一種基于虛擬樣本生成和多輸出神經網絡模型的錫冶煉過程能耗預測方法
本發明涉及生產過程能耗預測,具體涉及一種基于虛擬樣本生成和多輸出神經網絡模型的錫冶煉過程能耗預測方法。
背景技術:
1、隨著經濟發展進入新常態,錫冶煉作為典型的“三高一資”行業,是節能減排的重點對象,預測錫冶煉過程能耗在節能降耗方面有著重要作用,通過建立能耗預測模型可以了解錫冶煉過程的能耗使用規律,模型預測出的值也為錫生產計劃提供了重要的參考信息。關于生產過程的能耗預測模型可分為機理建模、投入產出法、時間序列預測、回歸預測和人工智能模型。其中,機理建模是根據生產過程的內部機制建立精確的數學模型;投入產出法以系統的觀點分析流程工業中每個工序之間的投入產出平衡,反映了各工序之間相互影響的關系;時間序列預測法需要的輸入變量只有能耗自身,因此模型的計算也相對比較簡單;回歸預測方法通過輸入相關歷史變量數據,挖掘輸入變量與能耗數據之間的變化規律和量化關系,建立回歸預測模型計算得到未來的能耗數值,如:多元回歸分析、邏輯回歸、線性回歸、多項式回歸等模型。人工智能算法被引入導生產過程能耗預測領域當中,常用的模型有支持向量機、人工神經網絡,決策樹等。
2、面對錫冶煉過程中高溫、強粉塵等復雜環境下,從現場采集到的過程數據無法直接用于預測模型的構建。過程數據的采集和記錄往往存在缺失值、異常值;不同工序所采集的數據還存在量綱和周期的差異。冶煉過程數據不僅在數量上存在不足,還存在數據信息的不完整,導致傳統的能耗預測模型預測精度低,模型泛化能力差。因此,預測錫冶煉過程的能耗對錫行業的持續發展和環境的健康發展具有重要意義。
技術實現思路
1、為了解決現有技術中存在的以上問題,本發明提出了一種基于虛擬樣本生成和多輸出神經網絡模型的錫冶煉過程能耗預測方法,以解決小樣本數據下模型預測精度低的問題,通過采用虛擬樣本生成技術方法解決數據數量不足,數據信息不完整等問題,從而提高小樣本數據集下錫生產能耗預測效果。
2、為實現上述目的,本發明的技術方案如下:
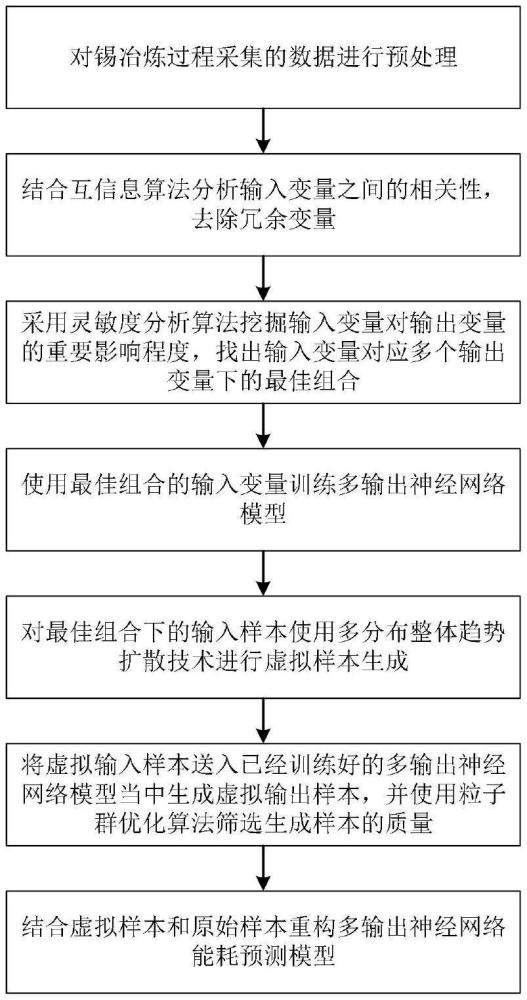
3、s1、收集錫冶煉過程中的歷史數據并進行預處理,所述歷史數據包括:能源消耗類型和能耗影響因素;
4、所述能源消耗類型包括:錫冶煉過程總的電耗、錫冶煉過程總的煤耗、錫冶煉過程總的水耗、錫冶煉過程總的天然氣消耗、錫冶煉過程總的氧氣消耗;
5、所述能耗影響因素包括:焙燒工序壓縮空氣、焙燒工序焙砂、焙燒工序進風速度、焙燒工序進風壓力、澳爐熔煉工序壓縮空氣、澳爐熔煉工序爐內壓力、澳爐熔煉工序粗錫、澳爐熔煉工序進風速度、澳爐熔煉工序進風壓力、澳爐熔煉工序爐渣溫度、精煉工序壓縮空氣、精煉工序焊錫、精煉工序進風速度、精煉工序進風壓力、精煉工序錫錠、精煉工序炭渣、精煉工序鋁渣、余熱回收工序煙氣壓力、余熱回收工序煙氣溫度、冶煉總錫錠;
6、所述預處理具體步驟如下所示:
7、s1.1、對缺失數據使用自回歸移動平均arima模型進行填補,具體表達式如下所示:
8、
9、式中:xt-i表示時間t-i時刻的值;c表示常數項;p表示自回歸階數,φi表示自回歸系數,et表示噪聲;
10、s1.2、采用拉依達準則進行異常值檢測并將其剔除;
11、在拉依達準則下,異常值如果超過3倍標準差,那么可以將其視為異常值,拉依達準則為:
12、1、數值分布在(μ-σ,μ+σ)中的概率為0.6827;
13、2、數值分布在(μ-2σ,μ+2σ)中的概率為0.9545;
14、3、數值分布在(μ-3σ,μ+3σ)中的概率為0.9973;
15、式中:μ表示均值,σ表示方差;
16、可以看出,數值的取值范圍幾乎全部集中在(μ-3σ,μ+3σ)區間內,超出這個范圍的值視為異常值;
17、s1.3、使用歸一化算法消除變量之間的量綱差異,其具體公式如下所示:
18、
19、式中,xmin表示數據最小值,xmax表示數據最大值,x表示缺失值填充和異常值檢測之后的數據。
20、s2、采用互信息算法分析步驟s1預處理后的歷史數據之間的相關性,去除冗余的影響因素;
21、由互信息算法計算不同輸入變量之間的相關性,對于相關性高于0.8的變量,可視為冗余,需要剔除冗余變量,互信息算法具體計算公式如下:
22、
23、式中,p(x,y)表示聯合概率密度,p(x),p(y)分別表示變量x與變量y的條件概率。
24、s3、將能耗影響因素設置為輸入變量、能源消耗類型設置為輸出變量,對輸入變量與輸出變量之間進行靈敏度分析,剔除靈敏度值低于0.1的輸入變量,并找出一組最能影響輸出變量變化的輸入變量組合,所述靈敏度分析具體計算公式如下:
25、
26、式中,xk,i表示輸入值,表示輸入的平均值,yi表示第i個數據點的輸出值,表示輸出的平均值,n表示數據點的數量,r表示靈敏度系數。
27、s4、將s2中預處理好的歷史數據按8:2劃分訓練集與測試集,選擇多輸出多層感知機為模型框架,以均方根誤差為損失函數,構建多輸出神經網絡模型,并使用訓練集進行模型訓練,使用優化器adam來最小化損失函數,在每個訓練周期(epoch)之后,使用測試集評估模型性能,防止模型過擬合。
28、s5、采用多分布整體趨勢擴散技術對s3得出的輸入變量組合進行虛擬樣本生成,將生成的虛擬輸入樣本送入s4中由訓練集訓練、測試集評估后,具備準確預測新數據能力的多輸出神經網絡模型,并將多輸出神經網絡模作為映射模型,由映射模型生成虛擬輸出樣本,并采用粒子群優化算法對生成的虛擬輸入與輸出樣本進行質量篩選;
29、所述虛擬樣本生成包括:采用多分布整體趨勢擴散技術進行虛擬輸入樣本的生成、將多輸出神經網絡模型作為虛擬輸出樣本的映射模型,再結合粒子群優化算法,采用平均百分比誤差小于10%作為適應度函數進行虛擬輸入與輸出樣本的質量篩選;
30、所述多分布整體趨勢擴散技術實現步驟如下:
31、s5.1、計算每個變量數據的中心值m,具體表達式如下:
32、m=median(xi)
33、式中,xi表示第i個變量;
34、s5.2、計算每個變量數據的左偏度sleft與右偏度sright,具體表達式如下:
35、
36、式中,nleft表示小于最小值的樣本數;nright表示大于中心值的樣本數;
37、s5.3、確定可擴展域的上界rb和下屆lb,具體表達式如下:
38、
39、式中,m表示數據的中心值,sleft和sright分別表示數據的左右偏度,表示第i個變量的方差,nleft表示小于最小值的樣本數;nright表示大于中心值的樣本數;
40、s5.4、在不同區間生成虛擬樣本xm,在區間[lb,min]生成的虛擬樣本為:
41、xm=lb+s(min-lb)
42、在區間[min,max]生成的虛擬樣本xm為:
43、
44、在區間[max,rb]生成的虛擬樣本xm為:
45、xm=max+s(rb-max)
46、式中,s為服從正態分布的隨機數;
47、s5.5、通過粒子群優化算法篩選虛擬樣本質量,其具體表達式如下所示:
48、
49、式中,y為輸出值,表示模型預測的輸出值。
50、s6、結合s5生成的虛擬輸入、輸出樣本和s2預處理后歷史數據,重新劃分訓練集與測試集,進一步對模型加以訓練,并進行模型預測性能評估;
51、在s2預處理后的歷史數據的基礎上加入粒子群優化算法篩選出的虛擬輸入與輸出樣本,通過模型實驗,即每次增加10組虛擬樣本觀察模型預測性能的變化,進而確定所需的虛擬輸入與輸出樣本數量,基于混合樣本對錫冶煉過程能耗進行預測,其中,模型性能評估的指標包括:決定系數、均方根誤差、平均誤差;
52、所述決定系數(r2)、均方根誤差(rmse)、平均誤差(mae),具體表達式如下:
53、
54、式中,m表示樣本總數,yi和分別表示測量值與預測值,表示測量值的平均值,其中決定系數(r2)、均方根誤差(rmse)、平均誤差(mae)最終得出的值越小越好。
55、本發明的有益效果
56、1、本發明的基于虛擬樣本生成和多輸出神經網絡模型的錫冶煉過程能耗預測方法,通過相關性分析和靈敏度分析,可以挖掘多輸出情況下最佳組合的輸入變量。
57、2、本發明的基于虛擬樣本生成和多輸出神經網絡模型的錫冶煉過程能耗預測方法,引入虛擬樣本生成技術實現了小樣本數據的有效擴充,提高了預測模型的魯棒性。
- 還沒有人留言評論。精彩留言會獲得點贊!