一種基于遺傳規劃的元學習小樣本圖像分類方法
本發明涉及機器學習與圖像處理,尤其涉及一種基于遺傳規劃的元學習小樣本圖像分類方法。
背景技術:
1、小樣本圖像分類是一個重要的計算機視覺任務,尤其是在醫療等資源有限的場景下。已有的專利大多數是基于元學習的方法,在數據樣本難以獲取的場景下,通過元學習的方法訓練出具有較好泛化性能的分類模型,該模型通過少量新類樣本的學習即能勝任新的分類任務。
2、元學習的目標是讓模型能夠從少量的樣本中快速學習到新的任務,為了達到這個目標,需要用大量不同的任務來訓練模型,使其獲得快速學習的能力。模型不可知元學習(maml)算法的背后思想十分簡單:訓練得到一套模型的初始參數,使得該模型僅通過少量樣本上的一次或幾次梯度更新就能夠最大化新任務的性能。這一過程可以看做是最大化新任務損失函數對于模型參數的敏感度:當敏感度比較高時,模型參數很細微的改變就能造成任務損失函數很大的進步。
3、maml算法是一種基于優化的元學習算法,其目的是建立神經網絡的良好初始狀態,然后可以使用幾個優化步驟來適應任何新的任務。在maml中,它的骨干體系結構是固定的四塊卷積架構,由于圖像之間的高度變化以及圖像中的扭曲,使用固定結構的網絡在對不同圖像進行的好的特征提取是困難的。
技術實現思路
1、針對現有技術的不足,本發明考慮到目前大多數基于元學習的方法,使用的網絡架構固定,而圖像之間存在高度變化,如比例、旋轉、照明和視點,以及圖像中的扭曲,如模糊、低對比度和噪聲的問題,提供一種可以在少量訓練樣本情況下表現的很好的基于遺傳規劃的元學習小樣本圖像分類方法。
2、本發明的技術方案為:
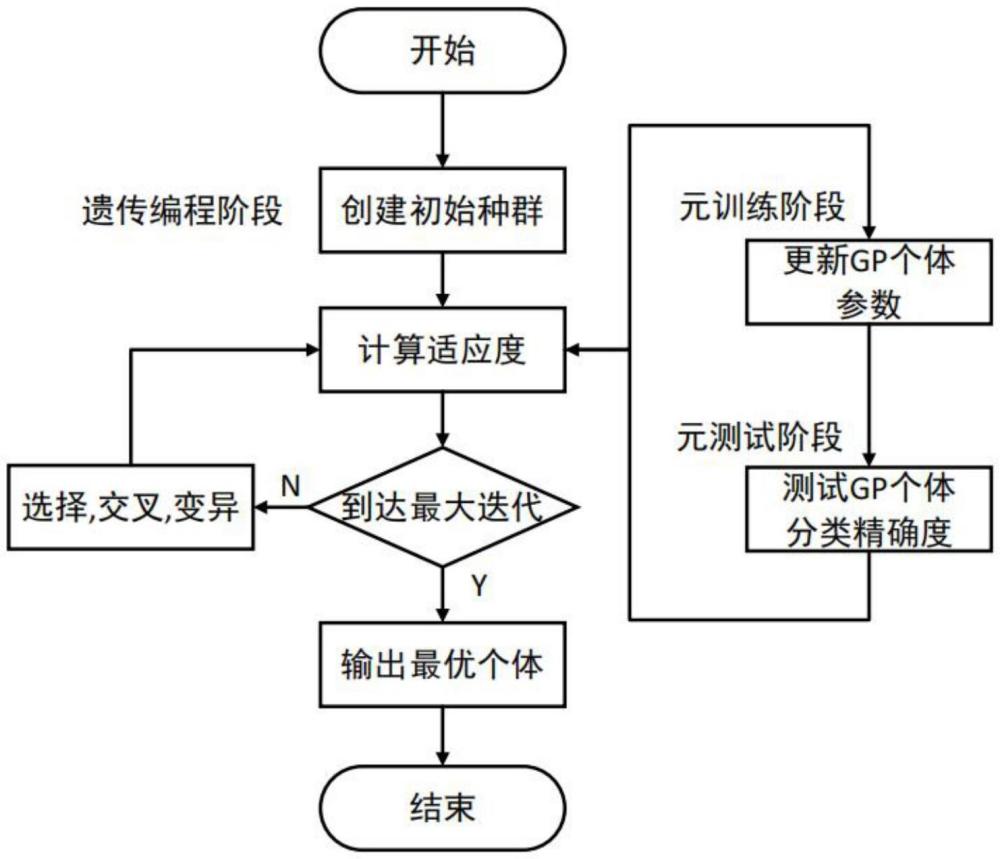
3、一種基于遺傳規劃的元學習小樣本圖像分類方法,包括如下步驟:
4、步驟1:根據分類需求,確定元學習的模式n-way?k-shot?learning,其中n為類別數量,k為每個類別的數據量;
5、步驟2:獲取元訓練集dmeta-train和元測試集dmeta-test;所述元訓練集dmeta-train包括xa個已標注類別的圖像,元測試集dmeta-test包括xn個已標注類別的圖像,且元測試集與元訓練集中的類別不同;
6、步驟3:在n-way?k-shot?learning模式下,根據元訓練集dmeta-train和元測試集dmeta-test構建訓練批次和驗證批次;
7、所述構建訓練批次的方法為:從元訓練集中隨機選取設定數量的類別,每個類別中選取設定數量的圖像,每個圖像作為一個支持集support?set,再選取設定數量的圖像,每個圖像作為一個查詢集query?set,組成一個task任務,重復選取過程,得到若干個訓練批次batch,每個訓練批次batch中包括若干個task任務;
8、所述構建驗證批次的方法為:從元測試集中隨機選取設定數量的類別,每個類別中選取設定數量的圖像,每個圖像作為一個支持集support?set’,再選取設定數量的圖像,每個圖像作為一個查詢集query?set’,組成一個task’任務,重復選取過程,得到若干個驗證批次batch’,每個驗證批次batch’中包括若干個task’任務;
9、步驟4:獲取初始種群;所述初始種群中包括n個樹形結構的gp個體;
10、gp個體的生成方法為:構建函數集和終端集,使用樹生成方法隨機生成n個gp個體,每個gp個體通過從函數集中選擇函數來構建內部節點和根節點,并從終端集中選擇終端來構建葉節點,得到樹形結構的gp個體;所述終端包括圖像和函數參數;所述根節點包括特征串聯節點;所述內部節點包括過濾節點、特征提取節點、池化節點和過濾或池化節點;所述葉節點包括圖像節點和函數參數節點;
11、每個gp個體中包括第一圖像節點、第一函數參數節點、第一過濾節點、第一池化節點、第一過濾或池化節點、第二圖像節點、第二函數參數節點、第二池化節點、第二過濾或池化節點、特征提取節點、特征串聯節點,其中第一過濾節點、第二池化節點、第一過濾或池化節點和第二過濾或池化節點為靈活節點,根據需求確定是否生成;
12、所述第一圖像節點和第二圖像節點均表示輸入gp個體的圖像;
13、所述第一函數參數節點和第二函數參數節點均表示輸入gp個體中的函數參數;
14、所述第一過濾節點表示一個過濾函數,用于對第一圖像節點表示的圖像進行過濾操作;
15、所述第一池化節點表示一個池化函數,用于對過濾節點輸出的圖像進行最大池化并縮小尺寸;
16、所述第一過濾或池化節點表示一個過濾函數或一個池化函數,用于對第一池化節點輸出的圖像進行過濾或最大池化;
17、所述第二池化節點表示一個池化函數,用于對第二圖像節點表示的圖像進行最大池化并縮小尺寸;
18、所述第二過濾或池化節點表示一個過濾函數或一個池化函數,用于對第二池化節點輸出的圖像進行過濾或最大池化;
19、所述特征提取節點用于表示一個特征提取函數,用于對第二過濾或池化節點輸出的圖像進行特征提取,得到特征向量;
20、所述特征串聯節點用于表示一個特征串聯函數,用于組合特征提取節點和第一過濾或池化節點輸出的不同的特征向量,得到最終的特征向量;
21、步驟5:將maml算法與遺傳規劃結合,利用訓練批次和驗證批次獲取gp個體中的最好個體;
22、步驟5.1:利用訓練批次中的圖像對當前種群中的gp個體進行元訓練,得到若干個訓練完成的gp個體;
23、步驟5.1.1:將當前種群中的每個gp個體轉換成神經網絡架構mmeta;
24、所述轉換的方法具體為:
25、s1:從每個gp個體的樹形結構中的根節點開始,遞歸地訪問每個子節點;所述子節點包括內部節點和葉節點;
26、s2:將每個gp個體的樹形結構中的所有節點映射為神經網絡的一個組件;
27、具體為:將內部節點映射為神經網絡的層,將葉節點映射為神經元,將根節點映射為連接;具體的,葉節點中的圖像節點作為神經網絡的輸入神經元,所述內部節點中的過濾節點,池化節點和特征提取節點分別作為神經網絡中的過濾層,池化層和特征提取層,所述葉節點中的函數參數節點對應過濾層,池化層和特征提取層的超參數,所述根節點中的特征串聯節點作為神經網絡中的連接層;
28、s3:根據映射結果,使用深度學習框架構建神經網絡架構mmeta;
29、步驟5.1.2:設置神經網絡架構mmeta的初始化參數φ,訓練批次batch的編號t=0;
30、步驟5.1.3:利用第t個訓練批次batch中的每個任務task中的支持集support?set訓練神經網絡架構,每個任務task訓練結束后計算更新后的參數
31、
32、其中,為在完成對一個任務的單次梯度下降后獲得的新參數,i為任務task的編號;η為學習率,l(φ)為在當前任務的支持集上的損失函數,表示損失函數關于參數φ的梯度;
33、步驟5.1.4:使用任務task中的查詢集query?set對由該任務task中支持集support?set得到的更新后的參數進行驗證,得到每個任務task中的查詢集query?set上的損失函數,進而計算得到總損失函數;
34、所述總損失函數為:
35、
36、其中,l(φ)為總損失函數;bs為任務的個數;li為在每個任務的查詢集上的損失函數;
37、步驟5.1.5:獲得總損失函數后,根據總損失函數更新神經網絡架構mmeta的當前參數,訓練批次batch的編號t加1并返回步驟5.1.3,直至t達到設置的訓練批次或神經網絡架構mmeta的參數收斂,訓練結束,得到若干個訓練完成的gp個體;
38、
39、其中,φ'為更新后的神經網絡架構mmeta的參數;
40、步驟5.2:利用驗證批次中的圖像對若干個訓練完成的gp個體對應的當前的神經網絡架構mmeta進行元測試,并對神經網絡架構mmeta的參數進行調整,得到若干個調整后的神經網絡架構mfine-tune并計算調整后的神經網絡架構mfine-tune的準確率;
41、步驟5.2.1:利用驗證批次batch’中每個任務task’中的支持集support?set’對當前的神經網絡架構mmeta的參數進行調整,經過k次調整更新后得到調整后的神經網絡架構mfine-tune;
42、多步梯度下降,對于k次迭代,更新規則為:
43、
44、其中,為更新后的參數;表示更新前的參數;ti'表示當前任務,i'表示任務task’的編號;j表示每個任務task’中梯度下降的次數,且j=0……k-1;α是學習率;表示損失函數關于的梯度;表示當前任務的損失函數;
45、步驟5.2.2:將準確率作為評估指標,使用驗證批次batch’中每個任務的查詢集query?set’對調整后的網絡架構mfine-tune進行評估,計算得到調整后的網絡架構mfine-tune的準確率;
46、步驟5.3:使用步驟5.2獲得的準確率作為對應的gp個體的適應度值,利用遺傳規劃獲取最優的gp個體;
47、步驟5.3.1:設置初始迭代次數為0;
48、步驟5.3.2:計算當前種群中每個gp個體的適應度值;所述適應度值為調整后的神經網絡架構mfine-tune的準確率;
49、步驟5.3.3:按照精英數z以精英主義的方式從當前種群中選擇適應度值最大的z個gp個體構成精英種群;
50、步驟5.3.4:對當前種群中剩余的gp個體進行交叉和突變,得到新的gp個體;
51、所述交叉的方法為:任意選擇兩個gp個體并隨機選擇一個非葉子節點作為交叉點,交換交叉點及其以下的子樹,得到兩個新的gp個體,這兩個新的子個體將作為新一代的個體參與下一輪的進化;
52、所述突變的方法為:隨機選擇一個gp個體并隨機從所有節點中選擇一個節點進行隨機的突變,突變包括插入一個新節點、刪除一個節點、替換一個節點,或者對節點的參數進行隨機變化,突變后得到的個體將作為新一代的個體參與下一輪的進化;
53、步驟5.3.5:計算得到新的gp個體的適應度值,選取適應度值最大的m個gp個體與精英種群中的gp個體構建為新一代種群;
54、步驟5.3.6:將當前種群中最好的gp個體保存在名人堂hof中,迭代次數加1,判斷當前迭代次數是否達到設定的最大迭代次數,如果是,則輸出名人堂hof中適應度值最大的gp個體作為gp個體中的最好個體,否則返回步驟5.3.3;
55、步驟6:將最好個體對應的神經網絡架構作為最終的神經網絡架構,將待分類的圖像輸入最終的神經網絡架構得到特征向量,將特征向量輸入到支持向量機分類器中,獲取分類結果。
56、與現有技術相比較,本發明的有益效果為:
57、已有的基于元學習的方法,網絡結構是通過重用最流行的分類網絡結構而任意選擇的,結構固定,由于圖像之間的高度變化以及圖像中的扭曲,使用固定結構的網絡在對不同圖像進行的好的特征提取是困難的,本發明通過在元學習算法中使用遺傳規劃自動生成的架構進行更好的特征提取,以提高其分類性能。
- 還沒有人留言評論。精彩留言會獲得點贊!