一種基于多模態的文本摘要生成方法與流程
本發明涉及數據處理,具體涉及一種基于多模態的文本摘要生成方法。
背景技術:
1、多模態檢索方法是一種結合不同模態(如圖像、文本、音頻等)信息來進行檢索任務的方法,?隨著互聯網和數字媒體的快速發展,大量的多模態數據被創造和分享。不同模態的信息可以提供互補的視角和豐富的語義信息,通過綜合利用多模態的信息可以獲得更全面、準確的檢索結果,滿足用戶不同的需求。
2、現有的多模態檢索方法在進行特征融合時,通常只是簡單地將不同模態的特征進行拼接或加權。這種簡單的融合方法可能無法充分利用不同模態之間的相關性和互補性。并且通常采用簡單的相似度計算方法,如余弦相似度或歐氏距離。這些方法可能無法很好地適應不同模態之間的特點和差異。現有的多模態檢索方法同樣在用戶交互和展示方面可能存在一些不足,無法滿足用戶的需求和期望。例如,用戶可能希望通過點擊圖像放大或播放音頻文件等方式與數據進行交互,但現有方法可能無法提供這樣的功能。
技術實現思路
1、本發明的目的在于提供一種基于多模態的文本摘要生成方法,解決以下技術問題:
2、現有的多模態檢索方法特征融合不充分、相似度計算方式不夠靈活、用戶交互和展示不夠友好。
3、本發明的目的可以通過以下技術方案實現:
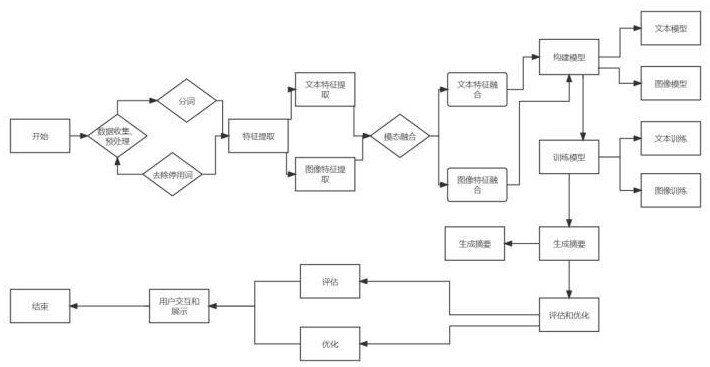
4、一種基于多模態的文本摘要生成方法,包括以下步驟:
5、采集圖像數據和文本數據,并分別進行預處理,圖像數據預處理包括去噪、縮放、tf-idf、歸一化;文本數據預處理包括分詞、去除停用詞、詞干化;
6、基于卷積神經網絡提取圖像的視覺特征,卷積神經網絡通過卷積操作提取圖像的局部特征,通過池化操作進行特征減采樣,通過全連接層進行特征分類或回歸;
7、使用自然語言處理技術對文本數據進行特征提取,通過詞袋模型、tf-idf獲取文本的語義特征,所述語義特征包括詞頻和逆文檔頻率;
8、將圖像和文本的特征進行融合,得到一個綜合的多模態特征向量;融合方法包括簡單拼接、加權融合、mlp模態融合;
9、基于transformer網絡構建文本生成模型,以將多模態特征向量作為輸入,生成摘要文本;
10、使用rouge評估指標對生成的摘要文本進行評估;根據評估結果,對模型進行優化。
11、作為本發明進一步的方案:所述去噪基于高斯濾波器:g(x,?y)?=?(1?/?(2πσ2))*?exp(-(x2?+?y2)?/?(2σ2)),其中,g(x,?y)表示濾波器在坐標(x,?y)處的值,σ表示高斯核的標準差;
12、所述縮放將圖像調整到設定的尺寸,公式為:
13、scaled_x?=?x?*?(width_new?/?width_orig);
14、scaled_y?=?y?*?(height_new?/?height_orig);
15、其中,scaled_x和scaled_y表示縮放后圖像中坐標(x,?y)處的像素位置,width_orig和height_orig表示原始圖像的寬度和高度,width_new和height_new表示縮放后圖像的寬度和高度;
16、所述tf-idf:
17、tf(t,?d)?=?(number?of?times?term?t?appears?in?document?d)?/?(totalnumber?of?terms?in?document?d);
18、??idf(t)?=?log(n?/?(number?of?documents?containing?term?t));
19、??tf-idf(t,?d)?=?tf(t,?d)?*?idf(t);
20、?其中,tf(t,?d)表示詞t在文檔d中的詞頻,idf(t)表示詞t的逆文檔頻率,n表示文檔總數;
21、所述歸一化為將圖像中任一點的像素值除以圖像像素值的最大值。
22、作為本發明進一步的方案:所述分詞包括基于規則的分詞或基于統計的分詞;
23、所述去除停用詞使用預先定義的停用詞列表過濾文本中的常見詞語;
24、所述詞干化將單詞轉化為原始形式。
25、作為本發明進一步的方案:所述卷積操作將濾波器與輸入數據的小區域進行逐元素相乘,再求和得到卷積結果,卷積操作用于計算輸入數據與濾波器之間的相似程度;
26、基于激活函數對卷積結果進行非線性的映射,基于relu函數,公式為f(x)?=?max(0,?x);
27、所述池化操作通過取窗口內的最大值或平均值來減小特征圖的尺寸;
28、所述全連接層將池化層輸出的特征向量連接成一個向量,通過全連接層進行分類或回歸等任務。
29、作為本發明進一步的方案:所述詞袋模型將文本表示成一個由文本中所有單詞組成的集合,忽略單詞的順序和語法,只關注文本中單詞的出現頻率;收集文本數據中的所有單詞,并為每個單詞分配一個唯一的索引;對于每個文本,統計每個單詞在文本中的出現次數,形成一個詞頻向量;每個向量的維度等于字典中單詞的數量;
30、所述tf-idf包括計算文本的詞頻tf以及該文本在整個文本集中的逆文檔頻率idf;詞頻tf表示單詞在當前文本中的頻率,逆文檔頻率idf表示一個單詞在整個文本集中的重要程度,通過文本集中所有文本數目除以包含該單詞的文本數目的對數計算;將詞頻與逆文檔頻率相乘,得到每個單詞在當前文本中的tf-idf值;每個文本都可以通過tf-idf值構成一個稀疏的詞袋向量,其中每個維度對應一個單詞的tf-idf值。
31、作為本發明進一步的方案:特征融合的過程為:
32、所述簡單拼接將圖像特征向量和文本特征向量按照一定的順序直接拼接在一起,形成一個綜合的多模態特征向量;
33、所述加權融合為不同模態的特征賦予不同的權重,通過權重調節對不同模態的特征進行強調或降低重要性;所述權重基于先驗知識或通過學習獲得;
34、所述mlp模態融合使用多層感知機前饋神經網絡模型來學習圖像和文本特征之間的關聯性,將圖像特征和文本特征分別作為輸入層,然后通過隱藏層和輸出層進行融合和分類。
35、作為本發明進一步的方案:評估的過程為:
36、準備包含原始文本和生成的摘要文本的測試集,所述rouge評估指標包括rouge-n、rouge-l和rouge-s;
37、對于rouge-n,計算生成摘要和參考摘要之間的n-gram重疊數,計算出兩者的n-gram重疊數后,計算出精確率p和召回率r,然后計算f1分數作為rouge-n分數;
38、對于rouge-l,計算生成摘要和參考摘要之間的最長公共子序列的長度;根據最長公共子序列長度計算出精確率和召回率,然后計算f1分數作為rouge-l分數;
39、對于rouge-s,計算生成摘要和參考摘要之間的連續片段重疊度;根據連續片段重疊度計算出精確率和召回率,然后計算f1分數作為rouge-s分數。
40、本發明的有益效果:
41、(1)本發明基于多模態的文本摘要生成方法可以綜合利用圖像和文本的特征,通過特征提取和表示學習,獲取豐富的語義和視覺信息;相比于傳統的多模態檢索方法,它可以更準確、精細地提取和表達多模態數據中的關鍵信息;
42、(2)本發明基于多模態的文本摘要生成方法可以根據用戶的輸入和需求生成個性化的摘要文本;通過用戶交互和展示模塊,用戶可以輸入查詢圖片和文本,系統根據輸入生成對應的摘要文本;這使得用戶可以根據自己的需要來定制和獲取感興趣的信息;
43、(3)本發明基于多模態的文本摘要生成方法不僅提供了更全面、準確的信息摘要,還可以通過多模態的展示方式,如圖像、文本等形式進行展示,提供更豐富的用戶體驗;用戶可以通過點擊摘要文本獲取詳細信息,并與生成的摘要文本進行交互,如加入評論或修改摘要內容;
44、(4)本發明基于多模態的文本摘要生成方法使用了適當的文本生成模型,如循環神經網絡(rnn)或transformer模型,可以通過訓練數據學習生成摘要的語言模式和語義信息,并生成具有一定準確度和流暢度的摘要文本;相比于傳統的多模態檢索方法,它可以產生更高質量的摘要文本;
45、(5)本發明基于多模態的文本摘要生成方法相較于傳統的多模態檢索方法具有更精細化的信息提取、個性化的摘要生成、提高的用戶體驗和更高質量的摘要生成等優點;通過綜合利用圖像和文本的特征,并結合合適的模型和評估方法,可以生成具有準確度和流暢度的多模態摘要文本,提高文本摘要生成的效果和用戶滿意度。
- 還沒有人留言評論。精彩留言會獲得點贊!