一種石油產量預測方法、裝置、設備及介質
本發明涉及石油生產,具體為一種石油產量預測方法、裝置、設備及介質。
背景技術:
1、在當今全球能源需求日益增長的背景下,石油作為核心的能源資源,在維持全球經濟發展的動力系統中扮演著不可或缺的角色。對于石油開采企業而言,能夠準確預測石油產量不僅是優化資源配置、制定有效戰略規劃的關鍵,也是確保市場供應穩定、滿足全球能源需求的重要基礎。然而,石油產量的預測工作遠非易事,其復雜性主要來源于石油產出受到地質條件、開采技術、全球經濟波動以及政策法規等多重因素的共同影響,這些因素構成了一個高度復雜的動態系統,給準確預測帶來了顯著挑戰。
2、傳統上,石油產量的預測依賴于統計學和時間序列分析的方法,例如廣泛應用的arima模型和指數平滑法。這些方法在處理線性關系和相對簡單的時間序列預測問題時表現良好。然而,它們在捕捉石油產量數據中存在的非線性關系和復雜的時間依賴性方面往往力不從心,難以準確反映石油產量的動態變化特征,數值模擬結果對未來石油產量的預測不夠準確。
技術實現思路
1、有鑒于此,為了解決現有技術中的問題,本發明提出一種石油產量預測方法、裝置設備及介質,本發明所要解決的技術問題是:如何提高石油產量預測的準確性和可靠性。本發明通過以下技術手段解決上述問題:
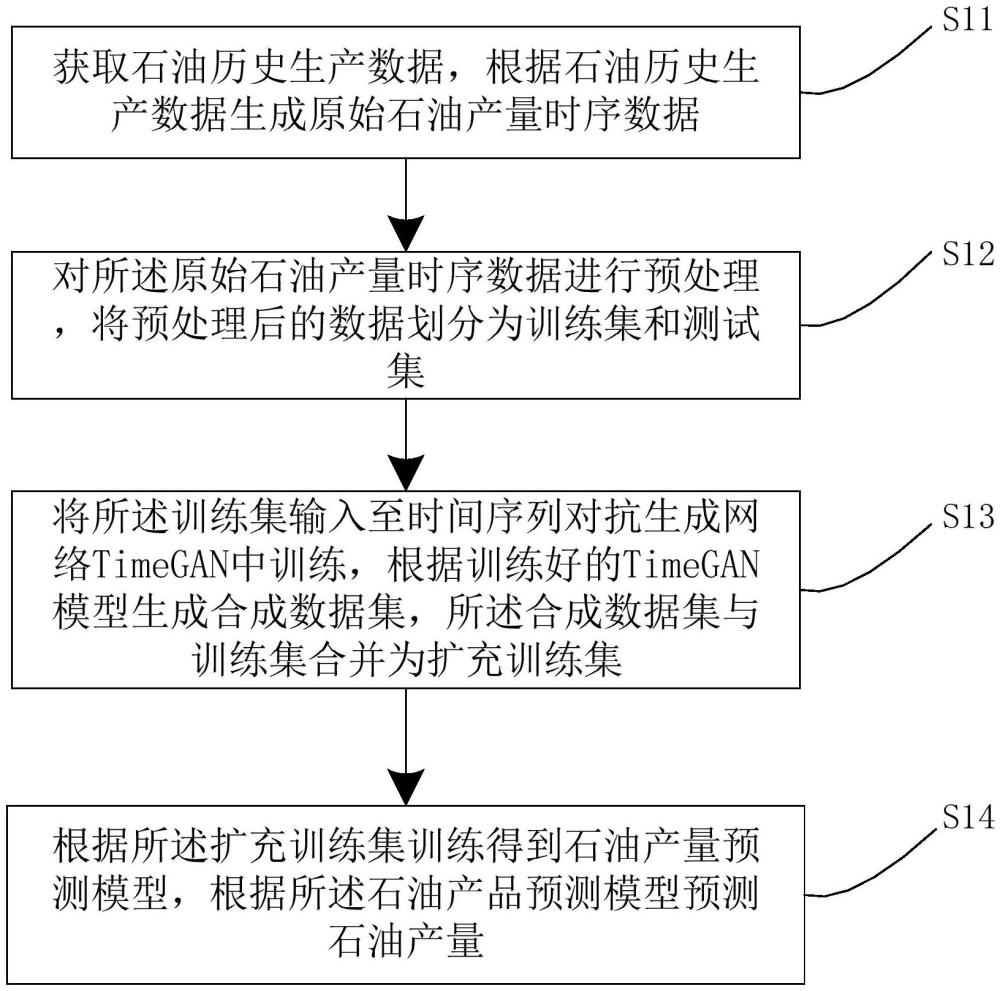
2、第一方面,本發明提供一種石油產量預測方法,包括:
3、獲取石油歷史生產數據,根據石油歷史生產數據生成原始石油產量時序數據;
4、對所述原始石油產量時序數據進行預處理,將預處理后的數據劃分為訓練集和測試集;
5、將所述訓練集輸入至時間序列對抗生成網絡timegan中訓練,根據訓練好的timegan模型生成合成數據集,所述合成數據集與訓練集合并為擴充訓練集;
6、根據所述擴充訓練集訓練得到石油產量預測模型,根據所述石油產品預測模型預測石油產量。所述根據所述擴充訓練集訓練得到石油產量預測模型,根據所述石油產品預測模型預測石油產量后,還包括:
7、將所述測試集輸入至石油產量預測模型中,評價石油產量預測模型性能。進一步的,
8、所述對所述原始石油產量時序數據進行預處理,預處理后的數據劃分為訓練集和測試集,包括:
9、對所述原始石油產量時序數據進行預處理包括缺失值處理、異常值處理和數據歸一化處理,通過皮爾遜相關系數進行特征選擇;預處理后的數據按照8:2的比例劃分為訓練集和測試集;
10、數據歸一化處理表達式為:
11、
12、其中,xstd為歸一化后的數據值;x為原始數據值;xmax為數據集中最大值;xmin為數據集中最小值;
13、皮爾遜相關系數表達式為:
14、
15、其中,xi為第i個觀測值在變量x中的取值;yi為第i個觀測值在變量y中的取值;和分別為x和y的均值;n為觀測值的數量;
16、
17、其中,r為相關系數,用于衡量變量x和y之間的線性關系強度和方向;
18、cov(x,y)為x和y的協方差;σx和σy分別為x和y的標準差。
19、進一步的,將所述訓練集輸入至時間序列對抗生成網絡timegan中訓練,根據訓練好的timegan模型生成合成數據集,所述合成數據集與訓練集合并為擴充訓練集,包括:
20、所述時間序列對抗生成網絡timegan網絡包括編碼器、生成器、解碼器和判別器;
21、所述編碼器用于將輸入的訓練集映射到潛在空間,使其捕捉到原始數據集的時間序列數據的特性;
22、所述生成器用于接收隨機噪聲作為輸入,并通過學習編碼器的潛在表示來生成假的時間序列數據;
23、所述解碼器用于將潛在空間的表示映射回原始數據空間,重構時間序列數據;
24、所述判別器用于判斷輸入的時間序列數據真偽,引導所述生成器生成所述合成數據集;
25、所述timegan模型訓練通過自編碼損失、生成對抗網絡損失、總損失函數優化,
26、自編碼器損失表達式為:
27、
28、其中,e為編碼器;d為解碼器;x為真實的時間序列數據;‖·‖表示歐式距離;為在數據分布pdata上的期望值;d(e(x))為通過編碼器e編碼并由解碼器d重構后的數據;
29、生成器損失表達式為:
30、
31、其中,為在噪聲分布pz上的期望值;d(g(z))為判別器d對生成器g生成的樣本g(z)的輸出;
32、判別器損失表達式為:
33、
34、其中,g為生成器,d為判別器,z為隨機噪聲,pz為噪聲分布,pdata為真實數據的分布;
35、總損失表達式為:
36、ltotal=lae+αlg+βld
37、其中,α和β為用于調節各個損失貢獻度的超參數。
38、進一步的,所述根據所述擴充訓練集訓練得到石油產量預測模型,根據所述石油產品預測模型預測石油產量,包括:
39、將原始石油產量時序數據輸入至石油產量預測模型中,石油產量預測模型輸出石油產量預測數據;所述石油產量預測模型包括cnn層、bigru層和attention層的模型,
40、所述cnn層對輸入的擴充訓練集進行特征提取,其表達式為:
41、yc=frelu(w*x+b)
42、frelu(x)=max(x,0)
43、yp(i)=max(yc,(i,i));
44、其中,frelu為cnn網絡激活函數,*表示卷積操作,w為卷積核的權重,yc為卷積層輸出,yp(i)為池化層在卷積層(i,i)的范圍內生成的特征映射;
45、所述bigru層將cnn層提取的特征進行處理,其表達式為:
46、zt=σ(wzxt+uzht-1)
47、rt=σ(wrxt+urht-1)
48、
49、其中,xt為bigru網絡中t時刻的輸入值,rt為重置門,zt為更新門,ht-1為上一時刻的輸入的狀態矩陣,ht為下一時刻的輸出矩陣,wz、wr、w、uz、ur、u為各狀態下的參數矩陣,σ、tanh為激活函數;
50、attention層對bigru層的輸出進行加權,其表達式為:
51、
52、c=∑tαtht
53、其中,αt為時間步t的注意力權重,ht為bigru層的輸出,hs為注意力層的查詢向量,c為加權后的上下文向量。
54、進一步的,所述根據所述擴充訓練集訓練得到石油產量預測模型,根據所述石油產品預測模型預測石油產量,包括:
55、構建石油產量預測模型優化算法采用adam算法,以sigmoid函數作為激活函數,損失函數選用均方誤差函數,根據損失函數的值對網絡內部參數進行更新調整,損失函數表達式:
56、
57、其中,n為數據樣本,yi為真實值,為預測值。
58、進一步地,所述將所述測試集輸入至石油產量預測模型中,評價石油產量預測模型性能,包括:
59、將測試集輸入到石油產量預測模型中,選用均方根誤差、平均絕對百分誤差、決定系數作為評價指標模型的性能;
60、決定系數表達式為:
61、
62、其中,sst為總平方和,sse為殘差平方和;
63、平均絕對百分誤差表達式為:
64、
65、均方根誤差表達式為:
66、
67、其中,n為數據樣本,yi為真實值,為預測值,為平均值。
68、第二方面,本發明提供一種石油產量預測裝置:
69、一種石油產量預測裝置,包括:
70、數據獲取模塊,用于獲取石油歷史生產數據,根據石油歷史生產數據生成原始石油產量時序數據;
71、數據分析模塊,用于對所述原始石油產量時序數據進行預處理,將預處理后的數據劃分為訓練集和測試集;
72、數據生成模塊,將所述訓練集輸入至時間序列對抗生成網絡timegan中訓練,根據訓練好的timegan模型生成合成數據集,所述合成數據集與訓練集合并為擴充訓練集;
73、產量預測模塊,根據所述擴充訓練集訓練得到石油產量預測模型,根據所述石油產品預測模型預測石油產量。
74、第三方面,本發明提供一種計算機設備,包括存儲器和處理器,所述存儲器存儲有計算機程序,所述處理器執行所述計算機程序,以實現上述的石油產量預測方法。
75、第四方面,本發明提供一種存儲介質,其上存儲有計算機程序,所述計算機程序被處理器執行時實現上述的石油產量預測方法步驟。
76、本發明的有益效果:
77、1、本發明對原始石油產量時序數據進行預處理,包括缺失值處理、異常值處理和數據歸一化處理,以去除數據的噪音影響,提高數據的準確性,從而提高預測的準確性。
78、2、本發明timegan模型訓練通過自編碼損失、生成對抗網絡損失、總損失函數優化,以使得生成的時間序列數據既保留了真實數據的統計特性,也能通過判別器的驗證,得到最佳的數據集擴充效果,提高預測準確性。
79、3、本發明的石油產品預測模型采用cnn網絡對時間序列特征進行提取,采用bigru網絡雙向處理輸入數據,有效的捕捉長序列依賴關系,有效緩解梯度消失和梯度爆炸的問題,采用attention機制,對輸出結果能夠集中注意力于序列中最關鍵的信息,提高預測準確度。
80、4、本發明采用各種評估指標,決定系數(r2)、平均絕對百分誤差(mape)、均方根誤差(rmse)等來評估模型的預測性能,確保石油產量預測的準確性和可靠性。
- 還沒有人留言評論。精彩留言會獲得點贊!