金融輿情相似度概率預測方法、系統及裝置與流程
本發明涉及人工智能,尤其涉及一種金融輿情相似度概率預測方法、系統及裝置。
背景技術:
1、網絡輿情是通過互聯網傳播的公眾對現實生活中某些熱點、焦點問題所持的有較強影響力、傾向性的言論和觀點,而金融輿情特指是金融方向的。由于互聯網具有虛擬性、隱蔽性、發散性、滲透性和隨意性等特點,越來越多的人樂意通過這種渠道來表達觀點、傳播思想。網絡輿情是一股強大的輿論力量,會反作用于熱點事件并對社會發展和事態進程產生一定的影響。如果引導不善,負面的網絡輿情將對社會公共安全形成較大威脅。如果形成較大的輿情事件,則可能會被傳播至多個渠道以產生更大的影響,因此對于輿情事件的輿論監測分析是輿情管理的關鍵環節。輿情事件發生后,往往會引來輿論的熱議,進而產生大批量的輿論信息,這類信息產生后,往往會加大輿情事件的影響力,進而形成輿情危機。因此,對于輿情事件的輿論監測分析也是輿情管制的關鍵環節。而輿情相似度的判斷更是關鍵中的關鍵。
2、在現有技術中,輿情相似度模型主要通過傳統機器學習、深度學習或者語言預訓練模型進行訓練的。這些訓練方式目前會存在以下問題:
3、傳統機器學習通常通過tf-idf、詞袋模型等方法將文本轉化為向量,再基于余弦相似度、歐氏距離等方法得到文本之間的相似度,目前還不能確切的捕捉文本的深層語義信息,對于一詞多義、同義詞或者由于語境不同導致語義不同的詞語處理效果不佳。
4、深度學習則通過神經網絡自動學習文本的深層表示,如使用卷積神經網絡(cnn)、循環神經網絡(rnn)或transformer等模型提取文本特征,再計算特征之間的相似度。語言預訓練模型則利用如bert、roberta等預訓練模型對文本進行編碼,得到文本的深層語義表示,再通過計算表示之間的相似度來衡量文本的相似性。深度學習和語言預訓練模型的方法雖然能夠捕捉文本的深層結構和語義信息,但需要大量的計算資源和訓練數據,在金融領域,輿情相關數據多為非結構化的文本信息,不僅會涉及專業術語和概念,而且特征復雜并且來源廣泛比如來自于新聞報道、分析師報告,還包括社交媒體、論壇、博客等,因此會使得數據形式多樣化。目前由于人工標注提供的樣本有限,因此難以充分學習輿情文本的特征表示,即使通過一些數據增強的手段,在魯棒性和泛化能力上也很難得以提升。
技術實現思路
1、本發明針對現有技術中的缺點,提供了一種金融輿情相似度概率預測方法、系統及裝置。
2、為了解決上述技術問題,本發明通過下述技術方案得以解決:
3、一種金融輿情相似度概率預測方法,包括以下步驟:
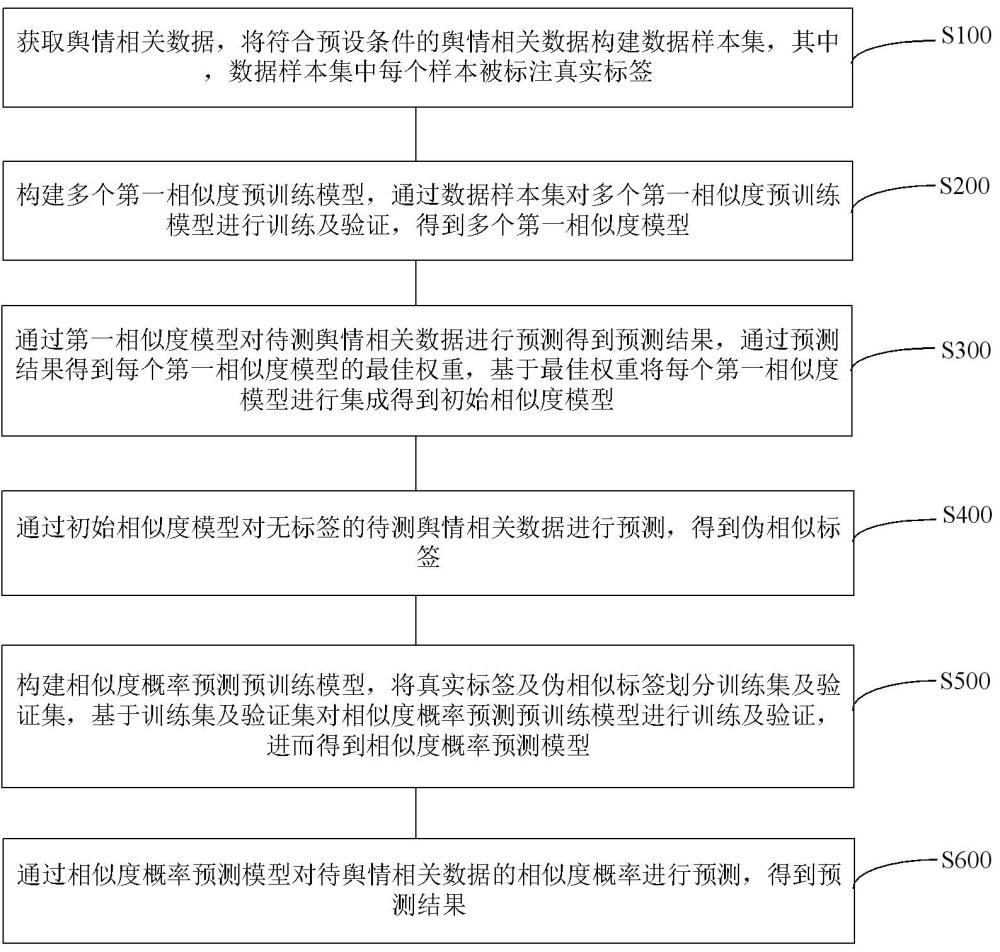
4、獲取輿情相關數據,將符合預設條件的輿情相關數據構建數據樣本集,其中,數據樣本集中每個樣本被標注真實標簽;
5、構建多個第一相似度預訓練模型,通過數據樣本集對多個第一相似度預訓練模型進行訓練及驗證,得到多個第一相似度模型;
6、通過第一相似度模型對待測輿情相關數據進行預測得到預測結果,通過預測結果得到每個第一相似度模型的最佳權重,基于最佳權重將每個第一相似度模型進行集成得到初始相似度模型;
7、通過初始相似度模型對無標簽的待測輿情相關數據進行預測,得到偽相似標簽;
8、構建相似度概率預測預訓練模型,將真實標簽及偽相似標簽劃分訓練集及驗證集,基于訓練集及驗證集對相似度概率預測預訓練模型進行訓練及驗證,進而得到相似度概率預測模型;
9、通過相似度概率預測模型對待輿情相關數據的相似度概率進行預測,得到預測結果。
10、作為一種可實施方式,還包括以下步驟:
11、若預測結果大于預設閾值,則通過語言模型對待輿情相關數據提取異常樣本特征;
12、基于異常樣本特征對真實標簽及偽相似標簽形成的標簽集重新劃分,以重新形成劃分訓練集及驗證集。
13、作為一種可實施方式,所述獲取輿情相關數據,將符合預設條件的輿情相關數據構建數據樣本集,包括以下步驟:
14、獲取連續兩組輿情相關數據并進行分析,分別得到第一事件特征和第二事件特征;
15、基于第一事件特征和第二事件特征得到特征重合率,判斷特征重合率是否大于預設特征閾值,若是,則作為輿情相關數據樣本;
16、若否,則計算事件時間差,判斷事件時差是否不超過時間閾值,若是,則作為輿情相關數據樣本;
17、若否,則比較兩個事件的類型是否相同,若相同,則作為輿情相關數據樣本;
18、若都不滿足,則無法作為輿情相關數據樣本。
19、作為一種可實施方式,還包括將數據樣本集劃分為訓練樣本集及驗證樣本集的步驟,具體為:
20、基于數據樣本集,對數據樣本集中的類型、特征、數量及真實標簽的分布情況進行統計,得到統計結果;
21、基于統計結果得到劃分比例,按照劃分比例將數據樣本集劃分為訓練樣本集及驗證樣本集。
22、作為一種可實施方式,所述基于最佳權重將每個第一相似度模型進行集成得到初始相似度模型,包括以下步驟:
23、構建關于權重的損失函數,使得損失函數達到最小值,進而得到最佳權重;
24、基于最佳權重將每個第一相似度模型進行集成,得到初始相似度模型;
25、所述損失函數,表示如下:
26、
27、所述最佳權重,表示如下:
28、
29、所述初始相似度模型,表示如下:
30、
31、其中,表示輸入為每個第一相似度模型輸出的最優權重的初始相似度模型,,表示初始相似度模型對實際標簽的預測結果,表示事件類型的實際標簽的真實結果,表示每個第一相似度模型對事件類型的輸出結果,表示每個第一相似度模型內部對事件類型進行計算的權重,表示初始相似度模型中第個第一相似度模型輸出的最優權重,表示第個第一相似度模型,表示事件類型集合,表示事件類型共有個不同的事件類型,,。
32、作為一種可實施方式,還包括以下步驟:
33、基于二元交叉熵模型計算第一相似度模型的預測結果與待測輿情相關數據真實標簽的差異值,若差異值達到預設條件,則第一相似度概率預測完成訓練;
34、所述二元交叉熵模型,表示如下:
35、
36、表示每個第一相似度模型的預測結果,表示真實標簽;表示真實標簽為1時的類別權重,表示真實標簽為0時的類別權重。
37、一種金融輿情相似度概率預測系統,包括數據獲取模塊、第一構建訓練模塊、預測集成模塊、第二預測模塊、第二構建訓練模塊及預測結果模塊;
38、所述數據獲取模塊,用于獲取輿情相關數據,將符合預設條件的輿情相關數據構建數據樣本集,其中,數據樣本集中每個樣本被標注真實標簽;
39、所述第一構建訓練模塊,用于構建多個第一相似度預訓練模型,通過數據樣本集對多個第一相似度預訓練模型進行訓練及驗證,得到多個第一相似度模型;
40、所述預測集成模塊,用于通過第一相似度模型對待測輿情相關數據進行預測得到預測結果,通過預測結果得到每個第一相似度模型的最佳權重,基于最佳權重將每個第一相似度模型進行集成得到初始相似度模型;
41、所述第二預測模塊,用于通過初始相似度模型對無標簽的待測輿情相關數據進行預測,得到偽相似標簽;
42、所述第二構建訓練模塊,用于構建相似度概率預測預訓練模型,將真實標簽及偽相似標簽劃分訓練集及驗證集,基于訓練集及驗證集對相似度概率預測預訓練模型進行訓練及驗證,進而得到相似度概率預測模型;
43、所述預測結果模塊,用于通過相似度概率預測模型對待輿情相關數據的相似度概率進行預測,得到預測結果。
44、作為一種可實施方式,還包括特征提取反饋模塊,被設置為:
45、若預測結果大于預設閾值,則通過語言模型對待輿情相關數據提取異常樣本特征;
46、基于異常樣本特征對真實標簽及偽相似標簽形成的標簽集重新劃分,以重新形成劃分訓練集及驗證集。
47、一種計算機可讀存儲介質,所述計算機可讀存儲介質存儲有計算機程序,所述計算機程序被處理器執行時實現如下所述的方法:
48、獲取輿情相關數據,將符合預設條件的輿情相關數據構建數據樣本集,其中,數據樣本集中每個樣本被標注真實標簽;
49、構建多個第一相似度預訓練模型,通過數據樣本集對多個第一相似度預訓練模型進行訓練及驗證,得到多個第一相似度模型;
50、通過第一相似度模型對待測輿情相關數據進行預測得到預測結果,通過預測結果得到每個第一相似度模型的最佳權重,基于最佳權重將每個第一相似度模型進行集成得到初始相似度模型;
51、通過初始相似度模型對無標簽的待測輿情相關數據進行預測,得到偽相似標簽;
52、構建相似度概率預測預訓練模型,將真實標簽及偽相似標簽劃分訓練集及驗證集,基于訓練集及驗證集對相似度概率預測預訓練模型進行訓練及驗證,進而得到相似度概率預測模型;
53、通過相似度概率預測模型對待輿情相關數據的相似度概率進行預測,得到預測結果。
54、一種金融輿情相似度概率預測裝置,包括存儲器、處理器以及存儲在所述存儲器中并在所述處理器上運行的計算機程序,所述處理器執行所述計算機程序時實現如下所述的方法:
55、獲取輿情相關數據,將符合預設條件的輿情相關數據構建數據樣本集,其中,數據樣本集中每個樣本被標注真實標簽;
56、構建多個第一相似度預訓練模型,通過數據樣本集對多個第一相似度預訓練模型進行訓練及驗證,得到多個第一相似度模型;
57、通過第一相似度模型對待測輿情相關數據進行預測得到預測結果,通過預測結果得到每個第一相似度模型的最佳權重,基于最佳權重將每個第一相似度模型進行集成得到初始相似度模型;
58、通過初始相似度模型對無標簽的待測輿情相關數據進行預測,得到偽相似標簽;
59、構建相似度概率預測預訓練模型,將真實標簽及偽相似標簽劃分訓練集及驗證集,基于訓練集及驗證集對相似度概率預測預訓練模型進行訓練及驗證,進而得到相似度概率預測模型;
60、通過相似度概率預測模型對待輿情相關數據的相似度概率進行預測,得到預測結果。
61、本發明由于采用了以上技術方案,具有顯著的技術效果:
62、本技術通過識別和提取輿情相關數據的關鍵特征進行訓練樣本劃分,在不需要大量人工標注樣本的前提下,通過深度學習最大程度上讓模型學習到樣本集中所有的特征信息。
63、本技術能使得小規模樣本在隨機劃分訓練集和驗證集導致特征信息遺失的情況下,通過對預測結果異常對應的樣本的特征進行提取及識別,得到異常樣本特征,進而能夠優化訓練過程中標簽集的劃分規則,最大程度上保留特征信息,提升模型的學習效果。
- 還沒有人留言評論。精彩留言會獲得點贊!