基于條件生成對抗網絡的平均場多智能體強化學習方法與流程
本發明涉及人工智能,尤其涉及基于條件生成對抗網絡的平均場多智能體強化學習方法。
背景技術:
1、近年來,多智能體強化學習(multi-agentreinforcementlearning,marl)作為人工智能領域的一個重要分支,因其可以很好的幫助含有多個智能體的集群在復雜的環境中進行決策以完成任務而受到越來越多的關注。目前,marl已經在多個領域取得了顯著的成果,例如智能交通系統、無人機編隊控制、多智能體協作游戲等。盡管如此,marl仍然存在一些挑戰和局限性。這是因為隨著智能體數量增多,狀態空間和動作空間的維度急劇增加,進而導致了分析和計算上的復雜性提高。目前比較好的解決方案是可以借助平均場對其進行化簡。合作型多智能體強化學習在達到帕累托最優狀態時,能由可學習的平均場控制(mean-fieldcontrol,mfc)近似。在mfc中,只需要關注一個代表智能體,而系統動態則通過所有智能體的狀態分布來描述。雖然mfc可以有效解決多智能體系統中的維度爆炸問題,但是仍然存在不少突出的問題。
2、首先,在強化學習訓練的初始階段,需要對環境進行全面探索。這一過程中往往伴隨著大量無效動作的產生,這不僅會加劇系統資源的消耗。而且當這種探索過程應用于現實場景時,可能引發諸如碰撞、墜機等不可逆轉的嚴重后果。其次,為了減少潛在損失,通常會先在虛擬仿真環境中對模型進行充分的訓練,直至其性能達到穩定狀態。但是當現實場景與虛擬訓練環境之間存在顯著差異,或者訓練的模型不夠精確存在較大誤差時,算法可能不再適用。基于模型的強化學習算法(model-based?reinforcement?learning,mbrl)可以有效解決上述問題。在mbrl中,智能體首先通過與環境的交互收集數據,通過挖掘數據之間的內在關系構建出相應的環境模型。隨后,智能體可以直接與學習到的環境模型交互產生虛擬樣本數據,從而實現策略優化或規劃。由此可見,一旦成功學習到了環境模型,智能體便能夠直接與其進行交互,實現對下一狀態的預測,從而避免了與真實環境直接交互所帶來的潛在風險。這不僅能夠防止因策略不當導致的不可逆后果,還顯著提高了樣本數據的利用效率。
3、此外,一個訓練得當的環境模型通常擁有穩定的內部系統模型。當應用場景發生變化時,這一內部模型能夠保持穩定,意味著智能體無需重新收集大量樣本進行訓練,即可快速適應新的環境。這種特性顯著增強了算法的適應性和效率,使其在多種應用場景中展現出優越的性能。
4、《efficientmodel-basedmulti-agentmean-fieldreinforcementlearning》一文中提到的基于平均場模型的多智能體強化學習算法(model-based?multi-agentmean-field?upper-confidence?rl?algorithm,m3-ucrl)將mfc與mbrl進行有效結合。在動態環境未知的情況下利用mfc簡化系統模型以解決維度爆炸問題;同時利用上置信邊界(upperconfidencebound,ucb)算法將環境模型作為一個附加策略與智能體的任務策略一起進行優化,有效解決訓練初期樣本利用率低的問題。但是該算法建立環境模型的方式不僅增加了分析的復雜度,而且給系統增加了額外的開銷。此外,在具體實現時依舊采用高斯過程或者神經網絡對環境模型進行建模,精確度難以保障。隨著實際任務場景的日漸復雜,多智能系統中建立的環境動力學模型的精準度也難以保證。
5、貝葉斯方法是在建立環境模型方法中發展比較成熟的。它通過引入先驗知識和后驗推理,構建概率動力學模型來實現對模型中的不確定性進行量化和建模,從而提高其預測和決策的準確性。應用最廣泛的貝葉斯方法有基于核的高斯過程,其中deisenroth等人提出的學習控制的概率推理方法(pilco)是該領域最經典的方法之一,但是在處理高維空間的場景問題時,就顯得力不從心了。為了克服這一問題,gal等人提出了貝葉斯網絡,使得pilco方法也可以有效解決具有復雜高維空間的應用問題。
6、另一方面,goodfellow在2014年提出了生成對抗網絡(generativeadversarialnetworks,gan),通過對現有的數據樣本進行學習并發現其內部規律從而生成新的數據。該生成模型由生成器(generator,g)和判別器(discriminator,d)組成。生成器g旨在生成逼真的數據樣本,而判別器d則旨在區分生成器生成的假樣本和真實數據樣本。二者通過對抗訓練相互競爭,逐漸達到納什均衡。最終,生成器可以生成非常逼真的數據樣本,而判別器也會變得更難以分辨真假。在此基礎上,為了讓網絡朝著特定方向改進,生成滿足某種條件的數據樣本,mehdimirza提出了生成對抗網絡的一種擴展形式:條件生成對抗網絡(conditional?generativeadversarialnetworks,cgan)。通過在生成器g和判別器d的輸入中增加額外的條件信息,cgan可以實現更加精細的控制,使得生成器g可以根據條件信息生成特定類別的樣本。在此模型中,判別器d不僅需要判斷輸入數據的真假,還要會判斷數據是否符合限定條件。cgan的訓練目標是最小化生成器g生成的假樣本被判別器d判定為假的概率,同時最大化判別器d正確判定真實樣本和生成樣本的概率。通過這種對抗訓練方式,生成器g和判別器d可以相互競爭學習,最終生成器g可以生成逼真的、符合條件信息的樣本。
7、本發明利用cgan在數據生成方面的優勢提出一種基于條件生成對抗網絡的平均場多智能體強化學習方法(model-based?multi-agent?mean-field?reinforcementlearning?based?on?conditional?generation?adversarialnetwork,cgan-m3rl)。
技術實現思路
1、針對上述現有技術的缺陷和不足,本發明提出一種基于條件生成對抗網絡的平均場多智能體強化學習方法,采用cgan的對抗訓練機制對多智能體系統的環境進行建模,從而提高建立環境模型的精確度。此外,一旦訓練得到穩定的環境模型,就可以讓智能體與該模型直接進行交互,從而可以獲得大量樣本數據用于后續策略的學習,解決了環境中智能體數量過多、環境復雜多變而導致的環境動力學模型難以精準捕捉造成狀態不穩定的問題。
2、基于條件生成對抗網絡的平均場多智能體強化學習方法,包括如下步驟:
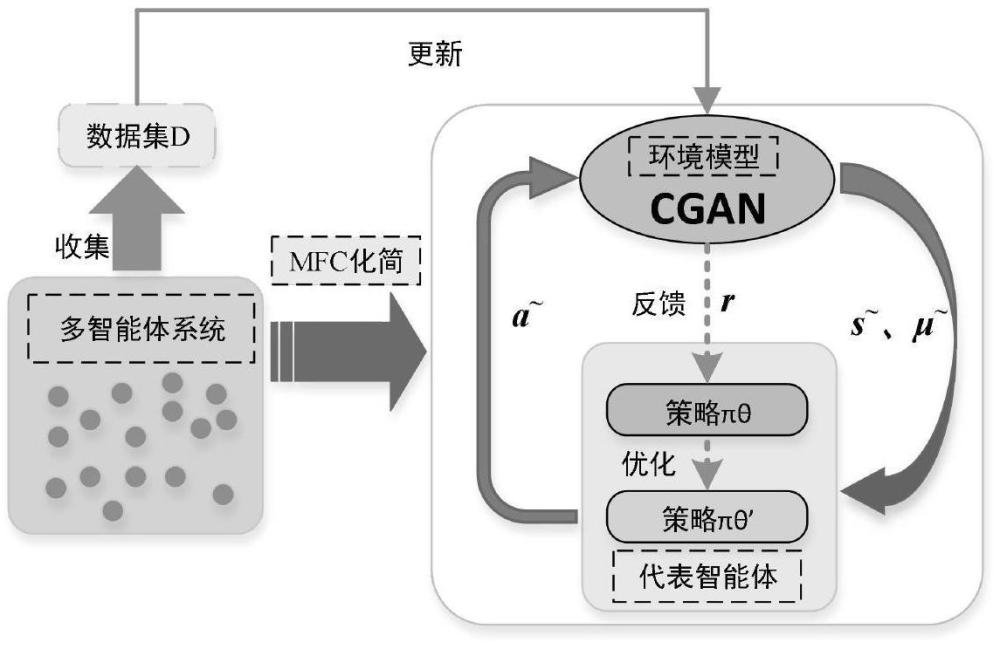
3、步驟1:對未知的動態環境進行建模,智能體采取回合制來執行任務,在每個訓練回合t中,將智能體與真實環境交互的數據收集到數據集dt={((si,h,ai,h,μi,h),si,h+1)},h=0,1,...,h-1,i=1,2,...,t中;
4、步驟2:利用cgan對狀態轉移函數p(st+1|st,at,μt)建模,并用數據集dt中的數據對環境模型進行訓練,直到環境模型收斂;
5、步驟3:讓mfc中的代表智能體直接與穩定后的環境模型p(st+1|st,at,μt)進行交互,獲得大量的樣本序列;
6、步驟4:利用第三步中交互獲得的數據對策略參數進行優化,直到學習到最優策略π*。
7、進一步,所述步驟1的具體過程為:采用cgan創建環境模型,cgan是在生成器g與判別器d的輸入項中增加了一個約束條件變量y,y可以是類別標簽、文本描述、圖像等。
8、cgan的目標函數如下所示:
9、
10、式中,v(d,g)表示損失值;pdata代表真實數據的分布;x是對真實數據分布進行采樣后得到的變量;pz代表隨機噪聲的分布;z代表隨機噪聲變量;y是約束條件變量。
11、進一步,所述步驟2的具體過程為:已知在用mfc化簡的多智能體系統中,將環境模型表示為p(st+1|st,at,μt),它表示著智能體在當前的狀態st與平均場狀態μt下,在當前策略執行動作at后進入下一狀態st+1的概率,可以將其看作為一個條件概率密度模型。而在cgan中,生成器g是對隨機變量z進行映射,同時在約束條件變量y的指導下生成偽造數據即偽造數據服從一個條件概率密度函數因此,可將兩者進行結合,即,在用mfc化簡的多智能體系統中,將當前平均場μt中狀態為st并執行動作at作為限定條件,用來指導cgan生成代表智能體的下一狀態st+1。最終cgan可以學習到強化學習中狀態轉移函數模型p(st+1|st,at,μt)。
12、進一步,所述步驟3的具體過程為:cgan中的生成器g負責捕捉真實數據的分布,學習環境模型,其輸入為隨機變量z與約束條件變量y,其中y由當前平均場μt、狀態st、動作at組成;輸出是在當前條件y下對下一狀態的預測判別器d負責判斷輸入的樣本是真實的數據st+1還是由g生成的數據同時判斷輸入樣本是否符合條件變量y;輸入為g生成的預測狀態與真實狀態st+1,以及與g相同的約束條件變量y;輸出是對輸入樣本真偽的概率。g與d通過對抗訓練相互競爭,逐漸達到納什均衡。此時,智能體可直接與該模型進行交互生成大量軌跡,來用于后續的策略學習。其目標函數表示如下:
13、
14、式中,g代表生成器,實質上代表環境模型p(st+1|st,at,μt);d代表判別器;v(d,g)代表訓練過程中的損失值;(st,at,μt)代表約束條件變量y;z代表隨機噪聲變量。
15、進一步,所述步驟4的具體過程為:將采用cgan訓練穩定后的環境模型記為fψ。在每個回合t,代表智能體根據當前可行策略πt=(πt,0,πt,1,...,πt,h-1)直接與建立好的環境模型fψ交互,對狀態軌跡進行前向模擬;同時根據平均場流動特性對系統的平均場軌跡進行前向模擬。在此期間獲得虛擬樣本數據用來對策略進行學習。則在每個訓練回合t,代表智能體對策略優化可以表示如下:
16、
17、接下來采用基于梯度的方法求解上述優化問題。求解過程包含三步:首先,將策略函數π(·)參數化為πθ;期望累積獎勵j(π)記為j(θ);然后,計算j(θ)相對于策略π的參數θ的梯度:最后,按照梯度的方向對策略的參數進行優化:
18、
19、式中,α表示策略參數的更新步長。
20、本發明的有益效果:
21、1、經過仿真實驗對比驗證,本發明可以有效提高環境動力學模型的準確度,同時生成的樣本數據能夠很好地用于策略學習,使得智能體在任務中獲得更高的期望累積獎勵值。
22、2、本發明是在基于平均場的多智能體強化學習(m3-ucrl)算法的基礎上對其進行了改進。充分發揮了cgan在數據生成方面的優勢,利用cgan對用mfc化簡的多智能體系統環境進行建模,提高了模型的準確性。在訓練過程中,一旦獲得穩定的環境模型,就讓代表智能體直接與該模型進行交互,相當于為智能體賦予了“想象力”,無需親力親為即可獲得一條軌跡。不僅節省了時間、降低了系統能耗,而且為智能體策略學習提供了豐富的樣本數據,使得智能體可以獲得更多的累積獎勵,從而提升算法的整體性能。
23、3、利用cgan的數據生成優勢,在集群合作場景下,對mfc化簡的多智能體環境進行精準建模;并當環境模型訓練穩定后,可以為策略的學習提供大量樣本數據,幫助智能體獲得更高的累積獎勵,從而提高算法的整體性能。
- 還沒有人留言評論。精彩留言會獲得點贊!