一種重要性感知的深度學習數據預取方法和系統
本發明屬于計算機科學人工智能系統領域,涉及一種重要性感知的深度學習數據預取方法和系統。針對深度學習訓練面對海量數據時,訓練數據預取時間長導致訓練性能較低的問題。
背景技術:
1、深度神經網絡(deep?neural?network,dnn)是一種由多層神經元組成的復雜網絡模型,能夠學習數據中的復雜模式和特征。dnn的訓練流程是一個迭代優化過程,整個訓練過程通常包含多個周期(epoch),每個周期對整個訓練數據集進行一次完整的遍歷。每個周期又由多個迭代(iteration)組成,每次迭代處理一個一小批數據(batch)。每次迭代包含三個階段:①數據加載:從待訓練的數據集中隨機選取一小批數據加載到內存中;②數據預處理:將數據進行增強操作(比如裁剪、翻轉等);③計算階段:通過前向傳播和反向傳播,得到模型參數梯度,并進行更新,從而實現訓練模型的目的。
2、在處理大規模訓練數據集時,將數據存儲在遠程并行文件系統中是一種普遍的做法。然而,由于dnn訓練過程中的數據訪問模式是強隨機的,加之gpu等硬件的快速發展,數據加載的i/o過程往往成為訓練過程中的瓶頸。為了緩解這一問題,緩存技術被廣泛采用,通過將部分數據保留在內存中來減少i/o操作。但是,當緩存空間遠小于訓練數據集大小時,緩存的效果會受到限制。
3、數據預取技術是另一種重要的優化手段。它通過在計算當前batch的同時,使用多個線程提前加載未來幾個batch的數據,從而實現數據加載與模型計算的并行化,減少數據加載的等待時間。盡管如此,由于預取本身耗時較長,無法完全與計算時間并行,因此數據預取在某些dnn訓練場景中依然可能成為性能瓶頸。現有的基于重要性采樣的訓練方法并不能有效減少數據預取的時間,因為它們需要先將訓練數據加載到內存后,才能計算其重要性。
技術實現思路
1、針對現有技術存在的不足,本發明的目的是提供一種重要性感知的深度學習數據預取方法和系統,旨在解決訓練數據預取時間長導致的訓練性能低下的問題。
2、本發明的目的是通過以下方案來實現的:一種重要性感知的深度學習數據預取系統,包括:
3、訓練數據分類模塊:用于執行數據分類,根據每個周期訓練結束時收集的訓練數據重要性值波動信息,計算出每個訓練數據的重要性值的變化方差;根據所有訓練數據的方差使用自動聚類算法k-means將訓練數據自動分為重要性波動大和波動小的兩類訓練數據;
4、訓練數據采樣器:用于在每個周期訓練開始前,對所有的訓練數據的重要性值進行評估,根據重要性值評估的結果對訓練數據進行采樣,從而讓每個周期僅訓練一部分數據;
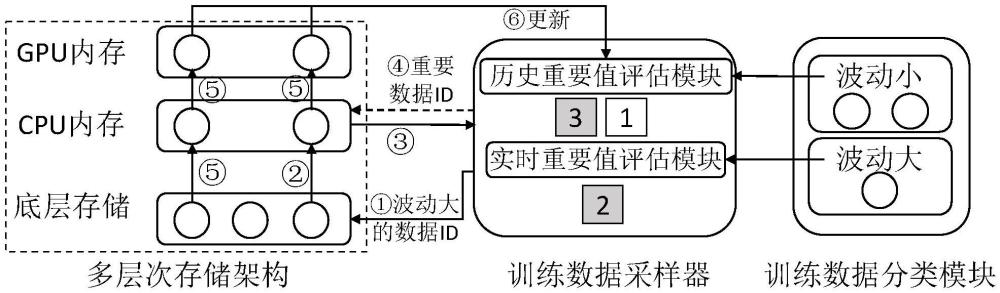
5、多層次存儲架構:包括底層存儲、cpu內存和gpu內存;底層存儲為本地的外存儲設備或由多個遠程服務器構成的并行存儲系統,用于存放完整的訓練數據;cpu內存用于存儲部分從底層讀取上來的訓練數據,進行數據預處理;gpu內存用于對dnn進行模型訓練。
6、進一步地,所述訓練數據采樣器包括以下兩個模塊:
7、實時重要值評估模塊:用于評估重要性波動程度大的訓練數據其當前的重要性值,在接下來的每個訓練周期開始前,將重要性波動程度大的訓練數據加載到cpu內存并通過該模塊重新計算重要性值,得到所述數據當前最新的重要性值;
8、歷史重要值評估模塊:用于評估重要性波動程度小的訓練數據其當前的重要性值,該評估方法直接采用上一周期訓練數據向前傳播計算得到的損失值來當做其當前的重要性值;該模塊記錄下這些歷史重要性值,并在每個周期對該歷史重要性值進行異步更新。
9、一種重要性感知的深度學習數據預取方法,其特征在于,包括以下兩個階段:
10、(1)數據分類階段:該階段由訓練數據分類模塊執行,包含k個周期;讀取預先準備的每個周期所有的訓練數據,并在前向傳播后記錄下其損失值,在第i個周期訓練結束時,得到重要性值列表記錄到訓練數據分類模塊中用于后續分類,k表示周期總數,n表示訓練數據總數,i表示訓練周期id,表示0號訓練數據在第i個周期訓練結束時的重要性值,表示1號訓練數據在第i個周期訓練結束時的重要性值,表示n-1號訓練數據在第i個周期訓練結束時的重要性值;
11、當k個周期訓練結束時,對于某個特定的訓練數據j,可以得到每個周期0至k-1,訓練結束時的重要性值列表其中,表示訓練數據j在第0周期訓練結束時的重要性值,表示訓練數據j在第1周期訓練結束時的重要性值,表示訓練數據j在第k-1周期訓練結束時的重要性值;根據這個列表計算該訓練數據j的方差varj;當得到所有訓練數據的重要性值波動方差[var0,var1,…,varn-1]后,其中,var0表示訓練數據0的方差,var1表示訓練數據1的方差,varn-1表示訓練數據n-1的方差,數據分類模塊會使用k-means聚類算法,將所有訓練數據的重要性值波動方差作為輸入,從而使訓練數據自動聚類成兩個部分;設這兩個訓練數據組分別為g1和g2,其中包含的訓練數據數量分別是n1和n2,將每個組別中訓練數據的重要性波動方差均值分別記作和其中:
12、
13、由此,得到每個訓練數據是重要性波動較大還是較小的數據,具體依據如下:
14、
15、該分類結果傳輸到訓練數據采樣器記錄下來;
16、(2)重要性感知的預取訓練階段:
17、(2.1)在下一個訓練周期開始前,訓練數據采樣器會先將本周期波動較大的訓練數據id告知底層存儲;從而,這部分數據先從底層存儲中預取到cpu內存中;
18、(2.2)波動較大的訓練數據傳輸到訓練數據采樣器中,并通過實時重要值評估模塊對其重要性值進行評估,通過前向傳播計算,根據最新損失值更新所述波動較大的訓練數據的最新重要性值;將這部分的數據存入cpu內存中的緩存以加速這部分數據的讀取;若緩存空間不夠,則將其中重要性值相對更大的數據優先存入緩存;
19、(2.3)將重要性值波動較小的訓練數據的歷史重要性值從歷史重要值評估模塊中讀取并作為當前周期重要性值;在此基礎上,將所有訓練數據按照重要性值降序排列,訓練數據采樣器選擇其中重要性值較大的部分數據參與后續的訓練;將這部分的數據id傳輸回cpu內存;
20、(2.4)根據步驟(2.3)選擇出來的數據每次隨機選擇一個小批次,從緩存或存儲設備中讀取送入gpu內存中參與模型訓練;訓練過程中對于波動較小的訓練數據,其重要性值即前向傳播的損失值,該值需要由歷史重要值評估模塊進行更新;
21、(2.5)在訓練當前批次數據的同時開啟后續批次數據的預取;重復步驟(2.4)當把所有采樣出來的數據都訓練結束后,一個周期的訓練結束。
22、進一步地,階段(2)中所述緩存采用靜態緩存。
23、本發明的有益效果在于:
24、(一)本發明提出的基于重要性感知的預取機制,可以減少不重要訓練數據的預取數量,與傳統對所有訓練數據都進行預取的方法相比,從而緩解i/o是瓶頸的dnn訓練中預取瓶頸的問題。
25、(二)本發明根據訓練數據的重要性值波動的劇烈程度,將訓練數據分為波動大和波動小的兩類數據,從而僅對波動大的數據通過額外的數據加載和重新評估重要性值;并將波動大的數據使用靜態緩存起來,這樣的做法可以降低(一)中引入的額外數據加載開銷。
26、(三)本發明方法可以加快i/o是瓶頸的模型訓練場景下的模型訓練速度。
- 還沒有人留言評論。精彩留言會獲得點贊!