一種對抗性雙分類器深度隱寫分析網絡訓練方法及裝置
本發明涉及面向現實應用中載體源失配情況下的深度隱寫分析,尤其涉及一種對抗性雙分類器深度隱寫分析網絡訓練方法及裝置。
背景技術:
1、圖像隱寫術是一種將秘密信息嵌入到數字圖像中以實現隱蔽通信的技術。圖像隱寫分析作為圖像隱寫術的對抗技術,則致力于揭示圖像中秘密信息的存在。
2、現有的圖像隱寫分析技術可以分為兩類:基于手工設計特征的方法和基于深度學習的方法。手工設計特征的隱寫分析是一種傳統的方法,其核心思想是通過專業領域知識和先驗信息手動選擇和構建用于隱寫分析的特征。其中,最具代表性的是空域富模型(spatial?rich?model,srm)及其變體和jpeg富模型(jpeg?rich?model,jrm)及其變體。而深度隱寫分析采用端到端的學習方式,無需手動設計特征提取器,模型可以自動地從圖像中學習到更高層次的特征表示。其中,空域的深度隱寫分析網絡有qiannet、xunet、yedroudjnet、yenet、zhunet、covpoolnet、lwenet;jpeg域的深度隱寫分析網絡有j-xunet、vnet,srnet在空域、jpeg域均能取得不錯的性能。這些網絡利用卷積神經網絡等結構,從輸入圖像中學習特征表示,并通過訓練階段調整網絡參數以優化隱寫分析性能。深度隱寫分析已成為隱寫術分析領域的主流方法,其高度自適應和學習能力使其在處理多樣化的隱寫術和圖像數據時表現出色。
3、基于深度學習的隱寫分析網絡在可控的實驗室環境中表現出了顯著的性能。然而,當待檢測的圖像(記為目標域圖像)與用于訓練的圖像(記為源域圖像)來自不同圖像源時,此時源域和目標域的圖像遵循不同的分布,網絡性能會迅速惡化,這種現象被稱為載體源失配(cover?source?mismatch,csm)。但目前解決這一問題的研究有限,如j-net通過最小化源域和目標域特征間的聯合最大均值差異來對齊源域和目標域,達到域適應的目的;rcdd則在進行領域對齊時額外考慮了類別信息,能夠分類別處理域間分布差異——最大化類間域差異的同時最小化類內域差異,從而使得領域對齊后的目標域樣本類內更緊湊、類間更分開,有利于目標域樣本的分類等。但上述方法主要集中在跨域特征對齊或提取域不變特征上,卻忽略了模型的判別能力。
技術實現思路
1、本發明的目的在于提供一種對抗性雙分類器深度隱寫分析網絡訓練方法及裝置。
2、本發明采用的技術方案是:
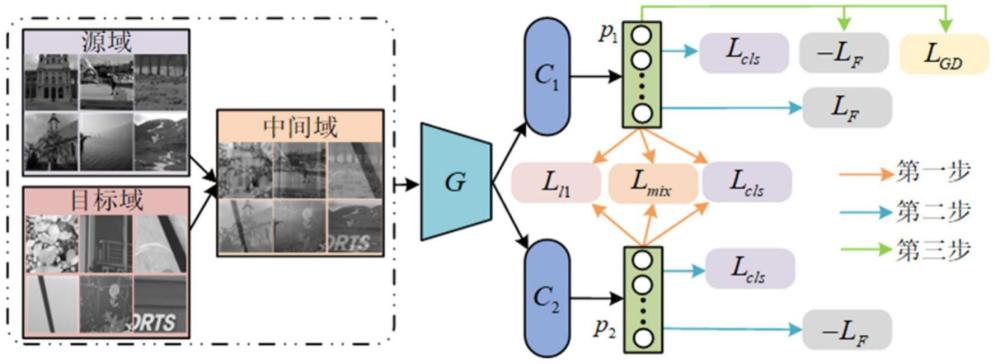
3、一種對抗性雙分類器深度隱寫分析網絡訓練方法,采用的一種對抗性雙分類器深度隱寫分析網絡包括中間域生成模塊、特征生成器、第一分類器c1、第二分類器c2;中間域生成模塊接收源域集合和目標域集合并采用mixup來生成中間域集合特征生成器g對中間域的特征進行特征提取得到第一特征;第一特征分別輸入至第一分類器c1和第二分類器c2;采用非均勻的訓練方式進行對抗訓練,第一分類器c1和特征生成器g進行對抗,使得特征生成器學習域不變特征,第二分類器c2用于保留特定于目標的決策邊界;具體訓練步驟如下:
4、步驟1,接收源域圖像和目標域圖像,構建隱寫訓練數據集;
5、步驟2,隱寫訓練數據集按批次成對送入對抗性雙分類器深度隱寫分析網絡進行第一次優化訓練,分別計算第一分類器和第二分類器的監督損失lcls、l1-距離ll1和中間域的交叉熵損失lmix;
6、步驟3,利用監督損失lcls、l1-距離ll1和交叉熵損失lmix對特征生成器g的更新參數θg、第一分類器c1的更新參數和第二分類器c2的更新參數進行第一次優化更新;第一次優化更新的目標表達式如下:
7、
8、其中,表示源域圖像集合,表示源域標簽集合,ns表示源域圖像數量;表示目標域圖像集合,nt表示目標域圖像數量;表示中間域圖像集合,表示中間域標簽集合,nm表示中間域圖像數量。lce表示標準交叉熵損失,表示第n(n∈{1,2})個分類器針對源域樣本的softmax輸出概率;表示第n個分類器針對目標域樣本的softmax輸出概率;表示第n(n∈{1,2})個分類器針對中間域樣本的softmax輸出概率。。k表示源域和目標域的類別數量(本發明中固定k=2),|.|表示絕對值,α和β為兩個平衡參數。
9、步驟4,保持第一次優化更新后的特征生成器g的更新參數θg不變,將隱寫訓練數據集按批次成對送入對抗性雙分類器深度隱寫分析網絡進行第二次優化訓練,分別計算第一分類器和第二分類器的監督損失lcls和f-范數lf;
10、
11、其中,表示第n個分類器針對目標域樣本的softmax輸出概率,是第k個元素的值。
12、步驟5,利用監督損失lcls和f-范數lf對第一分類器c1的更新參數和第二分類器c2的更新參數進行第二次優化更新,第二優化更新的目標表達式如下:
13、
14、其中,γ是與lf對應的平衡參數。
15、步驟6,保持第二次優化更新后的第一分類器c1的更新參數和第二分類器c2的更新參數不變,將隱寫訓練數據集按批次成對送入對抗性雙分類器深度隱寫分析網絡進行第二次優化訓練,計算第一分類器的梯度差異損失lgd和f-范數lf;
16、
17、其中,t表示轉置運算,‖.‖2表示l2-范數運算;gs和gt分別表示源和目標樣本上的期望梯度,對應的表達式如下:
18、
19、其中,e表示標準信息熵;表示分類器的梯;lmix是有權重的交叉熵;
20、步驟7,利用梯度差異損失lgf和f-范數lf對特征生成器g的更新參數θg進行第三次優化更新,第三優化更新的目標表達式如下:
21、
22、進一步地,中間域生成模塊利用加權聚類算法為目標域圖像的目標樣本產生偽標簽然后再與收源域圖像的源域標簽進行混合得到中間域圖像;混合過程采用如下表達式:
23、
24、其中,表示來自源域的第i個樣本,表示來自目標域的第j個樣本;表示源域標簽,表示為目標樣本產生的偽標簽和是生成的中間域樣本和標簽,λ服從beta(1,1)分布。
25、進一步地,偽標簽的產生步驟如下:
26、步驟0-1,利用第一分類器和第二分類器的softmax輸出對目標樣本進行加權,以獲得第k類的質心ck,對應的計算公式如下:
27、
28、其中,是第k個元素的值;表示第j個目標域樣本的特征輸出。
29、步驟0-2,依據最近質心策略獲得偽標簽其中,d代表余弦距離,意味著目標樣本被分配到其質心ck與的余弦距離最小的第k類。
30、進一步地,步驟2中的中間域的交叉熵損失lmix使用加權交叉熵,具體公式如下:
31、
32、其中,表示第j個目標域樣本的權重,表示目標域樣本的偽標簽。
33、進一步地,步驟5中最小化第一分類器c1的f-范數,縮小第一分類器c1決策邊界;同時最大化第二分類器c2的f-范數,擴展第二分類器c2決策邊界。
34、進一步地,步驟7中最大化lf保證目標域樣本提取的特征遠離決策邊界,從而提高模型對目標域樣本預測的確定性;最小化lgd,使目標域樣本的梯度向量與源域樣本的梯度向量相似,從而提高模型預測的準確性。
35、一種對抗性雙分類器深度隱寫分析網絡訓練裝置,其包括計算機設備,計算機設備包括處理器和存儲器,存儲器中存儲有計算機指令,處理器用于執行存儲器中存儲的計算機指令,當計算機指令被處理器執行時裝置實現所述的一種對抗性雙分類器深度隱寫分析網絡訓練方法所實現的步驟。
36、本發明采用以上技術方案,將雙分類器對抗學習引入隱寫分析以解決csm發生時性能下降問題的工作。考慮到有限數量的訓練樣本可能導致特征的潛在空間不夠平滑和連續,利用mixup生成用于訓練的中間域,從而增加樣本的多樣性并提高檢測精度。由于認識到傳統的均勻訓練范式縮小了決策邊界,不可避免地損害了模型對目標樣本的判別能力,采用了非均勻訓練策略,即兩個分類器c1和c2,在訓練期間經歷不同的處理。為了提高分類器的確定性,在分類器的預測上引入了f-范數。更大的f-范數表示更具決定性的預測。對于c1,最小化其f-范數以縮小決策邊界,促進學習域不變特征;對于c2,最大化其f-范數以擴展決策邊界,確保目標樣本預測的高確定性。最后,在優化特征提取器的過程中引入兩個域之間的梯度相似性來評估預測的準確性。如果來自兩個域的所有樣本都被正確分類,則從源樣本和目標樣本導出的梯度向量應該表現出相似性。通過梯度相似性的應用,本發明確保了預測的準確性,實現模型對目標樣本進行精確分類。
- 還沒有人留言評論。精彩留言會獲得點贊!