一種基于改進YOLOv7的半監督軸承表面缺陷檢測方法
本發明屬于目標檢測,具體涉及一種基于半監督學習的軸承表面缺陷檢測方法。
背景技術:
1、軸承作為機械設備中的關鍵部件,其表面質量直接影響設備的性能和使用壽命。有效檢測軸承表面的缺陷,如裂紋、凹坑和劃痕等,不僅能夠提高產品質量,減少設備故障和停機時間,還能降低維修成本,延長設備的使用周期。但是在工業生產線條件下往往只能獲取到少量有代表性的缺陷樣本,難以覆蓋所有可能出現的缺陷情況。同時收集和標注缺陷樣本是一項勞動密集型工作,特別是對于高精度的標注要求,這在經濟和時間成本上都是巨大的負擔。此外小樣本條件下,傳統的機器學習算法容易過擬合,難以泛化到未見過的缺陷類型上,不能滿足高效、精準的檢測需求。因此通過研究并應用先進的圖像處理和深度學習技術,實現對軸承表面缺陷的自動檢測和分類,有助于提高檢測效率和準確性,推動制造業向智能化和高效化方向發展。這不僅對提高生產效率和產品質量具有重要意義,還能夠增強企業的市場競爭力,推動整個行業的技術進步。
2、近年來,隨著深度學習技術的迅猛發展,基于深度學習的缺陷目標檢測算法逐漸取代了傳統的機器學習方法。深度學習等先進技術雖然在圖像識別等領域展現出卓越性能,但其成功往往基于大數據支持。目前基于深度學習的表面缺陷檢測通常采用全監督模型,這種模型依賴大量精確的人工標注樣本進行訓練,需要耗費大量的時間和人力資源。如何在缺陷檢測的小樣本場景下,減少模型參數量并提升對細微缺陷的檢測精度,成為亟待解決的關鍵問題。
3、因此,本發明提出了一種基于yolov7的半監督軸承表面缺陷檢測方法,用以解決現有軸承表面缺陷檢測模型參數量大、軸承缺陷尺度小以及當前公開數據集不足標注成本高的問題,以提高在有限樣本基礎上的檢測精度、速度和泛化能力。
技術實現思路
1、(一)解決的技術問題
2、為了克服現有技術的不足,本發明提出了一種基于yolov7的半監督軸承表面缺陷檢測方法,用以解決現有軸承表面缺陷檢測模型參數量大、軸承缺陷尺度小以及當前公開數據集不足標注成本高的問題,該方法能夠在有限樣本的基礎上,有效提升檢測精度、速度和泛化能力。
3、(二)技術方案
4、本發明為了實現上述目的具體采用以下技術方案:
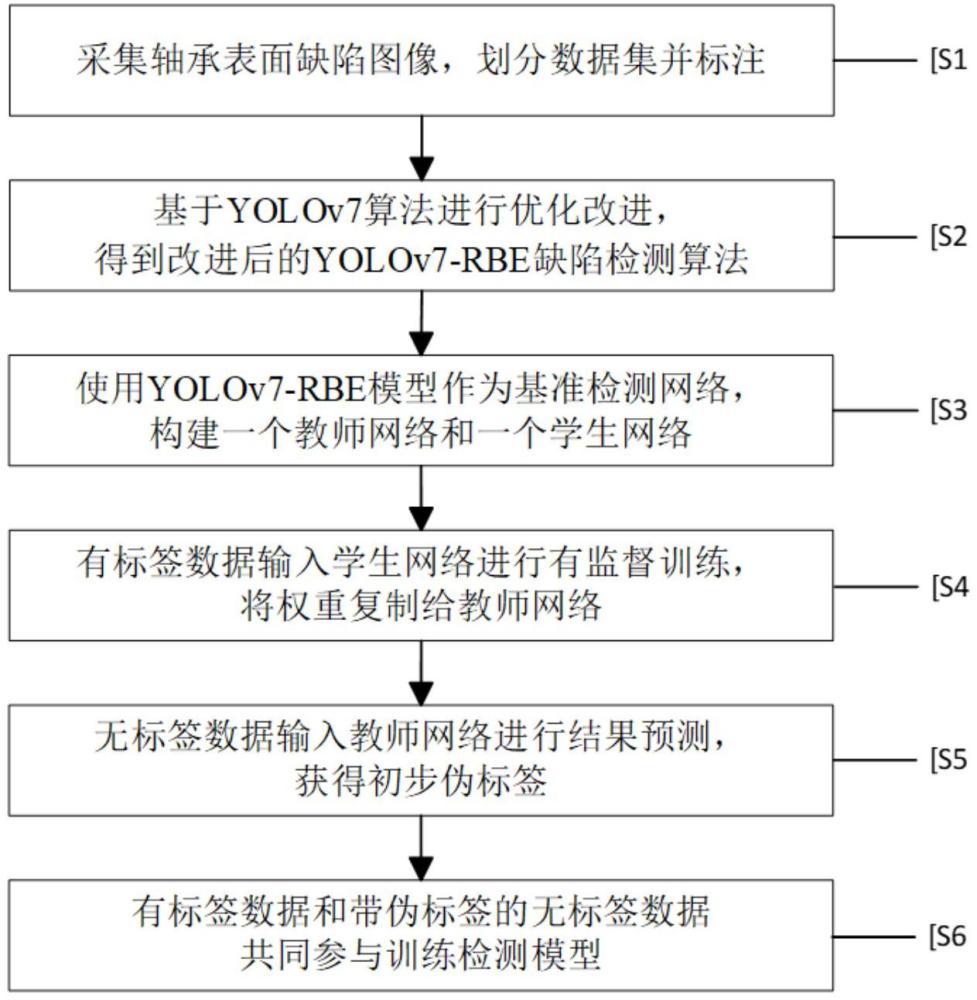
5、一種基于改進yolov7的半監督軸承表面缺陷檢測方法,該方法包括以下步驟:
6、s1.采集軸承表面缺陷圖像,劃分數據集并標注;
7、s2.基于yolov7算法進行優化改進,得到改進后的yolov7-rbe缺陷檢測算法;
8、s3.使用yolov7-rbe模型作為基準檢測網絡,構建一個教師網絡和一個學生網絡;
9、s4.在監督階段,有標簽數據輸入學生網絡中進行預訓練,將預訓練權重復制給教師網絡;
10、s5.在半監督階段,無標簽數據輸入教師網絡進行結果預測,獲得初步偽標簽;
11、s6.有標簽數據和帶偽標簽的無標簽數據共同訓練檢測模型,并且實時將學生網絡的權重參數傳遞給教師網絡。
12、進一步地,所述的s1:采集軸承表面缺陷圖像,劃分數據集并標注,具體為:
13、本次實驗數據集為自制的軸承表面缺陷數據集,從不同光照方向采集軸承表面缺陷圖像共2174張,圖片像素大小為1280×1024,該數據集中包含了缺口、擦傷、劃痕和銹斑4種缺陷類型。其中缺口圖片436,擦傷圖片602張,劃痕圖片611,銹斑圖片525張。
14、將軸承表面缺陷數據集按照設定的比例9:1劃分為無標簽數據集和有標簽數據集,使用labelimg軟件對劃分為有標簽數據集的圖像進行標注,標注出軸承表面缺陷的類型和位置,其中缺口的標簽為breath,擦傷的標簽為abrade,劃痕的標簽為scratch,銹斑的標簽為rust。標注完成后得到yolo格式的txt標注文件,最后將有標簽數據集按照8:2的比例劃分為訓練集和測試集。
15、進一步地,s2中所述的改進yolov7網絡結構包括以下步驟;
16、步驟一:將主干網絡中四個elan模塊替換為包含重參數卷積(repconv)的elan-rep模塊,降低的模型參數量;
17、步驟二:在特征融合階段引入雙向特征金字塔重構頸部網絡,使網絡具有更高的特征融合效率和能力,提高模型對小目標的檢測性能;
18、步驟三:在預測階段使用focal-eiou作為邊框回歸損失函數,通過調節低質量樣本和高質量樣本對損失函數的影響,精細優化邊框回歸,從而使模型更加關注高質量錨框,提高檢測性能和穩定性。
19、進一步地,步驟一所述的將主干網絡中四個elan模塊替換為包含重參數卷積(repconv)的elan-rep模塊,具體為:
20、原始yolov7架構大量采用了elan模塊,這種設計雖然可以增強特征表達,但其密集的堆疊大幅增加了模型的參數量與復雜性,影響了檢測性能。為了解決這一問題并促進更高效的特征提取,對elan模塊進行了優化。引入高效重參數卷積來提升模型的特征提取效率及檢測精度,通過簡化模型架構,有效加速了推理過程,實現了性能與效率的雙重優化。
21、重參數主要是在訓練階段和推理階段對網絡進行優化處理,實現模型計算效率和性能的提升。重參數化主要包括兩個步驟:一是訓練階段的多分支結構,如圖1所示,即在訓練階段,使用包含多個分支的卷積結構來增加模型的表達能力和訓練效果。這些分支可以包括卷積(conv)以及不同的歸一化層(bn)和激活函數等。二是推理階段的單分支結構,在推理階段,將訓練階段的多分支結構通過參數重排合并成一個單分支卷積結構。這一步通過數學轉換,將多個分支的權重和偏置合并到一個標準的卷積層中,從而減少計算開銷,提高推理效率,同時保持訓練階段的性能優勢。
22、為了進一步提高yolov7網絡在推理階段的效率,本發明采用重參數卷積設計了elan-rep模塊,替換原算法主干網絡四個elan模塊中的特定普通卷積層。
23、進一步地,步驟二所述的在特征融合階段引入雙向特征金字塔重構頸部網絡,具體為:
24、原始的yolov7算法在頸部層中采用特征金字塔和路徑聚合網絡,從不同特征層中提取信息。然而在面對軸承表面微小缺陷時,存在因特征細節丟失而導致檢測準確率下降的問題。為增強不同尺度間的特征融合并提高檢測精度,本發明引入了一種加權雙向特征融合網絡,該網絡通過智能加權融合不同層級的特征并構建跨尺度的特征連接,從而顯著增強了模型在小尺度目標檢測上的精確性,同時優化了特征利用效率。
25、相比于傳統的特征金字塔和路徑聚合網絡的疊加,雙向特征金字塔(bifpn)刪除了只存在一條輸入邊的節點,減少了冗余計算;雙向特征金字塔中所有節點都有兩條以上的輸入邊,增加了模型的特征融合能力;此外通過增加跳躍連接,可以以較小代價獲取更多特征的融合。雙向特征金字塔能夠對不同輸入特征進行區分性融合,賦予其不同權重,并采用快速歸一化的加權特征融合。雙向特征金字塔加權特征融合計算方法為:
26、
27、其中,ω為可學習權重;ii為輸入特征;ε=0.0001。
28、本發明優化了yolov7模型的頸部結構,用一種加權的雙向特征金字塔網絡取代了原有的特征金字塔與路徑聚合結構。實現對主干網絡輸出的三個特征圖的更高效融合,增強了模型的特征融合效率和能力。
29、進一步地,步驟三所述的在預測階段使用focal-eiou作為邊框回歸損失函數,具體為:
30、yolo系列的損失函數由邊框回歸損失、置信度損失和分類損失三部分組成。,yolov7選用了ciou損失來優化邊界框回歸,以此克服giou損失函數在在某些情境下退化為iou損失的局限,如當預測框被真實框完全包圍時。ciou通過將預測框與真實框的高寬比引入損失值進行計算,有效解決了當預測框與真實框不重疊時仍能指導邊界框正確移動方向的問題。但與giou損失一樣,二者均未充分考慮到預測框與真實框之間的定向偏差,這這限制了收斂效率和定位精度。
31、本發明采用focal-eiou損失函數該損失函數通過對eiou損失值進行iou加權,調節低質量和高質量樣本對損失函數的影響,精細優化邊框回歸,從而使模型更加專注于高質量錨框,提高檢測性能和穩定性,同時加快模型的收斂速度。
32、進一步地,s3所述的使用yolov7-rbe模型作為基準檢測網絡,構建一個教師網絡和一個學生網絡,具體為:
33、教師-學生網絡的核心思想是使用已有的有標簽數據作為“教師”來指導無標簽數據的學習過程,從而讓無標簽數據也能積極參與模型訓練。在這個過程中,教師網絡往往是首先在一個小的、有標簽的數據集上訓練得到的一個較為成熟的模型,然后基于其現有的知識,為無標簽數據分配偽標簽(pseudo-labels),即預測的類別標簽。然后,學生網絡利用這些帶有偽標簽的無標簽數據以及原始的有標簽數據進行訓練。為了促進模型權重的穩健性與預測穩定性,采用學生網絡參數的指數移動平均值對教師網絡進行更新,伴隨迭代進程的深入,教師網絡的權重會愈發穩定,進而逐漸提高偽標簽的質量和模型的泛化能力。
34、為了增強半監督缺陷檢測模型的魯棒性,在不同階段分別采用了強、弱兩種數據增強策略,其中強增強包括覆蓋、模糊、改變色度等,弱增強包括旋轉、平移、鏡像等。
35、進一步地,s4所述的在監督階段,有標簽數據輸入學生網絡中進行預訓練,將預訓練權重復制給教師網絡,具體為:
36、首先有標簽數據進行弱增強后輸入學生網絡中進行有監督訓練,得到一個預訓練權重,然后將預訓練權重復制給教師網絡,進行教師網絡學習。訓練的輪數設定為200,分組尺寸設定為32,圖片尺寸設定為640×640。這一階段的損失為有監督損失,即ls,有監督損失定義為:
37、
38、其中,表示第i個已標注布匹圖像,為置信度損失,lcls為缺陷分類損失,lbox為候選框回歸損失,kl為已標注圖像數量。
39、進一步地,s5所述的在半監督階段,無標簽數據輸入教師網絡進行結果預測,獲得初步偽標簽,具體為:
40、無標簽數據進行弱增強后輸入教師網絡,并使用更新權重參數后的教師網絡進行推理預測,然后將預測結果通過nms(non-maximum?suppression)過濾去除冗余框,獲得初步偽標簽,隨后采用框抖動(box?jittering)中的方差濾波算法對偽標簽進行篩選,將濾波之后的高質量偽標簽數據進行強增強用于指導學生網絡學習無標簽數據的特征。這一階段的損失為無監督損失,即lu,無監督損失定義為:
41、
42、其中,表示第個未標注布匹圖像,為置信度損失,lcls為缺陷分類損失,lbox為候選框回歸損失,ku為未標注圖像數量。
43、本發明采用的框抖動方法是由soft?teacher提出的,通過度量回歸結果的一致性來判斷一個邊界框的定位是否可靠。給定一個教師網絡生成的偽邊界框bi,在其周圍采樣一個抖動框,并將抖動框輸入教師模型,得到精細化的邊界框
44、
45、重復進行上面的操作,就能夠收集到一系列的經過精細化調整的框,這些框的方差越小,定位可靠性越高,這一方法有效改善了偽標簽的可靠性。以下是用來篩選抖動框的方差濾波算法公式:
46、
47、式中σk是提取抖動框集合,{bi,j}中第k個坐標的標準推導規則,是σk的歸一化,h(bi)和w(bi)分別為候選框的高和寬,為候選框bi的抖動框回歸方差均值,也是抖動框生成的依據。
48、進一步地,s6所述的有標簽數據和帶偽標簽的無標簽數據共同訓練檢測模型,并且實時將學生網絡的權重參數傳遞給教師網絡,具體為:
49、有標簽數據和帶偽標簽的無標簽數據共同訓練檢測模型,并且實時將學生網絡的權重參數通過指數移動平均方法(exponential?moving?average,ema)傳遞給教師網絡進行更新,如此循環反復,以獲得更加穩定可靠的偽標簽,逐漸提高整個模型的檢測準確率。這一階段的損失為半監督損失,半監督損失為監督損失和無監督損失之和,半監督損失定義為:
50、l=ls+λμlu
51、其中,ls有是監督損失,lu是無監督損失,λμ是無監督損失權重,用來平衡有監督損失和無監督損失。
52、本發明采用指數滑動平均(ema)策略用學生模型對教師模型進行更新,使偽標簽可以和缺陷檢測網絡互相加強,提升了檢測模型的健壯性,其公式如下:
53、ema[t]=α*x[t]+(1-α)*ema[t-1]
54、其中,t表示時間步,x[t]表示第t個時間點的原始數據,α是平滑因子,通常取值在0到1之間,表示當前樣本的權重,本實驗設置為0.999,(1-α)則表示歷史數據的權重,ema[t-1]表示上一個時間點的ema值。
55、(三)有益效果
56、與現有技術相比,本發明的有益效果為:
57、1.本發明引入重參數卷積對網絡進行優化,實現模型計算效率和性能的提升。在訓練階段,repconv通過使用多分支卷積結構,增加了模型的表達能力,使其能夠更好地捕捉和表示復雜的特征,從而提高了模型的整體性能。在推理階段,repconv將多分支卷積結構重參數化為單一分支卷積。這大大降低了計算復雜度和內存消耗,從而加快了推理速度,使其更高效且易于部署。
58、2.本發明引入雙向特征金字塔,通過雙向特征融合和加權連接,捕捉到更多的上下文信息,提高模型對小尺度目標的檢測能力。同時雙向特征金字塔通過刪除只存在一條輸入邊的節點,減少了計算冗余,提高了計算效率,使得模型更輕量化。引入加權特征融合機制,對不同輸入特征賦予不同權重,進行快速歸一化的加權融合,使得特征融合過程更加靈活和精細,進一步提升檢測精度。
59、3.本發明將損失函數更換為focal-eiou,可通過對eiou損失進行加權處理,使模型在邊框回歸時能夠更加精細地優化邊框的定位,同時減少容易樣本的損失貢獻,從而使模型更關注困難樣本和小物體的檢測。focal-eiou可以調整低質量樣本和高質量樣本對損失函數的影響,使模型更關注高質量錨框,有助于模型更快地收斂。
60、4.本發明以教師-學生網絡作為半監督學習框架,通過結合少量的標注數據和大量的未標注數據進行訓練,有助于模型更全面地理解數據的分布特性,不僅提升了學習效率和模型的泛化能力,還顯著減少了對標注數據的依賴,降低了數據準備的成本。其中在不同階段分別采用強、弱兩種數據增強策略,增強了半監督缺陷模型的魯棒性;采用框抖動方差濾波算法對偽標簽進行篩選,有效改善了偽標簽的可靠性;采用指數滑動平均(ema)策略用學生模型對教師模型進行更新,實現偽標簽與軸承缺陷檢測網絡的相互促進,增強了檢測模型的健壯性。
- 還沒有人留言評論。精彩留言會獲得點贊!