一種實時數據計算處理方法、系統、計算機設備及介質與流程
本發明涉及大數據處理,特別是涉及一種實時數據計算處理方法、系統、計算機設備及存儲介質。
背景技術:
1、隨著大數據的推廣應用,為了更好應對企業業務場景數據多源化和結構復雜化問題,建設數據倉庫管理維護數據已成為業務管理的必要技術手段。同時,為了更好地滿足業務處理的實時性需求,以數據倉庫為數據支撐,基于spark或flink計算引擎進行實時數據計算處理成為主流解決方案。
2、然而,現有實時計算引擎處理流程采用的是對數據有狀態記錄的操作,這樣做就相當于在實時計算任務啟動或重啟時,需要先將全量的歷史數據表項全量加載到內存中,再由spark或flink自行形成歷史數據和新數據的依賴關系進行關聯計算,才能實現數據的增刪改全場景計算。該方法雖然能保證計算效率的高效性,但對于存在大量歷史數據的場景而言,不僅因需要消耗相當大的內存使用量造成硬件消耗大,會增大企業業務管理的投資成本,而且還需要額外增加內存評估處理以避免任務運行中因數據量增加而導致內存溢出風險,會額外增加計算服務的性能開銷,進而導致內存硬件不足或主機內存擴展受限場景無法滿足大數據實時計算需求,給實際企業投入生產使用帶來較大的局限性。
技術實現思路
1、本發明的目的是提供一種實時數據計算處理方法,通過將內存管理歷史數據的壓力轉移至kudu數據庫磁盤上,利用其高效的主鍵檢索能力實現快速與歷史數據的關聯,使得只需要加載計算需要的歷史數據而避免加載無關歷史數據,有效解決了現有實時計算任務必須加載全量歷史數據的高內存占用缺陷,可以在低內存硬件條件下實現基于sql語句在spark計算引擎中對數據的實時計算,在多表關聯計算場景下也能兼容各個關聯子表數據的增刪改場景的操作,在保證實時計算效率的同時,有效降低實時計算內存開銷。
2、為了實現上述目的,有必要針對上述技術問題,提供一種實時數據計算處理方法、系統、計算機設備及存儲介質。
3、第一方面,本發明實施例提供了一種實時數據計算處理方法,所述方法包括以下步驟:
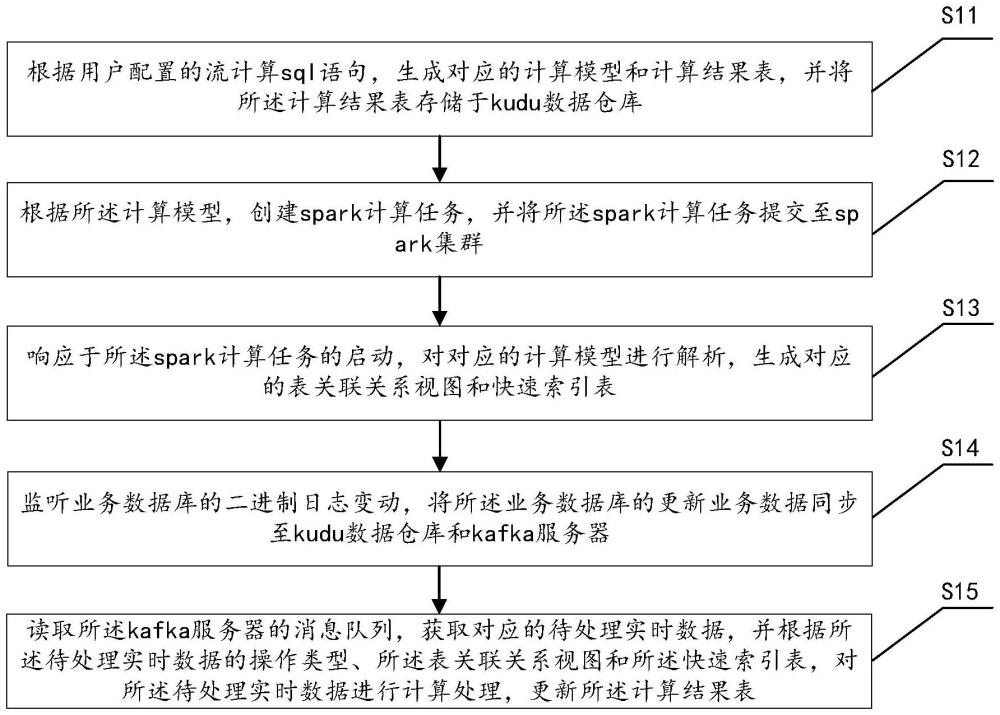
4、根據用戶配置的流計算sql語句,生成對應的計算模型和計算結果表,并將所述計算結果表存儲于kudu數據倉庫;
5、根據所述計算模型,創建spark計算任務,并將所述spark計算任務提交至spark集群;
6、響應于所述spark計算任務的啟動,對對應的計算模型進行解析,生成對應的表關聯關系視圖和快速索引表;
7、監聽業務數據庫的二進制日志變動,將所述業務數據庫的更新業務數據同步至kudu數據倉庫和kafka服務器;
8、讀取所述kafka服務器的消息隊列,獲取對應的待處理實時數據,并根據所述待處理實時數據的操作類型、所述表關聯關系視圖和所述快速索引表,對所述待處理實時數據進行計算處理,更新所述計算結果表。
9、進一步地,所述根據用戶配置的流計算sql語句,生成對應的計算模型和計算結果表的步驟包括:
10、判斷所述流計算sql語句是否包括子查詢;
11、若不包括,則直接根據所述流計算sql語句,生成對應的計算模型和計算結果表;
12、若包括,則對所述流計算sql語句進行子查詢拆分,生成對應的子查詢語句,并據各個子查詢語句,生成對應的子計算模型和子計算結果表,以及根據各個子計算結果表間的血緣依賴關系,構建對應的計算結果表。
13、進一步地,所述對對應的計算模型進行解析,生成對應的表關聯關系視圖和快速索引表的步驟包括:
14、通過sql解析器,對所述計算模型中的sql語句表關系依賴進行解析,得到對應的表關聯關系視圖;所述表關聯關系視圖包括多個關聯表依賴關系;所述關聯表依賴關系包括表名、主鍵字段名和關聯關系字段名和關聯類型;
15、根據所述表關聯關系視圖中各個關聯表的主鍵字段,計算主鍵md5值,并根據所述主鍵md5值和各個關聯表的主鍵字段,生成對應的快速索引表。
16、進一步地,所述將所述業務數據庫的更新業務數據同步至kudu數據倉庫和kafka服務器的步驟包括:
17、通過streamsets數據同步工具,將所述更新業務數據對應的實時消費數據同步至kafka服務器;同時,
18、根據所述更新業務數據,對所述kudu數據倉庫的貼源層數據表進行更新。
19、進一步地,所述待處理實時數據包括數據庫名、操作類型、待操作數據表名、待操作字段名和對應的字段值;
20、所述根據所述待處理實時數據的操作類型、所述表關聯關系視圖和所述快速索引表,對所述待處理實時數據進行計算處理,更新所述計算結果表的步驟包括:
21、當所述操作類型為新增或修改時,根據所述待操作數據表名、所述待操作字段名和所述表關聯關系視圖,獲取所述kudu數據倉庫中的相關歷史數據,并根據所述相關歷史數據、所述待操作字段名和對應的字段值,計算生成對應的彈性分布式數據集,以及根據所述快速索引表,將所述彈性分布式數據集更新至所述kudu數據倉庫中對應的計算結果表;
22、當所述待處理實時數據的操作類型為刪除時,根據所述待操作數據表名和所述待操作字段名,獲取對應的關聯表主鍵,并根據所述關聯表主鍵和所述快速索引表,刪除所述kudu數據倉庫中對應計算結果表的相關數據項,并根據所述待操作數據表名的關聯表屬性和所述表關聯關系視圖,對當前計算結果表的剩余表項數據進行計算更新。
23、進一步地,所述根據所述待操作數據表名、所述待操作字段名和所述表關聯關系視圖,獲取所述kudu數據倉庫的相關歷史數據的步驟包括:
24、根據所述表關聯關系視圖中的所有關聯表信息,生成與所述所述待操作數據表名和所述待操作字段名對應的臨時視圖表;
25、根據所述臨時視圖表進行spark謂詞下推處理,從所述kudu數據倉庫中獲取對應的相關歷史數據。
26、進一步地,所述根據所述待操作數據表名的關聯表屬性和所述表關聯關系視圖,對當前計算結果表的剩余表項數據進行計算更新的步驟包括:
27、當所述關聯表屬性為子表時,根據對應表關聯關系視圖中的上層表依賴關系,獲取對應的關聯主表;
28、根據所述關聯主表,獲取對應的主表kudu歷史數據,并根據所述主表kudu歷史數據、所述待操作字段名和對應的字段值,計算生成對應的主表臨時結果集;
29、根據所述主表臨時結果集,對所述kudu數據倉庫中的主表數據進行替換,并根據更新后的主表數據進行計算,得到實時計算結果;
30、根據所述實時計算結果,對當前計算結果表的剩余表項數據進行替換更新。
31、第二方面,本發明實施例提供了一種實時數據計算處理系統,所述系統包括:
32、計算模型創建模塊,用于根據用戶配置的流計算sql語句,生成對應的計算模型和計算結果表,并將所述計算結果表存儲于kudu數據倉庫;
33、計算任務創建模塊,用于根據所述計算模型,創建spark計算任務,并將所述spark計算任務提交至spark集群;
34、關聯關系提取模塊,用于響應于所述spark計算任務的啟動,對對應的計算模型進行解析,生成對應的表關聯關系視圖和快速索引表;
35、實時數據同步模塊,監聽業務數據庫的二進制日志變動,將所述業務數據庫的更新業務數據同步至kudu數據倉庫和kafka服務器;
36、實時數據計算模塊,用于讀取所述kafka服務器的消息隊列,獲取對應的待處理實時數據,并根據所述待處理實時數據的操作類型、所述表關聯關系視圖和所述快速索引表,對所述待處理實時數據進行計算處理,更新所述計算結果表。
37、第三方面,本發明實施例還提供了一種計算機設備,包括存儲器、處理器及存儲在存儲器上并可在處理器上運行的計算機程序,所述處理器執行所述計算機程序時實現上述方法的步驟。
38、第四方面,本發明實施例還提供一種計算機可讀存儲介質,其上存儲有計算機程序,所述計算機程序被處理器執行時實現上述方法的步驟。
39、上述本技術提供了一種實時數據計算處理方法、系統、計算機設備和存儲介質,實現了根據用戶配置的流計算sql語句,生成對應的計算模型和計算結果表,并將所述計算結果表存儲于kudu數據倉庫;根據計算模型,創建spark計算任務,并將spark計算任務提交至spark集群;響應于spark計算任務的啟動,對對應的計算模型進行解析,生成對應的表關聯關系視圖和快速索引表;監聽業務數據庫的二進制日志變動,將業務數據庫的更新業務數據同步至kudu數據倉庫和kafka服務器;讀取kafka服務器的消息隊列,獲取對應的待處理實時數據,并根據待處理實時數據的操作類型、所述表關聯關系視圖和所述快速索引表,對待處理實時數據進行計算處理,更新計算結果表的技術方案。與現有技術相比,該實時數據計算處理方法,通過將內存管理歷史數據的壓力轉移至kudu數據庫磁盤上,利用其高效的主鍵檢索能力實現快速與歷史數據的關聯,使得只需要加載計算需要的歷史數據而避免加載無關歷史數據,有效解決了現有實時計算任務執行必須加載全量歷史數據的高內存占用缺陷,可以在低內存硬件條件下實現基于sql語句在spark計算引擎中對數據的實時計算,在多表關聯計算場景下兼容各個關聯子表數據的增刪改場景的操作,在保證實時計算效率的同時,有效降低實時計算內存開銷,具有較高的實用價值。
- 還沒有人留言評論。精彩留言會獲得點贊!