一種用于神經網絡訓練的大規模POI數據處理和加載方法
本發明屬于機器學習領域,特別涉及一種用于神經網絡訓練的大規模poi數據處理和加載方法。
背景技術:
1、隨著信息技術的發展,在線地圖、推薦平臺等信息化服務日益融入到人們的生活中。這些服務為人們的生活提供了越來越多的便利。poi(po?ints?of?interest,興趣點)是許多平臺服務的重要內容,也是用戶生活中的關鍵信息需求來源。平臺需要根據poi的特點有針對性地進行推薦,用戶也需要快速獲取目標poi的相關信息。規范的、客觀的、信息充分的高質量poi描述文本可以對上述服務提供有效幫助。目前,大量新的poi正在快速涌現,且當前的poi基數已經非常大。但大多數poi缺乏此類高質量描述文本。鑒于poi數量巨大,人工撰寫描述文本實際上是不現實的。實現自動的poi描述生成模型將有著巨大的應用潛力。poi描述生成是指根據poi相關數據(評論、類別、位置背景信息等)生成對poi的客觀描述。良好的描述能夠方便用戶快速獲取poi的信息,同時提升poi推薦系統的性能。目前完成該任務的有效方法是利用poi數據訓練深度神經網絡模型。在深度學習領域,利用poi數據訓練相關模型需要對大規模poi數據進行處理和加載。處理指的是數據預處理,包括數據篩選、數據特征標記等。加載指的是在模型訓練階段對數據的讀取,基于梯度下降法的神經網絡訓練往往需要隨機讀取。poi數據一般存儲在分布式數據庫系統中,抽取到本地可以為文本形式的tsv文件(以tab分隔的表格形式文件),其中每一列表示一個poi數據字段,每一行為一個記錄。大規模poi數據通常具有幾億的記錄數量。對于一個數據集,上述tsv文件被按行拆分為多個。每個文件有兩個關鍵標識字段:poi?id(poi的唯一標識符),item?id(記錄的標識符),通常多個記錄對應一個poi。其他字段為poi相關數據如評論信息,poi類別等。深度神經網絡模型訓練需要上述加載和處理過程高效、資源占用低。
2、現有技術:
3、a)tfrecord是一種數據集存儲方法,便于加載和傳輸。tfrecord將每一個樣本編碼為字節碼,外加長度和檢驗值在連續的空間存儲,適合于大量數據的快速讀取,內存利用率高。對于一個數據集中的每一個樣本,tf?record首先將其轉化為字節碼形式,數據集中的各個樣本的字節碼順序寫入一個文件中即構成tfrecord文件。讀取時支持快速順序讀取,首先讀取一個樣本的字節碼,根據樣本數據類型轉換回相應的格式即可。
4、b)pandas是一個表格文件處理工具,支持對小規模表格類型(tsv等)的讀取和處理。處理過程中一般將數據文件全部讀取到內存中。
5、dask是一個采用并行計算的能夠處理大規模數據的表格文件處理工具。
6、c)哈希索引技術,基礎實現可以利用一個字典存儲數據鍵和對應的數據偏移量。利用偏移量可以快速找到數據位置。
7、現有技術的缺點:
8、a)poi數據需要進行處理、加載利用的反復迭代,對于大規模數據集,tfrecord處理占用磁盤空間較多(處理后需要構建新的數據文件)。訓練時需要進行隨機讀取,但tfrecord更適用于順序讀取,隨機讀取復雜度大:o(n)(在計算機領域用于描述算法復雜度);
9、b)pandas不適用于大規模數據處理,無法應用于該任務。dask對于數據處理計算時間仍然較長,且隨機讀取效率低。主要原因是存在大量不必要的計算,沒有針對該任務特征進行優化;
10、c)哈希表需要讀入內存中,在poi數據量過大時仍然面臨較大的內存壓力。
技術實現思路
1、為解決現有技術中存在的問題,本發明提供了一種用于神經網絡訓練的大規模poi數據處理和加載方法,能夠支持高效、低內存和磁盤占用的反復處理和隨機讀取,并且便于分割。
2、為實現上述目的,本發明采用如下方案:
3、本發明提供一種用于神經網絡訓練的大規模poi數據處理和加載方法,包括以下步驟:
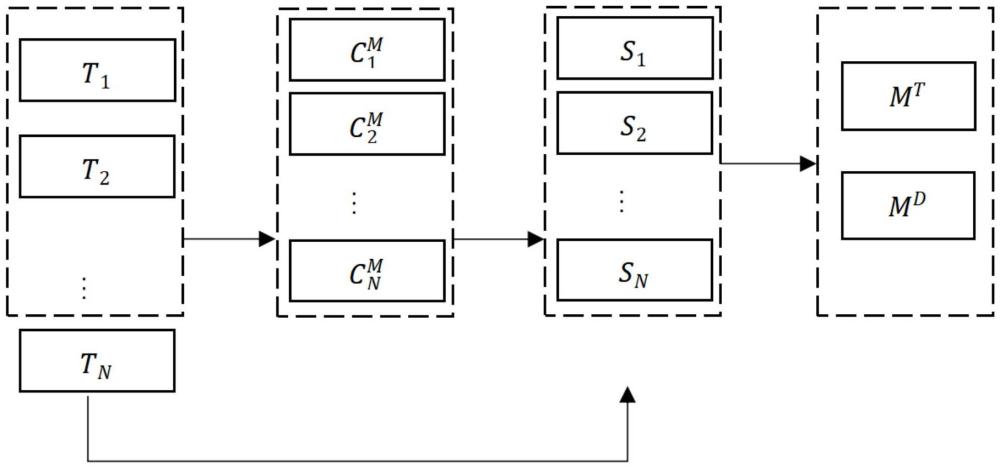
4、s1:定義基本參數,包括poi數據表格的結構定義;
5、s2:輔助文件構建:對數據進行預處理并將處理結果存儲在伴隨文件中;構建查找文件和映射文件,其中所述查找文件用于記錄poi數據在原始文件中的位置和處理結果,所述映射文件用于提供數據快速定位;
6、s3:數據加載:在實際使用時,系統先根據所述映射文件找到poi數據在所述查找文件中的位置,然后打開所述查找文件,根據所述映射文件指示的偏移量讀取相應的數據行;其中,所述伴隨文件中的處理結果可提供參考以對讀取的數據進行進一步的處理和利用。
7、在一些實施例中,本發明還包括以下技術特征:
8、步驟s1具體為:定義poi數據表格,包括若干數據表格文件t1,t2,…,tn,n為表格個數,所述poi數據表格有4個字段,分別為poi標識符poiid,行標識符itemid,數據字段1:d1,數據字段2:d2;所述數據表格文件為文本形式,其中每一個poi在所述poi數據表格中對應的一系列行連續且處于同一數據表格文件中,同一數據表格文件中存在若干poi。
9、步驟s2包括以下步驟:
10、s2-1:數據處理,處理結果以伴隨文件的形式存儲;數據處理過程可以多次進行,其結果文件分別記為其中p為處理次數,表示對表格tn的第i次處理所得的伴隨文件;對應于表格tn的一次處理所得的伴隨文件記為中包含兩個字段,狀態字段和item?id字段,其中狀態字段表示該行的處理結果,item?id字段存儲對應的item?id用于校驗;中的第l行與tn中的第l行對應;
11、s2-2:根據處理后的數據構建加載所需的相關輔助文件。
12、步驟s2-1中,數據處理的形式包括利用分類模型對字段內容進行分類,或對tn某行的數據字段內容進行分類,則其對應伴隨文件的內容即為分類結果。
13、數據處理包括數據長度過濾處理,如果tn中d1字段的第l行在合理長度區間內,則第l行中為1,否則為0。
14、步驟s2-2包括以下步驟:
15、s2-2-1:完成數據處理之后,進行查找文件的構建:
16、查找文件記為s1,s2,…,sn,其中sn對應tn,sn中的每一行的信息對應tn中的一個poi;sn的任意一行的信息可以分為以下幾個部分:
17、3)所對應的poi?id;
18、4)該poi對應的在tn中的所有行的查找字符串
19、具體形式如下:
20、poiid\tl1#q1\tl2#q2\t…\tlk#qk\n
21、其中,lk,qk分別以字符串形式表示上述偏移字節數和處理結果;字符\t和#作為分隔符號以方便解析,\n表示換行字符,在文件中即為相鄰兩行的分割位置;
22、s2-2-2:依據查找文件構建映射文件,其中,所述映射文件包括mt,md,mt為文本形式列表文件,該文件的所有行對應了所有sn中的所有行,其中每一行k對應某一個查找文件sn中的一行h,每行有三個字段:poi標識符即poi?id,某個查找文件sn的文件序號n∈[1,n],以及文件sn中某一行的h的起始位置相對于該文件開頭的偏移字節數;
23、md在內容上與mt等價,但為字典形式,其中poi?id作為健,上述文件序號和偏移量為值;
24、在數據加載中,md的作用為根據給定poiid進行加載,mt的作用是在訓練過程中進行隨機讀取;模型訓練中主要利用mt。
25、步驟s2-2-1中,每一個所述查找字符串包括以下兩個部分的字符串形式:
26、3)該行在tn中的起始位置相對于tn文件開頭位置的偏移字節數;
27、4)數據處理過程中的結果;
28、上述操作對所有n個文件均執行一次,得到n個查找文件。
29、步驟s2-2-2中,mt的每一行排除換行字符后保證字節數相等。
30、步驟s3包括以下步驟:
31、s3-1:根據映射文件定位該poi所在的查找文件及其位于該查找文件的位置;
32、s3-2:打開對應的文件sn,將文件指針偏移f個字節,讀取一行,得到對應poi的一組數據;
33、s3-3:根據lk,mk讀取原始文件tn中的數據;
34、s3-4:利用數據處理結果qk根據需求選擇數據利用方式。
35、步驟s3-1具體為,當給定poiid進行加載時利用md,將md加載到內存中,根據poiid找到文件序號n和偏移量f;在訓練過程中進行隨機讀取時,設整個數據集利用的poi數量設為p,則訓練時利用的數據采樣器會生成一組0~p的隨機數,這時加載對應于該隨機數的poi樣本;相當于數據集中的poi被重新編號為0~p;這時利用mt更加高效(無需加載文件mt至內存);由于mt每一行的字節數相等,只要將采樣器生成的隨機數乘以行字節數作為偏移量即可定位到所需數據;設生成的隨機數為r,行字節數為a,首先打開文件mt,將指針偏移r×a讀取一行,即得到字符串形式的文件序號n和偏移量f;
36、步驟s3-2中,所述一組數據為:
37、poiid\tl1#q1\tl2#q2\t…\tlk#qk\n;
38、步驟s3-3具體為,首先打開文件tn,將文件指針偏移lk個字節,然后讀取一行,即可得到數據字段d1,d2。
39、本發明的有益效果有:
40、poi相關數據的處理高效且磁盤和內存占用低;
41、隨機讀取高效,復雜度為o(1),內存占用低;
42、分割為訓練、驗證和測試集的過程高效、計算資源消耗低。
43、本發明針對大規模poi(興趣點)數據在神經網絡訓練中的處理和加載方法,具有顯著的效率和資源利用優勢。首先,它通過精心設計的數據處理流程,實現了對poi數據的高效處理,顯著降低了磁盤和內存的占用。這種方法通過構建輔助文件和映射文件,優化了數據的存儲和訪問方式,從而減少了在數據處理過程中對系統資源的需求。
44、而且,本發明在數據加載階段展現了其卓越的性能。通過利用映射文件,系統能夠以o(1)的時間復雜度實現對數據的隨機讀取,這意味著無論數據集的規模有多大,讀取任意poi數據的時間都保持不變,極大地提升了數據訪問的效率。此外,這種方法還減少了內存占用,因為無需將整個數據集加載到內存中,系統就可以快速定位并讀取所需的數據。
45、此外,本發明在數據集的分割過程中也體現了其高效性。在神經網絡訓練中,通常需要將數據集分割為訓練集、驗證集和測試集。本發明提供了一種高效的分割方案,它在這一過程中消耗的計算資源極低,從而允許研究人員和數據科學家在不同的數據子集上進行模型訓練和評估,而不必擔心資源的大量消耗。
46、綜上所述,本發明的主要優點在于其在處理、加載和分割大規模poi數據時的高效率和低資源占用,這些特性使其成為神經網絡訓練中數據管理的有效工具。
- 還沒有人留言評論。精彩留言會獲得點贊!