算機程序時實現任意一項用于大數據分析的異常數據清洗消除方法的步驟。
35、本發明具有如下有益效果:
36、本發明考慮到多種銷售渠道下的醫藥銷量數據相互影響,導致現有方法無法準確檢測出異常的銷量數據,進而降低對醫藥銷量數據清洗的效果,因此本發明首先獲取待測銷售渠道在預設時間段內每個時間點的銷量數據序列,考慮到異常因素和不同銷售渠道間相互影響的因素,都會導致使得銷量數據出現變化,因此本發明首先對醫藥銷量數據序列進行聚類,得到多個聚類簇以及每個聚類簇的特征時間段,并將待測銷售渠道中屬于目標聚類簇的特征時間段的銷量數據序列作為參考序列,當目標聚類簇中存在受這兩種因素影響的銷量數據序列時,使得參考序列和目標聚類簇中的銷量數據序列之間的數量差異較大,并且二者之間相同醫藥類型的銷量數據的變化情況也存在較大的差異,因此可通過時序離散特征值和數據變化特征值反映目標聚類簇中存在受影響的銷量數據序列的可能性,考慮到當目標聚類簇中存在異常數據時,會增大目標聚類簇與其他聚類簇之間的時序離散特征值差異以及相同醫藥類型的數據變化特征值的差異,因此可通過數據異常變化因子反映目標聚類簇中每種醫藥類型的銷量數據存在異常的可能性,進而結合數據異常變化因子,對目標聚類聚中的銷量數據序列進行清洗,提高異常銷量數據檢測的準確性以及對銷量數據清洗的效果。
- 還沒有人留言評論。精彩留言會獲得點贊!