一種應用于技術鑒定的基于數據挖掘的輔助系統及方法
本發明屬于數據匹配分析領域,具體來說,特別涉及一種應用于技術鑒定的基于數據挖掘的輔助系統及方法。
背景技術:
1、目前知識產權相關的侵權案件中對于知識產權法官比較頭疼的問題是對于專業技術的判斷和鑒定,實際中只能依靠技術調查官制度去輔助,由于技術調查官團隊規模有限,使得技術鑒定的準確性和效率是一直以來存在的問題;同時由于鑒定數據的多樣性,每個技術鑒定的不同用戶類型,對于不同類型鑒定數據的使用情況是不同的,若不能對使用技術鑒定數據的用戶的數據訪問權限進行控制和優化,不僅使得鑒定數據的安全性和保密性得不到保證,也影響了鑒定數據的利用效率。
技術實現思路
1、針對相關技術中的問題,本發明提出一種應用于技術鑒定的基于數據挖掘的輔助系統及方法,以克服現有相關技術所存在的上述技術問題。
2、為解決上述技術問題,本發明是通過以下技術方案實現的:
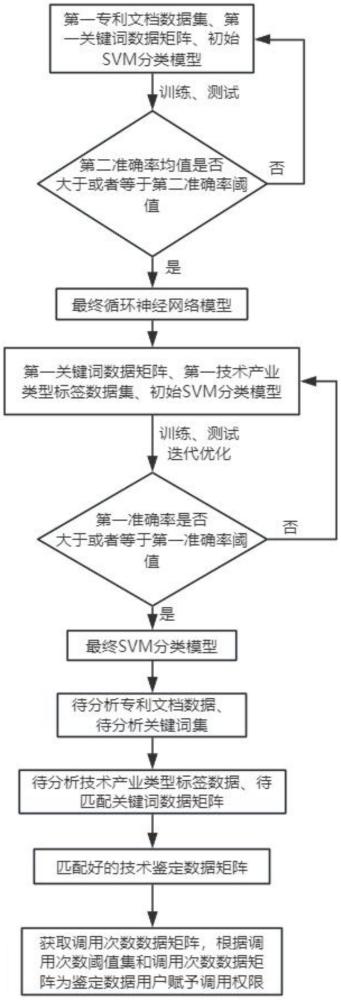
3、本發明為一種應用于技術鑒定的基于數據挖掘的輔助方法,包括以下步驟:
4、s1、采集多份專利文檔數據、對應的關鍵詞數據;采集多種類型技術產業中每個階段的關鍵詞數據以及對應的技術鑒定數據;
5、s2、采用采集到的關鍵詞數據和對應的技術產業類型標簽數據構建最終svm分類模型;采用采集到的專利文檔數據以及關鍵詞數據構建最終循環神經網絡模型;
6、s3、采集待分析的專利文檔數據;采用最終循環神經網絡模型對待分析的專利文檔數據進行關鍵詞提取,得到待分析關鍵詞集;采用最終svm分類模型對編碼后的待分析關鍵詞集進行分類,得到分類結果;根據分類結果獲取對應的技術鑒定數據,得到匹配好的技術鑒定數據矩陣;對存儲匹配好的技術鑒定數據矩陣的數據庫的調用接口進行構建,得到第二數據庫接口集;
7、s4、統計第二數據庫接口集中各個數據庫接口的調用次數;
8、s5、根據各個數據庫接口的調用次數給每個鑒定數據用戶分配調用權限;
9、通過采集多份專利文檔數據、對應的關鍵詞數據,為后續構建用于提取專利文檔數據的關鍵詞的模型提供了訓練數據以及測試數據,同時為后續構建用于根據關鍵詞對專利文檔數據所處的技術產業類型進行判定的模型提供了訓練數據以及測試數據;通過采集多種類型技術產業中每個階段的關鍵詞數據以及對應的技術鑒定數據,用于構建每種專利文檔類型對應的技術鑒定數據的數據庫,便于后續根據專利文檔數據所處的技術產業類型查詢出對應的技術鑒定數據;通過對循環神經網絡模型進行訓練以及測試以構建出最終循環神經網絡模型,使得最終循環神經網絡模型對于專利文檔數據中關鍵詞的提取能力大大增強,從而為后續對待分析的專利文檔數據中的關鍵詞進行提取提供了提取模型;再通過對svm分類模型進行訓練以及測試以構建出最終svm分類模型,使得最終svm分類模型可以根據專利文檔數據的多個關鍵詞對專利文檔數據所在的技術產業進行分類,從而為后續對最終循環神經網絡模型提取出的待分析的專利文檔數據中的關鍵詞進行分類,獲取待分析的專利文檔數據對應的技術產業類型提供了分類模型;由于不同用戶的需求是不相同的,因此本方案中對于根據專利文檔數據對應的技術產業類型查詢出的技術鑒定數據進行分庫存儲,根據不同用戶對這些不同類型的技術鑒定數據的調用次數,來為這些不同的用戶分配不同的權限,從而減少了用戶的無效調用,避免資源被占用,使得調用的效率得到了提高。
10、優選地,所述s1包括以下步驟:
11、s11、采集多份專利文檔數據、對應的關鍵詞數據,得到第一專利文檔數據集a={a1,a2,...,ai,...,aa′}、第一關鍵詞數據矩陣ai表示采集的第i份專利文檔數據,a′表示采集的專利文檔數據的總份數;如下,
12、
13、其中,表示第i份專利文檔數據中的第j個關鍵詞數據,表示第i份專利文檔數據中關鍵詞數據的總個數;
14、s12、采集多種類型技術產業中每個階段的關鍵詞數據以及對應的技術鑒定數據,得到第二關鍵詞數據矩陣c以及第一技術鑒定數據矩陣集d′={d1′,d2′,...,dk′,...,dh″},dk′表示第k種類型的技術鑒定數據矩陣,h′表示采集得到的技術鑒定數據類型的總個數;c和dk′分別如下,
15、
16、其中,cij表示第i種技術產業的第j個階段的關鍵詞數據集,dk′ij表示第k種類型的技術鑒定數據中第i種技術產業的第j個階段的技術鑒定數據集,表示采集的第i種技術產業的階段總個數;cijk、分別表示cij中第k個關鍵詞數據、dk′ij中第k1個技術鑒定數據;d1ij、d2kij分別表示cij中關鍵詞數據的總個數、dk′ij中技術鑒定數據的總個數;
17、s13、將所述第二關鍵詞數據矩陣c以及第一技術文檔數據矩陣d′中按照技術產業的類型分別存儲在多個數據庫中,得到技術產業數據庫集;構建所述技術產業數據庫集中每個技術產業數據庫對應的調用接口,得到第一數據庫接口集表示第i種技術產業對應的數據庫的調用接口;
18、多種類型技術產業包括信息技術、生物技術產業、能源技術產業、先進制造業、環保技術產業、航空航天技術產業、材料科學技術產業、人工智能和機器學習產業、量子計算技術產業、新能源汽車產業、醫療技術產業、農業技術產業等;技術產業的階段包括研究與開發階段、原型開發階段、試驗與驗證階段、產業化階段、成長與成熟階段、飽和與衰退階段、新興技術階段等;通過對多種類型技術產業中每個階段的關鍵詞數據以及對應的技術鑒定數據進行采集,提高了鑒定數據的豐富性,便于后續根據專利文檔數據的技術產業的類型查詢到對應的技術鑒定數據;通過為每種類型的技術鑒定數據的數據庫設置對應的調用接口,從而簡化了調用過程,每個接口對應一種技術產業類型,也提高了調用的準確性。
19、優選地,所述s2包括以下步驟:
20、s21、根據所述第二關鍵詞數據矩陣c、第一技術文檔數據矩陣d′設定第一關鍵詞數據矩陣中每行關鍵詞數據對應的技術產業類型標簽,得到第一技術產業類型標簽數據集表示第一關鍵詞數據矩陣中第i行關鍵詞數據對應的技術產業類型標簽數據;
21、s22、構建初始svm分類模型;所述初始svm分類模型采用的核函數為徑向基核函數;采用所述第一技術產業類型標簽數據集以及第一關鍵詞數據矩陣對初始svm分類模型進行訓練和測試;訓練和測試完成后,得到最終svm分類模型;
22、s23、構建初始循環神經網絡模型;采用所述第一專利文檔數據集a={a1,a2,...,ai,...,aa′}以及第一關鍵詞數據矩陣對初始循環神經網絡模型進行訓練和測試;訓練和測試完成后,得到最終循環神經網絡模型;
23、通過為第一關鍵詞數據矩陣中每行關鍵詞數據設置對應的技術產業類型標簽,從而為后續訓練以及測試svm分類模型提供了標簽數據,使得構建出的最終svm分類模型更加準確。
24、優選地,所述s22包括以下步驟:
25、s221、設定第一訓練數據比例;根據所述第一訓練數據比例對第一技術產業類型標簽數據集以及第一關鍵詞數據矩陣進行數據劃分,得到第一技術產業類型標簽訓練數據集、第一技術產業類型標簽測試數據集、第一關鍵詞訓練數據矩陣以及第一關鍵詞測試數據矩陣;
26、s222、將所述第一關鍵詞訓練數據矩陣以及第一關鍵詞測試數據矩陣中每個關鍵詞數據進行二進制編碼,得到第一關鍵詞訓練編碼數據矩陣和第一關鍵詞測試編碼數據矩陣;
27、s223、設定第一訓練誤差閾值;將所述第一關鍵詞訓練編碼數據矩陣和第一技術產業類型標簽訓練數據集輸入至初始svm分類模型中進行訓練操作;在訓練過程中,當訓練誤差小于所述第一訓練誤差閾值時,停止訓練,得到訓練好的svm分類模型;
28、設定所述訓練好的svm分類模型的軟間隔參數為e1,記為初始軟間隔參數、數據映射方式控制參數為e2,記為初始數據映射方式控制參數;
29、s224、設定第一準確率閾值e1′;將所述第一技術產業類型標簽測試數據集以及第一關鍵詞測試數據矩陣輸入至訓練好的svm分類模型中進行測試;測試完成后,得到第一準確率e′2;
30、當e′2≥e1′時,將所述訓練好的svm分類模型作為最終svm分類模型;否則,對所述訓練好的svm分類模型的初始軟間隔參數e1以及初始數據映射方式控制參數e2進行調整優化,得到最終svm分類模型;
31、當對訓練好的svm分類模型進行測試得到的結果不滿足要求時,通過對訓練好的svm分類模型的軟間隔參數以及數據映射方式控制參數進行優化,使得訓練好的svm分類模型達到測試要求,提高了最終svm分類模型的分類能力。
32、優選地,s224中對所述訓練好的svm分類模型的初始軟間隔參數e1以及初始數據映射方式控制參數e2進行調整優化,得到最終svm分類模型包括以下步驟:
33、s2241、構建鴿子種群表示所述鴿子種群中的第i只鴿子,表示所述鴿子種群的規模;設定所述鴿子種群的最大迭代次數為f1、當前迭代次數為f2以及搜索空間維度為二維;
34、s2242、根據所述初始軟間隔參數e1以及初始數據映射方式控制參數e2隨機生成鴿子種群中每只鴿子的初始位置,得到初始位置集fi′1、fi′2分別表示所述鴿子種群中第i只鴿子初始位置的一維分量和二維分量;fi′1、fi′2的生成公式如下,
35、
36、式中,randi1、randi2分別表示針對fi′1、fi′2生成的隨機數,分別表示初始軟間隔參數e1的取值下限和取值上限;分別表示初始數據映射方式控制參數e2的取值下限和取值上限;
37、s2243、根據所述第一準確率閾值e1′以及第一準確率e′2構建鴿子種群的適應度函數如下,
38、
39、式中,α為正數,表示修正參數;
40、s2244、開始進行迭代操作;每輪迭代過程中采用所述適應度函數計算鴿子種群中每只鴿子的適應度,得到適應度值集;選取所述適應度值集中最大適應度對應的個體位置作為全局最佳位置將每輪迭代過程分為教師階段和學習階段,所述教師階段以及學習階段中根據全局最佳位置對每只鴿子的位置進行更新的公式分別如下,
41、
42、式中,分別表示所述鴿子種群中第i只鴿子在當前輪迭代過程中的位置、第i只鴿子在下一輪迭代過程中的位置以及第j只鴿子在下一輪迭代過程中的位置;g1、g2分別表示在教師階段和學習階段生成的隨機數;分別表示所述鴿子種群中第i只鴿子、第j只鴿子在下一輪迭代過程中的位置的適應度值;β表示是學習因子;表示所述鴿子種群中所有鴿子位置的平均值;
43、s2245、當f2≥f1時,停止迭代操作,得到最終全局最佳位置g′=(g1′,g′2);g1′、g′2分別為最終全局最佳位置中表示軟間隔參數以及數據映射方式控制參數的位置分量;將所述最終全局最佳位置g′=(g1′,g′2)代入到訓練好的svm分類模型中,得到優化后的svm分類模型;
44、將s224中的第一技術產業類型標簽測試數據集以及第一關鍵詞測試數據矩陣輸入至優化后的svm分類模型中進行測試;測試完成后,得到第三準確率e3′;當e3′≥e1′時,將所述優化后的svm分類模型作為最終svm分類模型;否則,返回s2244中繼續進行迭代,直到e3′≥e1′為止,得到最終svm分類模型;
45、鴿群優化算法原理思想相對簡單,所需要設置的參數較少,因此通過采用鴿子優化算法對訓練好的svm分類模型的軟間隔參數以及數據映射方式控制參數進行多次迭代優化,優化的效率較高且優化過程簡潔;且在鴿群優化算法中融入了教與學算法的思想以對鴿群優化算法進行改進,更進一步提高了鴿群優化算法的收斂速度,即提高了最優軟間隔參數以及數據映射方式控制參數的搜尋速度。
46、優選地,所述s23包括以下步驟:
47、s231、設定第二訓練數據比例;根據所述第二訓練數據比例對第一專利文檔數據集a={a1,a2,...,ai,...,aa′}以及第一關鍵詞數據矩陣進行數據劃分,得到第一專利文檔訓練數據集、第一專利文檔測試數據集、第二關鍵詞訓練數據矩陣以及第二關鍵詞測試數據矩陣;
48、s232、設定第二訓練誤差閾值;將所述第一專利文檔訓練數據集和第二關鍵詞訓練數據矩陣輸入至初始循環神經網絡模型進行訓練操作;在訓練過程中,當訓練誤差小于所述第二訓練誤差閾值時,停止訓練,得到訓練好的循環神經網絡模型;
49、s233、設定第二準確率閾值;將所述第一專利文檔測試數據集和第二關鍵詞測試數據矩陣輸入至訓練好的循環神經網絡模型中進行測試操作;測試完成后,得到第二準確率數據集表示訓練好的循環神經網絡模型對第一專利文檔測試數據集中的第i個專利文檔測試數據進行關鍵詞提取的準確率,表示所述第一專利文檔測試數據集中專利文檔測試數據的總個數;
50、計算所述第二準確率數據集中每個準確率數據的平均值,得到第二準確率均值;當所述第二準確率均值大于或者等于第二準確率閾值時,將所述訓練好的循環神經網絡模型作為最終循環神經網絡模型;否則,返回s13對所述訓練好的循環神經網絡模型繼續進行訓練,直到當所述第二準確率均值大于或者等于第二準確率閾值為止,得到最終循環神經網絡模型;
51、當對訓練好的循環神經網絡模型進行測試完成后,通過比對訓練好的循環神經網絡模型提取出的關鍵詞數據和實際的關鍵詞數據,從而得到訓練好的循環神經網絡模型對專利文檔數據進行關鍵詞提取的準確性,進而提高了后續對待分析的專利文檔數據進行關鍵詞提取的準確性。
52、優選地,所述s3包括以下步驟:
53、s31、采集待分析專利文檔數據;采用所述最終循環神經網絡模型對待分析專利文檔數據中的關鍵詞進行提取,得到待分析關鍵詞集表示從所述待分析專利文檔數據提取出的第i個關鍵詞;表示從所述待分析專利文檔數據提取出的關鍵詞的總個數;
54、s32、對所述待分析關鍵詞集中的每個關鍵詞進行二進制編碼,得到待分析編碼關鍵詞集表示對從所述待分析專利文檔數據提取出的第i個關鍵詞進行編碼得到的編碼關鍵詞;
55、s33、采用所述最終svm分類模型對待分析編碼關鍵詞集進行分類操作,得到待分析技術產業類型標簽數據;
56、根據所述待分析技術產業類型標簽數據從第一數據庫接口集中選定對應技術產業數據庫的調用接口進行調用,得到待匹配關鍵詞數據矩陣c′;如下,
57、
58、其中,ci′j表示待分析技術產業類型標簽數據對應的技術產業中的第i個階段的第j個關鍵詞數據;hi表示待分析技術產業類型標簽數據對應的技術產業中的第i個階段中關鍵詞數據的總個數;b表示待分析技術產業類型標簽數據對應的技術產業中階段的總個數;
59、s34、將所述待分析關鍵詞集分別與待匹配關鍵詞數據矩陣c′中每行的關鍵詞數據進行相似度計算,得到匹配關鍵詞相似度數據集表示所述待分析關鍵詞集與待匹配關鍵詞數據矩陣c′中第i行關鍵詞數據的相似度;
60、s35、根據所述匹配關鍵詞相似度數據集中最大相似度值對應的技術產業類型的階段從第一技術鑒定數據矩陣集d′={d1′,d2′,...,dk′,...,dh″}選取對應的技術鑒定數據,得到匹配好的技術鑒定數據矩陣如下,
61、
62、其中,表示匹配得到技術產業類型階段的第i種類型的技術鑒定數據集中第j個技術鑒定數據;li表示匹配得到技術產業類型階段的第i種類型的技術鑒定數據集中技術鑒定數據的總個數;
63、將所述匹配好的技術鑒定數據矩陣按照類型分別存儲進多個數據庫中,對存儲有匹配好的技術鑒定數據的多個數據庫分別構建對應的調用接口,得到第二數據庫接口集l′={l1′,l2′,...,li′,...,lh″},li′表示存儲有第i種類型的技術鑒定數據的數據庫的調用接口;
64、通過采用最終循環神經網絡模型對待分析專利文檔數據中的關鍵詞進行提取,再采用最終svm分類模型對待分析專利文檔數據的關鍵詞進行分類,獲取到對應的技術產業類型標簽數據,從而為后續對技術鑒定數據進行查詢提供了查詢依據;從而減少了對比次數,提高了數據匹配效率;當將對應的技術鑒定數據查詢到之后,對查詢到的技術鑒定數據進行分類存儲,從而為后續不同類型的使用用戶對這些不同類型的技術鑒定數據賦予不同的調用權限提供了技術基礎。
65、優選地,所述s4包括以下步驟:
66、s41、設定用戶類型集以及數據庫角色類型集和分別表示設定的第i個用戶類型以及第i個數據庫角色類型;
67、表示設定的用戶類型以及數據庫角色類型的總個數;
68、分別設定所述用戶類型集中每個用戶類型對應的鑒定數據用戶,得到鑒定數據用戶集表示設定的第i個用戶類型對應的鑒定數據用戶;
69、s42、設定統計周期;預先賦予所述數據庫角色類型集中每個數據庫角色類型能訪問所有數據的權限并將數據庫角色類型集中每個數據庫角色類型分別給鑒定數據用戶集中的每個鑒定數據用戶進行使用;
70、在所述第二數據庫接口集l′={l1′,l2′,...,li′,...,lh″}中每個數據庫接口中添加調用次數計數器代碼塊;當使用的時間達到統計周期時,根據所述調用次數計數器代碼塊分別統計每個鑒定數據用戶調用第二數據庫接口集l′={l1′,l2′,...,li′,...,lh″}中每個數據庫接口的次數,得到調用次數數據矩陣m;如下,
71、
72、其中,mij表示第i個鑒定數據用戶調用第二數據庫接口集l′={l1′,l2′,...,li′,...,lh″}中第j個數據庫接口的次數;
73、用戶對技術鑒定數據的調用次數可以直接反映出這些用戶對不同類型的技術鑒定數據的需求程度;因此通過采集用戶對技術鑒定數據的調用次數,為后續根據這些調用次數對用戶的調用權限進行分配提供了數據依據。
74、優選地,所述s5包括以下步驟:
75、s51、設定所述第二數據庫接口集l′={l1′,l2′,...,li′,...,lh″}中的每個數據庫接口的調用次數閾值,得到調用次數閾值集m′={m1′,m′2,...,mi′,...,m′h′},mi′表示對所述第二數據庫接口集l′={l1′,l2′,...,li′,...,lh″}中第i個數據庫接口的調用次數閾值;
76、s52、將所述調用次數數據矩陣m中的每行數據分別與調用次數閾值集m′={m1′,m′2,...,mi′,...,m′h′}進行對比;當調用次數大于或者等于對應的調用次數閾值時,則將對應的數據庫接口的調用權限賦予對應的鑒定數據用戶使用的數據庫角色類型;
77、根據用戶對不同類型的技術鑒定數據的調用次數來為每種類型的用戶分配不同的調用權限,使得分配權限的過程更加準確和科學。
78、一種應用于技術鑒定的基于數據挖掘的輔助系統,包括第一專利數據采集模塊、技術產業數據采集模塊、svm分類模型構建模塊、循環神經網絡模型構建模塊、第二專利數據采集模塊、關鍵詞提取模塊、關鍵詞分類模塊、技術鑒定數據匹配模塊、第二調用接口構建模塊、調用次數統計模塊和權限分配模塊;
79、所述第一專利數據采集模塊用于采集多份專利文檔數據、對應的關鍵詞數據;
80、所述技術產業數據采集模塊用于采集多種類型技術產業中每個階段的關鍵詞數據以及對應的技術鑒定數據;
81、所述svm分類模型構建模塊用于采用采集到的關鍵詞數據和對應的技術產業類型標簽數據構建最終svm分類模型;
82、所述循環神經網絡模型構建模塊用于采用采集到的專利文檔數據以及關鍵詞數據構建最終循環神經網絡模型;
83、所述第二專利數據采集模塊用于采集待分析的專利文檔數據;
84、所述關鍵詞提取模塊用于采用最終循環神經網絡模型對待分析的專利文檔數據進行關鍵詞提取,得到待分析關鍵詞集;
85、所述關鍵詞分類模塊用于采用最終svm分類模型對編碼后的待分析關鍵詞集進行分類,得到分類結果;
86、所述技術鑒定數據匹配模塊用于根據分類結果獲取對應的技術鑒定數據,得到匹配好的技術鑒定數據矩陣;
87、所述第二調用接口構建模塊用于對存儲匹配好的技術鑒定數據矩陣的數據庫的調用接口進行構建,得到第二數據庫接口集;
88、所述調用次數統計模塊用于統計第二數據庫接口集中各個數據庫接口的調用次數;
89、所述權限分配模塊用于根據各個數據庫接口的調用次數給每個鑒定數據用戶分配調用權限。
90、本發明具有以下有益效果:
91、1.本發明中通過采集多種類型技術產業中每個階段的關鍵詞數據以及對應的技術鑒定數據,便于后續根據專利文檔數據所處的技術產業類型查詢出對應的技術鑒定數據;通過構建最終循環神經網絡模型,為后續對待分析的專利文檔數據中的關鍵詞進行提取提供了模型;通過構建最終svm分類模型,為后續對最終循環神經網絡模型提取出的待分析的專利文檔數據中的關鍵詞進行分類提供了分類模型;同時對查詢出的技術鑒定數據進行分庫存儲以及根據不同用戶對這些不同類型的技術鑒定數據的調用次數,來為這些不同的用戶分配不同的權限,避免了資源被占用,使得調用的效率得到了提高;通過進行數據匹配,使得技術鑒定人員可以方便且準確的獲取對應的技術鑒定數據,提高了鑒定效率。
92、2.本發明中通過采用鴿子優化算法對訓練好的svm分類模型的軟間隔參數以及數據映射方式控制參數進行多次迭代優化,優化的效率較高且優化過程簡潔;且在鴿群優化算法中融入了教與學算法的思想以對鴿群優化算法進行改進,更進一步提高了鴿群優化算法的收斂速度。
93、3.本發明中根據用戶對不同類型的技術鑒定數據的調用次數來為每種類型的用戶分配不同的調用權限,使得分配權限的過程更加準確和科學。
94、當然,實施本發明的任一產品并不一定需要同時達到以上所述的所有優點。
- 還沒有人留言評論。精彩留言會獲得點贊!