視頻封面的選擇方法、裝置、電子設備及存儲介質與流程
本公開涉及計算機視覺領域,尤其涉及一種視頻封面的選擇方法、裝置、電子設備及存儲介質。
背景技術:
1、視頻封面是視頻點擊率的重要影響因素。在視頻播放場景中,需要從視頻內容中抽取視頻幀作為宣傳素材,例如視頻封面,從而提升視頻點擊率。作為封面的視頻幀通常需要足夠清晰、足夠美觀、并且包括觀眾感興趣的內容。如人工瀏覽視頻內容對視頻幀進行主觀評價和挑選,在面臨海量視頻時,需要耗費極大的人工成本。相比完全由人工選擇封面,現有技術的自動化封面選擇方法雖無需人工挑選視頻幀,但仍需人工進行大量標注,因此人工成本依然有進一步壓縮的空間,且應用場景較為單一。
2、因此,如何自動化選擇視頻封面,并進一步降低視頻封面選擇的人工成本,提高應用場景的適配靈活性,成為本領域亟待解決的技術問題。
技術實現思路
1、有鑒于此,本公開提出了一種視頻封面的選擇方法、裝置、電子設備及存儲介質。該方法利用了多模態大模型泛化性高的特點,可以靈活地適配到多種應用場景,且不需要大量人工標注,可進一步降低人工成本,并保證封面的質量。
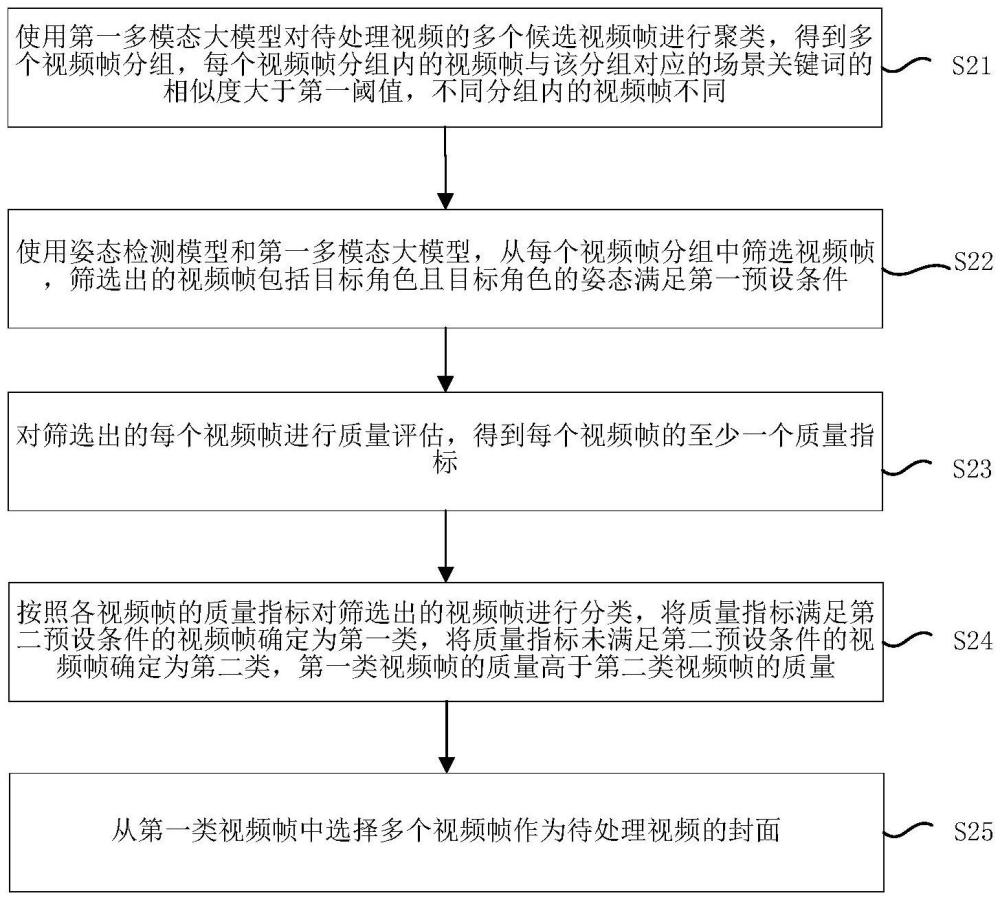
2、根據本公開的一方面,提供了一種視頻封面的選擇方法,所述方法包括:使用第一多模態大模型對待處理視頻的多個候選視頻幀進行聚類,得到多個視頻幀分組,每個視頻幀分組內的視頻幀與該分組對應的場景關鍵詞的相似度大于第一閾值,不同視頻幀分組內的視頻幀不同;使用姿態檢測模型和所述第一多模態大模型,從每個視頻幀分組中篩選視頻幀,篩選出的視頻幀包括目標角色且目標角色的姿態滿足第一預設條件;對篩選出的每個視頻幀進行質量評估,得到每個視頻幀的至少一個質量指標;按照各視頻幀的質量指標對篩選出的視頻幀進行分類,將質量指標滿足第二預設條件的視頻幀確定為第一類,將質量指標未滿足第二預設條件的視頻幀確定為第二類,第一類視頻幀的質量高于第二類視頻幀的質量;從第一類視頻幀中選擇多個視頻幀作為所述待處理視頻的封面。
3、在一種可能的實現方式中,對篩選出的每個視頻幀進行質量評估包括以下至少一種方式:使用姿態估計模型對視頻幀中角色的姿態進行評估,得到第一質量指標;對角色在視頻幀中的位置以及視頻幀的圖像內容對稱度進行評估,得到第二質量指標;使用所述第一多模態大模型解析視頻幀的標簽,對標簽的種類及內容進行評估,得到第三質量指標;使用第二多模態大模型,從美學角度對視頻幀進行評估,得到第四質量指標,所述美學角度包括和諧、平衡、優雅、感情中的至少一種。
4、在一種可能的實現方式中,所述從第一類視頻幀中選擇多個視頻幀作為所述待處理視頻的封面,包括:根據所述第一類視頻幀的質量指標,從所述第一類視頻幀中確定目標視頻幀,所述目標視頻幀的質量高于所述第一類視頻幀中的其他視頻幀;比較所述目標視頻幀與所述其他視頻幀的相似度,從所述第一類視頻幀中刪除與所述目標視頻幀的相似度大于第二閾值的視頻幀,將所述目標視頻幀由第一類視頻幀變更為第三類視頻幀;重新執行根據所述第一類視頻幀的質量指標,從所述第一類視頻幀中確定目標視頻幀及之后的步驟,直到所述第三類視頻幀的個數達到第三閾值,或者,直到所述第一類視頻幀的個數等于0;從所述第三類視頻幀中選擇多個視頻幀作為所述待處理視頻的封面。
5、在一種可能的實現方式中,所述從所述第三類視頻幀中選擇多個視頻幀作為所述待處理視頻的封面,包括:根據預設尺寸比例裁剪所述第三類視頻幀;對裁剪后的第三類視頻幀進行銳化;從銳化后的第三類視頻幀中選擇多個視頻幀作為所述待處理視頻的封面。
6、在一種可能的實現方式中,所述使用第一多模態大模型對待處理視頻的多個候選視頻幀進行聚類,包括:使用所述第一多模態大模型解析每個候選視頻幀的標簽;針對每個候選視頻幀,計算該候選視頻幀的每個標簽和每個場景關鍵詞的相似度;根據計算出的相似度,確定每個候選視頻幀和每個場景關鍵詞的相似度;根據每個候選視頻幀和每個場景關鍵詞的相似度,對多個候選視頻幀進行聚類。
7、在一種可能的實現方式中,所述第一預設條件包括:目標角色的正面或側面得到展示。
8、在一種可能的實現方式中,每個質量指標具有對應的指標閾值,所述第二預設條件包括:質量指標數值超出對應的指標閾值的質量指標的數量大于或等于第四閾值。
9、在一種可能的實現方式中,所述使用姿態檢測模型和所述第一多模態大模型,從每個視頻幀分組中篩選視頻幀,包括:使用所述姿態檢測模型篩選出每個視頻幀分組內包括任意角色且該角色的姿態滿足第一預設條件的視頻幀;使用所述第一多模態大模型解析所述姿態檢測模型篩選出的視頻幀的標簽,根據標簽對應的角色,篩選出包括目標角色的視頻幀。
10、在一種可能的實現方式中,所述使用第一多模態大模型對待處理視頻的多個候選視頻幀進行聚類之前,所述方法還包括:使用深度殘差網絡模型提取所述待處理視頻的每一視頻幀的特征向量;根據每兩個視頻幀的特征向量的相似度,確定多組相似的視頻幀;從每組相似的視頻幀中選擇質量最高的視頻幀作為候選視頻幀。
11、根據本公開的另一方面,提供了一種視頻封面的選擇裝置,所述裝置包括:聚類模塊,用于使用第一多模態大模型對待處理視頻的多個候選視頻幀進行聚類,得到多個視頻幀分組,每個視頻幀分組內的視頻幀與該分組對應的場景關鍵詞的相似度大于第一閾值,不同視頻幀分組內的視頻幀不同;第一級篩選模塊,用于使用姿態檢測模型和所述第一多模態大模型,從每個視頻幀分組中篩選視頻幀,篩選出的視頻幀包括目標角色且目標角色的姿態滿足第一預設條件;質量評估模塊,用于對篩選出的每個視頻幀進行質量評估,得到每個視頻幀的至少一個質量指標;第二級篩選模塊,用于按照各視頻幀的質量指標對篩選出的視頻幀進行分類,將質量指標滿足第二預設條件的視頻幀確定為第一類,將質量指標未滿足第二預設條件的視頻幀確定為第二類,第一類視頻幀的質量高于第二類視頻幀的質量;封面選擇模塊,用于從第一類視頻幀中選擇多個視頻幀作為所述待處理視頻的封面。
12、在一種可能的實現方式中,對篩選出的每個視頻幀進行質量評估包括以下至少一種方式:使用姿態估計模型對視頻幀中角色的姿態進行評估,得到第一質量指標;對角色在視頻幀中的位置以及視頻幀的圖像內容對稱度進行評估,得到第二質量指標;使用所述第一多模態大模型解析視頻幀的標簽,對標簽的種類及內容進行評估,得到第三質量指標;使用第二多模態大模型,從美學角度對視頻幀進行評估,得到第四質量指標,所述美學角度包括和諧、平衡、優雅、感情中的至少一種。
13、在一種可能的實現方式中,所述從第一類視頻幀中選擇多個視頻幀作為所述待處理視頻的封面,包括:根據所述第一類視頻幀的質量指標,從所述第一類視頻幀中確定目標視頻幀,所述目標視頻幀的質量高于所述第一類視頻幀中的其他視頻幀;比較所述目標視頻幀與所述其他視頻幀的相似度,從所述第一類視頻幀中刪除與所述目標視頻幀的相似度大于第二閾值的視頻幀,將所述目標視頻幀由第一類視頻幀變更為第三類視頻幀;重新執行根據所述第一類視頻幀的質量指標,從所述第一類視頻幀中確定目標視頻幀及之后的步驟,直到所述第三類視頻幀的個數達到第三閾值,或者,直到所述第一類視頻幀的個數等于0;從所述第三類視頻幀中選擇多個視頻幀作為所述待處理視頻的封面。
14、在一種可能的實現方式中,所述從所述第三類視頻幀中選擇多個視頻幀作為所述待處理視頻的封面,包括:根據預設尺寸比例裁剪所述第三類視頻幀;對裁剪后的第三類視頻幀進行銳化;從銳化后的第三類視頻幀中選擇多個視頻幀作為所述待處理視頻的封面。
15、在一種可能的實現方式中,所述使用第一多模態大模型對待處理視頻的多個候選視頻幀進行聚類,包括:使用所述第一多模態大模型解析每個候選視頻幀的標簽;針對每個候選視頻幀,計算該候選視頻幀的每個標簽和每個場景關鍵詞的相似度;根據計算出的相似度,確定每個候選視頻幀和每個場景關鍵詞的相似度;根據每個候選視頻幀和每個場景關鍵詞的相似度,對多個候選視頻幀進行聚類。
16、在一種可能的實現方式中,所述第一預設條件包括:目標角色的正面或側面得到展示。
17、在一種可能的實現方式中,每個質量指標具有對應的指標閾值,所述第二預設條件包括:質量指標數值超出對應的指標閾值的質量指標的數量大于或等于第四閾值。
18、在一種可能的實現方式中,所述使用姿態檢測模型和所述第一多模態大模型,從每個視頻幀分組中篩選視頻幀,包括:使用所述姿態檢測模型篩選出每個視頻幀分組內包括任意角色且該角色的姿態滿足第一預設條件的視頻幀;使用所述第一多模態大模型解析所述姿態檢測模型篩選出的視頻幀的標簽,根據標簽對應的角色,篩選出包括目標角色的視頻幀。
19、在一種可能的實現方式中,所述裝置還包括抽幀模塊,用于:在使用第一多模態大模型對待處理視頻的多個候選視頻幀進行聚類之前,使用深度殘差網絡模型提取所述待處理視頻的每一視頻幀的特征向量;根據每兩個視頻幀的特征向量的相似度,確定多組相似的視頻幀;從每組相似的視頻幀中選擇質量最高的視頻幀作為候選視頻幀。
20、根據本公開的另一方面,提供了一種電子設備,包括:處理器;用于存儲處理器可執行指令的存儲器;其中,所述處理器被配置為在執行所述存儲器存儲的指令時,實現上述方法。
21、根據本公開的另一方面,提供了一種非易失性計算機可讀存儲介質,其上存儲有計算機程序指令,其中,所述計算機程序指令被處理器執行時實現上述方法。
22、根據本公開的另一方面,提供了一種計算機程序產品,包括計算機可讀代碼,或者承載有計算機可讀代碼的非易失性計算機可讀存儲介質,當所述計算機可讀代碼在電子設備的處理器中運行時,所述電子設備中的處理器執行上述方法。
23、根據本公開實施例的視頻封面的選擇方法,使用第一多模態大模型對待處理視頻的多個候選視頻幀進行聚類,得到多個視頻幀分組,每個視頻幀分組內的視頻幀與該分組對應的場景關鍵詞的相似度大于第一閾值,可保證最終作為封面的視頻幀與場景關鍵詞有關聯,增加包括用戶感興趣場景的視頻幀在視頻封面中的占比。且場景關鍵詞可根據應用場景需求實時調整,因此聚類不需要任何標注和訓練,從而降低人工成本和數據處理成本。使用姿態檢測模型和第一多模態大模型,從每個視頻幀分組中篩選視頻幀,篩選出的視頻幀包括目標角色且目標角色的姿態滿足第一預設條件,可排除不包括目標角色的視頻幀以及包括目標角色但目標角色的姿態不適合作為封面的視頻幀。對篩選出的每個視頻幀進行質量評估,得到每個視頻幀的至少一個質量指標,按照各視頻幀的質量指標對篩選出的視頻幀進行分類,將質量指標滿足第二預設條件的視頻幀確定為第一類,將質量指標未滿足第二預設條件的視頻幀確定為第二類,第一類視頻幀的質量高于第二類視頻幀的質量,可以排除質量較差的視頻幀。在此情況下,從第一類視頻幀中選擇多個視頻幀作為所述待處理視頻的封面,即可保證封面包括目標角色且目標角色的姿態滿足第一預設條件,且質量較高。綜上所述,本公開的視頻封面的選擇方法利用了多模態大模型泛化性高的特點,可以靈活地適配到多種應用場景,且不需要大量人工標注,可進一步降低人工成本,并保證封面的質量。質量指標有多個時,還可以降低因質量評估錯誤導致的視頻幀篩選誤差。
24、根據下面參考附圖對示例性實施例的詳細說明,本公開的其它特征及方面將變得清楚。
- 還沒有人留言評論。精彩留言會獲得點贊!