解決方案生成方法、裝置、設備及存儲介質與流程
本發明涉及人工智能領域及金融科技領域,尤其涉及解決方案生成方法、裝置、設備及存儲介質。
背景技術:
1、隨著業務平臺的業務范圍不斷擴大,業務平臺面臨著越來越多的挑戰和機遇。在這種背景下,解決方案顯得尤為重要。解決方案不僅能夠幫助業務平臺應對日益復雜的業務環境,還能通過整合和優化資源,提升業務平臺的運營效率和市場競爭力。
2、然而,現有技術的解決方案生成過程繁瑣,不利于提高解決方案生成效率。其原因在于,現有的解決方案生成方法,需要人工參與配置和修改,因此解決方案的生成時間長,耗費了人力資源和時間資源,因此,不利于提高解決方案生成效率。
技術實現思路
1、本發明提供一種解決方案生成方法、裝置、計算機設備及存儲介質,以解決現有技術的解決方案生成過程繁瑣,不利于提高解決方案生成效率的技術問題。
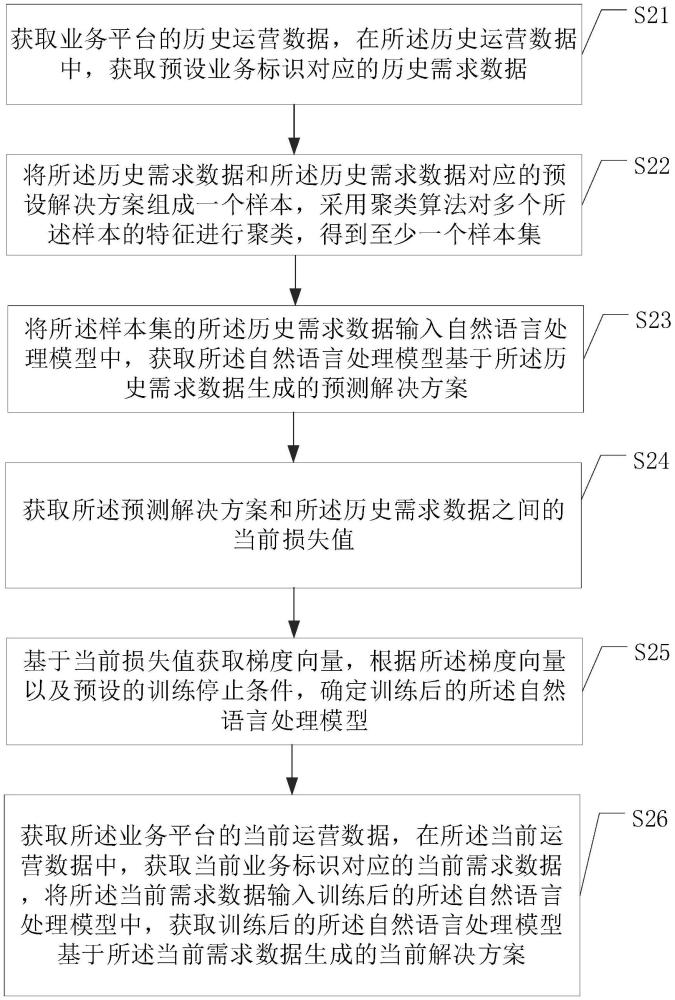
2、第一方面,提供了一種解決方案生成方法,包括:
3、獲取業務平臺的歷史運營數據,在所述歷史運營數據中,獲取預設業務標識對應的歷史需求數據;
4、將所述歷史需求數據和所述歷史需求數據對應的預設解決方案組成一個樣本,采用聚類算法對多個所述樣本的特征進行聚類,得到至少一個樣本集;
5、將所述樣本集的所述歷史需求數據輸入自然語言處理模型中,獲取所述自然語言處理模型基于所述歷史需求數據生成的預測解決方案;
6、獲取所述預測解決方案和所述歷史需求數據之間的當前損失值;
7、基于當前損失值獲取梯度向量,根據所述梯度向量以及預設的訓練停止條件,確定訓練后的所述自然語言處理模型;
8、獲取所述業務平臺的當前運營數據,在所述當前運營數據中,獲取當前業務標識對應的當前需求數據,將所述當前需求數據輸入訓練后的所述自然語言處理模型中,獲取訓練后的所述自然語言處理模型基于所述當前需求數據生成的當前解決方案。
9、進一步地,所述獲取業務平臺的歷史運營數據,在所述歷史運營數據中,獲取預設業務標識對應的歷史需求數據,包括:
10、獲取業務平臺的歷史運營數據,在所述歷史運營數據中,獲取所述預設業務標識對應的預設用戶文檔和預設用戶語音;
11、將所述預設用戶文檔和所述預設用戶語音的需求信息設置為所述歷史需求數據。
12、進一步地,所述將所述樣本集的所述歷史需求數據輸入自然語言處理模型中,獲取所述自然語言處理模型基于所述歷史需求數據生成的預測解決方案,包括:
13、獲取所述樣本集的所述歷史需求數據的第一特征向量,將所述第一特征向量輸入自然語言處理模型中;
14、獲取所述自然語言處理模型基于所述第一特征向量生成的預測解決方案。
15、進一步地,所述獲取所述預測解決方案和所述歷史需求數據之間的當前損失值,包括:
16、通過預設的損失函數,獲取所述預測解決方案和所述歷史需求數據之間的當前損失值,所述損失函數包括平均絕對誤差損失函數、交叉熵損失函數中的其中一種或其組合。
17、進一步地,所述基于當前損失值獲取梯度向量,根據所述梯度向量以及預設的訓練停止條件,確定訓練后的所述自然語言處理模型,包括:
18、基于當前損失值獲取梯度向量,根據所述梯度向量更新所述自然語言處理模型的模型參數,使用所述樣本對更新所述模型參數后的所述自然語言處理模型進行迭代訓練;
19、獲取訓練輪數,判斷所述訓練輪數是否大于所述訓練停止條件中的預設輪數,并判斷所述當前損失值是否小于所述訓練停止條件中的預設損失值;當所述訓練輪數大于所述訓練停止條件中的所述預設輪數或所述當前損失值是否小于所述訓練停止條件中的所述預設損失值時,停止訓練所述自然語言處理模型,保存訓練后的所述自然語言處理模型。
20、進一步地,所述獲取所述業務平臺的當前運營數據,在所述當前運營數據中,獲取當前業務標識對應的當前需求數據,將所述當前需求數據輸入訓練后的所述自然語言處理模型中,獲取訓練后的所述自然語言處理模型基于所述當前需求數據生成的當前解決方案,包括:
21、獲取所述業務平臺的當前運營數據,在所述當前運營數據中,獲取當前業務標識對應的當前用戶文檔和當前用戶語音;
22、將所述當前用戶文檔和所述當前用戶語音的需求信息設置為所述當前需求數據;
23、獲取所述當前需求數據的第二特征向量,將所述第一特征向量輸入訓練后所述自然語言處理模型中,獲取訓練后所述自然語言處理模型基于所述第二特征向量生成的當前解決方案。
24、進一步地,在所述獲取所述業務平臺的當前運營數據,在所述當前運營數據中,獲取當前業務標識對應的當前需求數據,將所述當前需求數據輸入訓練后的所述自然語言處理模型中,獲取訓練后的所述自然語言處理模型基于所述當前需求數據生成的當前解決方案之后,所述解決方案生成方法,包括:
25、將所述解決方案存儲至預設的解決方案庫中。
26、第二方面,提供了一種解決方案生成裝置,包括:
27、第一獲取模塊,用于獲取業務平臺的歷史運營數據,在所述歷史運營數據中,獲取預設業務標識對應的歷史需求數據;
28、聚類模塊,用于將所述歷史需求數據和所述歷史需求數據對應的預設解決方案組成一個樣本,采用聚類算法對多個所述樣本的特征進行聚類,得到至少一個樣本集;
29、第二獲取模塊,用于將所述樣本集的所述歷史需求數據輸入自然語言處理模型中,獲取所述自然語言處理模型基于所述歷史需求數據生成的預測解決方案;
30、第三獲取模塊,用于獲取所述預測解決方案和所述歷史需求數據之間的當前損失值;
31、保存模塊,用于基于當前損失值獲取梯度向量,根據所述梯度向量以及預設的訓練停止條件,確定訓練后的所述自然語言處理模型;
32、生成模塊,用于獲取所述業務平臺的當前運營數據,在所述當前運營數據中,獲取當前業務標識對應的當前需求數據,將所述當前需求數據輸入訓練后的所述自然語言處理模型中,獲取訓練后的所述自然語言處理模型基于所述當前需求數據生成的當前解決方案。
33、第三方面,提供了一種計算機設備,包括存儲器、處理器以及存儲在存儲器中并可在處理器上運行的計算機程序,處理器執行計算機程序時實現上述解決方案生成方法的步驟。
34、第四方面,提供了一種計算機可讀存儲介質,計算機可讀存儲介質存儲有計算機程序,計算機程序被處理器執行時實現上述解決方案生成方法的步驟。
35、本技術提供一種解決方案生成方法、裝置、計算機設備及存儲介質,獲取業務平臺的歷史運營數據,在所述歷史運營數據中,獲取預設業務標識對應的歷史需求數據;將所述歷史需求數據和所述歷史需求數據對應的預設解決方案組成一個樣本,采用聚類算法對多個所述樣本的特征進行聚類,得到至少一個樣本集;將所述樣本集的所述歷史需求數據輸入自然語言處理模型中,獲取所述自然語言處理模型基于所述歷史需求數據生成的預測解決方案;獲取所述預測解決方案和所述歷史需求數據之間的當前損失值;基于當前損失值獲取梯度向量,根據所述梯度向量以及預設的訓練停止條件,確定訓練后的所述自然語言處理模型;獲取所述業務平臺的當前運營數據,在所述當前運營數據中,獲取當前業務標識對應的當前需求數據,將所述當前需求數據輸入訓練后的所述自然語言處理模型中,獲取訓練后的所述自然語言處理模型基于所述當前需求數據生成的當前解決方案,有益效果在于兩方面,一方面,由于無需人工參與配置和修改,因此減少了解決方案的生成時間,節省了人力資源和時間資源,有利于提高解決方案生成效率;另一方面,獲取訓練后的所述自然語言處理模型基于所述當前需求數據生成的當前解決方案,可以減少對人工操作的依賴,降低人工操作在當前解決方案生成過程中的影響,因此有利于提升所述當前解決方案的穩定性。
- 還沒有人留言評論。精彩留言會獲得點贊!